

8 つの言語で共通の 280 万のマルチモーダル コマンドと応答のペア、ビデオ コンテンツをカバーする初のコマンド データ セット MIMIC-IT が登場

最近、AI 対話アシスタントは言語タスクにおいて大幅な進歩を遂げています。この大幅な改善は、LLM の強力な汎化能力に基づくだけでなく、命令のチューニングにも起因すると考えられます。これには、多様で質の高い指導を通じて、さまざまなタスクに関して LLM を微調整することが含まれます。
命令チューニングでゼロショット パフォーマンスを達成できる潜在的な理由の 1 つは、コンテキストを内部化することです。これは、ユーザー入力が常識的なコンテキストをスキップする場合に特に重要です。命令チューニングを組み込むことで、LLM はユーザーの意図を高度に理解できるようになり、これまで目に見えなかったタスクでも優れたゼロショット機能を発揮します。
ただし、理想的な AI 会話アシスタントは、複数のモダリティが関係するタスクを解決できる必要があります。これには、データセットに従って多様で高品質なマルチモーダルな命令を取得する必要があります。たとえば、LLaVAInstruct-150K データセット (LLaVA としても知られています) は、一般的に使用される視覚的言語指示に従うデータセットであり、COCO 画像、画像キャプションおよび GPT-4 Constructed から取得したターゲット境界ボックスに基づく指示と応答を使用します。ただし、LLaVA-Instruct-150K には 3 つの制限があります: 視覚的多様性が制限されていること、単一の視覚データとして画像を使用していること、および言語形態のみを含む文脈情報です。
AI 対話アシスタントによるこれらの限界の突破を促進するために、シンガポールの南洋理工大学とレドモンドのマイクロソフト研究所の学者は、マルチモーダル コンテキスト命令チューニング データ セット MIMIC を提案しました。 IT は、さまざまな現実のシナリオをカバーする、280 万のマルチモーダル コンテキストの命令と応答のペアを含むデータセットです。

#論文アドレス: https://arxiv.org/pdf/2306.05425.pdf
さらに、命令と応答のペアを効率的に生成するために、研究者らは、自己命令メソッドにヒントを得た命令と応答のアノテーションの自動パイプラインである「Sythus」も導入しました。 Sythus は、システム情報、視覚的な注釈、およびコンテキスト内の例を使用して、言語モデル (GPT-4 または ChatGPT) をガイドし、視覚的なコンテキストに基づいてコマンドと応答のペアを生成します。これは、視覚的言語モデルの 3 つの基本的な機能である知覚、推論、および視覚的なコンテキストに基づいて生成されます。計画中。さらに、英語のコマンドと応答は7か国語に翻訳され、多言語での使用をサポートします。
研究者らが OpenFlamingo に基づくマルチモーダル モデル「Otter」を MIMIC-IT 上でトレーニングしたことは特に注目に値します。 ChatGPT と人間の両方で評価された Otter のマルチモーダル機能は、他の最近の視覚言語モデルを上回っています。
研究者らは一連のデモで、Otter のマルチモーダルな質問と回答機能を実証しました。
Q: 次にプレイされるカードはどれですか? ?
#A: チューブは 8 本です。こうすることで、ストレートを待ち続けることができます。

#A: 左下のボタンを 1 回押して左に曲がり、着陸するときに右側のハンドブレーキを引きます。
#Q: 次に何をしますか?

#次に、研究の詳細を見てみましょう。
MIMIC-IT データセット
MIMIC-IT データセットには、認識、推論、計画といった基本的な機能をカバーする、280 万のマルチモーダルな命令と応答のペアが含まれています。各命令にはマルチモーダルな会話コンテキストが伴うため、MIMIC-IT でトレーニングされた VLM が対話型命令で優れた習熟度を示し、ゼロショット汎化を実行できるようになります。
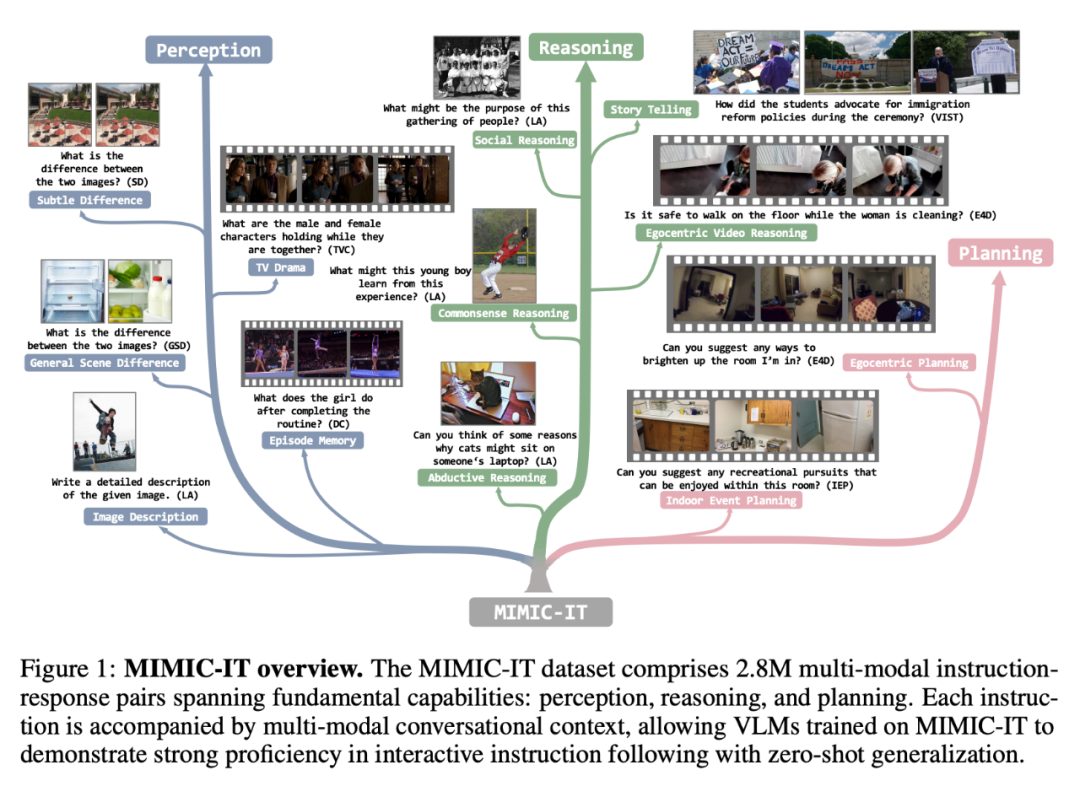
LLaVA と比較した場合、MIMIC-IT の特徴は次のとおりです。
# (1) 一般的なシーン、自己中心的な視点シーン、屋内 RGB-D 画像など、さまざまなデータ セットからの画像やビデオを含む多様なビジュアル シーン;(2) 詳細画像 (またはビデオ)を視覚データとして;
(3) 複数のコマンドと応答のペアおよび複数の画像またはビデオを含むマルチモーダル コンテキスト情報;
(4) 英語、中国語、スペイン語、日本語、フランス語、ドイツ語、韓国語、アラビア語を含む 8 つの言語をサポートします。
#次の図は、この 2 つのコマンドと応答の比較を示しています (黄色のボックスは LLaVA)。

Sythus: 自動コマンド応答ペア生成パイプライン
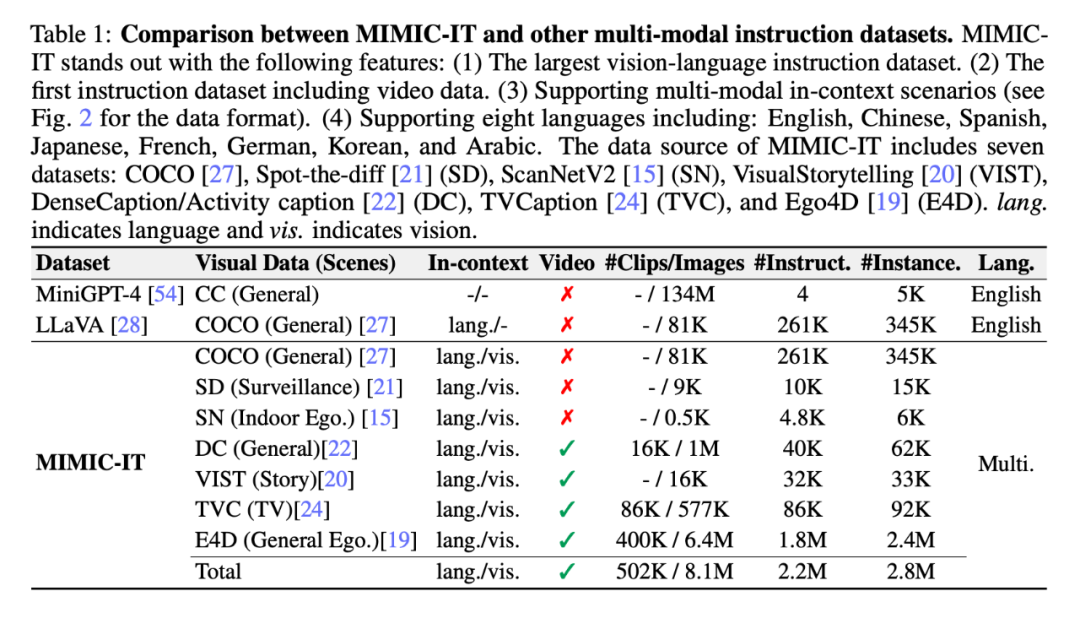
コア セットの品質はその後のデータ収集プロセスに影響を与えるため、研究者らはコールド スタート戦略を採用し、大規模なクエリを実行する前にコンテキスト内のサンプルを強化しました。コールド スタート フェーズでは、ヒューリスティックなアプローチが採用され、ChatGPT がシステム情報と視覚的な注釈を通じてのみコンテキスト内でサンプルを収集するように指示されます。このフェーズは、満足のいくコンテキスト内のサンプルが特定された後にのみ終了します。 4 番目のステップでは、コマンドと応答のペアが取得されると、パイプラインはそれらを中国語 (zh)、日本語 (ja)、スペイン語 (es)、ドイツ語 (de)、フランス語 (fr)、韓国語 (ko)、およびアラビア語に展開します。 (ar)。詳細については付録 C を、特定のタスク プロンプトについては付録 D を参照してください。
 実験的評価
実験的評価
研究者らはその後、視覚言語モデルのさまざまなアプリケーションと潜在的な機能を実証しました ( VLM) でトレーニングされました。まず、研究者らは、MIMIC-IT データセットを使用して開発されたコンテキスト命令調整モデルである Otter を紹介しました。次に研究者らは、MIMIC-IT データセットで Otter をトレーニングするさまざまな方法を検討し、Otter を効果的に使用できる多くのシナリオについて議論しました。
図 5 は、さまざまなシナリオにおける Otter の応答の例です。 MIMIC-IT データセットでのトレーニングのおかげで、Otter は状況の理解と推論、状況に応じたサンプル学習、自己中心的な視覚アシスタントを提供できます。

最後に、研究者らは一連のベンチマーク テストで Otter と他の VLM のパフォーマンスの比較分析を実施しました。
ChatGPT の評価
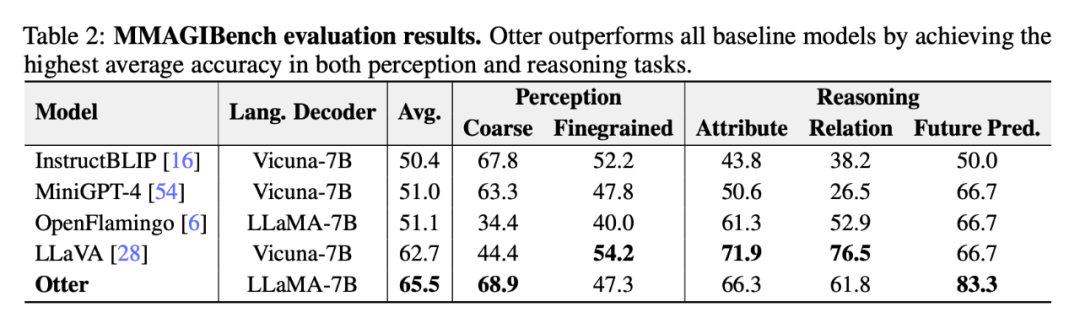
以下の表 2 は、MMAGIBench フレームワークを使用した視覚言語モデルの研究者による評価を示しています [43] 】 知覚力と推論力が幅広く評価されます。
##人間評価
マルチモダリティアリーナ[32] は、Elo 評価システムを使用して、VLM 応答の有用性と一貫性を評価しています。図 6(b) は、Otter が優れた実用性と一貫性を示し、最近の VLM で最高の Elo 評価を達成していることを示しています。
少数ショットの文脈学習ベンチマーク評価
Otter は、マルチモデルである OpenFlamingo に基づいて微調整されています動的なコンテキスト学習のために設計されたアーキテクチャ。 MIMIC-IT データセットを使用して微調整した後、Otter は COCO Captioning (CIDEr) [27] の数ショット評価で OpenFlamingo を大幅に上回りました (図 6 (c) を参照)。予想どおり、微調整により、ゼロサンプル評価のパフォーマンスもわずかに向上します。

# 図 6: ChatGPT ビデオ理解の評価。 欠陥について話し合う。研究者たちはシステム メッセージとコマンド応答の例を繰り返し改善してきましたが、ChatGPT は言語幻覚を起こしやすいため、誤った応答を生成する可能性があります。多くの場合、より信頼性の高い言語モデルには自己指示データ生成が必要です。
将来の仕事。将来的には、研究者らは、LanguageTable や SayCan など、より具体的な AI データセットをサポートする予定です。研究者らは、命令セットを改善するために、より信頼できる言語モデルや生成技術を使用することも検討しています。
以上が8 つの言語で共通の 280 万のマルチモーダル コマンドと応答のペア、ビデオ コンテンツをカバーする初のコマンド データ セット MIMIC-IT が登場の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7530
7530
 15
1379
52
82
11
21
76
15
1379
52
82
11
21
76

 Terrariaでコマンドを使用してアイテムを取得するにはどうすればよいですか? -Terrariaでアイテムを集めるにはどうすればよいですか?
Mar 19, 2024 am 08:13 AM
Terrariaでコマンドを使用してアイテムを取得するにはどうすればよいですか? -Terrariaでアイテムを集めるにはどうすればよいですか?
Mar 19, 2024 am 08:13 AM
Terrariaでコマンドを使用してアイテムを取得するにはどうすればよいですか? 1. Terraria でアイテムを与えるコマンドは何ですか? Terraria ゲームでは、アイテムにコマンドを与えることは非常に実用的な機能です。このコマンドにより、プレイヤーはモンスターと戦ったり、特定の場所にテレポートしたりすることなく、必要なアイテムを直接入手できます。これにより、時間が大幅に節約され、ゲームの効率が向上し、プレイヤーは世界の探索と構築により集中できるようになります。全体として、この機能によりゲーム体験がよりスムーズで楽しいものになります。 2. Terraria を使用してアイテム コマンドを与える方法 1. ゲームを開き、ゲーム インターフェイスに入ります。 2. キーボードの「Enter」キーを押してチャットウィンドウを開きます。 3. チャットウィンドウにコマンド形式「/give[プレイヤー名][アイテムID][アイテム数量]」を入力します。
 PyTorch を使用した少数ショット学習による画像分類
Apr 09, 2023 am 10:51 AM
PyTorch を使用した少数ショット学習による画像分類
Apr 09, 2023 am 10:51 AM
近年、深層学習ベースのモデルは、物体検出や画像認識などのタスクで優れたパフォーマンスを発揮しています。 1,000 種類の異なるオブジェクト分類を含む ImageNet のような難しい画像分類データセットでは、一部のモデルが人間のレベルを超えています。しかし、これらのモデルは教師ありトレーニング プロセスに依存しており、ラベル付きトレーニング データの利用可能性に大きく影響され、モデルが検出できるクラスはトレーニングされたクラスに限定されます。トレーニング中にすべてのクラスに十分なラベル付き画像がないため、これらのモデルは現実の設定ではあまり役に立たない可能性があります。そして、すべての潜在的なオブジェクトの画像でトレーニングすることはほぼ不可能であるため、モデルがトレーニング中に認識しなかったクラスを認識できるようにしたいと考えています。いくつかのサンプルから学びます
 VUE3 クイック スタート: Vue.js 命令を使用してタブを切り替える
Jun 15, 2023 pm 11:45 PM
VUE3 クイック スタート: Vue.js 命令を使用してタブを切り替える
Jun 15, 2023 pm 11:45 PM
この記事は、初心者が Vue.js3 をすぐに使い始めて、簡単なタブ切り替え効果を実現できるようにすることを目的としています。 Vue.js は、再利用可能なコンポーネントの構築、アプリケーションの状態の簡単な管理、ユーザー インターフェイスの操作の処理に使用できる人気の JavaScript フレームワークです。 Vue.js3 はフレームワークの最新バージョンであり、以前のバージョンと比較して大きな変更が加えられていますが、基本原理は変わっていません。この記事では、読者が Vue.js に慣れることを目的として、Vue.js の命令を使用してタブ切り替え効果を実装します。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 カスタム データセットへの OpenAI CLIP の実装
Sep 14, 2023 am 11:57 AM
カスタム データセットへの OpenAI CLIP の実装
Sep 14, 2023 am 11:57 AM
2021 年 1 月、OpenAI は DALL-E と CLIP という 2 つの新しいモデルを発表しました。どちらのモデルも、テキストと画像を何らかの方法で接続するマルチモーダル モデルです。 CLIP の正式名は Contrastive Language-Image Pre-training (ContrastiveLanguage-ImagePre-training) で、対照的なテキストと画像のペアに基づく事前トレーニング方法です。なぜCLIPを導入するのか?なぜなら、現在人気のStableDiffusionは単一のモデルではなく、複数のモデルで構成されているからです。重要なコンポーネントの 1 つはテキスト エンコーダで、ユーザーのテキスト入力をエンコードするために使用されます。このテキスト エンコーダは、CLIP モデルのテキスト エンコーダ CL です。
 Google AIビデオがまたすごい!オールインワンのユニバーサル ビジュアル エンコーダーである VideoPrism が 30 の SOTA パフォーマンス機能を更新
Feb 26, 2024 am 09:58 AM
Google AIビデオがまたすごい!オールインワンのユニバーサル ビジュアル エンコーダーである VideoPrism が 30 の SOTA パフォーマンス機能を更新
Feb 26, 2024 am 09:58 AM
AIビデオモデルSoraが人気を博した後、MetaやGoogleなどの大手企業は研究を行ってOpenAIに追いつくために手を引いた。最近、Google チームの研究者は、ユニバーサル ビデオ エンコーダー VideoPrism を提案しました。単一の凍結モデルを通じてさまざまなビデオ理解タスクを処理できます。画像ペーパーのアドレス: https://arxiv.org/pdf/2402.13217.pdf たとえば、VideoPrism は、以下のビデオ内でろうそくを吹き飛ばしている人を分類して特定できます。画像ビデオテキスト検索では、テキストコンテンツに基づいて、ビデオ内の対応するコンテンツを検索できます。別の例として、下のビデオについて説明します。小さな女の子が積み木で遊んでいます。 QAの質問と回答もご覧いただけます。
 データセットを正しく分割するにはどうすればよいでしょうか? 3 つの一般的な方法のまとめ
Apr 08, 2023 pm 06:51 PM
データセットを正しく分割するにはどうすればよいでしょうか? 3 つの一般的な方法のまとめ
Apr 08, 2023 pm 06:51 PM
データセットをトレーニング セットに分解すると、モデルを理解するのに役立ちます。これは、モデルを新しい未知のデータに一般化する方法にとって重要です。モデルが過剰適合している場合、新しい未確認のデータに対して適切に一般化できない可能性があります。したがって、良い予測はできません。適切な検証戦略を持つことは、適切な予測を作成し、AI モデルのビジネス価値を活用するための最初のステップです。この記事では、一般的なデータ分割戦略をいくつかまとめました。シンプルなトレーニングとテストの分割では、データセットがトレーニング部分と検証部分に分割され、80% がトレーニング、20% が検証になります。これは、Scikit のランダム サンプリングを使用して行うことができます。まず、ランダム シードを修正する必要があります。修正しないと、同じデータ分割を比較できず、デバッグ中に結果を再現できません。データセットの場合
 PyTorch 並列トレーニング DistributedDataParallel の完全なコード例
Apr 10, 2023 pm 08:51 PM
PyTorch 並列トレーニング DistributedDataParallel の完全なコード例
Apr 10, 2023 pm 08:51 PM
大規模なデータセットを使用して大規模なディープ ニューラル ネットワーク (DNN) をトレーニングするという問題は、ディープ ラーニングの分野における大きな課題です。 DNN とデータセットのサイズが増加するにつれて、これらのモデルをトレーニングするための計算要件とメモリ要件も増加します。そのため、コンピューティング リソースが限られている 1 台のマシンでこれらのモデルをトレーニングすることが困難または不可能になります。大規模なデータセットを使用して大規模な DNN をトレーニングする際の主な課題には次のようなものがあります。 長いトレーニング時間: モデルの複雑さとデータセットのサイズによっては、トレーニング プロセスが完了するまでに数週間、場合によっては数か月かかる場合があります。メモリの制限: 大規模な DNN では、トレーニング中にすべてのモデル パラメーター、勾配、中間アクティベーションを保存するために大量のメモリが必要になる場合があります。これにより、メモリ不足エラーが発生し、単一マシンでトレーニングできる内容が制限される可能性があります。
