

500万トークンモンスター、『ハリー・ポッター』全巻を一気読み! ChatGPT の 1000 倍以上長い

メモリ不足は、現在の主流の大規模言語モデルの主な問題点です。たとえば、ChatGPT は 4096 トークン (約 3000 単語) しか入力できません。チャット中に前に言ったことをよく忘れてしまいます。読むのに十分ではない、短編小説です。
入力ウィンドウが短いため、言語モデルの適用シナリオも制限されます。たとえば、科学論文 (約 10,000 ワード) を要約する場合、記事を手動で分割する必要があります。がモデルに入力されると、異なる章間の関連情報は失われます。
GPT-4 は最大 32,000 トークンをサポートし、アップグレードされた Claude は最大 100,000 トークンをサポートしますが、脳容量不足の問題を 緩和することしかできません。
最近、 起業家チーム Magic は、最大 5 をサポートできる LTM-1 モデル を間もなくリリースすると発表しました。 million token, これは約 500,000 行のコードまたは 5,000 個のファイルであり、クロードの 50 倍です。基本的にほとんどのストレージ ニーズをカバーできます。これはまさに質的変化につながる量的変化です。 LTM-1 の主なアプリケーション シナリオはコード補完です。たとえば、より長く複雑なコードの提案を生成できます。
複数のファイルにわたって情報を再利用したり、合成したりすることもできます。
悪いニュースは、LTM-1 の開発者である Magic が具体的な技術原則を公開せず、長期記憶ネットワークという全く新しい方法を設計したとだけ述べたことです。 (LTMネット)。
しかし、良いニュースもあります。2021 年 9 月に、DeepMind と他の機関の研究者は、かつて、長期記憶 (長期記憶 ( LTM) メカニズムにより、理論的には Transformer モデルに無限のメモリを持たせることができますが、この 2 つが同じテクノロジーなのか、それとも改良版なのかは明らかではありません。

開発チームは、LTM Nets は GPT よりも多くのコンテキストを確認できるものの、LTM-1 モデルのパラメーターの数は現在の sota モデルよりもはるかに少ないため、よりインテリジェントであると述べました。低いですが、モデル サイズを大きくし続けると、LTM ネットのパフォーマンスが向上するはずです。
現在、LTM-1 はアルファ テスト アプリケーションを公開しています。
 アプリケーションリンク:
アプリケーションリンク:
https://www.php. cn/link/bbfb937a66597d9646ad992009aee405LTM-1 開発者 Magic は 2022 年に設立されました。主に GitHub Copilot に似た製品を開発しており、ソフトウェア エンジニアの作成とレビューに役立ちます。 、コードのデバッグと変更の目標は、モデルが長いコードを読み取れることが主な競争上の利点であるプログラマーのための AI 同僚を作成することです。
Magic は公益に取り組んでおり、その使命は人間の能力を超える AGI システムを構築し、安全に展開することです。現在、従業員はわずか 10 名の新興企業です。
# 今年 2 月、マジックはアルファベットの子会社である CapitalG が主導するシリーズ A 資金調達で 2,300 万米ドルを受け取りました。投資家には GitHub の元 CEO で Copilot の共同プロデューサーである Nat Friedman も含まれており、同社の資金総額は現在 2,800 万米ドルに達しています。 
Magic の CEO 兼共同創設者である Eric Steinberger は、ケンブリッジ大学を卒業してコンピューター サイエンスの学士号を取得し、FAIR で機械学習の研究を行ってきました。
スタインバーガーは、マジックを設立する前に、世界中の子供たちが気候変動の影響について学べるよう、クライメートサイエンスも設立しました。
無限メモリ トランスフォーマー
言語モデルのコア コンポーネントであるトランスフォーマーのアテンション メカニズムの設計により、長さが長くなるたびに時間計算量が増加します。入力シーケンスの増加 二次成長。
アルゴリズムの複雑さを軽減するために、スパース アテンションなど、アテンション メカニズムのいくつかの変形がすでに存在していますが、その複雑さは依然として入力長に関連しており、考慮することはできません。無限に広がる。
∞-前 長期記憶 (LTM) の鍵となる入力シーケンスを無限に拡張できる Transformer モデルは、表現の粒度を減らす連続空間注意フレームワークです 数値を増やしますメモリ情報単位(基底関数)の。
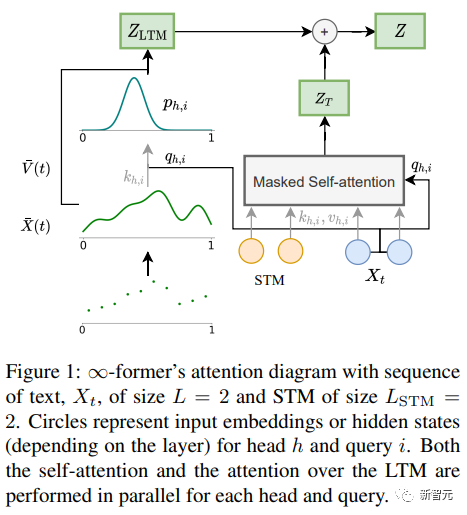
#フレームワークでは、入力シーケンスは、N 個の動径基底関数 ( RBF ) を表す「連続信号」として表されます。 )、このようにして、∞-former の注意の複雑さは O(L^2 L × N) に削減されますが、元の Transformer の注意の複雑さは O(Lx(L L_LTM)) です。ここで、L と L_LTM は対応します。それぞれ、Transformer の入力サイズと長期メモリの長さに応じて変化します。
#この表現方法には 2 つの主な利点があります:
#1. コンテキストは、基底関数 N によって表現できます。トークンの数、減少 アテンションの計算コストが削減されます;
2. N を固定できるため、アテンション メカニズムの複雑さを増すことなく、メモリ内で無制限のコンテキストを表すことができます。

もちろん、世界にはフリーランチは存在せず、その代償として解像度が低下します。基底関数の数が少ないと、入力シーケンスを連続信号として表すときに精度が低下する可能性があります。
解像度低下の問題を軽減するために、研究者は「スティッキー メモリ」の概念を導入しました。これは、LTM 信号内のより大きなスペースを、より頻繁にアクセスされるメモリ領域に帰属させるという概念を作成しました。これにより、モデルは関連情報を失うことなく、長期的な背景をより適切に捕捉できるようになります。また、脳の長期的な可能性と可塑性にも影響を受けています。
実験部分
∞-formerが長いコンテキストをモデル化できるかどうかを検証するために、研究者は最初に実験を行います。長いシーケンス内の頻度によってトークンを並べ替える合成タスクが実行され、その後、事前にトレーニングされた言語モデルを微調整することによって、言語モデリングとドキュメントベースの対話生成に関する実験が実行されます。
#Sort
入力は、確率分布に従ってサンプリングされたトークンで構成されます (システムには不明) シーケンスの場合、目標はシーケンス内の頻度の降順でトークンを生成することです
語彙には 20 のトークンがあり、それぞれ 4,000、8,000、16,000 の長さのシーケンスで実験が行われました。Transformer-XL と圧縮トランスは比較のためのベースライン モデルとして使用されました。
#
実験結果から、シーケンス長が短い (4,000) 場合、Transformer-XL は他のモデルよりわずかに高い精度を実現しますが、シーケンス長が増加すると精度も急激に低下することがわかります。 ∞ 前者と比較して、この減少は明らかではありません。これは、長いシーケンスをモデル化する際に、より多くの利点があることを示しています。
言語モデリング
長期記憶を拡張に使用できるかどうかを理解する言語モデルについては、研究者らは約 2 億個のトークンを含む Wikitext103 と PG-19 のサブセット上で GPT-2 を微調整しました。
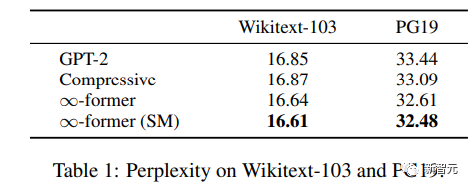
実験結果から、∞-former は Wikitext-103 と PG19 の混乱を軽減できることがわかります。 - 書籍はウィキペディアの記事よりも長期記憶に依存するため、前者によって得られる改善は PG19 データセットでより大きくなります。
#ドキュメントベースのダイアログ
ドキュメントベースのダイアログ生成では、「追加」を除きます。会話履歴に基づいて、モデルは会話のトピックに関するドキュメントを取得することもできます。
CMU Document Grounded Conversation データセット (CMU-DoG) では、会話は映画についてであり、映画の概要は補助ドキュメントとして提供されます。会話には以下の内容が含まれていると考えられます。複数の異なる連続的な会話では、補助文書はいくつかの部分に分割されます。
長期記憶の有用性を評価するために、研究者らは、会話が始まる前にのみモデルにファイルへのアクセスを許可することで、タスクをより困難にしました。
GPT-2 を小さく微調整した後、モデルがドキュメント全体をメモリ内に保持できるようにするために、N=512 基底関数を持つ連続 LTM (∞-former) は次のようになります。 GPT -2 を拡張するために使用されます。
モデルの効果を評価するには、パープレキシティ、F1 スコア、Rouge-1 および Rouge-L、および Meteor インジケーターを使用します。
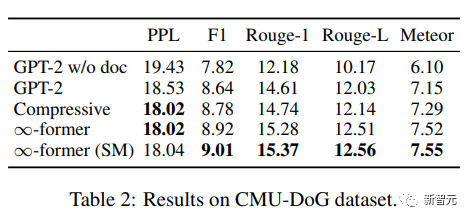
結果から、∞-former と compressive Transformer の方がより良いコーパスを生成できますが、両者の程度は混同されています。基本的には同じですが、他の指標では ∞-former の方が良いスコアを達成しています。
以上が500万トークンモンスター、『ハリー・ポッター』全巻を一気読み! ChatGPT の 1000 倍以上長いの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7488
7488
 15
1377
52
77
11
19
40
15
1377
52
77
11
19
40

 SQLクリアテーブル:パフォーマンスの最適化のヒント
Apr 09, 2025 pm 02:54 PM
SQLクリアテーブル:パフォーマンスの最適化のヒント
Apr 09, 2025 pm 02:54 PM
SQLテーブルクリアパフォーマンスを改善するためのヒント:削除の代わりにTruncateテーブルを使用し、スペースを解放し、ID列をリセットします。カスケードの削除を防ぐために、外部のキーの制約を無効にします。トランザクションカプセル化操作を使用して、データの一貫性を確保します。バッチはビッグデータを削除し、制限で行数を制限します。クリアリング後にインデックスを再構築して、クエリ効率を改善します。
 削除ステートメントを使用して、SQLテーブルをクリアします
Apr 09, 2025 pm 03:00 PM
削除ステートメントを使用して、SQLテーブルをクリアします
Apr 09, 2025 pm 03:00 PM
はい、削除ステートメントを使用してSQLテーブルをクリアできます。手順は次のとおりです。クリアするテーブルの名前にtable_nameを置き換えます。
 phpmyAdminはデータテーブルを作成します
Apr 10, 2025 pm 11:00 PM
phpmyAdminはデータテーブルを作成します
Apr 10, 2025 pm 11:00 PM
phpMyAdminを使用してデータテーブルを作成するには、次の手順が不可欠です。データベースに接続して、[新しいタブ]をクリックします。テーブルに名前を付けて、ストレージエンジンを選択します(InnoDB推奨)。列名、データ型、null値、その他のプロパティを許可するかどうかなど、列の追加ボタンをクリックして列の詳細を追加します。一次キーとして1つ以上の列を選択します。 [保存]ボタンをクリックして、テーブルと列を作成します。
 Redisメモリの断片化に対処する方法は?
Apr 10, 2025 pm 02:24 PM
Redisメモリの断片化に対処する方法は?
Apr 10, 2025 pm 02:24 PM
Redisメモリの断片化とは、再割り当てできない割り当てられたメモリ内に小さな自由領域の存在を指します。対処戦略には、Redisの再起動:メモリを完全にクリアしますが、サービスを割り当てます。データ構造の最適化:Redisに適した構造を使用して、メモリの割り当てとリリースの数を減らします。構成パラメーターの調整:ポリシーを使用して、最近使用されていないキー価値ペアを排除します。永続性メカニズムを使用します:データを定期的にバックアップし、Redisを再起動してフラグメントをクリーンアップします。メモリの使用量を監視する:問題をタイムリーに発見し、対策を講じる。
 Oracleデータベースの作成方法Oracleデータベースを作成する方法
Apr 11, 2025 pm 02:33 PM
Oracleデータベースの作成方法Oracleデータベースを作成する方法
Apr 11, 2025 pm 02:33 PM
Oracleデータベースを作成するのは簡単ではありません。根本的なメカニズムを理解する必要があります。 1.データベースとOracle DBMSの概念を理解する必要があります。 2。SID、CDB(コンテナデータベース)、PDB(プラグ可能なデータベース)などのコアコンセプトをマスターします。 3。SQL*Plusを使用してCDBを作成し、PDBを作成するには、サイズ、データファイルの数、パスなどのパラメーターを指定する必要があります。 4.高度なアプリケーションは、文字セット、メモリ、その他のパラメーターを調整し、パフォーマンスチューニングを実行する必要があります。 5.ディスクスペース、アクセス許可、パラメーター設定に注意し、データベースのパフォーマンスを継続的に監視および最適化します。 それを巧みに習得することによってのみ、継続的な練習が必要であることは、Oracleデータベースの作成と管理を本当に理解できます。
 Oracleデータベースの作成方法Oracleデータベースの作成方法
Apr 11, 2025 pm 02:36 PM
Oracleデータベースの作成方法Oracleデータベースの作成方法
Apr 11, 2025 pm 02:36 PM
Oracleデータベースを作成するには、一般的な方法はDBCAグラフィカルツールを使用することです。手順は次のとおりです。1。DBCAツールを使用してDBNAMEを設定してデータベース名を指定します。 2. SyspasswordとSystemPassWordを強力なパスワードに設定します。 3.文字セットとNationalCharactersetをAL32UTF8に設定します。 4.実際のニーズに応じて調整するようにMemorySizeとTableSpacesizeを設定します。 5. logfileパスを指定します。 高度な方法は、SQLコマンドを使用して手動で作成されますが、より複雑でエラーが発生しやすいです。 パスワードの強度、キャラクターセットの選択、表空間サイズ、メモリに注意してください
 Redis ExporterサービスでRedis Dropletを監視します
Apr 10, 2025 pm 01:36 PM
Redis ExporterサービスでRedis Dropletを監視します
Apr 10, 2025 pm 01:36 PM
Redisデータベースの効果的な監視は、最適なパフォーマンスを維持し、潜在的なボトルネックを特定し、システム全体の信頼性を確保するために重要です。 Redis Exporter Serviceは、Prometheusを使用してRedisデータベースを監視するために設計された強力なユーティリティです。 このチュートリアルでは、Redis Exporterサービスの完全なセットアップと構成をガイドし、監視ソリューションをシームレスに構築します。このチュートリアルを研究することにより、完全に動作する監視設定を実現します
 Redisメモリ構成パラメーターとは何ですか?
Apr 10, 2025 pm 02:03 PM
Redisメモリ構成パラメーターとは何ですか?
Apr 10, 2025 pm 02:03 PM
** Redisメモリ構成のコアパラメーターはMaxMemoryであり、Redisが使用できるメモリの量を制限します。この制限を超えると、Redisは、Maxmemory-Policyに従って除去戦略を実行します。これには、次のようになります。その他の関連パラメーターには、Maxmemory-Samples(LRUサンプル量)、RDB圧縮が含まれます
