

いつでもどこでもすべてのピクセルを追跡し、障害物さえ恐れない「すべてを追跡」ビデオ アルゴリズムが登場しました。

少し前に、Meta は、あらゆる画像やビデオ内のあらゆるオブジェクトのマスクを生成できる「Segment Everything (SAM)」AI モデルをリリースしました。これにより、コンピューター ビジョン (CV) 分野の研究者は次のように叫びました。 「履歴書が存在しません」。その後、CVの分野では「二次創作」の波が起こり、セグメンテーションに基づいてターゲット検出や画像生成などの機能を次々と組み合わせた作品もありましたが、静止画像をベースとした研究がほとんどでした。
今回、「Tracking Everything」と呼ばれる新しい研究では、オブジェクトの動きを正確かつ完全に追跡できる、ダイナミック ビデオにおける動き推定の新しい方法が提案されています。

この研究は、コーネル大学、Google Research、カリフォルニア大学バークレー校の研究者によって主導されました。研究者たちは協力して研究しました。彼らは共同で、完全かつグローバルに一貫した動き表現である OmniMotion を提案し、ビデオ内のすべてのピクセルに対して正確かつ完全な動き推定を実行するための新しいテスト時間最適化手法を提案しました。

- 紙のアドレス: https://arxiv.org/abs/2306.05422 #プロジェクトのホームページ: https://omnimotion.github.io/
- #一部のネチズンがこれを推奨していますこの研究はわずか1日でリツイートされ、3,500件の「いいね!」を獲得するなど、研究内容は好評でした。
 研究によって公開されたデモから判断すると、動きを追跡するなど、モーション トラッキングの効果は非常に優れています。カンガルーのジャンプの軌跡:
研究によって公開されたデモから判断すると、動きを追跡するなど、モーション トラッキングの効果は非常に優れています。カンガルーのジャンプの軌跡:
スイング運動曲線: 
 #モーション トラッキング ステータスをインタラクティブに表示することもできます。
#モーション トラッキング ステータスをインタラクティブに表示することもできます。
##次のような場合でも、モーション トラッキング ステータスを追跡できます。オブジェクトがブロックされています。たとえば、犬が走っているときに木にブロックされます: 
#コンピュータ ビジョンの分野では、次の 2 つが考えられます。一般的に使用される動き推定方法: まばらな特徴追跡と密なオプティカル フロー。ただし、どちらの方法にも独自の欠点があり、疎な特徴追跡ではすべてのピクセルの動きをモデル化できず、密なオプティカル フローでは長時間の動きの軌跡を捉えることができません。

この研究で提案されたオムニモーションは、準 3D 正準ボリュームを使用してビデオを特徴付け、ローカル空間と正準空間の間の全単射を通じて各ピクセルを追跡します。この表現により、グローバルな一貫性が実現され、オブジェクトが遮られている場合でもモーション トラッキングが可能になり、カメラとオブジェクトのモーションのあらゆる組み合わせがモデル化されます。この研究は、提案された方法が既存の SOTA 方法よりも大幅に優れていることを実験的に示しています。
方法の概要
この調査では、一対のノイズの多い動き推定 (オプティカル フロー フィールドなど) を含むフレームのコレクションを入力として取り、ビデオ全体の完全でグローバルに一貫した動き表現を形成します。その後、この研究では、ビデオ全体で滑らかで正確な動きの軌跡を生成するために、任意のフレーム内の任意のピクセルで表現をクエリできるようにする最適化プロセスを追加しました。特に、この方法では、フレーム内のポイントがいつオクルージョンされるかを特定でき、オクルージョンを通じてポイントを追跡することもできます。
OmniMotion の特性評価
オブジェクトが遮られた場合の従来のモーション推定方法 (ペアワイズ オプティカル フローなど)オブジェクトは失われます。オクルージョン下でも正確で一貫した運動軌跡を提供するために、この研究ではグローバル運動表現 OmniMotion を提案します。
この研究では、明示的な動的 3D 再構成を行わずに、現実世界の動きを正確に追跡することを試みます。 OmniMotion 表現は、ビデオ内のシーンを正準 3D ボリュームとして表し、ローカル正準全単射を通じて各フレーム内のローカル ボリュームにマッピングされます。ローカルの正準全単射はニューラル ネットワークとしてパラメータ化され、カメラとシーンの動きを 2 つ分離せずにキャプチャします。このアプローチに基づいて、ビデオは固定された静的カメラのローカル ボリュームからのレンダリング結果として表示されます。
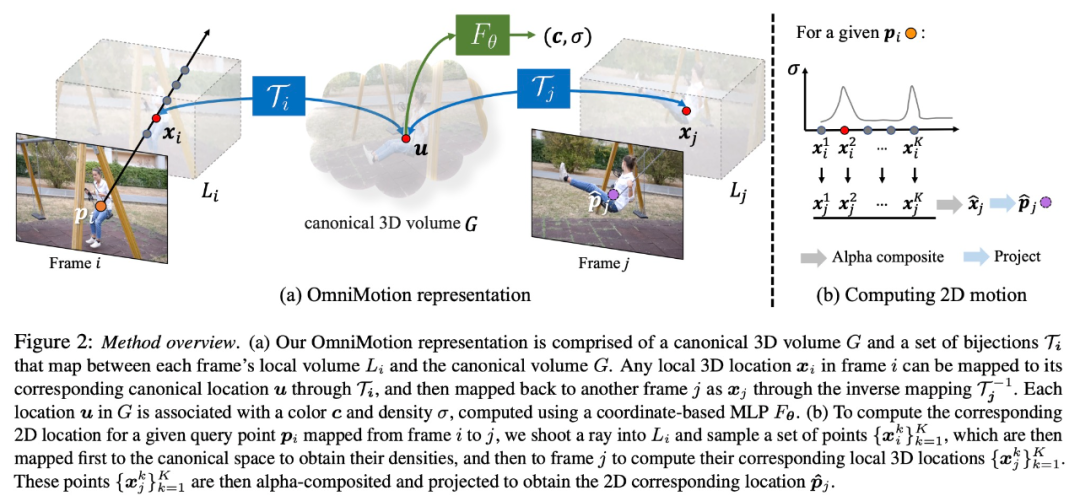
# OmniMotion はカメラとシーンの動きを明確に区別しないため、形成される表現は物理的に正確な 3D シーンの再構成ではありません。 。したがって、この研究ではこれを準 3D 特性評価と呼んでいます。
OmniMotion は、各ピクセルに投影されたすべてのシーン ポイントとその相対的な深さの順序に関する情報を保持するため、一時的にトラックが遮られた場合でもフレーム内のポイントを移動できます。

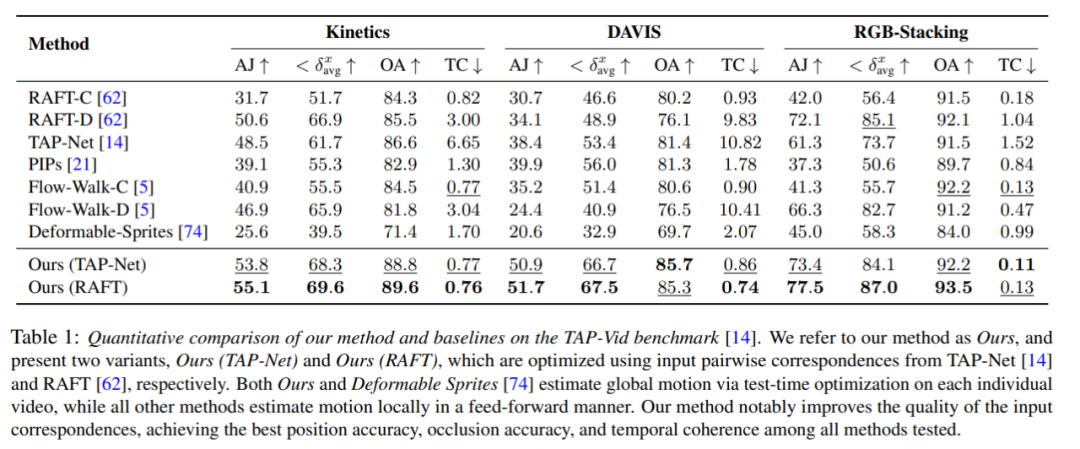
定量的比較
研究者らは、提案された手法と TAP-Vid ベンチマークを比較しました。その結果を表 1 に示します。さまざまなデータセット上で、彼らの方法は常に最高の位置精度、オクルージョン精度、タイミングの一貫性を達成していることがわかります。彼らの方法は、RAFT と TAP-Net からのさまざまなペアごとの対応入力を適切に処理し、両方のベースライン方法に比べて一貫した改善を提供します。
#定性的な比較
図 3 に示すように、研究者は、方法はベースライン方法と定性的に比較されます。新しい方法は、(長い) オクルージョン イベント中に優れた認識および追跡機能を示し、オクルージョン中にポイントの合理的な位置を提供し、大きなカメラの動きの視差を処理します。

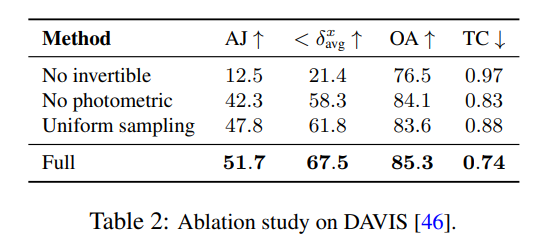
研究者は、アブレーション実験を使用して設計上の決定の有効性を検証しました。その結果を表 2 に示します。
 # 図 4 では、学習された深さの並べ替えを示すために、モデルによって生成された疑似深度マップが示されています。
# 図 4 では、学習された深さの並べ替えを示すために、モデルによって生成された疑似深度マップが示されています。
これらの図は物理的な深さに対応していないことに注意してください。ただし、測光信号とオプティカル フロー信号のみを使用する場合、新しい方法が異なる表面間の相対的な順序を効果的に決定できることを示しています。オクルージョンにおける追跡は重要です。追加のアブレーション実験と分析結果は補足資料でご覧いただけます。
以上がいつでもどこでもすべてのピクセルを追跡し、障害物さえ恐れない「すべてを追跡」ビデオ アルゴリズムが登場しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7517
7517
 15
1378
52
79
11
21
66
15
1378
52
79
11
21
66

 動画ファイルはブラウザのキャッシュのどこに保存されますか?
Feb 19, 2024 pm 05:09 PM
動画ファイルはブラウザのキャッシュのどこに保存されますか?
Feb 19, 2024 pm 05:09 PM
ブラウザはビデオをどのフォルダにキャッシュしますか? 私たちは毎日インターネット ブラウザを使用するときに、YouTube でミュージック ビデオを視聴したり、Netflix で映画を視聴したりするなど、さまざまなオンライン ビデオを視聴することがよくあります。これらのビデオは読み込みプロセス中にブラウザによってキャッシュされるため、将来再び再生するときにすぐに読み込むことができます。そこで問題は、これらのキャッシュされたビデオが実際にどのフォルダーに保存されるのかということです。ブラウザーが異なれば、キャッシュされたビデオ フォルダーは異なる場所に保存されます。以下に、いくつかの一般的なブラウザとそのブラウザを紹介します。
 他人の動画をDouyinに投稿することは侵害になりますか?侵害せずにビデオを編集するにはどうすればよいですか?
Mar 21, 2024 pm 05:57 PM
他人の動画をDouyinに投稿することは侵害になりますか?侵害せずにビデオを編集するにはどうすればよいですか?
Mar 21, 2024 pm 05:57 PM
ショートビデオプラットフォームの台頭により、Douyinはみんなの日常生活に欠かせないものになりました。 TikTokでは世界中の面白い動画を見ることができます。他人のビデオを投稿することを好む人もいますが、「Douyin は他人のビデオを投稿することを侵害しているのでしょうか?」という疑問が生じます。この記事では、この問題について説明し、著作権を侵害せずに動画を編集する方法と、著作権侵害の問題を回避する方法について説明します。 1.Douyin による他人の動画の投稿は侵害ですか?私の国の著作権法の規定によれば、著作権者の著作物を著作権者の許可なく無断で使用することは侵害となります。したがって、オリジナルの作者または著作権所有者の許可なしに他人のビデオをDouyinに投稿することは侵害となります。 2. 著作権を侵害せずにビデオを編集するにはどうすればよいですか? 1. パブリックドメインまたはライセンスされたコンテンツの使用: パブリック
 Wink でビデオの透かしを削除する方法
Feb 23, 2024 pm 07:22 PM
Wink でビデオの透かしを削除する方法
Feb 23, 2024 pm 07:22 PM
Wink でビデオからウォーターマークを削除するにはどうすればよいですか? winkAPP にはビデオからウォーターマークを削除するツールがありますが、ほとんどの友達は wink でビデオからウォーターマークを削除する方法を知りません。次は Wink でビデオからウォーターマークを削除する方法の画像です。編集者が持参したテキストチュートリアルですので、興味のある方はぜひ見に来てください! Wink でビデオ透かしを削除する方法 1. まず、Wink APP を開き、ホームページ領域で [透かしを削除] 機能を選択します; 2. 次に、アルバムで透かしを削除したいビデオを選択します; 3. 次に、ビデオを選択してクリックしますビデオ編集後、右上隅にある [√]; 4. 最後に、下図のように [ワンクリック印刷] をクリックし、[処理] をクリックします。
 Douyin に動画を投稿して収益を得るにはどうすればよいですか?初心者はどうやってDouyinでお金を稼ぐことができますか?
Mar 21, 2024 pm 08:17 PM
Douyin に動画を投稿して収益を得るにはどうすればよいですか?初心者はどうやってDouyinでお金を稼ぐことができますか?
Mar 21, 2024 pm 08:17 PM
全国的なショートビデオプラットフォームであるDouyinは、自由な時間にさまざまな興味深く斬新なショートビデオを楽しむことができるだけでなく、自分自身を示し、自分の価値観を実現するステージも提供します。では、Douyin に動画を投稿してお金を稼ぐにはどうすればよいでしょうか?この記事ではこの質問に詳しく答え、TikTokでより多くのお金を稼ぐのに役立ちます。 1.Douyin に動画を投稿してお金を稼ぐにはどうすればよいですか?動画を投稿し、Douyin で一定の再生回数を獲得すると、広告共有プランに参加できるようになります。この収入方法はDouyinユーザーにとって最も馴染みのある方法の1つであり、多くのクリエイターにとって主な収入源でもあります。 Douyin は、アカウントの重み、動画コンテンツ、視聴者のフィードバックなどのさまざまな要素に基づいて、広告共有の機会を提供するかどうかを決定します。 TikTok プラットフォームでは、視聴者がギフトを送ったり、
 iPhoneのビデオからスローモーションを削除する2つの方法
Mar 04, 2024 am 10:46 AM
iPhoneのビデオからスローモーションを削除する2つの方法
Mar 04, 2024 am 10:46 AM
iOS デバイスでは、カメラ アプリを使用してスローモーション ビデオを撮影できます。最新の iPhone を使用している場合は、1 秒あたり 240 フレームのビデオを撮影することもできます。この機能により、高速アクションを詳細にキャプチャできます。ただし、ビデオの詳細やアクションをよりよく理解するために、スローモーション ビデオを通常の速度で再生したい場合もあります。この記事では、iPhone上の既存のビデオからスローモーションを削除するすべての方法を説明します。 iPhoneでビデオからスローモーションを削除する方法[2つの方法] 写真アプリまたはiMovieアプリを使用して、デバイス上のビデオからスローモーションを削除できます。方法 1: 写真アプリを使用して iPhone で開く
 小紅書ビデオ作品を公開するにはどうすればよいですか?動画を投稿する際に注意すべきことは何ですか?
Mar 23, 2024 pm 08:50 PM
小紅書ビデオ作品を公開するにはどうすればよいですか?動画を投稿する際に注意すべきことは何ですか?
Mar 23, 2024 pm 08:50 PM
短編ビデオ プラットフォームの台頭により、Xiaohongshu は多くの人々が自分の生活を共有し、自分自身を表現し、トラフィックを獲得するためのプラットフォームになりました。このプラットフォームでは、ビデオ作品の公開が非常に人気のある交流方法です。では、小紅書ビデオ作品を公開するにはどうすればよいでしょうか? 1.小紅書ビデオ作品を公開するにはどうすればよいですか?まず、共有できるビデオ コンテンツがあることを確認します。携帯電話やその他のカメラ機器を使用して撮影することもできますが、画質と音声の明瞭さには注意する必要があります。 2.ビデオを編集する:作品をより魅力的にするために、ビデオを編集できます。 Douyin、Kuaishou などのプロ仕様のビデオ編集ソフトウェアを使用して、フィルター、音楽、字幕、その他の要素を追加できます。 3. 表紙を選択する: 表紙はユーザーのクリックを誘致するための鍵です。ユーザーのクリックを誘致するために、表紙には鮮明で興味深い写真を選択してください。
 画質を圧縮せずにWeiboに動画を投稿する方法_画質を圧縮せずにWeiboに動画を投稿する方法
Mar 30, 2024 pm 12:26 PM
画質を圧縮せずにWeiboに動画を投稿する方法_画質を圧縮せずにWeiboに動画を投稿する方法
Mar 30, 2024 pm 12:26 PM
1. まず携帯電話で Weibo を開き、右下隅の [Me] をクリックします (図を参照)。 2. 次に、右上隅の [歯車] をクリックして設定を開きます (図を参照)。 3. 次に、[一般設定] を見つけて開きます (図を参照)。 4. 次に、[Video Follow] オプションを入力します (図を参照)。 5. 次に、[ビデオアップロード解像度]設定を開きます(図を参照)。 6. 最後に、圧縮を避けるために [オリジナルの画質] を選択します (図を参照)。
 UC ブラウザでダウンロードしたビデオをローカルビデオに変換する方法
Feb 29, 2024 pm 10:19 PM
UC ブラウザでダウンロードしたビデオをローカルビデオに変換する方法
Feb 29, 2024 pm 10:19 PM
UC ブラウザでダウンロードしたビデオをローカルビデオに変換するにはどうすればよいですか?多くの携帯電話ユーザーは UC Browser を好んで使用しており、Web を閲覧するだけでなく、オンラインでさまざまなビデオやテレビ番組を視聴したり、お気に入りのビデオを携帯電話にダウンロードしたりすることもできます。実は、ダウンロードした動画をローカル動画に変換することもできますが、その方法がわからない人も多いでしょう。したがって、エディターは、UC ブラウザーによってキャッシュされたビデオをローカルビデオに変換する方法を特別に提供します。 uc ブラウザーのキャッシュされたビデオをローカルビデオに変換する方法 1. uc ブラウザーを開き、「メニュー」オプションをクリックします。 2.「ダウンロード/ビデオ」をクリックします。 3. 「キャッシュされたビデオ」をクリックします。 4. 任意のビデオを長押しし、オプションがポップアップ表示されたら、「ディレクトリを開く」をクリックします。 5. ダウンロードしたいものにチェックを入れます
