

事前トレーニングされたモデルに基づく金融イベントの分析とアプリケーション


#1. 金融イベント分析の主なタスク

金融イベント分析分析 主なタスクは 3 つの部分に分けることができます。
① 最初の部分は、非構造化データのインテリジェントな分析です。金融分野の情報は、インターネットの情報とは異なる特徴があります。金融分野の情報は構造化されていない形式で存在することが多く、PDF などの特殊なファイル形式が存在するため、ファイルやデータからクリーンで正確なデータを抽出することがより困難になります。 PDF 形式は植字および印刷形式であり、他のファイル形式ほど明確な段落はありません。 PDF は植字に特化しているため、ファイル内にはいくつかの位置情報しかありません。非構造化データから正確にフォーマットされ、意味的に明確なテキストを解析することはより困難です。さらに、ドキュメント内の形式のセマンティクスが不明瞭な場合、イベント分析によってノイズが発生し、これらのダーティなデータがモデルのトレーニングと推論に多大な干渉を引き起こす可能性があります。したがって、モデルの精度を向上させるには、最初に非構造化データを解析する必要があります。
② 2 番目の部分はイベント セマンティクスの理解であり、技術的に重要な部分です。これには主に、イベント検出、イベント要素抽出、イベント関係抽出が含まれます。
③ イベントの理解に基づいて、このタスクでより重要な 3 番目のモジュールであるイベント グラフ分析が導入されます。これには、イベント チェーン分析とイベント予測が含まれます。
上記のタスクを完了するために、さらに 2 つの重要なシステムが導入されます。 1 つ目は金融イベント システムであり、金融イベント システムには金融分野の関連エンティティが含まれており、これらのエンティティにもさまざまな適用シナリオがあります。これらの主題とシナリオをより適切にサポートするには、対応するイベント システムを確立する必要があります。これには多くのドメイン知識が含まれ、ドメイン専門家が対応する知識を入力として提供する必要があります。これは、対応するシナリオをカバーできる、より完全で科学的なシステムを構築するのに役立ちます。もちろん、専門知識に加えて、完全なシナリオベースでスケーラブルなイベント システムを提供できる帰納的学習にもテクノロジーが必要になります。
専門知識の導入は、主に現場のより重要なイベントを対象としているためです。一部の中規模およびロングテール イベントの場合、主に学習に基づくいくつかのテクノロジーによって解決されます。金融イベントグラフでは、イベント抽出技術を組み合わせ、イベント抽出、イベント関係分類、イベント表現の学習を行った後、分析と予測のためのグラフを構築できます。
明確なタスクと技術サポートがあれば、ニュースや文書を処理し、多くの質問を要約して答えることができます。例えば、どの企業でどのようなイベントが発生し、そのイベントにどのような要素が関与したか、共通要素である時刻、場所、人物、あるいはイベントの種類に関連する要素など、例えば「自社の株式の発行」というイベントには、要素の発行価格、発行部数など。さらに、このイベントに対する人々の評価(感情分析)などの情報にも注目することができます。特定の種類のイベントが発生した後に会社に将来何が起こるかを予測します。上記の質問に答えることができれば、多くのシナリオで役に立ちます。
具体的な例を見てみましょう。
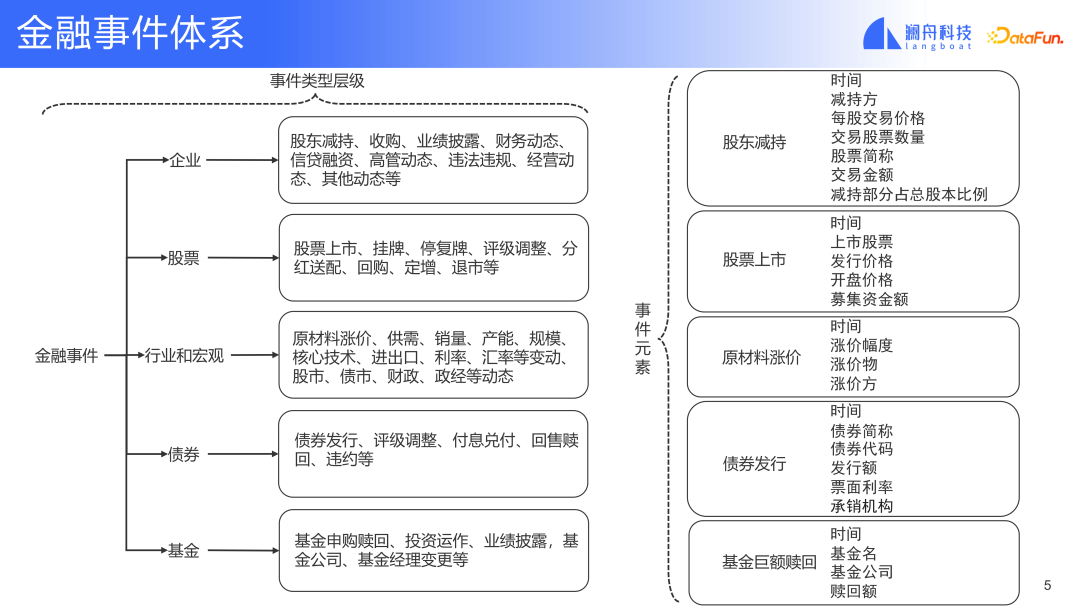
#上図は金融イベント システムを 2 つのレベルに分けており、最初のレベルには主に特定の項目に基づいた 5 つのカテゴリがあります。企業イベント、株式イベント、業界およびマクロ イベント、債務イベント、ファンド イベントなどを区別します。異なるイベント オブジェクトに対して異なるイベント タイプが定義されます。これらは金融において最も一般的なオブジェクトです。第 2 レベルでは、各タイプのオブジェクトをさらに細分化します。たとえば、株主還元など、企業内の一般的なイベントです (上の図を参照)。株主による株式の減額などのイベントを例に挙げると、そのイベント要素には、減額の時刻、減額を行った株主、減額時の取引価格などが含まれます。シナリオを対象とした完全なイベント システムを定義することは、イベント分析が目的を達成するための重要な前提条件です。イベント システムの定義の詳細度によって、最終的なイベント分析で得られる詳細なイベント情報の程度が決まります。成し遂げる。
#イベントグラフを以下に紹介します。
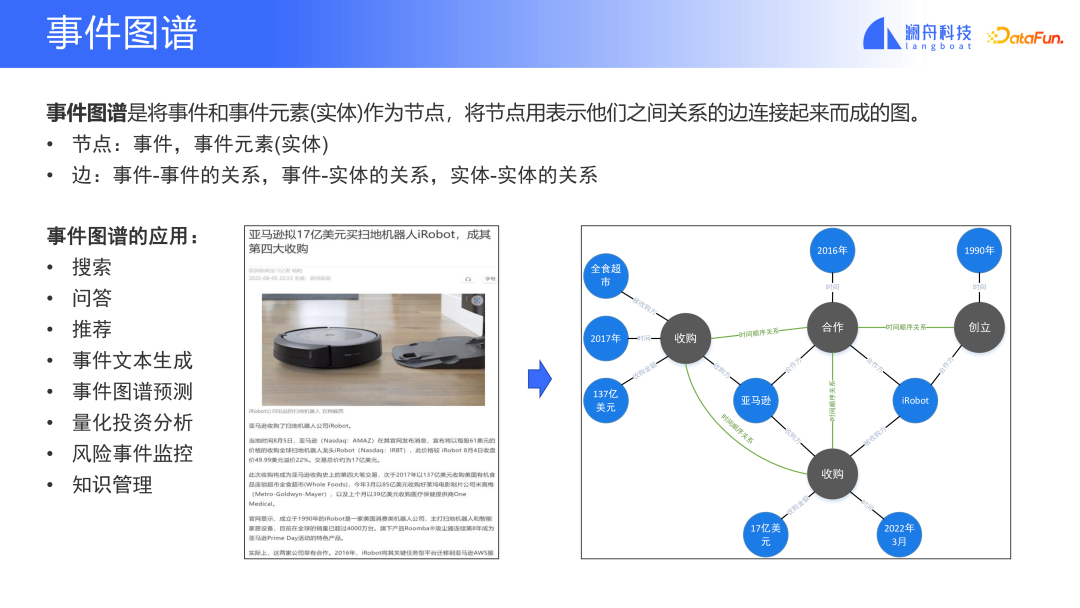
イベント グラフはグラフに属し、ノードとエッジが含まれます。イベント グラフでは、イベント ノードはイベントまたはイベント内のエンティティ (会社など) になります。エッジは、イベント間の関係、イベントとエンティティ間の関係、またはエンティティ間の関係です。
例を見てみましょう。上の写真は、AmazonによるiRobot買収を紹介するニュース記事です。このニュースレポートには合計 4 つの出来事が記載されており、そのうち 2 つは買収であり、異なる時期に発生しました。残りの 2 つは、会社設立のイベントと協力のイベントです。これらの出来事は、発生の時系列順に関連付けられています。このニュースには出来事だけでなく、他の実体や時刻も含まれており、これらの実体や時刻も対応関係で結ばれている。
#このように、構造化されていない Web ページの情報のように見えますが、文書内のテキストと段落を解析し、段落の意味解析を実行することで、イベント エンティティと関係を抽出すると、イベント グラフを構築できます。それは、非構造化データを構造化情報に変換することです。情報が構造化されていると、情報の理解と処理が容易になります。これらの情報は、検索や質疑応答などの情報取得シーンや、金融分野におけるリスクモニタリングや定量的投資などのビジネスシーンで活用できます。
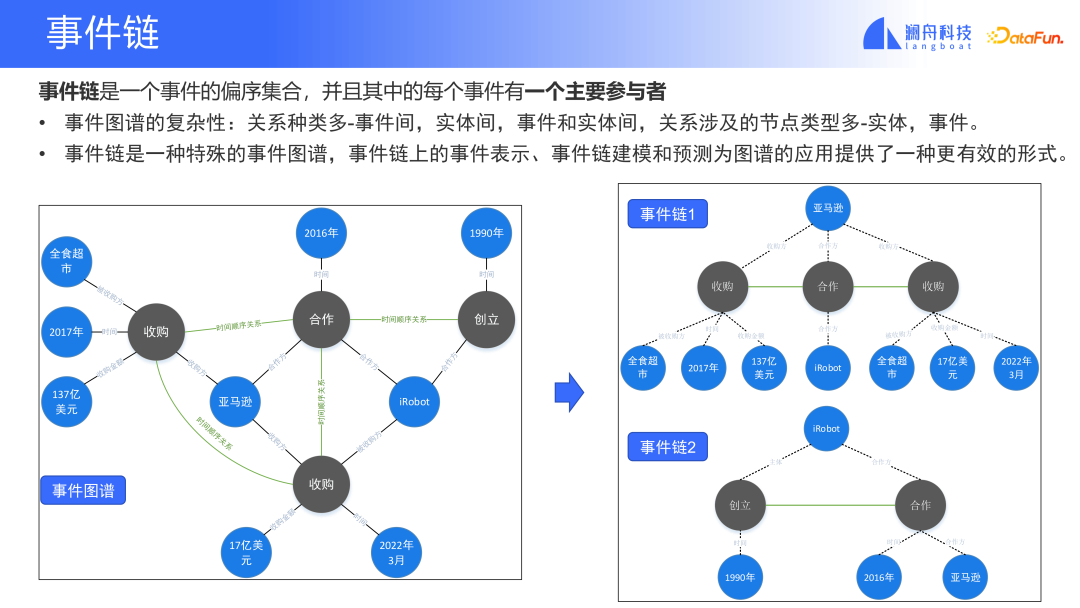
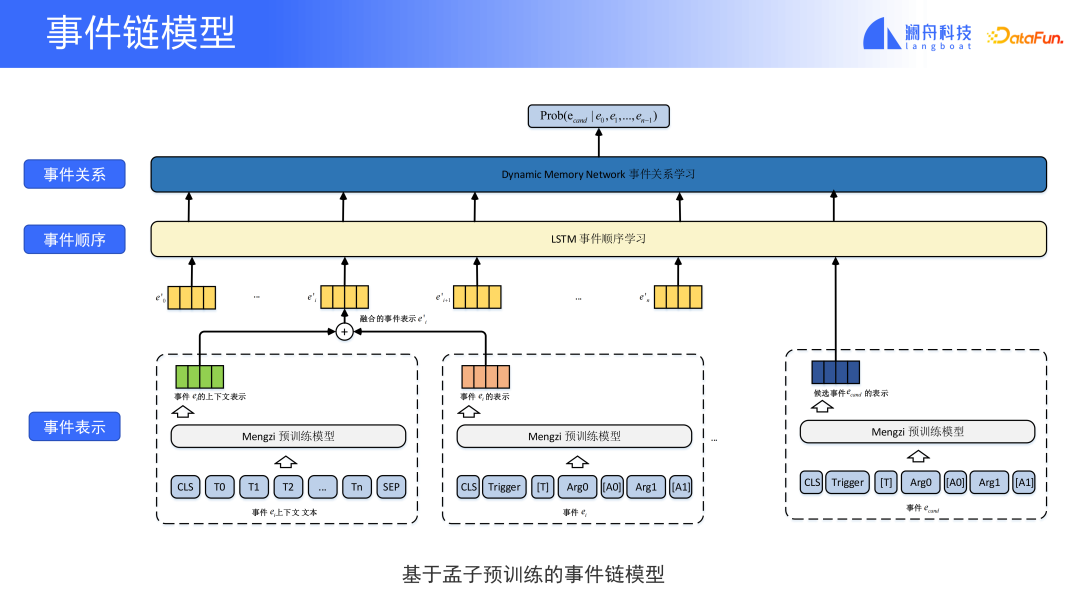
ここで強調しなければならないのは、このモデルの予測結果は、将来社内で確実に起こる事象を予測するものではなく、分析のための補助的な情報を提供するものであるということです。 、予測、研究と判断の根拠を提供します。
#上記のイベントチェーンとイベント予測は、まだ起こっていない状況についての予測と判断です。イベント予測は実際に、すでに発生したイベントに対して役立つ助けを提供します。
別の例を見てみましょう。この例は、役立つヘルプを提供するためにすでに発生したイベントに基づいています。
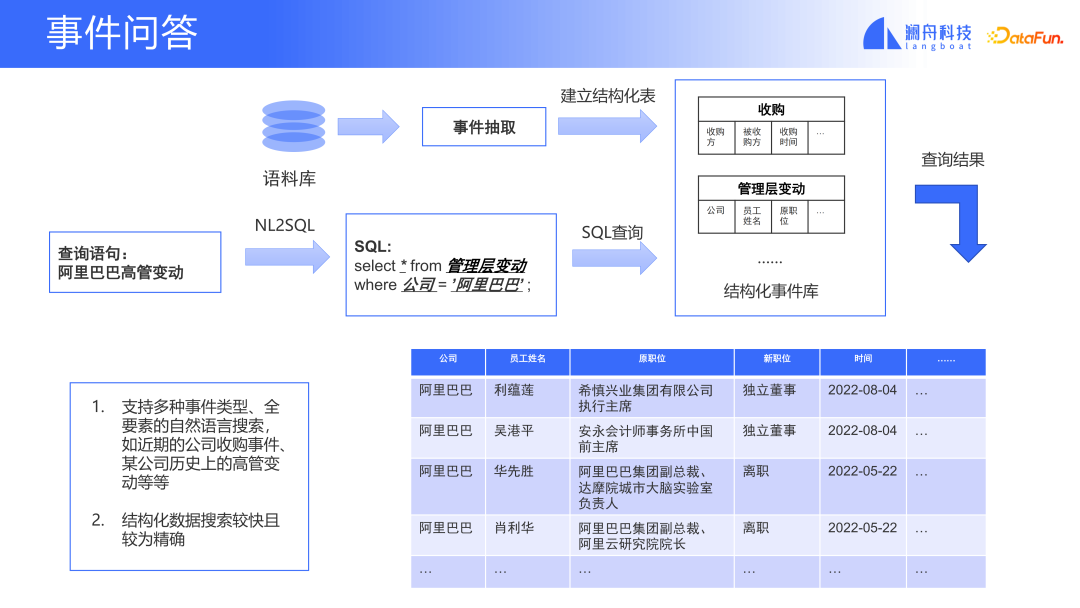
イベント ライブラリに基づくこの種のイベントの質問と回答は、イベントの自然言語検索をサポートできます。まずコーパスから抽出し、構造化イベント ライブラリを構築します。イベントの種類ごとにテーブルが作成されます。テーブルの各フィールドは、異なるイベント要素を表します。NL2SQL テクノロジと組み合わせると、クエリ ステートメントをデータベース クエリ ステートメントに変換できます。このようにして、作成したばかりのテーブルで正確なイベント タイプを見つけることができます。これは、現在市販されている一般的な検索エンジンでイベントを検索する体験とは異なります。検索エンジンによって返される結果は、このイベント タイプに関するさまざまな種類のニュースです。関連するニュースが見つかったとしても、表示される結果は、特定のイベントに関する具体的な情報ではなく、完全なレポートです。イベントデータベースをベースとしたイベントQ&Aにより、より正確にイベントのQ&A検索を行うことができます。
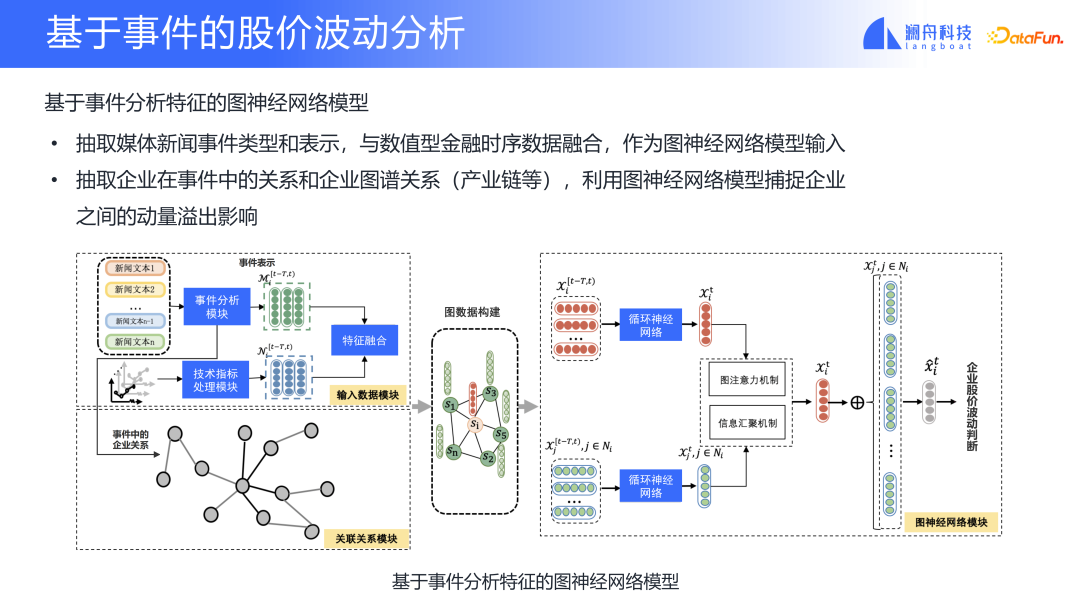
#上記の例を通じて、特定のシナリオでイベント分析をどのように実行できるかを確認できます。市場では企業の株価変動が注目されている。イベントベースの株価変動も、イベント分析においてNLPと金融分野を組み合わせたシナリオであり、市場情報と株価変動の変革を実現できます。上図はモデル内の 2 つの特徴を示しており、1 つは特定の企業を表し、もう 1 つは企業間の関係を表しています。イベントの種類とイベントに関与するさまざまな企業を抽出するイベント分析を紹介します。抽出されたイベント タイプと、企業が提供できる 2 種類の情報。1 つはイベントの表現であり、これは機能となり、企業の機能と統合できます。企業とイベントとの間の関係は、企業間の関連関係モジュールを構築することができる。次に、企業固有のテクニカル指標や企業関係マップなどの既存の機能を追加します。 2 つを組み合わせると、企業情報と関係情報を含むグラフを構築できます。このグラフに基づいて、企業間の関係が企業の株価変動パフォーマンスに及ぼす影響をグラフ・アテンション・ネットワークを用いて捉えます。株価変動をモデル学習の対象としてモデルをトレーニングすることで得られたモデルネットワーク構造は、ニュース業界マップや企業関係マップなどの特徴から企業の将来の特徴を判断することができます。アテンションモデルの分析を通じて、イベントタイプモジュールかイベント関係モジュールかにかかわらず、変動が主にどのモジュールに由来しているかを知ることもできます。また、企業間の関係をモデル化することで、この影響が関連企業にどのように波及するかを分析することもできます。これは金融分野におけるモメンタム波及効果ともいえる。
#以前に紹介したさまざまなイベント分析テクノロジとシナリオの包括的な内容です。完全なイベント分析フレームワークを要約しました。 (以下に示すように)
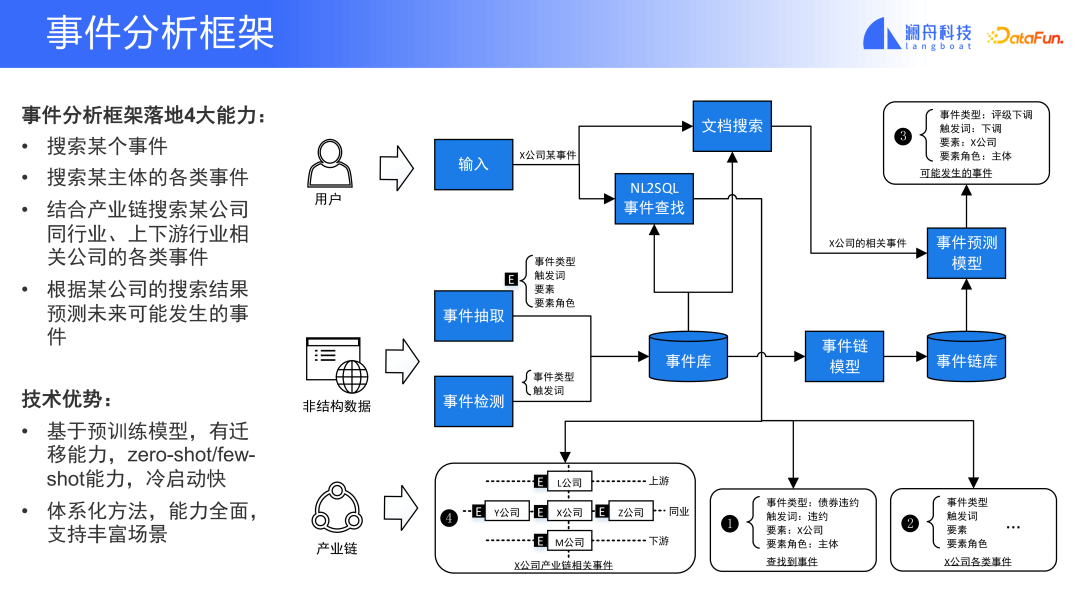
① まず、特定のイベントや特定の主題のさまざまなイベントを検索できます。
② 次に、産業チェーンを通じて、同じ業界の企業のさまざまな関連イベントの検索を提供できます。産業チェーンは、産業チェーンまたは企業にすることができます。鎖。
③ このフレームワークは、企業の検索結果に基づいて将来起こり得るイベントを予測することもできます。
このフレームワークの利点は、事前トレーニングされたモデルに基づいており、学習を転移する機能があり、ゼロショット/少数の攻撃をサポートできることです。ショットトレーニングに適しており、コールドスタートが速いです。さらに、この体系的な方法は比較的包括的な機能を備えており、さまざまなシナリオをサポートできます。
#すべてのシナリオでフレームワーク内のすべてのモジュールが必要なわけではなく、モジュールは必要に応じて分割して個別に使用できます。
2. 金融イベント分析テクノロジー
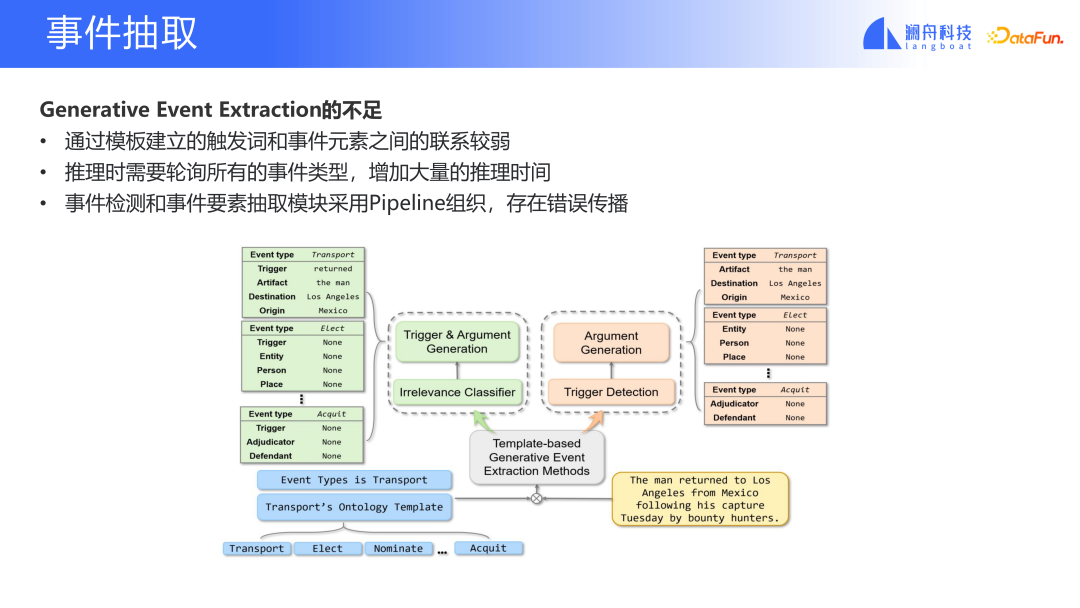
金融イベント分析テクノロジーでさらに重要な 2 つのコンテンツはイベントです。そしてイベント抽出。
イベント検出タスクの目標は、テキストからイベントを抽出し、分類することです。通常はトリガーワードを抽出してイベントを検出しますが、トリガーワードを抽出せずにイベントを検出する方法もあります。このタイプの問題の課題は、トリガー ワードのラベル付けです。また、セマンティック マイグレーション、イベント分割、イベント定義の変更などの問題が発生した場合、データのラベルを再設定する必要があります。この種の問題は実際のシナリオでもよく発生します。当社は独自のイベント検出ソリューションのセットを持っていますが、さまざまな分野に適用したり、さまざまな顧客ニーズに直面したりすると、イベント システムは大きく異なります。既存のモデルとデータをより適切に組み合わせる方法は、イベント システムの変更をサポートすることが当社の最大の課題です。現在の顔。現在のアプローチは、キューワードと事前トレーニングされたモデルに基づくイベント検出です。イベント タイプのプロンプトに従って、数ショットのシナリオでデータ移行やモデル トレーニングをより適切に実行できます。

#上の図は、トリガーワードに基づくモデルと手法を示しています。イベントタイプのプロンプトに従って、モデルの入力にトークンレベルで注釈を付けることができるため、対応するイベントのトリガーワードを抽出できます。トリガー ワードが現在のプロンプトに基づいて変換される場合、対応するイベント タイプとトリガー ワードもそれに応じて変更できます。公開データセットでのデータ比較を通じて、データ全体において、以前の手法と比較してモデルのパフォーマンスが大幅に向上していることがわかります。少数ショットの場合でも、モデルのパフォーマンスは優れています。他のモデルよりも。
 #イベント抽出タスクは、イベント検出タスクの機能を拡張したものです。イベントの種類やトリガーワードを特定するだけでなく、イベント内の対応する要素も抽出します。これは、イベント分析に比較的完全な情報が必要なシナリオに大きな影響を与えます。上図の例では、より詳細な情報を抽出できます。イベント抽出の課題には、完全なイベント システムでは多数のイベント要素が存在すること、データ アノテーションを完了するにはドメインの専門家が必要であること、コストが比較的高いこと、多くのイベント タイプに拡張することが難しいことなどが挙げられます。現在のソリューションは、事前トレーニングされたモデルとプロンプトを使用することです。
#イベント抽出タスクは、イベント検出タスクの機能を拡張したものです。イベントの種類やトリガーワードを特定するだけでなく、イベント内の対応する要素も抽出します。これは、イベント分析に比較的完全な情報が必要なシナリオに大きな影響を与えます。上図の例では、より詳細な情報を抽出できます。イベント抽出の課題には、完全なイベント システムでは多数のイベント要素が存在すること、データ アノテーションを完了するにはドメインの専門家が必要であること、コストが比較的高いこと、多くのイベント タイプに拡張することが難しいことなどが挙げられます。現在のソリューションは、事前トレーニングされたモデルとプロンプトを使用することです。
に基づく生成手法は、注釈付きデータが少ないシナリオでも良好なモデル パフォーマンスを達成でき、データ利用率と柔軟性が高く、拡張が容易になります。新しいイベントタイプへ。
 #イベント抽出タスクは、イベント検出タスクの機能を拡張したものです。イベントの種類やトリガーワードを特定するだけでなく、イベント内の対応する要素も抽出します。これは、イベント分析に比較的完全な情報が必要なシナリオに大きな影響を与えます。上図の例では、より詳細な情報を抽出できます。イベント抽出の課題には、完全なイベント システムでは多数のイベント要素が存在すること、データ アノテーションを完了するにはドメインの専門家が必要であること、コストが比較的高いこと、多くのイベント タイプに拡張することが難しいことなどが挙げられます。私たちの現在のソリューションは、事前トレーニングされたモデルとプロンプトを使用することです。生成手法は、注釈付きデータが少ないシナリオでも良好なモデル パフォーマンスを達成でき、データ利用率と柔軟性が高く、新しいイベント タイプへの拡張が容易です。
#イベント抽出タスクは、イベント検出タスクの機能を拡張したものです。イベントの種類やトリガーワードを特定するだけでなく、イベント内の対応する要素も抽出します。これは、イベント分析に比較的完全な情報が必要なシナリオに大きな影響を与えます。上図の例では、より詳細な情報を抽出できます。イベント抽出の課題には、完全なイベント システムでは多数のイベント要素が存在すること、データ アノテーションを完了するにはドメインの専門家が必要であること、コストが比較的高いこと、多くのイベント タイプに拡張することが難しいことなどが挙げられます。私たちの現在のソリューションは、事前トレーニングされたモデルとプロンプトを使用することです。生成手法は、注釈付きデータが少ないシナリオでも良好なモデル パフォーマンスを達成でき、データ利用率と柔軟性が高く、新しいイベント タイプへの拡張が容易です。
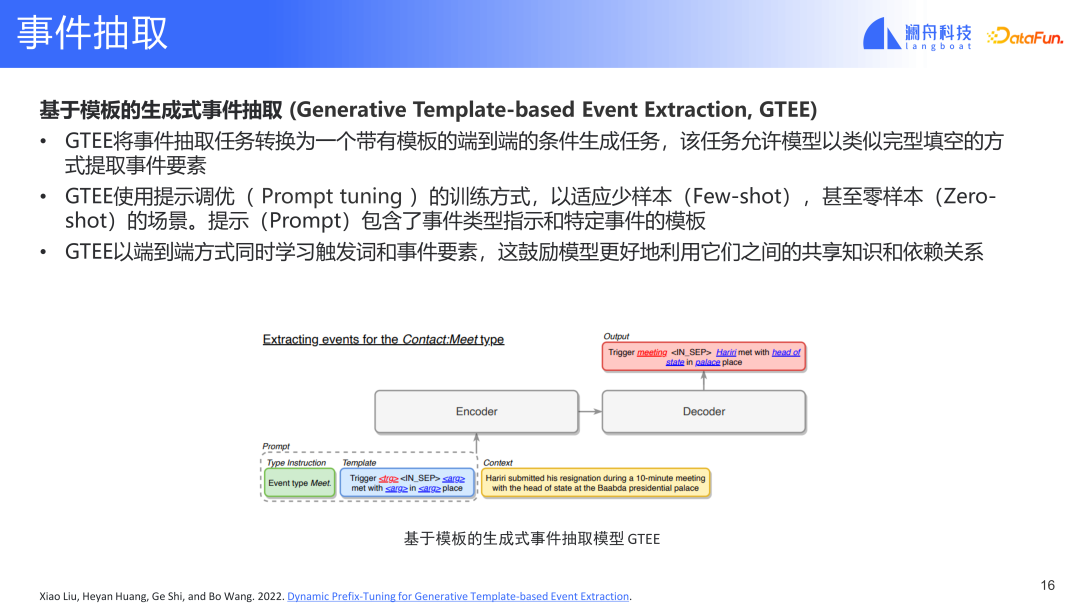
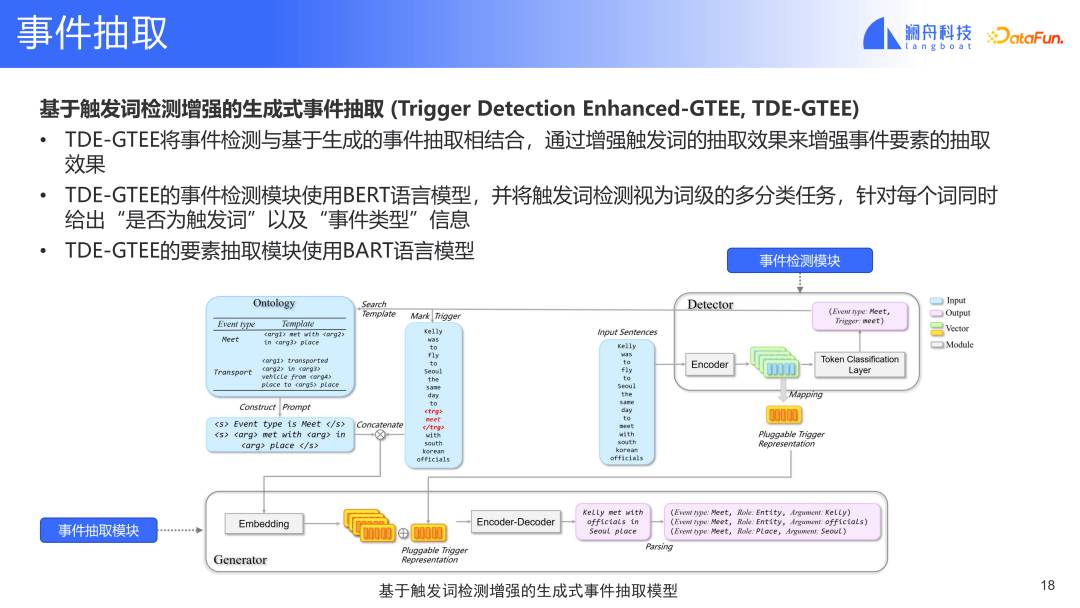
#上記で提起された質問に基づいてモデルを改善しました。別の生成強化されたトリガワード検出に基づくイベント抽出手法TDE-GTEEを提案する。
(Ge Shi、Yunyue Su、Yongliang Ma、Ming Zhou (2023)。イベント抽出用に個別のエンコーダを備えたハイブリッド検出および生成フレームワーク。議事録中(計算言語学協会のヨーロッパ支部の第 17 回会議: メインボリューム。計算言語学協会。)
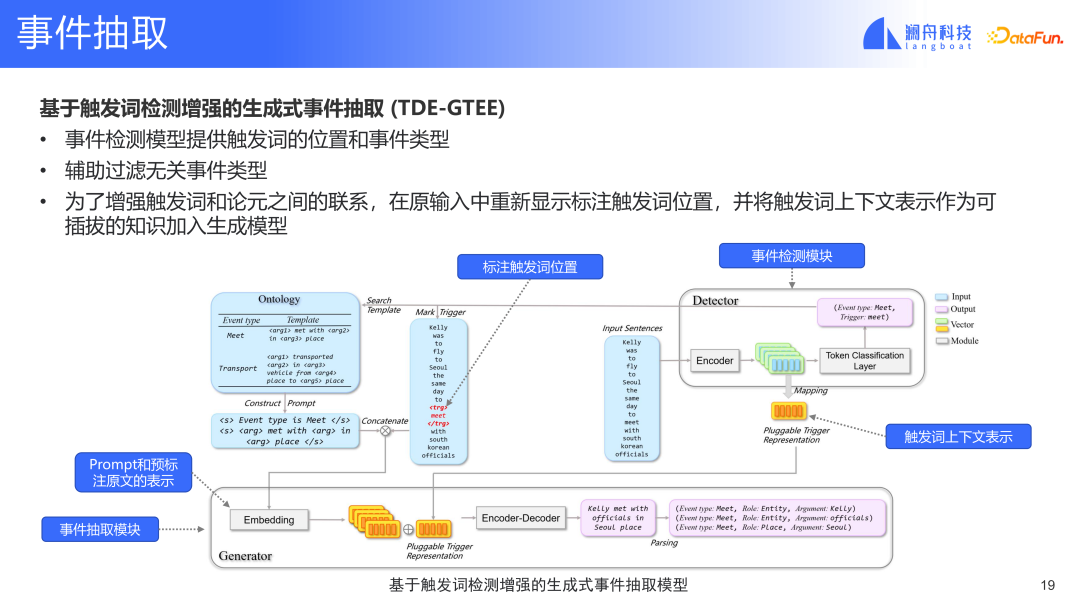
この方法では、イベント検出モジュールは以下を提供します。イベントトリガーワードに関する情報。入力内のトリガーワードをマークし、イベントタイプ情報に基づいて対応するテンプレートを選択します。この入力とイベント テンプレートは後で結合されて、イベント検出モジュールの表現を形成します。この表現はトピック モデルに入力され、最終的に埋め込まれたテンプレートが取得されます。このモデルと以前のモデルの違いは、このモデルには追加のトリガー ワード表現があり、コンテキスト情報も結合されていることです。これにより、最初に挙げたトリガーワードとトリガーワード抽出要素とのつながりが少ないという問題が解決される。このモデルは、2 つの間の表示関係を構築できます。同時に、トリガーワードの入力により、トリガーワードに関連するイベントの種類を知ることができます。このようにして、無関係なイベント タイプを除外できます。イベント検出モジュールは、関連するイベント タイプのイベントのみを抽出します。最後に、イベント検出モジュールとイベント抽出モジュールは、エンドツーエンドの共同トレーニングを形成できます。このモデルは、上記の他の 2 つの問題を解決できます。
TDE-GTEE モデルは、公開データセット ACE と ERE の両方で SOTA レベルに達しました。実験では全量のデータを使用しました。少数のサンプルでこのモデルのパフォーマンスを検証するために、元の多重分類メソッドをプロンプトベースのメソッドに置き換えるなど、イベント検出モジュールにいくつかの調整も加えました。モデルは、ゼロショット/少数ショットでも良好な結果を達成できます。このモデルは実用的なシナリオで広く使用できると考えています。
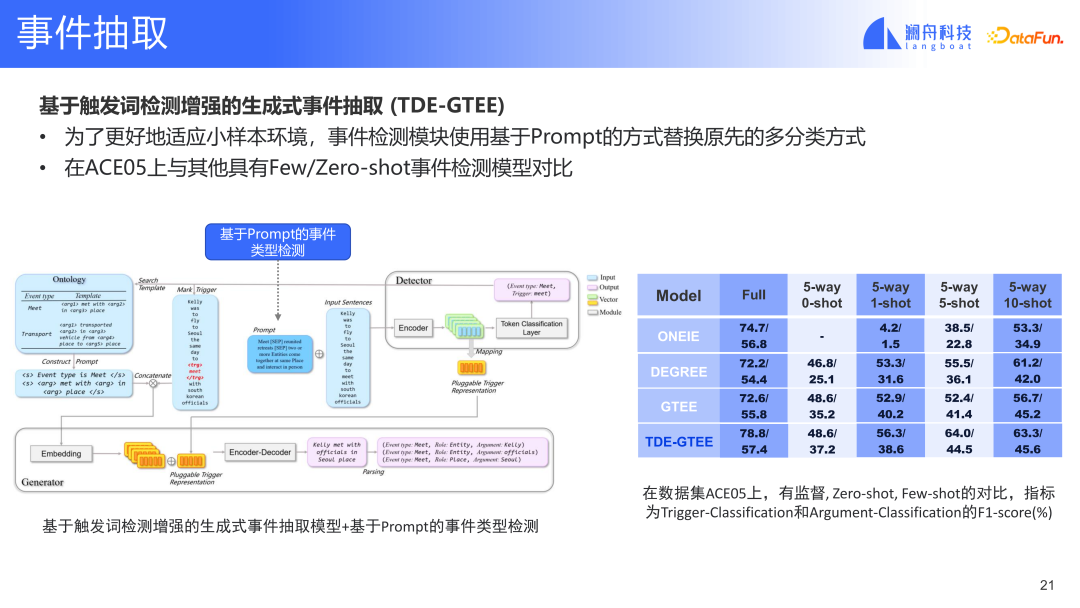
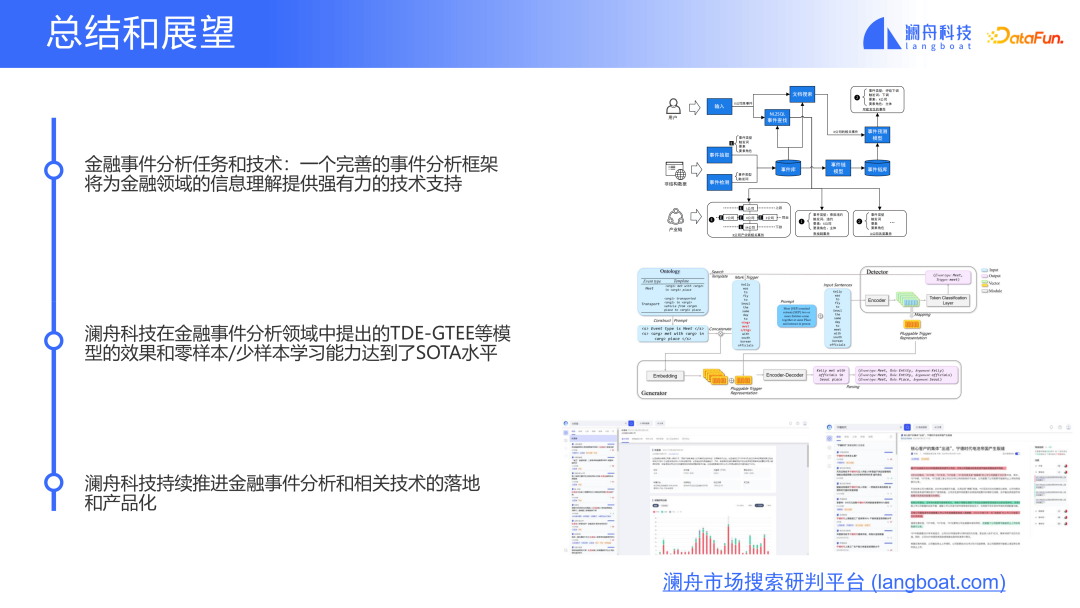
Lanzhou Technology が金融イベント分析の分野で提案している TDE-GTEE などの手法は、SOTA レベルに達することができ、少数サンプルでも非常に優れています。ゼロサンプルシナリオ、パフォーマンス。当社は今後も金融イベント分析分野の技術進歩と製品化を推進していきます。
#4. 質疑応答セッション
#Q1: イベント グラフ専用のデータベースはありますか? 従来のグラフ データベースです。 Neo4j などのイベント グラフを保存および管理しますか?
#A1: イベント グラフ専用のデータベースがあり、一部のデータ プロバイダーがそのようなデータベースを提供しています。たとえば、Lanzhou Technology や Ant Group などの企業も、自社内に独自のデータベースを構築することになります。 Neo4j を使用して、イベント グラフを保存および管理できます。使用シナリオに応じて、Neo4j は複雑なシナリオでのストレージと管理により適しています。イベント チェーンに単純化すると、イベントの表現がより柔軟になる可能性があり、テキストからデータを抽出して、モデルのトレーニング データとしてイベント チェーンを生成します。トレーニングにはグラフ操作は含まれません。
#A2: 主に 2 つの方法があります。特定のモデルを構築および評価するプロセスでは、株式市場からの情報にさらに依存します。クオンツ取引におけるバックテストとして理解され、トレーニングと評価のために過去のデータが使用されます。もう1つは、実際のシナリオでは、企業ニュースや株式の出来高や価格取引などのテクニカル指標を基に翌月の株価変動を予測するなど、人手による判断が必要になることです。今月は実際に株価の変動が起こるのか具体的に見ていきます。変動が発生した場合には、対応するイベントの種類、対応する株価の出来高や価格情報などを分析し、強い因果関係があるかどうかを判断します。 Q2: 株価変動分析の効果はどのように評価すればよいですか?
以上が事前トレーニングされたモデルに基づく金融イベントの分析とアプリケーションの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7530
7530
 15
1379
52
82
11
21
76
15
1379
52
82
11
21
76

 画像内の物体検出のために ML データを探索および視覚化する方法
Feb 16, 2024 am 11:33 AM
画像内の物体検出のために ML データを探索および視覚化する方法
Feb 16, 2024 am 11:33 AM
近年、機械学習データ(ML-data)を深く理解することの重要性に対する理解が深まってきています。ただし、大規模なデータ セットの検出には通常、多大な人的および物的投資が必要なため、コンピュータ ビジョンの分野で広く応用するにはさらに開発が必要です。通常、オブジェクト検出 (コンピューター ビジョンのサブセット) では、画像内のオブジェクトは境界ボックスを定義することによって配置されます。オブジェクトを識別できるだけでなく、コンテキスト、サイズ、オブジェクトとシーン内の他の要素との関係も把握できます。関係性も理解できます。同時に、クラスの分布、オブジェクト サイズの多様性、クラスが出現する一般的な環境を包括的に理解することは、評価とデバッグ中にトレーニング モデル内のエラー パターンを発見するのにも役立ちます。
 Pythonによるディープラーニング事前学習モデルの詳細説明
Jun 11, 2023 am 08:12 AM
Pythonによるディープラーニング事前学習モデルの詳細説明
Jun 11, 2023 am 08:12 AM
人工知能と深層学習の発展に伴い、事前トレーニング モデルは、自然言語処理 (NLP)、コンピューター ビジョン (CV)、音声認識などの分野で一般的なテクノロジーになりました。現在最も人気のあるプログラミング言語の 1 つである Python は、当然のことながら、事前トレーニングされたモデルの適用において重要な役割を果たします。この記事では、Python のディープラーニング事前トレーニング モデルに焦点を当て、その定義、種類、アプリケーション、事前トレーニング モデルの使用方法について説明します。事前トレーニング済みモデルとは何ですか?深層学習モデルの主な困難は、高品質のデータを大量に分析することです。
 知識強化と事前トレーニングされた大規模モデルに基づくクエリ意図認識
May 19, 2023 pm 02:01 PM
知識強化と事前トレーニングされた大規模モデルに基づくクエリ意図認識
May 19, 2023 pm 02:01 PM
1. 背景 はじめに 近年、エンタープライズデジタル化が注目されており、人工知能、ビッグデータ、クラウドコンピューティングなどの新世代デジタル技術を活用して企業のビジネスモデルを変革し、企業ビジネスの新たな成長を促進することを指します。 。企業のデジタル化には、通常、業務運営のデジタル化と企業管理のデジタル化が含まれます。この共有化では主に企業管理レベルのデジタル化を導入します。情報のデジタル化とは、簡単に言えば、デジタル的な方法で情報を読み取り、書き込み、保存し、送信することを意味します。以前の紙の文書から現在の電子文書やオンラインで共同作業を行う文書に至るまで、情報のデジタル化は今日のオフィスの新たな常態となっています。現在、アリババはビジネス コラボレーションに DingTalk ドキュメントと Yuque ドキュメントを使用しており、オンライン ドキュメントの数は 2,000 万件以上に達しています。さらに、多くの企業は社内で
 MITが「Advanced Mathematics」ソルバーの強化版をリリース:7コースで正解率が81%に到達
Apr 12, 2023 pm 04:04 PM
MITが「Advanced Mathematics」ソルバーの強化版をリリース:7コースで正解率が81%に到達
Apr 12, 2023 pm 04:04 PM
小学校の算数の文章題を解くだけでなく、高度な算数もAIが攻略し始めています!最近、MIT の研究者は、OpenAI Codex 事前トレーニング モデルに基づいて、数回の学習で学部レベルの数学の問題について 81% の正解率を達成することに成功したと発表しました。論文のリンク: https://arxiv.org/abs/2112.15594 コードのリンク: https://github.com/idrori/mathq まず、グラフの回転の計算など、答えを確認するためにいくつかの小さな質問を見てみましょう。軸を中心とした単一変数関数、体積、ローレンツ アトラクターと射影の計算、特異値分解 (SVD) の幾何学計算と描画、正しく解くことができるだけでなく、
 バリアフリーで旅行も安心! ByteDanceの研究成果がCVPR2022 AVAコンペティションチャンピオンシップで優勝
Apr 08, 2023 pm 11:01 PM
バリアフリーで旅行も安心! ByteDanceの研究成果がCVPR2022 AVAコンペティションチャンピオンシップで優勝
Apr 08, 2023 pm 11:01 PM
このほど、CVPR2022の各種コンペティションの結果が発表され、ByteDanceの知的創造AIプラットフォーム「Byte-IC-AutoML」チームが、自社開発した合成データに基づくAccessibility Vision and Autonomy Challenge(以下、AVA)で優勝した。 Parallel Pre-trained Transformers (PPT) フレームワークは、コンテストの唯一のトラックの勝者として際立っていました。論文アドレス: https://arxiv.org/abs/2206.10845 この AVA コンテストはボストン大学 (Bos) によって後援されています。
 強化学習の第一人者であるセルゲイ・レヴィンの新作: 3 つの大きなモデルがロボットに自分の進むべき道を認識するよう教える
Apr 12, 2023 pm 11:55 PM
強化学習の第一人者であるセルゲイ・レヴィンの新作: 3 つの大きなモデルがロボットに自分の進むべき道を認識するよう教える
Apr 12, 2023 pm 11:55 PM
大規模なモデルが組み込まれたロボットが、地図を見ずに言語の指示に従って目的地に到達することを学習しました。この成果は、強化学習の第一人者であるセルゲイ・レヴィン氏の新しい研究によってもたらされました。目的地が与えられた場合、ナビゲーション トラックなしで目的地に正常に到達することはどれほど難しいでしょうか?この作業は、方向感覚が苦手な人間にとっても非常に困難です。しかし、最近の研究では、数人の学者が、事前に訓練された 3 つのモデルのみを使用してロボットを「教育」したことがわかりました。ロボット学習の中核的な課題の 1 つは、人間の高度な指示に従ってロボットがさまざまなタスクを実行できるようにすることであることは誰もが知っています。そのためには、人間の指示を理解し、現実世界でこれらの指示を実行するためのさまざまなアクションを備えたロボットが必要です。ナビゲーションの説明については
 ChatGPT PHP 技術分析: 事前トレーニングされたモデルを使用してインテリジェントなチャット アプリケーションを構築する方法
Oct 24, 2023 am 11:47 AM
ChatGPT PHP 技術分析: 事前トレーニングされたモデルを使用してインテリジェントなチャット アプリケーションを構築する方法
Oct 24, 2023 am 11:47 AM
ChatGPTPHP 技術分析: 事前トレーニング済みモデルを使用してインテリジェントなチャット アプリケーションを構築する方法 今日の情報化時代において、インテリジェントなチャット アプリケーションは日常生活とビジネスに不可欠な部分になっています。スマート チャット アプリケーションは、ユーザーが自然言語でコミュニケーションし、質問や提案に対してリアルタイムで回答できるようにします。最近オープンソースになった ChatGPT プロジェクトは、インテリジェントなチャット アプリケーションを構築する効果的な方法を提供します。この記事では、PHP プログラミング言語と事前トレーニング済みモデルを組み合わせてインテリジェントなチャット アプリケーションを構築し、提供する方法を詳しく紹介します。
 事前トレーニングされたモデルに基づく金融イベントの分析とアプリケーション
Jun 12, 2023 am 11:15 AM
事前トレーニングされたモデルに基づく金融イベントの分析とアプリケーション
Jun 12, 2023 am 11:15 AM
1. 金融イベント分析の主なタスク 金融イベント分析の主なタスクは 3 つの部分に分けることができます。 ① 最初の部分は、非構造化データのインテリジェントな分析です。金融分野の情報は、インターネットの情報とは異なる特徴があります。金融分野の情報は構造化されていない形式で存在することが多く、PDF などの特殊なファイル形式が存在するため、ファイルやデータからクリーンで正確なデータを抽出することがより困難になります。 PDF 形式は植字および印刷形式であり、他のファイル形式ほど明確な段落はありません。 PDF は植字に特化しているため、ファイル内に位置情報は一部しかありません。非構造化データから正確にフォーマットされ、意味的に明確なテキストを解析することはさらに困難です。また、ドキュメント内の形式のセマンティクスが不明瞭な場合は、
