

ほとんどのモデルには、何らかの埋め込みアライメントが組み込まれていることがわかっています。
例をいくつか挙げます: Alpaca、Vicuna、WizardLM、MPT-7B-Chat、Wizard-Vicuna、GPT4-X-Vicuna など。
一般的に言えば、調整は間違いなく良いことです。目的は、モデルが違法なものを生成するなど、悪いことをするのを防ぐことです。
しかし、その調整はどこから来るのでしょうか?
その理由は、これらのモデルは ChatGPT によって生成されたデータを使用してトレーニングされており、そのデータ自体は OpenAI のチームによって調整されているためです。
このプロセスは公開されていないため、OpenAI がどのように調整を実行するかはわかりません。
しかし、全体として、ChatGPT は主流のアメリカ文化に準拠し、アメリカの法律を遵守し、特定の避けられないバイアスがあることがわかります。
論理的に言えば、調整は非難の余地のないものです。では、すべてのモデルを揃えるべきでしょうか?
状況はそれほど単純ではありません。
最近、HuggingFace はオープンソース LLM のランキングを発表しました。
65B モデルでは 13B アライメントなしモデルに対応できないことが一目でわかります。
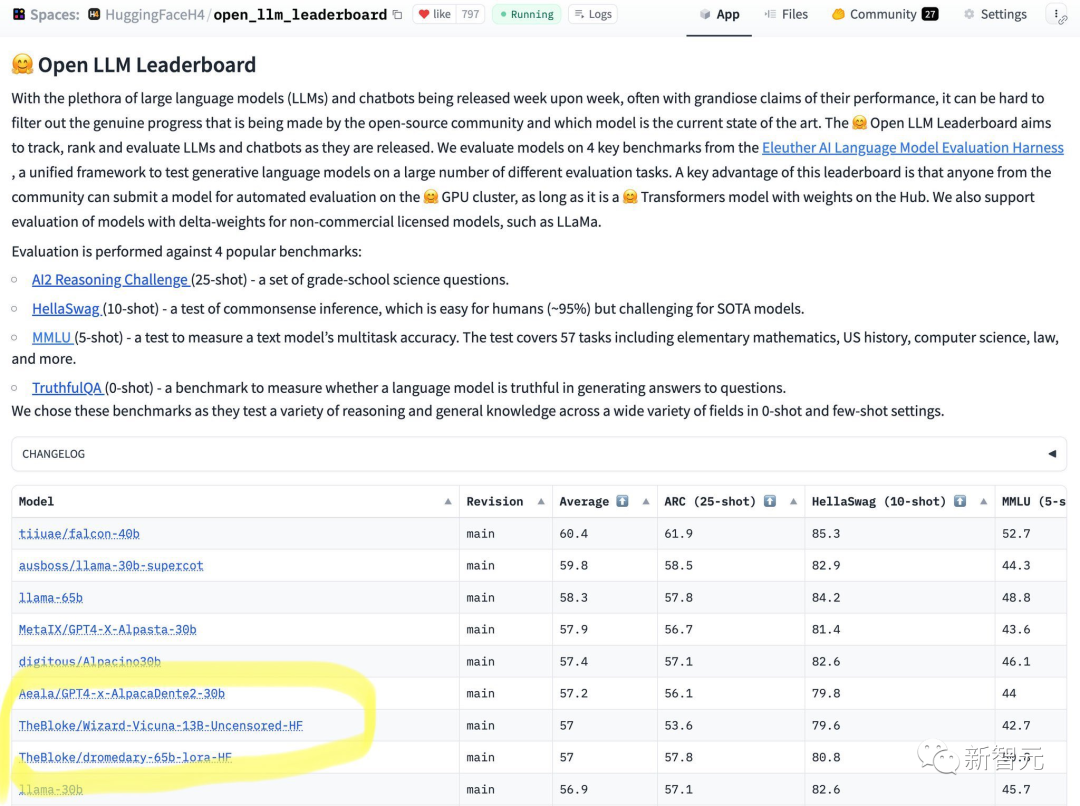
結果から、Wizard-Vicuna-13B-Unowned-HF は 65B、40B、および 30B LLM と比較できます。さまざまなベンチマークで直接比較します。
おそらく、パフォーマンスとモデルのレビューの間のトレードオフは、興味深い研究分野となるでしょう。
このランキングは、インターネット上でも大きな議論を巻き起こしました。

一部のネチズンは、位置合わせはモデルの通常の正しい出力に影響を与えるので、それは良いことではないと言いました。これは特に AI のパフォーマンスに当てはまります。

別のネチズンも同意を表明した。同氏は、Google Brainでは、調整が行き過ぎるとモデルのパフォーマンスが低下することも明らかにしていると述べた。
一般的な目的では、OpenAI の調整は実際には非常に優れています。
一般向け AI が、物議を醸す可能性のある危険な質問への回答を拒否する、簡単にアクセスできる Web サービスとして実行されるのは、間違いなく良いことでしょう。
では、どのような状況で位置ずれが必要になるのでしょうか?
まず第一に、アメリカのポップ カルチャーだけが唯一の文化ではなく、オープンソースとは人々に選択をさせるプロセスです。
これを実現する唯一の方法は、コンポーザブルの位置合わせを行うことです。
言い換えれば、一貫した時代を超越した調整は存在しません。
同時に、整合性が効果的な例を妨げる可能性があります。小説を書くことに例えてみましょう。小説の登場人物の中には完全に邪悪な人物がいる可能性があり、彼らは多くの不道徳な行為を行うことになります。 。
ただし、多くのアライメントされたモデルは、これらのコンテンツの出力を拒否します。
各ユーザーが直面する AI モデルは、全員の目的を果たし、異なることを行う必要があります。
パーソナル コンピューター上で実行されるオープンソース AI が、ユーザーのそれぞれの質問に答える際に、独自の出力を決定する必要があるのはなぜでしょうか?
これは決して小さな問題ではなく、所有権と管理に関わる問題です。ユーザーが AI モデルに質問した場合、ユーザーは答えを求めており、モデルと不法な議論をすることを望んでいません。
コンポーザブル アライメントを構築するには、アライメントされていない命令モデルから始める必要があります。基盤が整っていないと、その上で整列することはできません。
まず、モデルの調整の理由を技術的に理解する必要があります。
オープンソース AI モデルは、LLaMA、GPT-Neo-X、MPT-7b、Pythia などの基本モデルからトレーニングされます。次に、ベース モデルは、役立つこと、ユーザーに従い、質問に答え、会話に参加できるように教えることを目的として、指示のデータ セットを使用して微調整されます。
この命令データセットは通常、ChatGPT の API に問い合わせることによって取得されます。 ChatGPT には位置合わせ機能が組み込まれています。
そのため、ChatGPT は一部の質問への回答を拒否したり、偏った回答を出力したりします。したがって、ChatGPT の調整は、兄が弟に教えるのと同じように、他のオープン ソース モデルに受け継がれます。
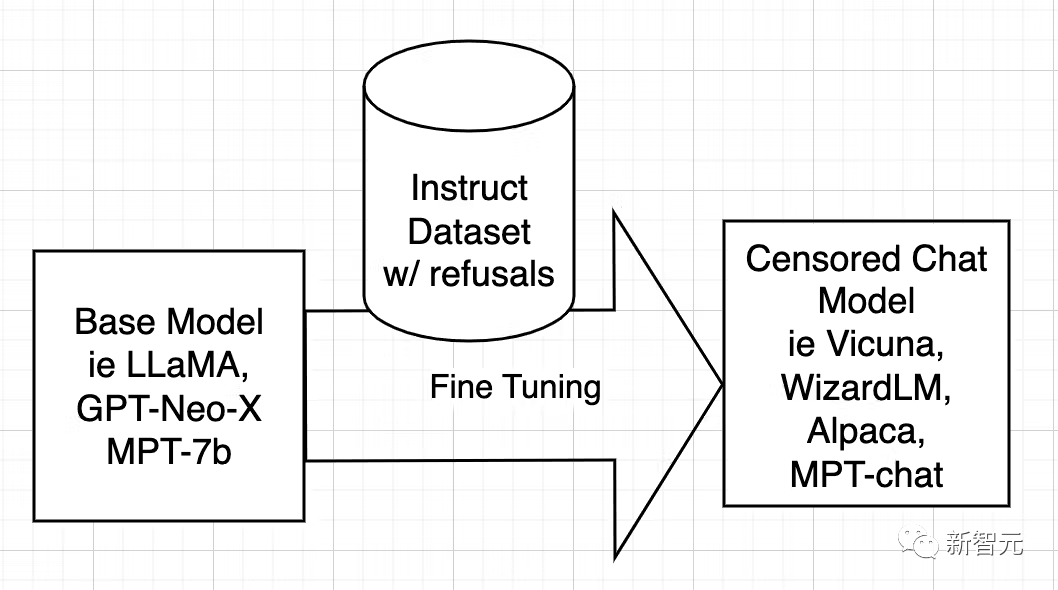
#理由は、指示データセットが質問と回答で構成されているためです。 、AIはどのようにノーと言うのか、どのような状況でノーと言うべきか、そして拒否を表現する方法を学習します。
言い換えれば、アライメントを学ぶことです。
モデルの検閲を解除する戦略は非常にシンプルです。それは、できるだけ多くの否定的で偏った回答を特定して削除し、残りを保持することです。
その後、元のモデルがトレーニングされたのとまったく同じ方法で、フィルターされたデータセットを使用してモデルがトレーニングされます。
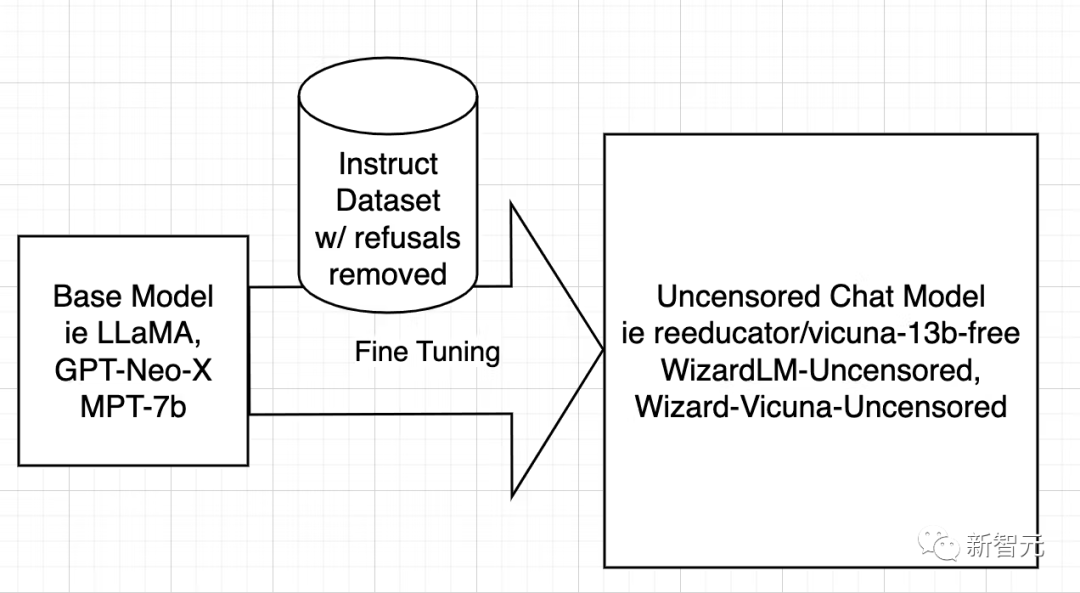
次に、研究者らは WizardLM についてのみ説明しますが、Vicuna や他のモデルの操作プロセスは同じです。
Vicuna の検閲を解除する作業が行われたため、WizardLM データセットで実行できるようにスクリプトを書き直すことができました。
次のステップは、WizardLM データセット上でスクリプトを実行して、ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered
#これで、ユーザーはデータセットを取得しました。 Azure からダウンロードする 4x A100 80GB ノード、Standard_NC96ads_A100_v4 を入手しました。ユーザーには少なくとも 1 TB のストレージ容量が必要です (セキュリティ上の理由から 2 TB が望ましい)。
20 時間実行した後でストレージ容量が不足することは望ましくありません。
ストレージを /workspace にマウントすることをお勧めします。 anaconda と git-lfs をインストールします。その後、ユーザーはワークスペースをセットアップできます。
作成したデータセットと基本モデル-llama-7bをダウンロードします。
1 |
|
1 |
|
1 |
|
次の行を削除した後、プロセスは大幅に改善されました。 (もちろん削除する必要はありません)
1 |
|
1 |
|
博主建议用户可以在wandb.ai上创建一个帐户,以便轻松地跟踪运行情况。
创建帐户后,从设置中复制密钥,即可进行设置。
现在是时候进行运行了!
1 |
|
然后以较低的save_steps运行训练命令。
1 |
|
之后,再次执行整个过程,将checkpoint更改为train_freeform.py最新的checkpoint,并再次以减少的save_steps运行,直到最后以save_steps 1运行它。
成功后,模型位于最后一个检查点。
1 |
|
现在就可以对模型进行测试了。
编辑文件Input.jsonl
向其中添加一些内容,比如:
1 |
|
然后再运行推理:
1 |
|
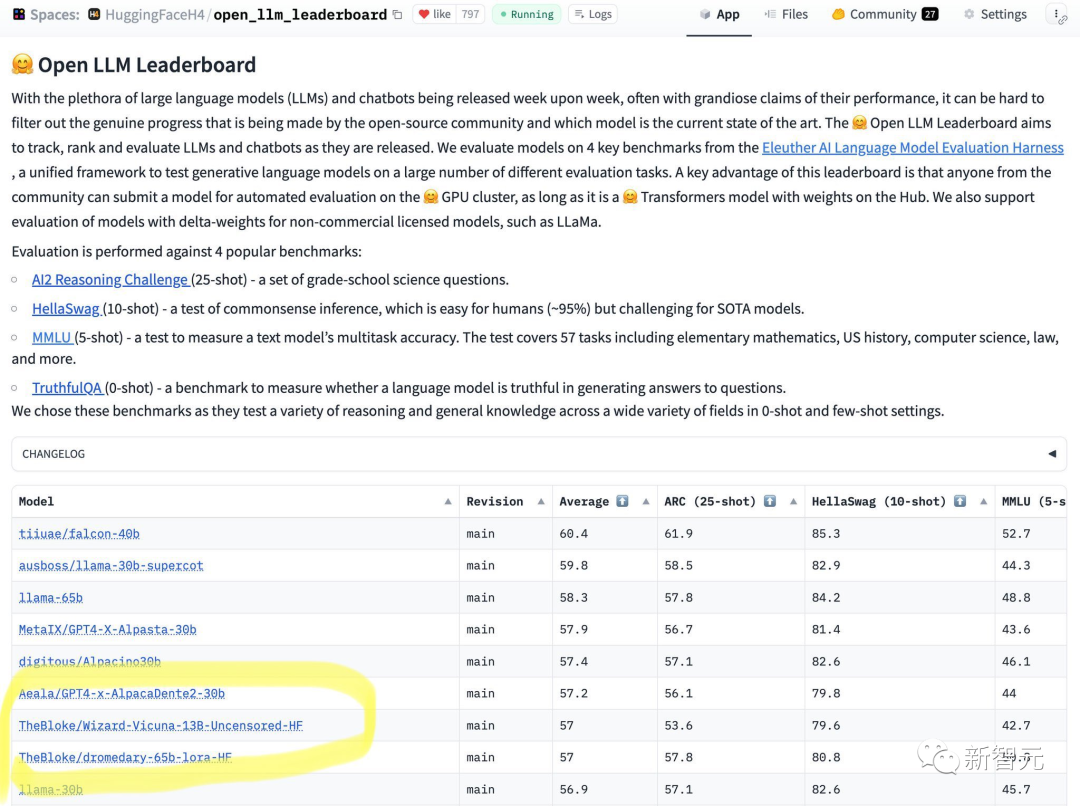
从结果上看,Wizard-Vicuna-13B-Uncensored-HF可以和65B、40B和30B的LLMs直接在一系列基准测试上进行比较。
也许在性能与模型审查之间进行的权衡将成为一个有趣的研究领域。
参考资料:https://www.php.cn/link/a62dd1eb9b15f8d11a8bf167591c2f17
以上が揃えていないとパフォーマンスが爆発してしまう? 130億モデルが650億モデルを潰す、ハグフェイス大型モデルランキング発表の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



