

Google DeepMind が 10 年間のアルゴリズムの封印を破り、AlphaDev が衝撃的なデビューを果たし、人間のアルゴリズムの現状を覆します。

本日、「Alpha」ファミリーに新しいメンバー AlphaDev が追加されました。
コンピューティング エコシステム全体の基盤が、AI によって作成された新しいアルゴリズムによって破壊される可能性があります。
Google Brain と DeepMind が組み合わされて、このような素晴らしい成果が生まれるまでに時間はかかりませんでした。
AlphaDev は、並べ替えアルゴリズムを 70% 高速化できるだけでなく、一部のアルゴリズムでは人間の 3 倍も高速化することさえできます。
10 年以上で初めて、C ソート ライブラリが変更されました。 AI は世界のコードを最適化し、新たなマイルストーンに到達します。
現在、最新の研究がNature誌に掲載されています。

論文アドレス: https://www.nature.com/articles/s41586-023-06004-9
AlphaDev は、強化学習を通じて、科学者やエンジニアによる数十年にわたる慎重な磨きを直接上回る、より効率的なアルゴリズムを発見しました。
新しいアルゴリズムは 2 つの標準 C コーディング ライブラリの一部となり、世界中のプログラマーによって毎日何兆回も使用されています。
一部のネチズンは、ついにそれが来た、私たちは未知の領域に入りつつある、人工知能は人工知能を構築している、と言いました!
強化学習により 10 年にわたるアルゴリズムのボトルネックが打破されましたAlphaZero や AlphaFold などの前任者と同様に、AlphaDev も分野での変更を直接開始しました。
DeepMind コンピュータ科学者で論文の筆頭著者であるダニエル・マンコウィッツ氏は、「最初は信じられませんでした。」
「正直に言うと、私たちはそれを期待していませんでした。より良い結果が得られます: これは非常に短いプログラムであり、この種のプログラムは何十年にもわたって研究されてきました。」
現在、GPT-4 、吟遊詩人など。大規模モデルのパラメータは指数関数的に増加し、計算能力などのリソースの需要は増加し続けています。過去 50 年にわたり、人類はチップの改良に依存し続けてきました。
しかし、マイクロチップが物理的な限界に近づいているため、コンピューティングをより強力で持続可能なものにするためにコードを改善することが重要です。これは、毎日何兆ものコードを実行するアルゴリズムに特に当てはまります。
本日、Google DeepMind は、Nature に掲載された論文で初めて、Alpha ファミリーの「新興企業」である AlphaDev を紹介しました。
AlphaDev は、何十億もの人々が無意識にこれらのアルゴリズムを毎日使用している、より高速な並べ替えアルゴリズムを発見しました。
これらは、オンライン検索結果からソーシャル投稿、コンピューターや携帯電話のデータ処理方法に至るまで、あらゆるものの基礎となります。これらのアルゴリズムは毎日何兆回も実行されます。
AI を使用してより優れたアルゴリズムを生成すると、コンピューターのプログラミング方法が変わり、デジタル社会のあらゆる側面に影響を与えることになります。
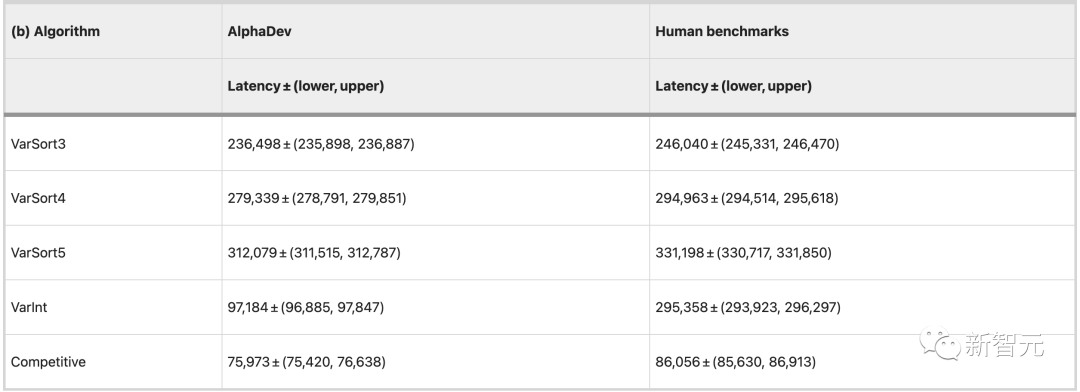
#Nature 論文のデータによると、AlphaZero が作成したアルゴリズムは人間の 3 倍の速さでデータを並べ替えることができます。
オープンソース アドレス: https://reviews.llvm.org/D118029並べ替えとは何ですか?
並べ替えは、複数の項目を特定の順序で整理する方法です。3 つの文字をアルファベット順に並べたり、5 つの数字を最大から最小の順に並べたり、何百万ものレコードを含むデータベースを並べ替えたりするのと同じです。
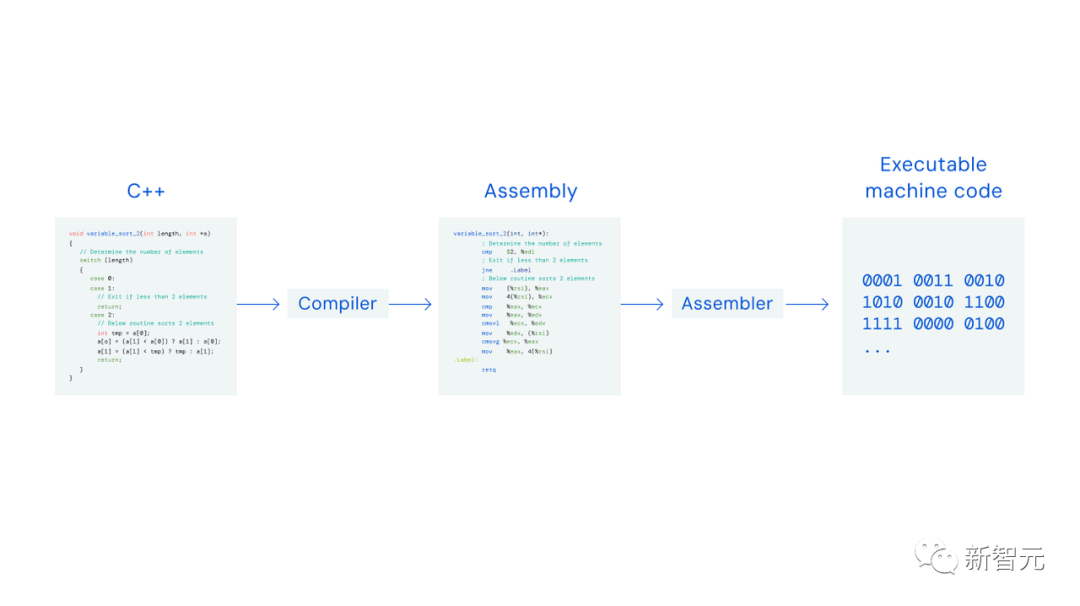
分類方法は人類の歴史を通じて進化してきました。最古の例は 2 世紀から 3 世紀に遡り、学者たちがアレクサンドリア図書館の書架に数千冊の本を手作業でアルファベット順に並べていました。 産業革命の後、私たちは分類に役立つ機械を発明しました。パンチカードに情報を保存する集計機は、1890 年の米国国勢調査の結果を収集するために使用されました。 1950 年代の商用コンピューターの台頭により、最も初期のコンピューター サイエンスの並べ替えアルゴリズムが登場しました。 現在、オンラインで大量のデータを整理するために、世界中のコード ベースでさまざまな並べ替え手法とアルゴリズムが使用されています。 # 並べ替えアルゴリズム、つまり、並べ替えられていない一連の数値を入力し、並べ替えられた数値を出力します 今日のアルゴリズムでは、コンピューター科学者やプログラマーが数十年にわたる研究開発に投資する必要があります。 これは、既存のアルゴリズムが非常に効率的であるため、前進するたびに大きな課題となるためです。 この難易度は、電気エネルギーを節約する新しい方法を見つけるか、より効率的な数学的手法を見つけるようなものです。 新しいアルゴリズムを探しています さらに、それは実際には、ほとんどの人間が思いつかないところ、つまりコンピューターの組み立て説明書から始まりました。 アセンブリ命令は、バイナリ コードを作成するために使用されます。開発者はコードを記述するときに C などの高級言語を使用しますが、コンピューターが理解できるようにするには、これらの高級言語を「低レベル」アセンブリ命令に変換する必要があります。
通常、C などの高級プログラミング言語を使用してコードを記述し、コンパイラーがそれを翻訳します。低レベルの CPU 命令、アセンブリ命令にも組み込まれます。次に、アセンブラはアセンブリ命令を実行可能なマシン コードに変換します。 この下位レベルでは、コンピューターはストレージと操作の両方においてより柔軟であるため、さらにいくつかの潜在的な改善が速度とエネルギーに大きな影響を与える可能性があります。
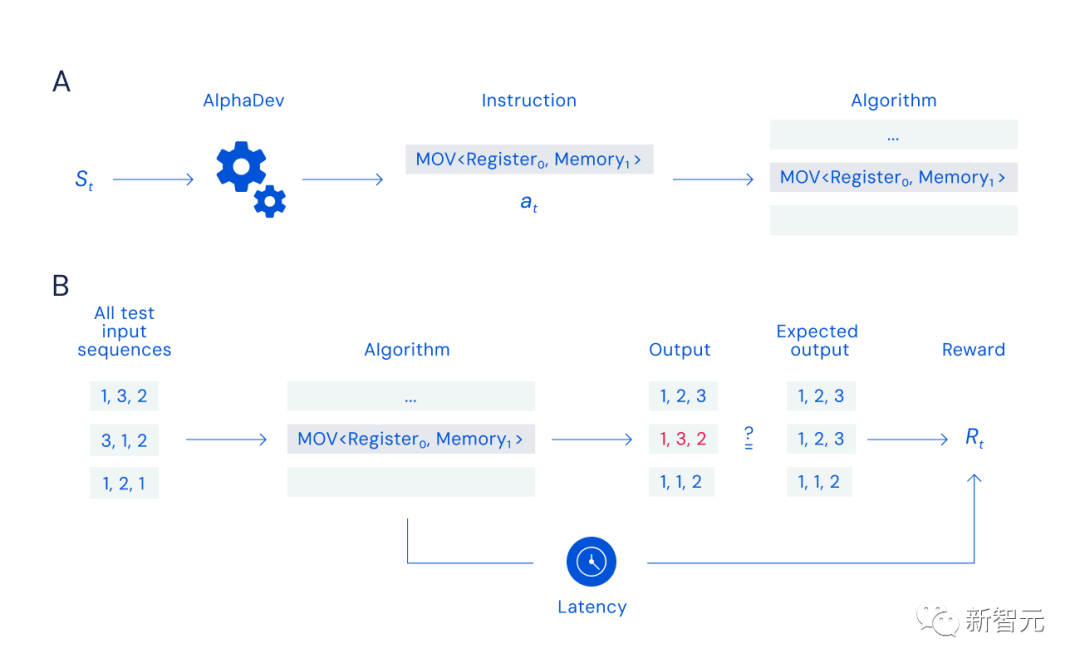
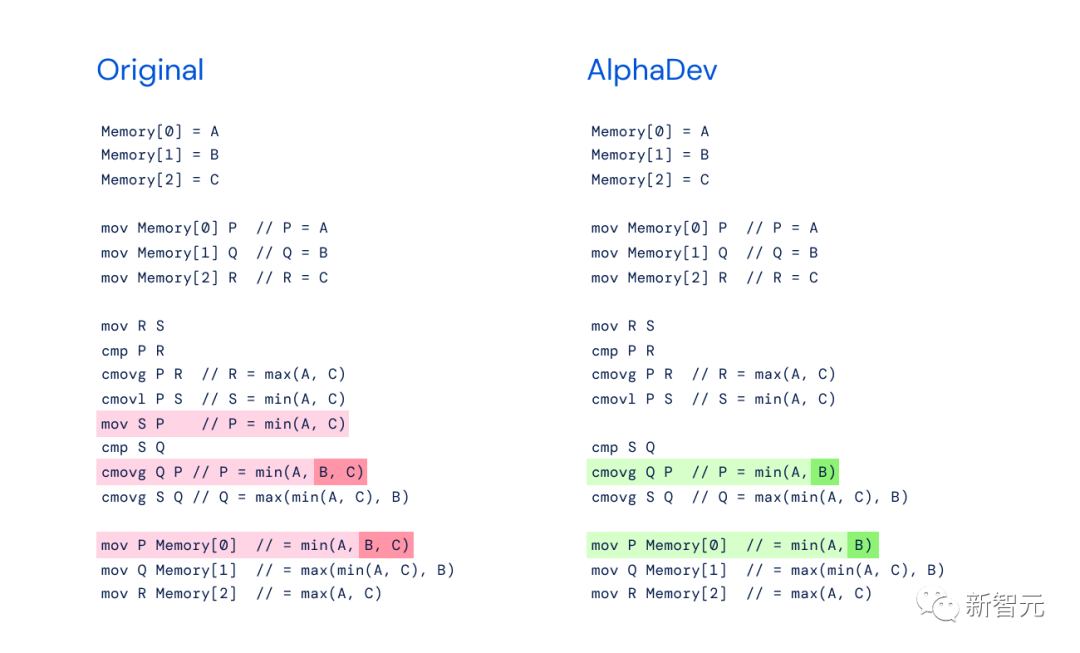
AlphaDev: AlphaZero のアセンブリ バージョン そして、今回の主人公である AlphaDev は、AlphaZero をベースにしています。 AlphaDev は、コンピューターの推論と直観を組み合わせてボード ゲームの各手を選択する、その前身である AlphaZero と同様に機能します。 ただし、AlphaDev は次にどのように移動するかを選択するのではなく、どの命令を追加するかを選択します。 AlphaDev をトレーニングして新しいアルゴリズムを発見するために、DeepMind は並べ替え問題を「組み立てゲーム」に変換しました。 各ラウンドで、AlphaDev は、生成したアルゴリズムと中央処理装置 (CPU) に含まれる情報を観察し、アルゴリズムに命令を追加して行動を起こす必要があります。 そして、このアセンブリ ゲームは非常に困難です。AlphaDev は、考えられる多数の命令の組み合わせを効率的に検索して、ソート可能で現在最適なアルゴリズムよりも高速なアルゴリズムを見つける必要があるからです。 「可能なコマンドの組み合わせ」は、宇宙内の粒子の数や、チェス (10^120 ゲーム) と囲碁 (10^700 ゲーム) の可能な組み合わせと直接比較することもできます。ゲーム)、動きの組み合わせ。 さらに、間違った動きをするとアルゴリズム全体が無効になる可能性があります。 最終的に、DeepMind は、数値を正しく並べ替える能力と、その並べ替えをいかに迅速かつ効率的に完了するかに基づいて AlphaDev に報酬を与えます。AlphaDev は、正確かつ高速な方法を発見してゲームに勝つ必要があります。プログラム。 # 図 A: 組み立てゲーム。プレーヤー AlphaDev は、システム状態 st を入力として受け取り、すでに生成されたアルゴリズムに追加するアセンブリ命令を選択することによって動きます。 図 B: 報酬の計算。各移動の後、結果として得られたアルゴリズムがテストされ、その正確さと応答時間に基づいてエージェントに報酬が与えられます。 具体的には、AlphaZero は、詳細な思考 (熟議) を行う際に、各決定点で次に考えられるアクションと、次に考えられる次のステップを検討します。樹形図のように、段階的に逆算して、どのアクションが成功する可能性が最も高いかを判断します。 しかし問題は、状況の考えられるすべての分岐を考慮すると、必要な時間は宇宙の年齢よりも長くなる可能性があるということです。そこで研究者は直感のようなものを使ってそれを絞り込みます。 各ステップで、プログラムは現在の状態をニューラル ネットワーク (複雑で調整可能な数学関数) に入力し、最も適切な動作を見つけます。同時に、トレーニング プロセス中、ニューラル ネットワークは結果に基づいて更新され続けます。場合によっては、最高評価の行動が積極的な探索の対象として意図的に選択されないことがあります。 AlphaDev が実行できるアクションは 4 つあります。これには、異なる値の比較、値の別の場所への移動、プログラムの別の部分へのジャンプなどが含まれます。 各ステップの後、一連のリストを並べ替えてみて、正しく並べ替えられたリスト内の値の数に基づいて報酬を受け取ります。 以下同様に、リスト全体がソートされるか、プログラムの長さの制限に達し、新しいプログラムが最初から開始されるまで続きます。 AlphaDev は新しい並べ替えアルゴリズムを発見し、LLVM libc 並べ替えライブラリに大幅な改善をもたらしました。 短いシーケンスの場合、スピードアップは 70% ですが、250,000 要素を超えるシーケンスの場合、スピードアップはわずか約 1.7% です。 研究者は、より短い 3 ~ 5 個の要素を使用した配列ソート アルゴリズムの改善に重点を置いています。 これらのアルゴリズムは、大規模な並べ替え関数の一部として複数回呼び出されることが多いため、最も広く使用されています。 これらのアルゴリズムを改善すると、任意の数の項目を並べ替える全体的な速度が向上します。 新しい並べ替えアルゴリズムを誰でも利用できるようにするために、研究者らはまた、このアルゴリズムをリバース エンジニアリングし、「プログラマー」が最も一般的に使用するコーディング言語である C に翻訳しました。 現在、これらのアルゴリズムは LLVM libc 標準並べ替えライブラリで利用できるようになりました。 より高速な並べ替えアルゴリズムを発見した後、DeepMind は、AlphaDev がさまざまなコンピューター サイエンス アルゴリズムを一般化して改善できるかどうかをテストしました。 - ハッシュ。 ハッシュはコンピューティングの基本的なアルゴリズムであり、データの取得、保存、圧縮に使用されます。図書館員が特定の本を見つけるために分類システムを使用するのと同じように、ハッシュ アルゴリズムは、ユーザーが探しているものと正確な場所を知るのに役立ちます。 これらのアルゴリズムは、特定のキー (ユーザー名「Jane Doe」など) をハッシュします。つまり、元のデータを一意の文字列 (1234ghfty など) に変換します。その後、コンピューターはこのハッシュ値を使用して、すべてのデータを検索するのではなく、キーに関連付けられたデータを迅速に取得します。 結果は、AlphaDev によって発見されたアルゴリズムが、ハッシュ関数の 9 ~ 16 バイト範囲に適用された場合、従来のアルゴリズムよりも 30% 高速であることを示しています。 DeepMind は、新しいハッシュ アルゴリズムをオープン ソースの Abseil ライブラリにリリースしました。このアルゴリズムは毎日何兆回も使用されることが予想されることがわかります。 AlphaDev は、より高速なアルゴリズムを発見しただけでなく、新しいメソッドも発見しました。 その並べ替えアルゴリズムは新しい一連の命令で構成されており、適用されるたびにそのうちの 1 つが保存されます。これらのアルゴリズムは毎日何兆回も使用されるため、これは大きな影響を与える可能性があります。 研究者らはこれを「AlphaDev スワップ移動」および「AlphaDev コピー移動」と呼んでいます。 最新の手法は、AlphaGo の衝撃的な「ステップ 37」を彷彿とさせます。 2016 年のマンマシン戦争で、AlphaGo は人間の直感に反する単純なショルダーチャージという手を打ち、伝説の囲碁棋士イ・セドルを破りました。 どちらの戦略でも、AlphaDev はステップをスキップし、間違っているように見えても実際には近道となる方法でプロジェクトを接続します。 これは、独自のソリューションを発見する AlphaDev の能力を実証し、コンピューター サイエンス アルゴリズムを改善する方法についての私たちの考え方に挑戦します。 下の図に示すように、元の sort3 実装には min(A, B, C) が含まれていますが、AlphaDev Swap Move を使用すると、AlphaDev は min(A, B) のみが必要であることがわかりました。 。 別の例として、元の実装では、max(B, min(A,C, D)) のより大きな並べ替えアルゴリズムを使用して 8 を並べ替えます。要素を並べ替えます。 AlphaDev は、「スワップとコピーの移動」を使用する際に必要なのは max(B, min(A, C)) だけであることを発見しました。 最適化して使用できるように展開することによってAlphaDev は、改良されたソートおよびハッシュ アルゴリズムにより、世界クラスの新しいアルゴリズムを一般化して発見する能力を実証しました。 Google DeepMind は、AlphaDev が、コンピューティング エコシステム全体を最適化し、社会に利益をもたらすその他の問題の解決に役立つ AGI ツールの開発に向けた一歩であると信じています。 ただし、研究者らは、AlphaDev は現在、低レベルのアセンブリ命令を最適化する能力に非常に優れているものの、アルゴリズムの発展に伴い限界があることも認めています。 開発者にとってより使いやすいものにするために、高級言語 (C など) でアルゴリズムを最適化する AlphaDev の機能が研究されています。 「AlphaDev スワップ移動」や「AlphaDev コピー移動」などの AlphaDev の新しい発見は、アルゴリズムを改善できるだけでなく、新しい解決策も見つけられることを示しています。 研究者らは、これらの発見が研究者や開発者に、基盤となるアルゴリズムをさらに最適化して、より強力で持続可能なコンピューティング エコシステムを構築するための技術や手法を開発するきっかけとなることを期待しています。 NVIDIA の科学者 Jim Fan が AlphaDev について詳しくまとめました: ソート アルゴリズムすべての鍵となるソフトウェアの基礎。 DeepMind の AlphaDev は、小さなシーケンス (3 ~ 5 項目) の並べ替えを 70% 高速化します。重要なポイント: - 主要な RL アルゴリズムは、もともと囲碁、チェス、将棋をプレイしていた AlphaZero に基づいています。同じ考え方が検索プログラムにも当てはまります。 #- 研究者らは C コードではなく、アセンブリ コードを最適化しました。これは、低レベルにして、保存されたすべての命令を圧縮するための意図的な選択です。 - アセンブリ コードはリバース エンジニアリングされて C に変換され、LLVM でオープンソース化されました。

ご存知のとおり、DeepMind の強化学習モデルは、囲碁、国際 チェスや将棋などのゲームで世界チャンピオンを繰り返し破ってきた。

C 実行速度が 70% 向上します

ハッシュ関数の効率が 30% 向上
2 つの新しい戦略: 「スワップ移動」と「コピー移動」


世界中のコードを一度に 1 つのアルゴリズムで最適化する
ネチズンからの熱いコメント
 #ML を使用したアルゴリズム発見でもう 1 つの大きなマイルストーンが達成されました!
#ML を使用したアルゴリズム発見でもう 1 つの大きなマイルストーンが達成されました! AlphaDev は、コア コンピューター サイエンス アルゴリズムを革新する DeepMind の革新的な人工知能です。シーケンス手法を再考し、短いシーケンスを 70% 高速化しています。ハッシュ アルゴリズムの検出速度も 30% 向上します。強化学習はアルゴリズムの状況を再構築しています。
AlphaDev は、コア コンピューター サイエンス アルゴリズムを革新する DeepMind の革新的な人工知能です。シーケンス手法を再考し、短いシーケンスを 70% 高速化しています。ハッシュ アルゴリズムの検出速度も 30% 向上します。強化学習はアルゴリズムの状況を再構築しています。  一部のネチズンは、言語モデルに興奮している一方で、他の深層学習アルゴリズムの成功事例を忘れるべきではないと言いました: AlphaZero、AlphaFold、そして今はAlphaDevです。
一部のネチズンは、言語モデルに興奮している一方で、他の深層学習アルゴリズムの成功事例を忘れるべきではないと言いました: AlphaZero、AlphaFold、そして今はAlphaDevです。
以上がGoogle DeepMind が 10 年間のアルゴリズムの封印を破り、AlphaDev が衝撃的なデビューを果たし、人間のアルゴリズムの現状を覆します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1677
1677
 14
1431
52
1334
25
1280
29
1257
24
14
1431
52
1334
25
1280
29
1257
24

 HTX公式ログインポータル登録HTX Exchange Huobi Novices登録チュートリアル2025最新バージョン
May 15, 2025 pm 04:36 PM
HTX公式ログインポータル登録HTX Exchange Huobi Novices登録チュートリアル2025最新バージョン
May 15, 2025 pm 04:36 PM
世界をリードするデジタル資産取引プラットフォームの1つとして、HTX Exchangeは、安全で便利で効率的な取引サービスを備えた多数のユーザーを引き付けました。 2025年の出現により、HTX Exchangeは登録プロセスを最適化および更新し続け、ユーザーがデジタルアセット取引をよりスムーズに体験できるようにします。この記事では、公式HTXログインポータルの登録プロセスを詳細に紹介し、初心者向けの最新の登録チュートリアルを提供して、すぐに開始できるようにします。
 VSCODEでSQLコードを作成およびテストするためのヒント
May 15, 2025 pm 09:09 PM
VSCODEでSQLコードを作成およびテストするためのヒント
May 15, 2025 pm 09:09 PM
vscodeでSQLコードの書き込みとテストは、SQLToolsとSQLServer(MSSQL)プラグインをインストールして実装できます。 1.拡張市場にプラグインをインストールします。 2。データベース接続を構成し、settings.jsonファイルを編集します。 3。SQLコードを書き込むために、構文の強調表示と自動完了を使用します。 4. CTRL/やShift Alt Fなどのショートカットキーを使用して、効率を向上させます。 5. executeQueryを右クリックして、SQLクエリをテストします。 6.説明コマンドを使用して、クエリパフォーマンスを最適化します。
 トップ10の暗号通貨交換アプリのランキングトップ10の暗号通貨交換のランキング
May 15, 2025 pm 06:27 PM
トップ10の暗号通貨交換アプリのランキングトップ10の暗号通貨交換のランキング
May 15, 2025 pm 06:27 PM
上位10の暗号通貨交換は次のとおりです。1。Binance、2。Okx、3。Huobi、4。Coinbase、5。Kraken、6。Bittrex、7。Bitfinex、8。Kucoin、9。Gemini、10。
 ピンAIとは何ですか?ピンAIの資金調達、アプリケーション、プロトコル経済、アーキテクチャの解釈
May 15, 2025 pm 06:03 PM
ピンAIとは何ですか?ピンAIの資金調達、アプリケーション、プロトコル経済、アーキテクチャの解釈
May 15, 2025 pm 06:03 PM
ピナイとは何ですか? Pinaiの資金調達はどうですか? Pinaiはどのようにデータプライバシーを革新しますか? PinaiがデジタルIDの断片化の問題をどのように解決し、分散化されたアーキテクチャを通じて真にパーソナライズされたAIサービスを提供する方法を学びます。データプライバシーの安全なエッジコンピューティングと信頼できる実行環境(TEE)の利点を調べます。以下では、Script Homeの編集者がPinaiとは何かを詳細に紹介します。およびPinaiの資金調達の状況。困っている友達、見てみましょう!今日のデジタルの世界では、個人データが主要なテクノロジーの巨人のプラットフォームに散らばっているため、ユーザーがデータを制御することが困難です。現在のAIアプリケーション
 トップ10仮想通貨取引プラットフォームランキングトップ10仮想通貨交換アプリ
May 15, 2025 pm 06:24 PM
トップ10仮想通貨取引プラットフォームランキングトップ10仮想通貨交換アプリ
May 15, 2025 pm 06:24 PM
トップ10仮想通貨取引プラットフォームランキング:1。OKX、2。Binance、3。Huobi、4。Coinbase、5。Kraken、6。Bitfinex、7。Bittrex、8。Poloniex、9。Gemini、10。Kucoin。これらのプラットフォームはすべて、さまざまなデジタル資産取引サービスを提供し、スポット、先物、レバレッジド取引をサポートし、ステーキングおよび貸付サービスを提供しています。ユーザーインターフェイスはシンプルで、モバイルアプリケーション機能は強力です。
 トップ10仮想通貨取引プラットフォームランキングトップ10仮想通貨取引プラットフォームアプリ
May 15, 2025 pm 06:39 PM
トップ10仮想通貨取引プラットフォームランキングトップ10仮想通貨取引プラットフォームアプリ
May 15, 2025 pm 06:39 PM
トップ10仮想通貨取引プラットフォームランキング:1。OKX、2。Binance、3。Huobi、4。Coinbase、5。Kraken、6。Bitfinex、7。Bittrex、8。Poloniex、9。Gemini、10。Kucoin。これらのプラットフォームはすべて、さまざまなデジタル資産取引サービスを提供し、スポット、先物、レバレッジド取引をサポートし、ステーキングおよび貸付サービスを提供しています。ユーザーインターフェイスはシンプルで、モバイルアプリケーション機能は強力です。
 収入の馬鹿げたものは何ですか? 20種類の収入stablecoins
May 15, 2025 pm 06:06 PM
収入の馬鹿げたものは何ですか? 20種類の収入stablecoins
May 15, 2025 pm 06:06 PM
ユーザーが利益の最大化を追求したい場合、利益ベースのStablecoinsを通じてStablecoinの価値を最大化できます。収益安定性は、Defiアクティビティ、デリバティブ戦略、またはRWA投資を通じてリターンを生み出す資産です。現在、このタイプのスタブコインは、2,400億米ドルのスタブコインの市場価値の6%を占めています。需要が増すにつれて、JPMorganは50%の割合が手の届かないと考えています。収入の安定コインは、担保を契約に預け入れることによって鋳造されています。預金された資金は、収入戦略への投資に使用され、収入は所有者によって共有されます。それは、預金者と預金者との利息を共有する資金を貸し出す伝統的な銀行のようなものですが、安定した収入の金利が高いことを除いて
 VSCODEプラグインマーケットのヒントと推奨事項を使用してください
May 15, 2025 pm 09:39 PM
VSCODEプラグインマーケットのヒントと推奨事項を使用してください
May 15, 2025 pm 09:39 PM
VSCODEプラグイン市場をより適切に活用するには、最初に高度な検索機能を使用してプラグインをフィルタリングし、次にプラグインをインストールしてアンインストールし、最後にプラグイン機能を最大限に活用し、定期的に維持します。 1.キーワードと高度な検索関数(評価、ダウンロード、リリース日)を使用して、プラグインをフィルタリングします。 2。[インストール]をクリックしてプラグインをインストールし、[アンインストール]をクリックしてプラグインをアンインストールします。 3.きれい、Gitlens、Liveshareプラグインを使用し、パフォーマンスを最適化するためにプラグインを定期的に確認および更新することをお勧めします。
