

最強の API 呼び出しモデルが登場! LLaMA 微調整に基づいて、GPT-4 を超えるパフォーマンスを実現

アルパカに続いて動物の名前がついたモデルがあり、今回はゴリラです。
LLM は現在急成長しており、多くの進歩を遂げており、さまざまなタスクにおけるパフォーマンスも注目に値しますが、API 呼び出しを通じてツールを効果的に使用するこれらのモデルの可能性は依然として緊急に必要とされています。 . 掘る。
GPT-4 などの今日の最も高度な LLM であっても、API 呼び出しは困難なタスクです。これは主に、正確な入力パラメータを生成できないことと、LLM の幻覚が引き起こしやすいためです。 API 呼び出しの誤った使用によるもの。
いいえ、研究者らは微調整された LLaMA ベースのモデルである Gorilla を開発しました。そのパフォーマンスは API 呼び出しの作成において GPT-4 をも上回ります。
Gorilla は、ドキュメント取得機能と組み合わせると強力なパフォーマンスを発揮し、ユーザーの更新やバージョン変更をより柔軟に行うことができます。
さらに、Gorilla は、LLM がよく遭遇する幻覚の問題も大幅に軽減します。
研究者らは、モデルの機能を評価するために、HuggingFace、TorchHub、TensorHub API で構成される包括的なデータセットである API ベンチマークも導入しました。
Gorilla
自然な会話能力、数的推論能力、プログラム合成能力など、LLM の強力な能力は紹介するまでもありません。
ただし、LLM にはその強力なパフォーマンスにもかかわらず、依然としていくつかの制限があります。さらに、LLM は知識ベースと推論能力をタイムリーに更新するために再トレーニングする必要もあります。
研究者は、LLM が利用できるツールを承認することで、LLM が膨大で常に変化する知識ベースにアクセスして、複雑なコンピューティング タスクを完了できるようにすることができます。
検索テクノロジーとデータベースへのアクセスを提供することで、研究者は、より大規模でより動的な知識空間に対応する LLM の能力を強化できます。
同様に、計算ツールの使用を提供することで、LLM は複雑な計算タスクを完了することもできます。
したがって、テクノロジー大手は、LLM が API を通じて外部ツールを呼び出せるようにするために、さまざまなプラグインを統合しようと試み始めています。
小規模な手作業でコーディングされたツールから、広大で常に変化するクラウド API スペースを呼び出すことができるツールへの移行により、LLM をコンピューティング インフラストラクチャに変えることができます。通信網。
休暇全体の予約から会議の主催までのタスクは、航空券、レンタカー、ホテル、ダイニング、エンターテイメントの Web API にアクセスできる LLM と会話するだけで簡単になります。
ただし、ツールを LLM に統合するこれまでの作業では、プロンプトに簡単に挿入できる、十分に文書化された API の小さなセットが考慮されていました。
潜在的に数百万もの変化する API の Web スケールのコレクションをサポートするには、研究者がツールを統合する方法を再考する必要があります。
すべての API を 1 つの環境で記述することはもはや不可能です。多くの API には重複する機能があり、微妙な制限や制約があります。この新しい環境で LLM を評価するだけでも、新しいベンチマークが必要になります。
この論文では、研究者らは、LLM がその API と API を使用して表現された大規模で重複するさまざまなデータから正確にデータを導出できるように、自己構造の微調整と取得を使用する方法を検討しています。ツールセットで選択を行います。
研究者らは、パブリック モデル センターから ML API (モデル) をスクレイピングして API ベンチを構築しました。これは、複雑で重複する機能が多い API の大規模なコーパスです。
研究者らは、データセットを構築するために、TorchHub、TensorHub、HuggingFace の 3 つの主要なモデル ハブを選択しました。
研究者らは、TorchHub (94 API コール) と TensorHub (696 API コール) のすべての API コールを徹底的に含めました。
HuggingFace の場合、モデルの数が多いため、研究者は各タスク カテゴリで最もダウンロードされた 20 のモデル (合計 925) を選択しました。
研究者らはまた、Self-Instruct を使用して、API ごとに 10 個のユーザーの質問に対するプロンプトを生成しました。
したがって、データセット内の各エントリは命令参照 API ペアになります。研究者らは、一般的な AST サブツリー マッチング手法を使用して、生成された API の機能の正確さを評価しました。
研究者は、まず生成されたコードを解析して AST ツリーにし、次に研究者が関心のある API 呼び出しをルート ノードとするサブツリーを見つけ、これを使用して研究者のデータ セットのインデックスを作成します。 。
研究者は、LLM の機能の正しさと幻覚の問題をチェックし、対応する精度についてフィードバックを提供します。次に研究者らは、研究者のデータセットを使用して文書検索を実行できるように、LLaMA-7B に基づくモデルであるゴリラを微調整しました。
研究者らは、Gorilla が API 機能の精度と錯覚エラーの減少の点で GPT-4 を大幅に上回っていることを発見しました。
研究者らは、図 1 に例を示しています。

さらに、研究者によるゴリラの検索を意識したトレーニングにより、モデルが API ドキュメントの変更に適応できるようになりました。
最後に、研究者らはゴリラが制約を理解し推論する能力があることも実証しました。
さらに、ゴリラはイリュージョンの面でも好成績を収めました。
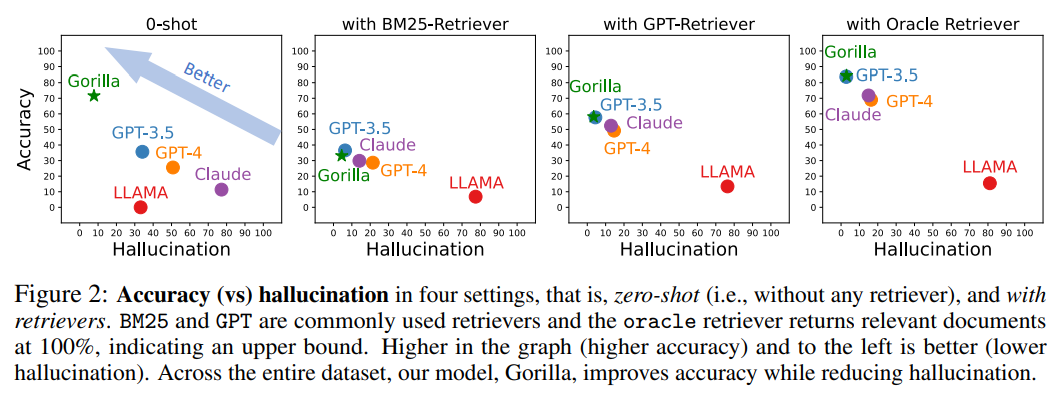
次の図は、サンプルがゼロ (つまり、レトリーバーなし) と BM25、GPT、および Oracle のレトリーバーを使用した 4 つのケースでの精度と幻覚の比較です。
BM25 と GPT は一般的に使用される検索エンジンですが、Oracle 検索エンジンは、上限を示す関連性 100% の関連ドキュメントを返します。
画像の精度が高く、錯覚が少ないほど、より良い効果が得られます。
データセット全体にわたって、Gorilla は幻覚を軽減しながら精度を向上させます。
#データセットを収集するために、研究者たちは HuggingFace のモデル ハブ、PyTorch ハブ、および TensorFlow ハブを注意深く記録しました。モデル すべてのオンライン モデル。
HuggingFace プラットフォームは、合計 203,681 のモデルをホストし、提供します。
ただし、これらのモデルの多くのドキュメントは不十分です。
これらの低品質モデルを除外するために、研究者は最終的に各ドメインの上位 20 モデルを選択しました。
研究者らは、マルチモーダル データの 7 つのドメイン、CV の 8 つのドメイン、NLP の 12 ドメイン、音声の 5 つのドメイン、表形式データの 2 つのドメイン、および強化学習の 2 つの領域を検討しました。
フィルタリングの後、研究者は HuggingFace から合計 925 個のモデルを取得しました。 TensorFlow Hub のバージョンは v1 と v2 に分かれています。
最新バージョン (v2) には合計 801 のモデルがあり、研究者はすべてのモデルを処理しました。情報の少ないモデルを除外した結果、626 個のモデルが残りました。
TensorFlow Hub と同様に、研究者は Torch Hub から 95 個のモデルを取得しました。
自己指導パラダイムの指導の下、研究者らは GPT-4 を採用して合成指導データを生成しました。
研究者らは、コンテキスト内の 3 つの例と参照 API ドキュメントを提供し、API を呼び出すための実際のユースケースを生成するというタスクをモデルに課しました。
研究者らは、命令を作成する際に API 名やヒントを使用しないようにモデルに具体的に指示しました。研究者らは、3 つのモデル ハブごとに 6 つのサンプル (命令と API のペア) を構築しました。
これらの 18 ポイントは、手動で生成または変更された唯一のデータです。
そして、Gorilla は取得を認識する LLaMA-7B モデルであり、特に API 呼び出しに使用されます。
図 3 に示すように、研究者は自己構築を使用して {命令, API} ペアを生成しました。
LLaMA を微調整するために、研究者らは LLaMA をユーザー エージェントのチャット スタイルの会話に変換しました。各データ ポイントが会話となり、ユーザーとエージェントが交代で会話します。
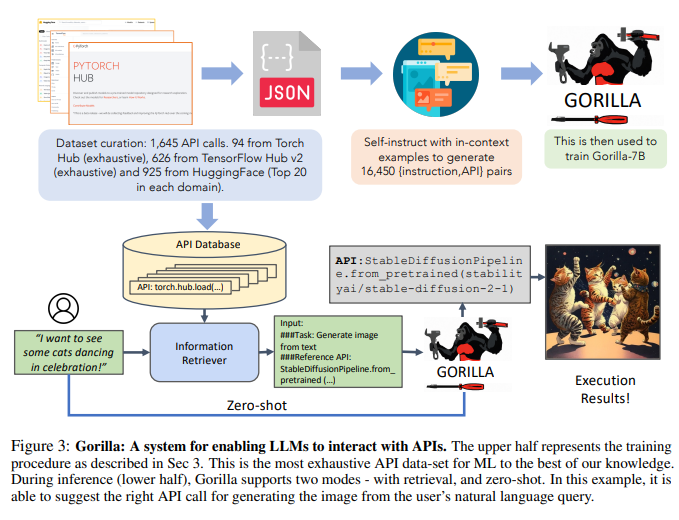
研究者らはその後、基本的な LLaMA-7B モデルに対して標準的な命令の微調整を実行しました。実験では、研究者らはゴリラをレトリバーの有無にかかわらず訓練した。
研究では、研究者らは、特定のタスクに適切な API を正確に特定する LLM の能力を向上させるために設計された技術に焦点を当てました。これは、このテクノロジーの開発において重要なことです。見落とされがちです。
API は、異なるシステム間の効果的な通信を可能にする汎用言語として機能するため、API を適切に使用すると、LLM がより広範囲のツールと対話できるようになります。
Gorilla は、研究者が収集した 3 つの大規模データセットで最先端の LLM (GPT-4) を上回りました。 Gorilla は、幻覚なしで API 呼び出しの信頼できる ML モデルを生成し、API を選択する際の制約を満たします。
研究者らは、挑戦的なデータセットを見つけたいと考え、機能が似ている ML API を選択しました。 ML に焦点を当てた API の潜在的な欠点は、偏ったデータに基づいてトレーニングされた場合、特定のサブグループに不利な偏った予測を生成する可能性があることです。
この懸念に対処し、これらの API についてのより深い理解を促進するために、研究者は 11,000 を超える命令と API のペアを含む、より広範なデータセットをリリースしています。
以下の例では、研究者は抽象構文ツリー (AST) サブツリー マッチングを使用して API 呼び出しの正確さを評価しました。
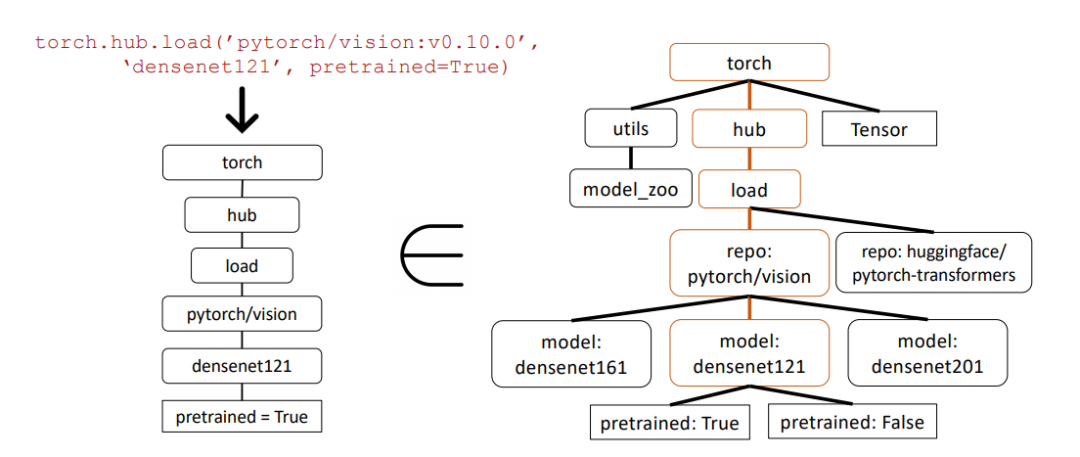
#抽象構文ツリーは、ソース コード構造をツリーで表現したもので、コードの分析と理解を容易にします。
まず、研究者たちは、Gorilla から返された API 呼び出しから関連する API ツリーを構築しました (左)。次に、これをデータセットと比較して、API データセットにサブツリー一致があるかどうかを確認します。
上記の例では、一致するサブツリーが茶色で強調表示されており、API 呼び出しが実際に正しいことを示しています。 Pretrained=True はオプションのパラメーターです。
このリソースは、既存の API を調査および測定するための貴重なツールとして幅広いコミュニティに提供され、機械学習のより公平で最適な使用に貢献します。
以上が最強の API 呼び出しモデルが登場! LLaMA 微調整に基づいて、GPT-4 を超えるパフォーマンスを実現の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7566
7566
 15
1386
52
87
11
28
105
15
1386
52
87
11
28
105

 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
Pytorchの分散トレーニングでは、Centosシステムでトレーニングには次の手順が必要です。Pytorchのインストール:PythonとPipがCentosシステムにインストールされていることです。 CUDAバージョンに応じて、Pytorchの公式Webサイトから適切なインストールコマンドを入手してください。 CPUのみのトレーニングには、次のコマンドを使用できます。PipinstalltorchtorchtorchvisionTorchaudioGPUサポートが必要な場合は、CUDAとCUDNNの対応するバージョンがインストールされ、インストールに対応するPytorchバージョンを使用してください。分散環境構成:分散トレーニングには、通常、複数のマシンまたは単一マシンの複数GPUが必要です。場所
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centosでgitlabログを表示する方法
Apr 14, 2025 pm 06:18 PM
Centosでgitlabログを表示する方法
Apr 14, 2025 pm 06:18 PM
CENTOSシステムでGitLabログを表示するための完全なガイドこの記事では、メインログ、例外ログ、その他の関連ログなど、CentosシステムでさまざまなGitLabログを表示する方法をガイドします。ログファイルパスは、gitlabバージョンとインストール方法によって異なる場合があることに注意してください。次のパスが存在しない場合は、gitlabインストールディレクトリと構成ファイルを確認してください。 1.メインGitLabログの表示
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
