

iPhone は画像を生成するのに 2 秒かかります。既知の最速のモバイル安定拡散モデルがここにあります。

安定拡散 (SD) は、現在最も一般的なテキストから画像へ (テキストから画像へ) 生成する拡散モデルです。その強力な画像生成機能は衝撃的ですが、明らかな欠点は、膨大なコンピューティング リソースを必要とし、推論速度が非常に遅いことです。SD-v1.5 を例に挙げると、半精度ストレージを使用した場合でも、そのモデル サイズは 1.7GB です。パラメータが 10 億個ある場合、デバイス上の推論時間は 2 分近くになることがよくあります。
推論速度の問題を解決するために、学界と産業界は主に 2 つのルートに焦点を当てて SD 高速化の研究を開始しました。 (1) 推論ステップ数の削減、このルート2 つのサブルートに分かれており、1 つはより優れたノイズ スケジューラを提案することでステップ数を削減するもので、代表的な成果は DDIM [1]、PNDM [2]、DPM [3] などです。順蒸留のステップ数(Progressive Distillation) ステップ数、代表的な作品としては、プログレッシブ蒸留[4]、w-コンディショニング[5]などがあります。 (2) エンジニアリング スキルの最適化. 代表的な成果としては、Qualcomm が int8 定量化フルスタック最適化を使用して Android 携帯電話で SD-v1.5 を 15 秒で達成 [6]、Google がオンエンド GPU 最適化を使用して SD-v1 を達成していることです。 Samsung 携帯電話では .4。12 秒まで加速します [7]。
これらの取り組みは長い道のりを歩んできましたが、まだ十分なスピードで進んでいません。
最近、スナップ研究所は、ネットワーク構造、学習プロセス、損失関数の包括的な最適化により、2 秒で画像を生成できる最新の高性能安定拡散モデルを発表しました。 iPhone 14 Pro. (512x512) で、SD-v1.5 よりも優れた CLIP スコアを達成します。これは既知の最速のエンドツーエンド安定拡散モデルです。

- #論文アドレス: https://arxiv.org/pdf/2306.00980.pdf
- #ウェブページ: https://snap-research.github.io/SnapFusion コア メソッド
次の表は、SD-v1.5 モデルと SnapFusion モデルの概要比較です。UNet と VAE デコーダの 2 つの部分によって速度が向上していることがわかります。 UNet 部分が大きな部分です。 UNet 部分の改善には 2 つの側面があります。1 つは、提案された Efficient UNet 構造を通じて得られる単一遅延の削減 (1700 ミリ秒 -> 230 ミリ秒、7.4 倍の加速)、もう 1 つは推論ステップの削減です ( 50 -> 8、6.25 x 加速)、これは提案された CFG を意識した蒸留によって得られます。 VAE デコーダは、構造化されたプルーニングによって高速化されます。

(1) 効率的な UNet
UNet の Cross-Attend モジュールと ResNet モジュールを分析することで速度を特定します。以下の図に示すように、ボトルネックはクロス アテンション モジュール (特に最初のダウンサンプル ステージのクロス アテンション) にあります。この問題の根本的な原因は、アテンション モジュールの複雑さが特徴マップの空間サイズと二乗関係にあることです。最初のダウンサンプル ステージでは、特徴マップの空間サイズがまだ大きいため、計算の複雑さが高くなります。
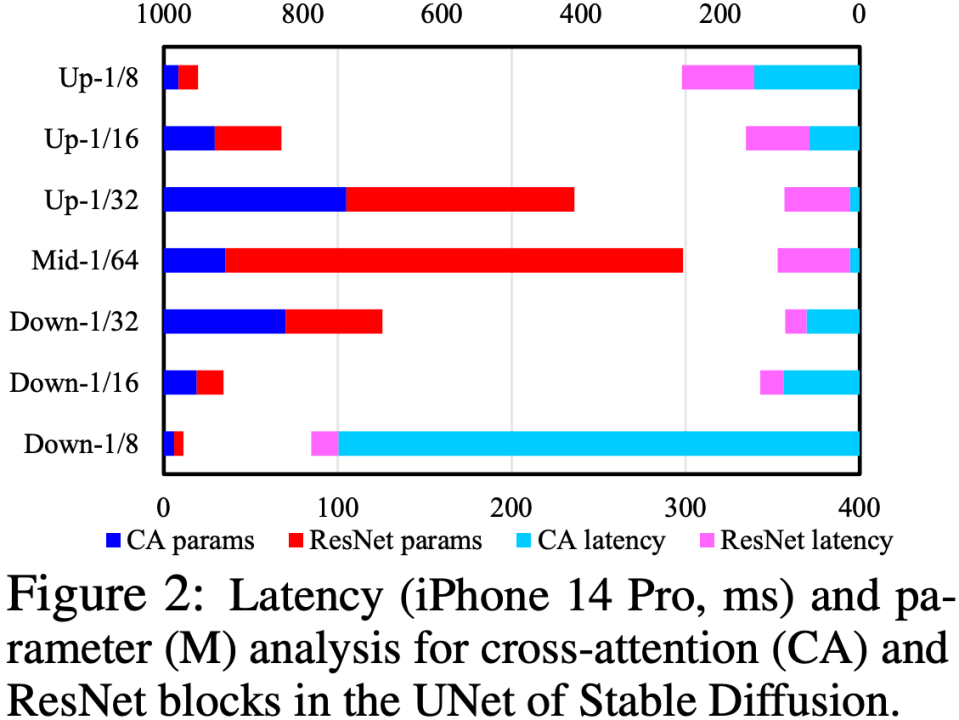
UNet 構造を最適化するために、UNet 構造の自動評価および進化プロセスのセットを提案します。最初に UNet 上で堅牢なトレーニング (ロバスト トレーニング) を実施し、トレーニング中にいくつかのモジュールをランダムにドロップしてそれぞれをテストします。パフォーマンスに対する各モジュールの実際の影響は、「CLIP スコアに対する影響とレイテンシへの影響」のルックアップ テーブルを構築するために構築されます。その後、ルックアップ テーブルに基づいて、CLIP スコアにほとんど影響を与えず、影響が非常に大きいモジュールを削除することが優先されます。時間がかかる。この一連のプロセスはオンラインで自動的に実行され、完了すると、Efficient UNet と呼ばれるまったく新しい UNet 構造が得られます。オリジナルの UNet と比較して、パフォーマンスを低下させることなく 7.4 倍の高速化を実現します。
(2) CFG を意識したステップ蒸留
CFG (Classifier-Free Guide) は SD 推論段階です画質を大幅に向上させるための必須スキル、非常に重要です。加速のために段階的蒸留を使用する拡散モデルに関する研究はこれまでにも行われていますが[4]、それらは蒸留トレーニングの最適化目標として CFG を含めていませんでした。つまり、蒸留損失関数は後で CFG が使用されることを知りません。私たちの観察によると、ステップ数が少ない場合、これは CLIP スコアに重大な影響を及ぼします。
この問題を解決するために、蒸留損失関数を計算する前に教師モデルと学生モデルの両方に CFG を実行させ、損失関数が CFG 後のフィーチャで計算されるようにすることを提案します。したがって、さまざまな CFG スケールの影響が明示的に考慮されます。実験では、CFG を意識した蒸留を完全に使用することで CLIP スコアは改善できるものの、FID も大幅に悪化することがわかりました。次に、元のステップ蒸留損失関数と CFG を意識した蒸留損失関数を混合するランダム サンプリング スキームを提案し、2 つの利点の共存を実現しました。これにより、CLIP スコアが大幅に改善されただけでなく、FID も悪化しませんでした。 。このステップにより、さらなる推論段階で 6.25 倍の加速が達成され、合計で約 46 倍の加速が達成されます。
上記の 2 つの主要な貢献に加えて、この記事には、VAE デコーダのプルーニング アクセラレーションと蒸留プロセスの慎重な設計も含まれています。具体的な内容については、論文を参照してください。
実験結果
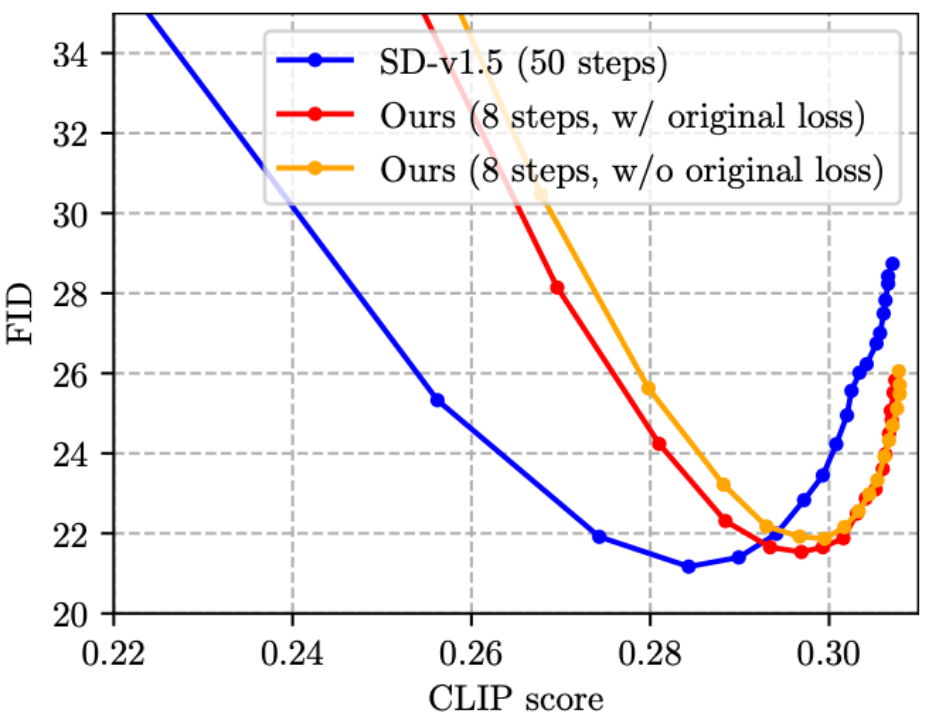
SnapFusion ベンチマーク SD-v1.5 のテキストから画像への変換機能。目標は、推論時間を大幅に短縮し、画質を劣化させることなく維持することです。これが最もよく表されています。これを次の図に示します。
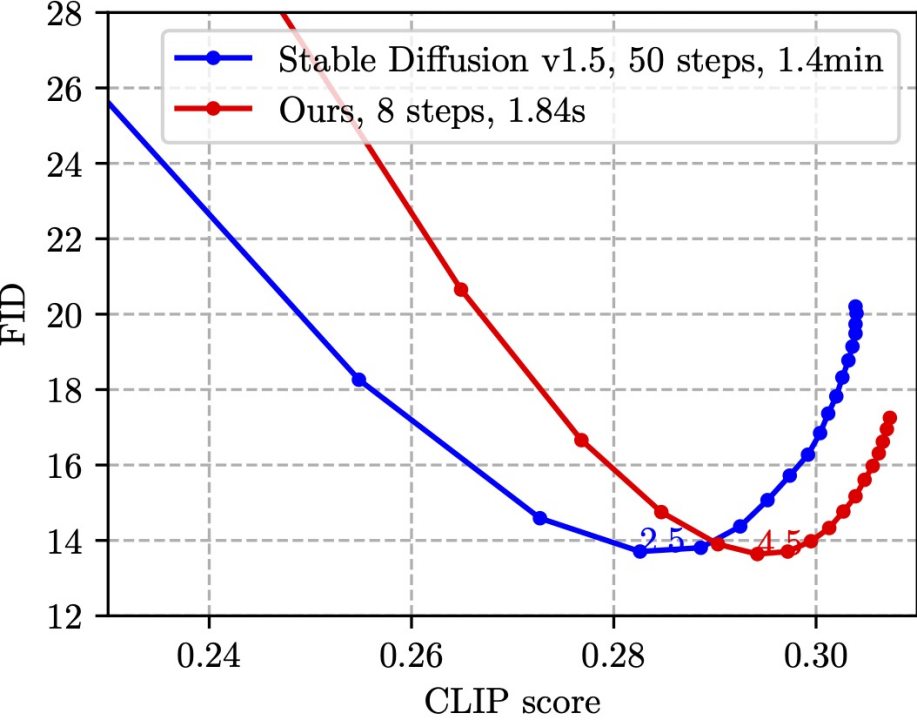
この図は、CLIP を計算するために MS COCO'14 検証セット上の 30,000 個のキャプションと画像のペアをランダムに選択します。スコアと FID。 CLIP スコアは、画像とテキスト間の意味上の一貫性を測定し、大きいほど優れています。FID は、生成された画像と実際の画像の間の分布距離 (一般に、生成された画像の多様性の尺度と考えられます) を測定し、小さいほど優れています。グラフ内の異なる点は異なる CFG スケールを使用して取得され、各 CFG スケールはデータ ポイントに対応します。図からわかるように、私たちの方法 (赤線) は SD-v1.5 (青線) と同じ最低の FID を達成でき、同時に私たちの方法の CLIP スコアも優れています。 SD-v1.5 ではイメージの生成に 1.4 分かかるのに対し、SnapFusion では 1.84 秒しかかからないことは注目に値します。これは、私たちが知る限り最速のモバイル安定拡散モデルでもあります。
SnapFusion によって生成されたサンプルをいくつか示します:

その他のサンプルをご覧ください記事の付録を参照してください。
これらの主な結果に加えて、この記事では効率的な SD モデルの開発に参考となる経験を提供することを目的として、多数のアブレーション解析 (アブレーションスタディ) 実験も示しています。
# (1) 段階蒸留に関する以前の研究では、通常、漸進スキーム [4、5] が使用されていましたが、SD モデルでは漸進蒸留には直接蒸留に比べて利点がなく、プロセスが煩雑であることがわかりました。この記事では直接蒸留スキームを使用します。
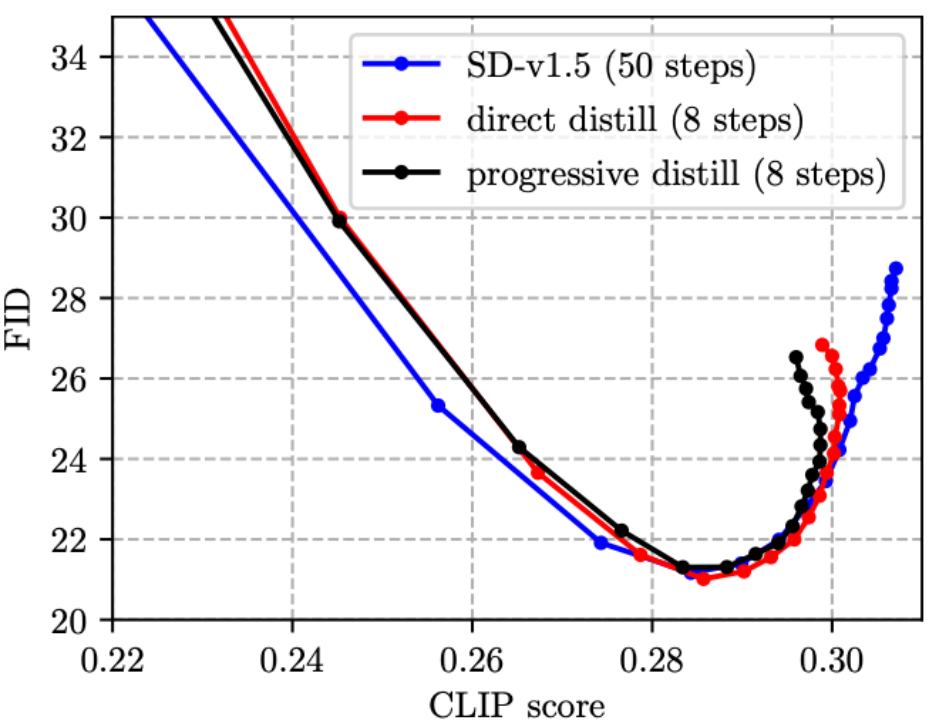
(2) CFG は画質を大幅に向上させることができますが、コストは推論コストの 2 倍になります。今年の CVPR'23 賞候補者の蒸留に関する論文 [5] では、蒸留のための UNet への入力として CFG パラメータを使用する w-conditioning (結果として得られるモデルは w-conditioned UNet と呼ばれます) を提案し、それによって推論中の CFG ステップを排除し、推論を実現します。コストが半分になります。しかし、そうすることで実際には画質が低下し、CLIP スコアが低下することがわかりました (下の図に示すように、4 本の w 条件付きラインの CLIP スコアは 0.30 を超えず、これは SD よりも悪いです)。 v1.5)。私たちの方法では、提案された CFG を認識した蒸留損失関数のおかげで、ステップ数を削減し、同時に CLIP スコアを向上させることができます。特に注目すべき点は、以下の図の緑の線 (w 条件付き、16 ステップ) とオレンジ色の線 (私たちのもの、8 ステップ) の推論コストは同じですが、オレンジ色の線の方が明らかに優れていることです。テクニカル ルートは、W 条件付きコンディショニング [5] よりも優れており、蒸留された CFG ガイド付き SD モデルではより効果的です。
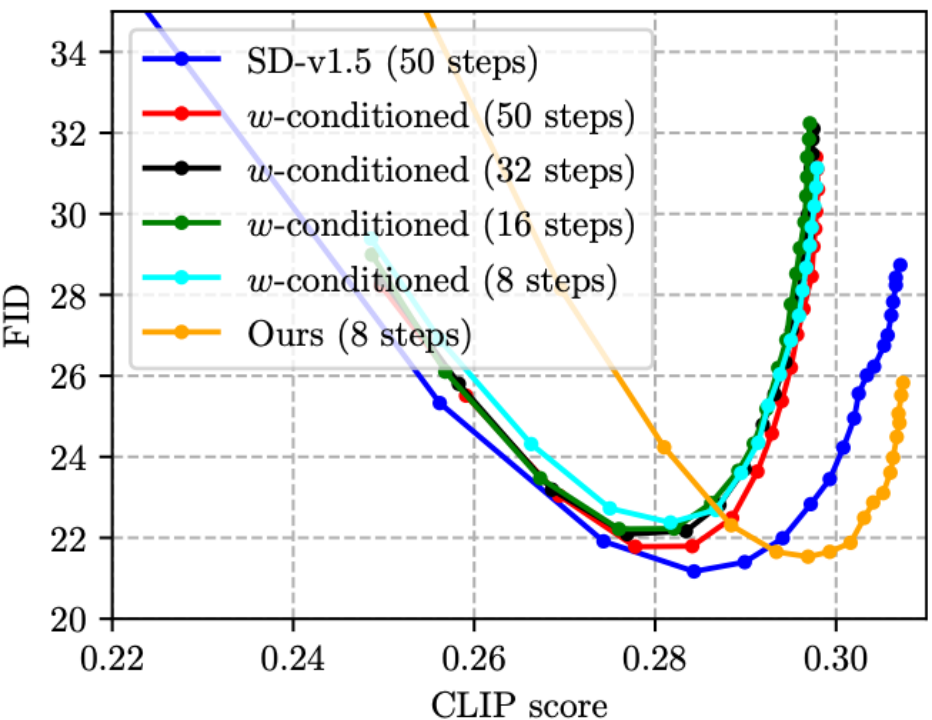
(3) ステップ蒸留に関する既存の研究 [4、5] は、元の損失関数と蒸留を組み合わせていませんでした。画像分類の知識の抽出に精通している友人なら、この設計が直観的に最適ではないことが分かるはずです。そこで、以下の図に示すように、トレーニングに元の損失関数を追加することを提案しました。これは実際に効果的です (FID がわずかに減少します)。
概要と今後の課題
この論文では、高性能安定拡散モデルである SnapFusion を提案します。携帯端末。 SnapFusion には 2 つの主要な貢献があります。(1) 既存の UNet のレイヤーごとの分析を通じて、速度のボトルネックを特定し、元の Stable Diffusion の UNet を効果的に置き換えることができる新しい効率的な UNet 構造 (Efficient UNet) を提案します。 7.4 倍の加速を達成; (2) 推論フェーズの反復ステップ数を最適化し、ステップ数を削減しながら CLIP スコアを大幅に改善できる新しいステップ蒸留スキーム (CFG 認識ステップ蒸留) を提案し、6.25 倍を達成します。加速度。全体として、SnapFusion は iPhone 14 Pro 上で 2 秒以内に画像出力を達成します。これは現在知られている最速のモバイル安定拡散モデルです。
今後の取り組み:
1. SD モデルは、さまざまな画像生成シナリオで使用できます。時間の制約のため、現在はテキストから画像へのコアタスクのみに焦点を当てており、他のタスク (修復、ControlNet など) については後で説明します。
2. この記事では主に速度の向上に焦点を当てており、モデル ストレージの最適化については説明しません。提案されている Efficient UNet にはまだ圧縮の余地があると考えており、他の高性能最適化手法 (枝刈り、量子化など) と組み合わせることで、ストレージを縮小し、時間を 1 秒未満に短縮し、リアルタイム SD を実現できることが期待されます。オフエンドではさらに一歩進んでいます。
以上がiPhone は画像を生成するのに 2 秒かかります。既知の最速のモバイル安定拡散モデルがここにあります。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7747
7747
 15
1643
14
1397
52
1291
25
1234
29
15
1643
14
1397
52
1291
25
1234
29

 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
