

Uber Practice: 大規模な分散システムの運用と保守に関する経験

この記事は、Uber のエンジニアである Gergely Orosz によって書かれています。元のアドレスは: https://blog.pragmaticengineer.com/operating-a-high-scale-distributed-system/
過去数年間、私は大規模な分散システムである Uber の支払いシステムを構築および運用してきました。この期間中、私は分散アーキテクチャの概念について多くを学び、高負荷かつ高可用性のシステムを実行する際の課題を直接目の当たりにしました (システムは開発された時点では完成には程遠いものであり、それをオンラインで実行する際の課題は実際に存在します)。さらに大きな)。システムを構築すること自体は興味深い取り組みです。 10 倍/100 倍のトラフィック増加にシステムがどのように対処するかを計画し、データの耐久性を確保し、ハードウェア障害に対処するなど、すべてに知恵が必要です。いずれにしても、大規模な分散システムの運用は私にとって目を見張るような経験でした。
システムが大規模になればなるほど、「うまくいかない可能性があるものはうまくいかない」というマーフィーの法則がより明らかになります。多くの開発者が頻繁にコードを展開し、複数のデータセンターが関係し、システムが世界中の多数のユーザーによって使用されると、このようなエラーが発生する可能性が高くなります。過去数年間、私はさまざまなシステム障害を経験しましたが、その多くは私を驚かせました。ハードウェア障害や一見無害に見えるバグなどの予測可能な原因から発生するものもありますが、データセンターのケーブルが掘り出されたり、複数の連鎖的な障害が同時に発生したりすることもあります。私は、システムの一部が正常に動作せず、ビジネスに多大な影響を及ぼした業務停止を何十回も経験してきました。
この記事は、私が Uber で働いている間にまとめた、大規模なシステムを効果的に運用および保守できるプラクティスをまとめたものです。私の経験は特別なものではありません。同様の規模のシステムに取り組んでいる人々は、同様の道のりを歩んできました。私は Google、Facebook、Netflix のエンジニアと話をしましたが、彼らは同様の経験とソリューションを共有していました。ここで概説したアイデアやプロセスの多くは、自社のデータセンター (ほとんどの場合 Uber が実行しているように) で実行されているか、クラウド (Uber はサービスの一部を柔軟にクラウドに展開することもあります) で実行されているかにかかわらず、同様の規模のシステムに適用できるはずです。ただし、これらの方法は、小規模またはそれほどミッションクリティカルではないシステムにとっては厳しすぎる可能性があります。
取り上げるべきことはたくさんあります。ここでは次のトピックを取り上げます:
- モニタリング
- 勤務、異常検出とアラート
- 障害イベント管理プロセス
- 事後分析、インシデントレビュー、継続的改善文化
- 障害訓練、キャパシティプランニング、ブラックボックステスト
- SLO、SLAとそのレポート
- SRE 独立したチームとして
- #継続的投資としての信頼性
- その他の推奨読書
モニタリング
システムが適切かどうかを確認するには健全な場合、「システムは適切に動作していますか?」という質問に答える必要がありますか?これを行うには、システムの主要部分に関するデータを収集することが重要です。複数のコンピューターやデータセンターで複数のサービスが実行されている分散システムの場合、監視すべき重要な項目を判断するのが難しい場合があります。
インフラストラクチャの健全性監視 1 つ以上のコンピュータ/仮想マシンが過負荷になると、分散システムの一部の機能が低下する可能性があります。マシンの健全性ステータス、CPU 使用率、メモリ使用量は、監視する価値のある基本的な内容です。一部のプラットフォームでは、この監視と自動スケール インスタンスをすぐに処理できます。 Uber には、インフラストラクチャの監視とアラートをすぐに提供できる優れたコア インフラストラクチャ チームがいます。技術レベルでどのように実装されているかに関係なく、インスタンスまたはインフラストラクチャに問題が発生した場合、監視プラットフォームは必要な情報を提供する必要があります。
サービス状態の監視: トラフィック、エラー、遅延。多くの場合、「このバックエンド サービスは健全ですか?」という質問に答える必要があります。エンドポイントにアクセスするリクエスト トラフィック、エラー率、エンドポイント レイテンシーなどを観察すると、サービスの健全性に関する貴重な情報が得られます。これらすべてをダッシュボードに表示することを好みます。新しいサービスを構築する場合、正しい HTTP 応答マッピングを使用し、関連するコードを監視することで、システムについて多くのことを学ぶことができます。したがって、クライアント エラーの場合は 4XX が返され、サーバー エラーの場合は 5xx が返されるようにすることは、構築も解釈も簡単です。
遅延の監視については、もう一度考えてみる価値があります。実稼働サービスの目標は、大多数のエンド ユーザーに優れたエクスペリエンスを提供することです。この平均により、待ち時間の長いリクエストのごく一部が隠れてしまう可能性があるため、平均待ち時間の測定はあまり良い指標ではないことがわかりました。 p95、p99、または p999 (95、99、または 99.9 パーセンタイルのリクエストによって発生するレイテンシ) を測定することは、より良い指標です。これらの数字は、「人々のリクエストの 99% はどれくらいの速さですか?」(p99) などの質問に答えるのに役立ちます。または「1,000 人に 1 人以上が経験する遅延はどれくらい遅いでしょうか?」(p999)。このトピックに興味のある方は、この遅れた入門記事を参照してください。
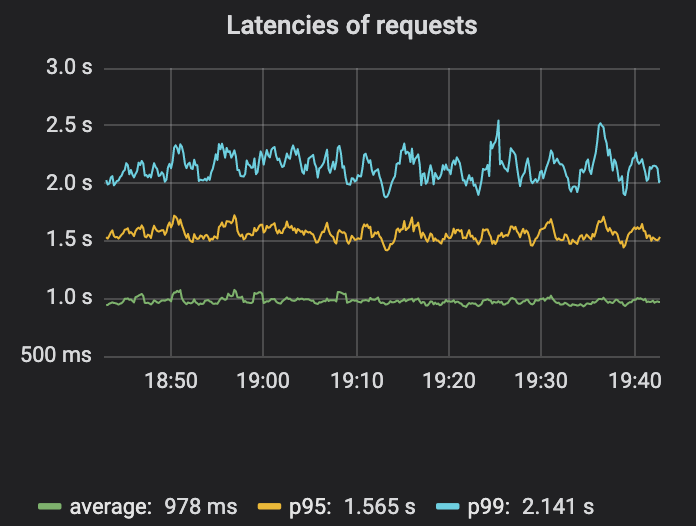
この図から、平均遅延、p95、および p99 の差が非常に大きいことが明確にわかります。したがって、平均レイテンシによっていくつかの問題が隠れてしまう可能性があります。
監視と可観測性に関しては、さらに詳細なコンテンツが多数あります。読む価値のある 2 つのリソースは、Google の SRE 本と、分散システム監視の 4 つの黄金指標に関するセクションです。ユーザー向けシステムの 4 つの指標しか測定できない場合は、トラフィック、エラー、遅延、飽和に焦点を当てることをお勧めします。短い資料については、Cindy Sridharan の電子書籍『Distributed Systems Observability』をお勧めします。この電子書籍では、イベント ログ、メトリクス、トレースのベスト プラクティスなどの他の便利なツールについて説明しています。
ビジネス指標のモニタリング。サービス モジュールを監視すると、サービス モジュールがどのように正常に動作しているかがわかりますが、ビジネスが期待どおりに動作しているかどうか、また「通常通り」であるかどうかはわかりません。決済システムにおいて重要な問題は、「特定の支払い方法を使用して支払いを行うことができるか?」ということです。ビジネス イベントを特定して監視することは、最も重要な監視手順の 1 つです。
さまざまなモニタリングを確立しましたが、依然として経営上の問題を検出できず、非常に苦労しましたが、最終的に経営指標のモニタリングを確立しました。すべてのサービスが正常に実行されているように見えても、主要な製品機能が利用できない場合があります。この種のモニタリングは、私たちの組織や分野にとって非常に役立ちます。したがって、Uber の可観測性テクノロジー スタックに基づいて、この種の監視を独自にカスタマイズするには、多くの考えと労力を費やす必要がありました。
翻訳者注: ビジネス指標の監視については、私たちも同じように感じています。以前は、Didi ではすべてのサービスが正常であっても、ビジネスが適切に機能していないことが時々ありました。ビジネスを開始するために現在構築中の Polaris システムは、この問題に対処するために特別に設計されています。興味のある友達は、公式アカウントのバックグラウンドで私にメッセージを残すか、私の友達ピコバイトを追加して通信して試してみてください。
オンコール、異常検出、アラート
モニタリングは、システムの現在の状態を把握するための優れたツールです。しかし、これは問題を自動的に検出し、人々が行動を起こすように警告を発するための単なる足がかりにすぎません。
オンコール自体は幅広いトピックです - Increment マガジンは「オンコール問題」で多くの側面を取り上げています。私の強い意見は、「自分で作ったら自分が所有する」という考え方があれば、OnCall もそれに従うだろう、というものです。サービスを構築するチームがサービスを所有し、オンコールの責任を負います。私たちのチームが支払いサービスを担当しています。そのため、アラームが発生するたびに、勤務中のエンジニアが対応し、詳細を確認します。しかし、監視からアラートへはどのように移行するのでしょうか?
監視データから異常を検出することは難しい課題ですが、機械学習が活躍できる分野です。異常検出を提供するサードパーティ サービスが多数あります。繰り返しになりますが、幸運なことに、私たちのチームには協力する社内の機械学習チームがあり、Uber の使用状況に合わせてソリューションを調整していました。ニューヨークを拠点とする Observability チームは、Uber の異常検出がどのように機能するかを説明する役立つ記事を書きました。私のチームの観点から見ると、監視データをそのチームのパイプラインにプッシュし、それぞれの信頼レベルでアラートを取得します。その後、エンジニアを呼ぶべきかどうかを決定します。
いつアラームをトリガーするかは興味深い質問です。アラートが少なすぎると、影響のある停止を見逃す可能性があります。多すぎると、眠れなくなったり、疲労感を感じたりする可能性があります。アラームの追跡と分類、および信号対雑音比の測定は、アラーム システムを調整するために重要です。アラートを確認して対応可能としてフラグを付け、その後、対応不可能なアラートを減らすための措置を講じることは、持続可能なオンコール ローテーションを達成するための良いステップです。
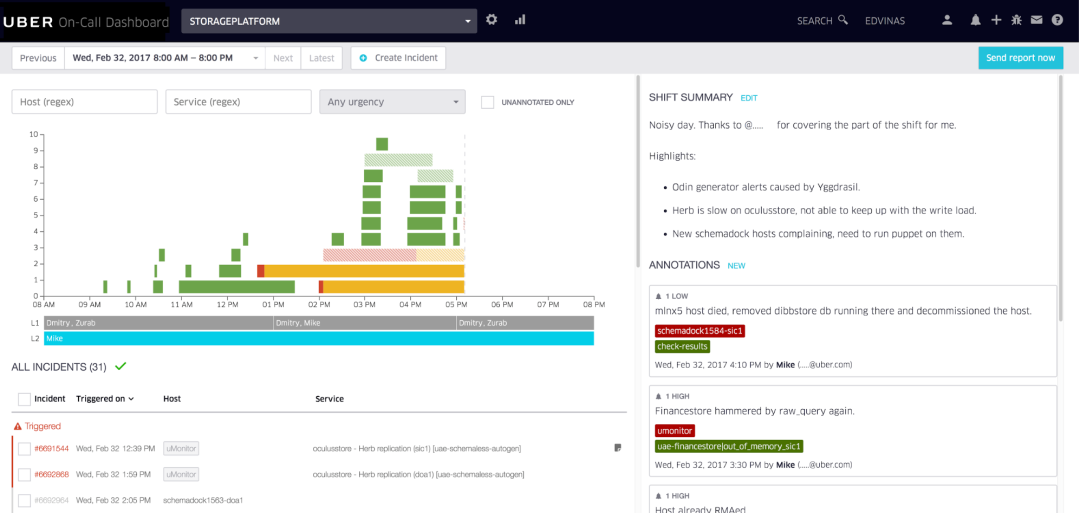
#Uber が使用する内部オンコール ダッシュボードの例。ビリニュスの Uber Developer Experience チームによって構築されました。
ビリニュスの Uber Dev Tools チームは、アラートに注釈を付けたり、コール シフトを視覚化したりするために使用する、優れた通話ツールを構築しました。私たちのチームは、最後のオンコール シフトを毎週レビューし、問題点を分析し、毎週オンコール エクスペリエンスの改善に時間を費やしています。
翻訳者注: アラーム イベントの集約、ノイズ低減、スケジュール設定、要求、アップグレード、コラボレーション、柔軟なプッシュ戦略、マルチチャネル プッシュ、IM 接続は非常に一般的なニーズであり、製品を参照してください。 FlashDuty、エクスペリエンスアドレス: https://console.flashcat.cloud/
障害およびイベント管理プロセス
想像してください: あなたは今週勤務するエンジニアです。夜中にアラームで目が覚めます。運用停止が発生したかどうかを調査します。おっと、システムの一部に問題があるようです。何をするべきだろう?モニタリングとアラートは実際に発生します。
小規模システムの場合、停止は大した問題ではない可能性があり、勤務中のエンジニアは何が起こっているのか、そしてなぜ起こっているのかを理解できます。通常、それらは理解しやすく、軽減するのが簡単です。複数の(マイクロ)サービスと多くのエンジニアがコードを実稼働環境にプッシュする複雑なシステムの場合、潜在的な問題が発生する場所を特定するだけでも十分に困難な場合があります。この問題を解決するための標準プロセスをいくつか用意しておくと、大きな違いが生まれます。
簡単な緩和手順を説明したアラートに添付されたランブックが防御の第一線となります。優れたランブックを備えたチームの場合、担当エンジニアがシステムを深く理解していなくても、問題になることはほとんどありません。 Runbook は常に最新の状態に保たれ、更新され、障害が発生した場合には新しい緩和策を使用して対処する必要があります。
翻訳者注: Nightingale と Grafana のアラーム ルール設定はカスタム フィールドをサポートできますが、RunbookUrl などの追加フィールドがデフォルトで提供されます。核心は SOP マニュアルの重要性を伝えることです。セックス。さらに、安定性管理システムでは、アラーム ルールに RunbookUrl が事前に設定されているかどうかは、アラームの健全性を示す非常に重要な指標です。
複数のチームがサービスを展開すると、障害を組織全体に伝達することが重要になります。私は、何千人ものエンジニアが独自の裁量で開発したサービスを運用環境にデプロイする環境で働いており、場合によっては 1 時間あたり数百件のデプロイが行われる可能性があります。一見無関係に見えるサービスの展開が、別のサービスに影響を与える可能性があります。この場合、標準化された障害ブロードキャストおよび通信チャネルが大いに役立ちます。私は複数のまれな警告メッセージに遭遇しましたが、他のチームの人々も同様の奇妙な現象を見ていることに気づきました。停止を処理する集中チャット グループに参加することで、停止の原因となっているサービスを迅速に特定し、問題を解決しました。私たちは誰よりも早くそれをやり遂げました。
今は安心して、明日調べましょう。故障中は、問題を解決したいという「アドレナリンラッシュ」が起こることがよくあります。多くの場合、根本的な原因はコードのデプロイメントが不十分であり、コード変更に明らかなバグがあります。以前は、コードの変更をロールバックするのではなく、すぐにバグを修正し、修正をプッシュしてバグを閉じていました。ただし、障害が発生したときに根本原因を解決するのはひどい考えです。順方向復元を使用すると、利益はほとんどありませんが、損失は大きくなります。新しい修正は迅速に行う必要があるため、運用環境でテストする必要があります。これが、2 番目のエラー、つまり既存のエラーに加えて不具合が発生する理由です。このような不具合が悪化し続けるのを私は見てきました。まずは軽減に重点を置き、根本原因を修正したり調査したりする衝動を抑えてください。適切な調査は翌営業日までお待ちいただく場合があります。
翻訳者注: ベテラン ドライバーもこの点を十分に認識しておく必要があります。オンラインでデバッグしないでください。問題が発生した場合は、修正するためにホットフィックス バージョンをリリースしようとするのではなく、すぐにロールバックしてください。
事後分析、インシデントのレビュー、および継続的な改善の文化
これは、チームが障害の余波にどのように対処するかについてです。彼らは働き続けますか?小規模な調査を行ってくれるでしょうか?システムレベルの修正を行うために製品の作業を停止するなど、将来的には驚くほどの労力を費やすことになるでしょうか?
適切に行われた事後分析は、強力なシステムを構築するための基礎です。優れた事後分析とは、非非難的かつ徹底したものです。 Uber の事後分析テンプレートはエンジニアリング テクノロジーとともに進化し続けており、インシデントの概要、影響の概要、タイムライン、根本原因分析、学んだ教訓、詳細なフォローアップ チェックリストなどのセクションが含まれています。
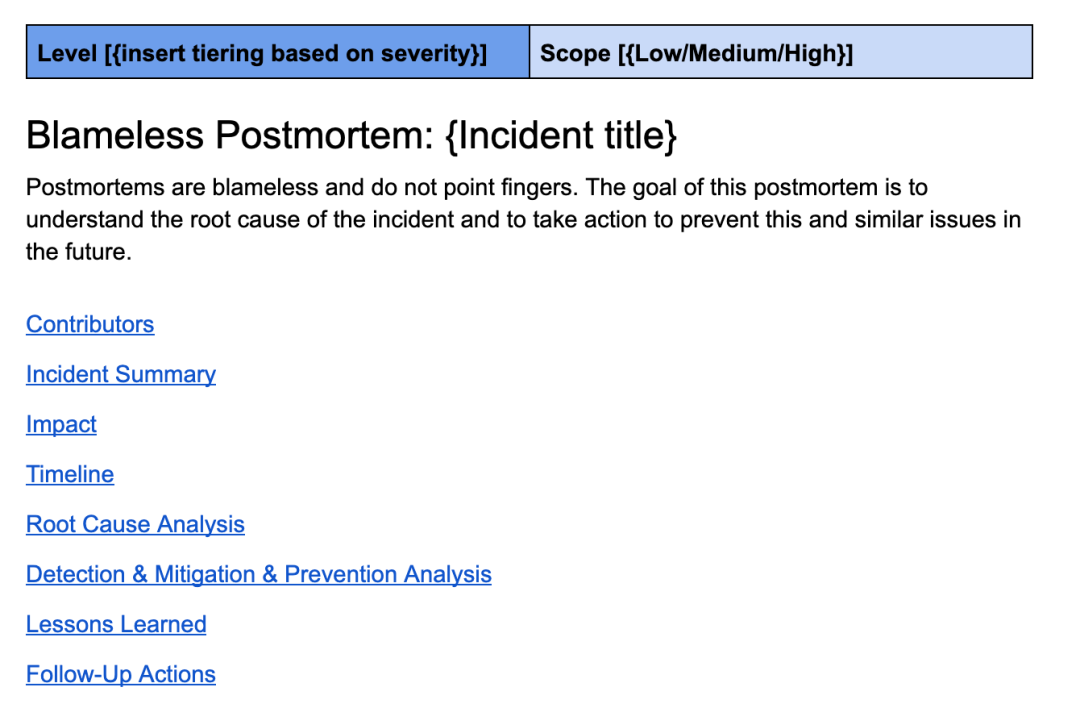
これは、私が Uber で使用しているものと同様のレビュー テンプレートです。
優れた事後分析では、根本原因を深く掘り下げ、同様の障害をすべてより迅速に防止、検出、軽減するための改善策を提案します。私が「より深く掘り下げる」と言うのは、間違ったコード変更やコードレビュー担当者がバグを発見していないという根本原因に留まらないことを意味します。
彼らは、「5why」探索手法を使用してさらに深く掘り下げ、より有意義な結論に達します。例えば:###
- なぜこの問題が発生するのでしょうか? –>コードにバグが導入されたため。
- なぜ誰もこのバグを発見しなかったのでしょうか? –> コードレビュー担当者が気付かないコード変更がこのような問題を引き起こす可能性があります。
- なぜこのエラーを発見するのにコードレビュー担当者のみに依存するのでしょうか? –> このユースケースには自動テストがないためです。
- 「このユースケースには自動テストがないのはなぜですか?」 –> テスト アカウントがないとテストが難しいためです。
- なぜテスト アカウントがないのですか? –> システムがまだサポートしていないため
- 結論: この問題は、テスト アカウントの不足によるシステムの問題を示しています。テスト アカウントのサポートをシステムに追加することをお勧めします。次に、将来の同様のコード変更すべてに対して自動テストを作成します。
イベント レビューは、イベント後の分析をサポートする重要なツールです。多くのチームは事後分析を徹底していますが、追加のインプットや予防的改善への挑戦から恩恵を受けるチームもあります。また、チームが責任を感じ、提案したシステムレベルの改善を実装する権限を与えられていると感じることも重要です。
信頼性を真剣に考える組織では、最も重大な障害が経験豊富なエンジニアによってレビューされ、問題が解決されます。特に修理に時間がかかり、他の作業に支障をきたす場合には、組織レベルのエンジニアリング管理者も立ち会い、修理を完了する権限を与える必要があります。堅牢なシステムは一夜にして実現するものではなく、継続的な反復を通じて構築されます。どうすれば反復を続けることができるでしょうか?これには、組織レベルでの継続的な改善と失敗から学ぶ文化が必要です。
障害訓練、キャパシティ プランニング、およびブラック ボックス テスト
多額の投資を必要とする日常的なアクティビティがいくつかありますが、大規模な分散システムを稼働し続けるためには不可欠です。これらは、私が Uber で初めて知った概念です。以前の会社では、当社の規模とインフラストラクチャがそうする必要がなかったため、これらを使用する必要はありませんでした。
データセンターの障害訓練は、いくつかの実際の訓練を観察するまでは退屈だと思っていました。私の最初の考えは、堅牢な分散システムを設計するということは、まさにデータセンターが崩壊した場合でも回復力を維持できるようにすることである、ということでした。理論上は問題なく動作するのであれば、なぜ頻繁にテストする必要があるのでしょうか?その答えは、規模と、新しいデータセンターでのトラフィックの突然の増加にサービスが効果的に対処できるかどうかをテストする必要性に関係しています。
私が観察した最も一般的な障害シナリオは、フェールオーバーが発生し、新しいデータ センターのサービスにグローバル トラフィックを処理するのに十分なリソースがない場合です。 ServiceA と ServiceB がそれぞれ 2 つのデータセンターから実行されていると仮定します。各データセンターで数十または数百の仮想マシンが実行されており、リソース使用率が 60% であると仮定し、70% でトリガーされるようにアラームを設定します。次に、フェイルオーバーを実行して、すべてのトラフィックを DataCenterA から DataCenterB にリダイレクトしましょう。新しいマシンをプロビジョニングしないと、DataCenterB は突然負荷を処理できなくなりました。新しいマシンのプロビジョニングには時間がかかるため、リクエストが蓄積され、ドロップされ始めることがあります。このブロックは他のサービスに影響を及ぼし始め、このフェイルオーバーの一部ではない他のシステムに連鎖的な障害を引き起こす可能性があります。
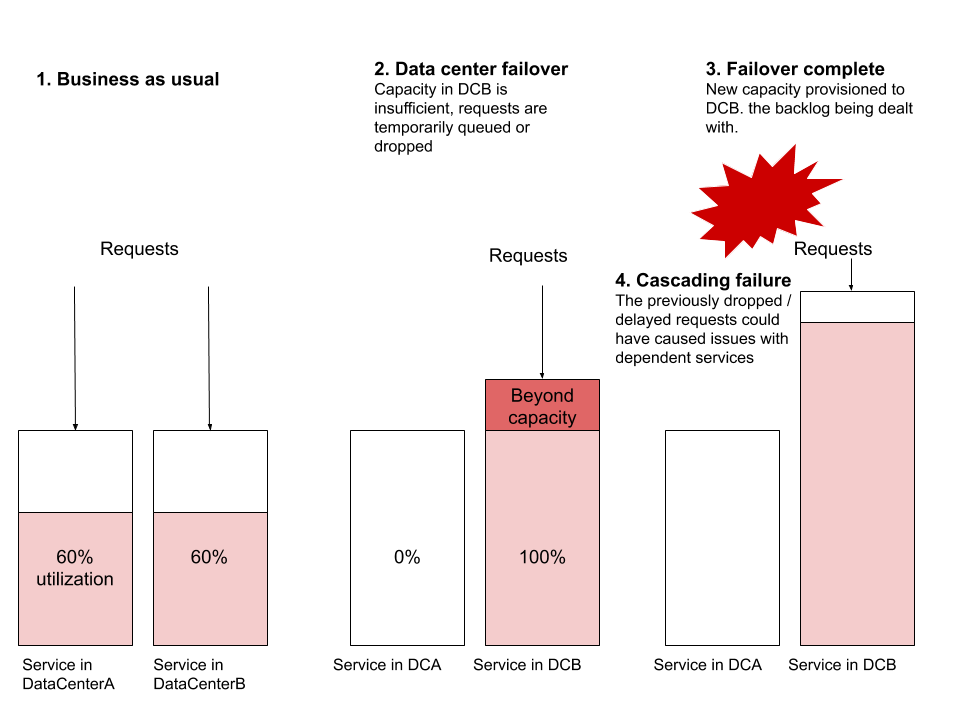
その他の一般的な障害シナリオには、ルーティング レベルの問題、ネットワーク容量の問題、バック プレッシャーの問題点などがあります。データセンターのフェイルオーバーは、信頼性の高い分散システムであれば、ユーザーに影響を与えることなく実行できるはずです。私は「すべき」ということを強調します。この演習は、分散システムの信頼性をテストするのに最も役立つ演習の 1 つです。
翻訳者注: トラフィックの削減は、計画の「3 つの軸」の 1 つです。何か問題が発生した場合に計画を確実に実行できるようにするためには、訓練が不可欠です。皆さん、気を付けてください。
計画的なサービス ダウンタイムの演習は、システム全体の回復力をテストする優れた方法です。これらは、特定のシステムの隠れた依存関係や不適切または意図しない使用を発見する優れた方法でもあります。この演習は、依存関係がほとんどない顧客向けサービスの場合は比較的簡単に実行できますが、高可用性が必要なシステムや他の多くのシステムに依存している重要なシステムの場合は、それほど簡単ではありません。しかし、この重要なシステムがある日利用できなくなったらどうなるでしょうか?すべてのチームが予期せぬ混乱を認識し、備えている管理された演習を通じて答えを検証することが最善です。
ブラック ボックス テストは、エンド ユーザーが見た状態にできるだけ近いシステムの正確さを測定する方法です。このタイプのテストはエンドツーエンドのテストに似ていますが、ほとんどの製品では、適切なブラックボックス テストを実行するには別の投資が必要です。主要なユーザー プロセスと最も一般的なユーザー向けテスト シナリオは、優れたブラック ボックス テスト容易性の例です。これらは、システムが適切に動作していることを確認するためにいつでもトリガーできるように設定されています。
Uber を例に挙げると、明らかなブラック ボックス テストは、乗客とドライバーのプロセスが都市レベルで適切に機能しているかどうかを確認することです。つまり、特定の都市内の乗客は Uber をリクエストし、ドライバーと協力して乗車を完了できるでしょうか。この状況が自動化されると、このテストを定期的に実行して、さまざまな都市をシミュレートできます。強力なブラック ボックス テスト システムを使用すると、システムまたはシステムの一部が正しく動作していることを簡単に検証できます。これは、フェイルオーバーの訓練にも非常に役立ちます。フェイルオーバーのフィードバックを取得する最も簡単な方法は、ブラック ボックス テストを実行することです。
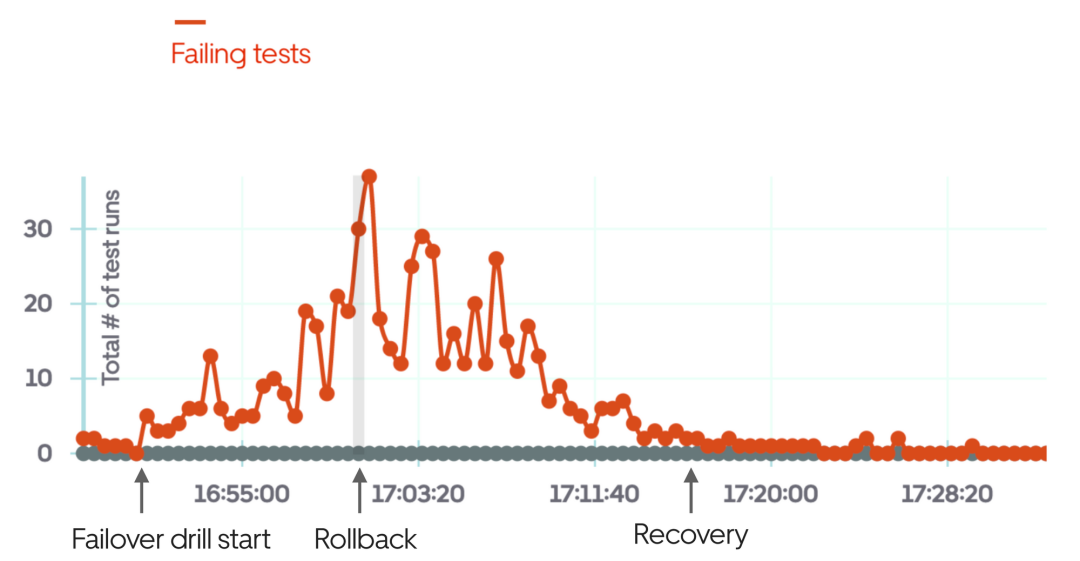
上の図は、フェールオーバー ドリルが失敗し、ドリルの数分後に手動でロールバックする場合のブラック ボックス テストの使用例です。
キャパシティプランニングは、大規模な分散システムにとっても同様に重要です。大まかに言えば、コンピューティングとストレージのコストは月に数万ドルから数十万ドルに達するということです。この規模では、固定数のデプロイメントを使用する方が、自動スケーリングのクラウド ソリューションを使用するよりも安価になる可能性があります。少なくとも、固定デプロイメントは「通常どおり」のトラフィックを処理し、ピーク負荷時に自動的にスケーリングする必要があります。しかし、次の月、次の 3 か月、そして来年に実行する必要があるインスタンスの最小数はいくつでしょうか?
良好な履歴データを使用して、成熟したシステムの将来のトラフィック パターンを予測することは難しくありません。これは、予算を立てたり、ベンダーを選択したり、クラウド プロバイダーの割引を確定したりするために重要です。サービスが高価であり、キャパシティ プランニングについて考えていない場合は、コストを削減および制御する簡単な方法を見逃していることになります。
SLO、SLA、および関連レポート
SLO は Service Level Objective の略で、システム可用性の数値目標です。個々のサービスごとにサービス レベルの SLO (容量、遅延、精度、可用性の目標など) を定義することをお勧めします。これらの SLO は、アラートのトリガーとして機能します。サービス レベル SLO の例は次のようになります。
| ##SLO メトリック
|
サブカテゴリ |
サービスの価値 |
| 容量 | #最小スループット||
|
||
予想される応答時間の中央値 |
50 ~ 90 ミリ秒 |
|
p99 の予想応答時間 |
#500-800ms | |
| #精度 |
最大エラー率 |
0.5% |
| 可用性 |
保証された稼働時間 |
99.9% |
以上がUber Practice: 大規模な分散システムの運用と保守に関する経験の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7521
7521
 15
1378
52
81
11
21
70
15
1378
52
81
11
21
70

 PHP 分散システムのアーキテクチャと実践
May 04, 2024 am 10:33 AM
PHP 分散システムのアーキテクチャと実践
May 04, 2024 am 10:33 AM
PHP 分散システム アーキテクチャは、ネットワークに接続されたマシン全体にさまざまなコンポーネントを分散することで、スケーラビリティ、パフォーマンス、およびフォールト トレランスを実現します。このアーキテクチャには、アプリケーション サーバー、メッセージ キュー、データベース、キャッシュ、ロード バランサーが含まれます。 PHP アプリケーションを分散アーキテクチャに移行する手順は次のとおりです。 サービス境界の特定 メッセージ キュー システムの選択 マイクロサービス フレームワークの採用 コンテナ管理への展開 サービスの検出
 ガイダンス: ウーバーはテスラと協力して電気自動車の普及促進に取り組み、モデル 3/Y のドライバーに最大 2,000 ドルの補助金を提供
Jan 17, 2024 am 09:42 AM
ガイダンス: ウーバーはテスラと協力して電気自動車の普及促進に取り組み、モデル 3/Y のドライバーに最大 2,000 ドルの補助金を提供
Jan 17, 2024 am 09:42 AM
1月17日のこのウェブサイトのニュースによると、ウーバーは2030年までにアメリカとカナダの都市で「ゼロエミッション」目標を達成することを目指し、より多くのアメリカのドライバーに電気自動車の導入を促進するためにテスラと協力すると発表した。ウーバーは、現行の連邦税額控除(最大7500ドル)に加え、モデル3とモデルYの購入に対して最大2000ドルの自動車購入奨励金をドライバーに提供すると発表した。この自動車購入奨励金は約14,400元に相当します。データによると、昨年末の時点で、ウーバーには米国、カナダ、欧州で合計7万4000人の現役電気自動車ドライバーがいる。 Uber のモビリティおよび事業運営担当上級副社長であるアンドリュー・マクドナルド氏は、Uber ドライバーとのコミュニケーションを通じて、車両の所有コストと充電基準がどのようなものかについて学んだと述べた。
 Golang テクノロジーを使用して分散システムを設計する場合、どのような落とし穴に注意する必要がありますか?
May 07, 2024 pm 12:39 PM
Golang テクノロジーを使用して分散システムを設計する場合、どのような落とし穴に注意する必要がありますか?
May 07, 2024 pm 12:39 PM
分散システム設計時の Go 言語の落とし穴 Go は、分散システムの開発によく使用される言語です。ただし、Go を使用する場合は注意すべき落とし穴がいくつかあり、システムの堅牢性、パフォーマンス、正確性が損なわれる可能性があります。この記事では、いくつかの一般的な落とし穴を調査し、それらを回避する方法に関する実践的な例を示します。 1. 同時実行性の過剰使用 Go は、開発者が並行性を高めるためにゴルーチンを使用することを奨励する同時実行言語です。ただし、同時実行性を過剰に使用すると、ゴルーチンがリソースをめぐって競合し、コンテキスト切り替えのオーバーヘッドが発生するため、システムが不安定になる可能性があります。実際のケース: 同時実行性の過剰な使用は、サービス応答の遅延とリソースの競合につながり、CPU 使用率の高さとガベージ コレクションのオーバーヘッドとして現れます。
 Golang 分散システムでキャッシュを使用するにはどうすればよいですか?
Jun 01, 2024 pm 09:27 PM
Golang 分散システムでキャッシュを使用するにはどうすればよいですか?
Jun 01, 2024 pm 09:27 PM
Go 分散システムでは、groupcache パッケージを使用してキャッシュを実装できます。このパッケージは、一般的なキャッシュ インターフェイスを提供し、LRU、LFU、ARC、FIFO などの複数のキャッシュ戦略をサポートします。グループキャッシュを活用すると、アプリケーションのパフォーマンスが大幅に向上し、バックエンドの負荷が軽減され、システムの信頼性が向上します。具体的な実装方法は以下の通りです。必要なパッケージのインポート、キャッシュプールサイズの設定、キャッシュプールの定義、キャッシュ有効期限の設定、同時値リクエスト数の設定、値リクエスト結果の処理を行います。
 Golang 関数を使用して分散システムでメッセージ駆動型アーキテクチャを構築する
Apr 19, 2024 pm 01:33 PM
Golang 関数を使用して分散システムでメッセージ駆動型アーキテクチャを構築する
Apr 19, 2024 pm 01:33 PM
Golang 関数を使用してメッセージ駆動型アーキテクチャを構築するには、イベント ソースの作成とイベントの生成の手順が含まれます。イベントを保存および転送するためのメッセージ キューを選択します。 Go 関数をサブスクライバーとしてデプロイして、メッセージ キューからのイベントをサブスクライブして処理します。
 高可用性分散システムを実装するための Golang ソリューション
Jan 16, 2024 am 08:17 AM
高可用性分散システムを実装するための Golang ソリューション
Jan 16, 2024 am 08:17 AM
Golang は、開発者が高可用性の分散システムを実装するのに役立つ、効率的で簡潔かつ安全なプログラミング言語です。この記事では、Golang が高可用性分散システムを実装する方法を検討し、いくつかの具体的なコード例を示します。分散システムの課題 分散システムは、複数の参加者が協力するシステムです。分散システムの参加者は、地理的位置、ネットワーク、組織構造などの複数の側面で分散された異なるノードである場合があります。分散システムを実装する場合、次のような多くの課題に対処する必要があります。
 Golang マイクロサービス フレームワークを使用して分散システムを作成する
Jun 05, 2024 pm 06:36 PM
Golang マイクロサービス フレームワークを使用して分散システムを作成する
Jun 05, 2024 pm 06:36 PM
Golang マイクロサービス フレームワークを使用して分散システムを作成します。Golang をインストールし、マイクロサービス フレームワーク (Gin など) を選択し、Gin マイクロサービスを作成し、エンドポイントを追加してマイクロサービスをデプロイし、アプリケーションを構築して実行し、注文と在庫のマイクロサービスを作成し、注文と在庫を処理するエンドポイント Kafka などのメッセージング システムを使用してマイクロサービスに接続する sarama ライブラリを使用して注文情報を生成および消費する
 ソフトウェア開発における Golang の一般的な適用シナリオは何ですか?
Dec 28, 2023 am 08:39 AM
ソフトウェア開発における Golang の一般的な適用シナリオは何ですか?
Dec 28, 2023 am 08:39 AM
Golang は開発言語として、シンプルさ、効率性、強力な同時実行パフォーマンスという特徴を備えているため、ソフトウェア開発における幅広いアプリケーション シナリオを備えています。いくつかの一般的なアプリケーション シナリオを以下に紹介します。ネットワーク プログラミング Golang はネットワーク プログラミングに優れており、特に高同時実行性と高性能サーバーの構築に適しています。豊富なネットワーク ライブラリが提供されており、開発者は TCP、HTTP、WebSocket、その他のプロトコルを簡単にプログラムできます。 Golang の Goroutine メカニズムにより、開発者は簡単にプログラミングできます
