

Prompt は音声言語モデル生成機能のロックを解除し、SpeechGen は音声翻訳と複数のタスクのパッチ適用を実装します。


- #論文リンク: https://arxiv.org/pdf/2306.02207.pdf
- ##デモ ページ: https://ga642381.github.io/SpeechPrompt/speechgen.html
- コード: https://github.com /ga642381/SpeechGen ##導入と動機
しかし、大規模な言語モデルを使用して連続音声を処理する方法は未解決の課題のままであり、音声生成における大規模な言語モデルの適用の妨げとなっています。音声信号には、純粋なテキスト データを超えた話者や感情などの豊富な情報が含まれているため、音声ベースの言語モデル (音声 LM) が出現し続けています。
音声言語モデルは、テキストベースの言語モデルに比べてまだ初期段階にありますが、音声データにはテキストよりも豊富な情報が含まれているため、大きな可能性を秘めており、期待に満ちています。
研究者たちは、事前トレーニングされた言語モデルの力を解き放つプロンプト パラダイムの可能性を積極的に研究しています。このプロンプトは、少数のパラメーターを微調整することによって、事前トレーニングされた言語モデルが特定の下流タスクを実行するようにガイドします。この手法は、その効率性と有効性により、NLP 分野で人気があります。音声処理の分野では、SpeechPrompt はパラメータ効率の大幅な向上を実証し、さまざまな音声分類タスクで競争力のあるパフォーマンスを達成しました。
ただし、音声言語モデルが生成タスクを完了するのにヒントが役立つかどうかは、まだ未解決の問題です。この論文では、生成タスクのための音声言語モデルの可能性を解き放つことを目的とした、革新的な統一フレームワークである SpeechGen を提案します。以下の図に示すように、音声と特定のプロンプト (プロンプト) が入力として音声 LM に供給され、音声 LM は特定のタスクを実行できます。たとえば、赤色のプロンプトが入力として使用される場合、音声 LM は音声翻訳のタスクを実行できます。
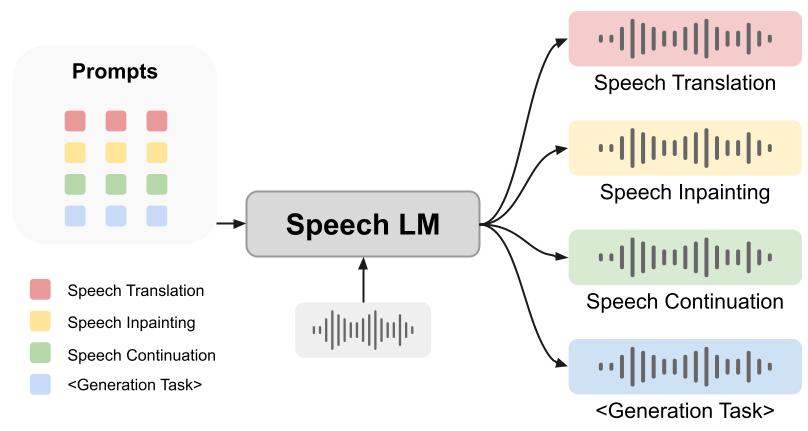
1. テキストレス: 私たちはフレームワークと依存する音声言語モデルはテキスト データから独立しており、計り知れない価値があります。結局のところ、テキストと音声を組み合わせて取得するプロセスは時間がかかり面倒であり、言語によっては適切なテキストを作成することさえ不可能です。テキストフリー機能により、強力な音声生成機能がさまざまな言語ニーズに対応できるようになり、全人類に利益をもたらします。
2. 汎用性: 私たちが開発したフレームワークは非常に汎用性が高く、さまざまな音声生成タスクに適用できます。この論文の実験では、例として音声翻訳、音声復元、音声継続性を使用しています。
3. 理解しやすい: 私たちが提案するフレームワークは、さまざまな音声生成タスクに対する一般的なソリューションを提供し、下流のモデルと損失関数の設計を容易にします。
4. 移転可能性: 私たちのフレームワークは、将来のより高度な音声言語モデルに簡単に適応できるだけでなく、効率と有効性をさらに向上させる大きな可能性も秘めています。特に興味深いのは、高度な音声言語モデルの出現により、私たちのフレームワークがさらに強力な発展をもたらすことです。
5. 手頃な価格: 私たちのフレームワークは、巨大な言語モデル全体ではなく、少数のパラメーターのみをトレーニングする必要があるように慎重に設計されています。これにより、計算負荷が大幅に軽減され、GTX 2080 GPU でトレーニング プロセスを実行できるようになります。大学の研究室でも、このような計算オーバーヘッドを許容できます。
SpeechGen の概要
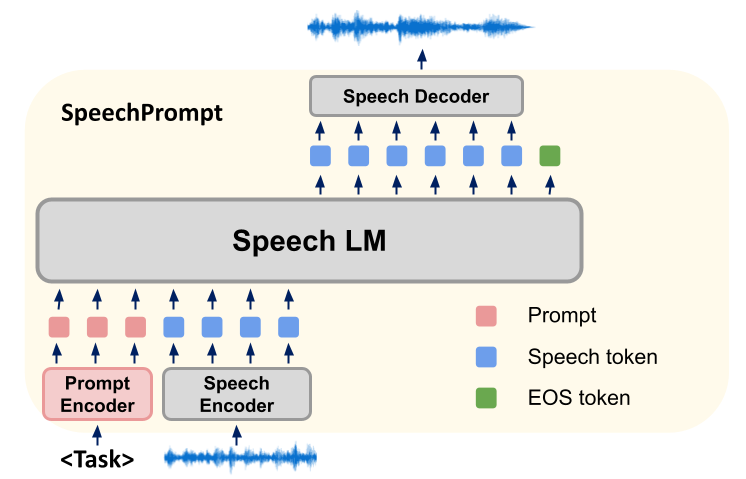
私たちの研究方法は、主に音声言語モデル (Spoken Language Model、SLM) を使用してさまざまな微調整を行う新しいフレームワーク SpeechGen を構築することです。下流の音声生成タスクの調整。トレーニング中、SLM のパラメーターは一定に保たれ、私たちの方法はタスク固有のプロンプト ベクトルの学習に重点を置いています。 SLM は、キュー ベクトルと入力ユニットを同時に調整することで、特定の音声生成タスクに必要な出力を効率的に生成します。これらの個別のユニット出力は、ユニットベースの音声合成装置に入力され、対応する波形が生成されます。
私たちの SpeechGen フレームワークは、音声エンコーダ、SLM、音声デコーダ (Speech Decoder) の 3 つの要素で構成されています。
まず、音声エンコーダは波形を入力として受け取り、それを限られた語彙から派生した一連の単位に変換します。シーケンスの長さを短縮するには、繰り返される連続するユニットが削除され、圧縮されたユニットのシーケンスが生成されます。次に、SLM は一連のユニットの言語モデルとして機能し、一連のユニットの前のユニットと後続のユニットを予測することで尤度を最適化します。 SLM を迅速に調整して、タスクに適切な単位を生成できるようにします。最後に、SLM によって生成されたトークンは音声デコーダによって処理され、波形に変換されます。私たちのキュー調整戦略では、キュー ベクトルが入力シーケンスの先頭に挿入され、生成中に SLM の方向をガイドします。挿入されるヒントの正確な数は、SLM のアーキテクチャによって異なります。シーケンスツーシーケンス モデルでは、キューはエンコーダー入力とデコーダー入力の両方に追加されますが、エンコーダーのみまたはデコーダーのみのアーキテクチャでは、ヒントのみが入力シーケンスの前に追加されます。
シーケンスツーシーケンス SLM (mBART など) では、自己教師あり学習モデル (HuBERT など) を採用して入力音声とターゲット音声を処理します。これにより、入力の離散ユニットと、ターゲットの対応する離散ユニットが生成されます。エンコーダーとデコーダーの両方の入力の前にヒント ベクトルを追加して、入力シーケンスを構築します。さらに、アテンション メカニズムのキーと値のペアを置き換えることにより、キューのガイダンス機能をさらに強化します。
モデルのトレーニングでは、すべての生成タスクの目的関数としてクロスエントロピー損失を使用し、モデルの予測結果をターゲットの離散単位ラベルと比較することで損失を計算します。このプロセスでは、キュー ベクトルはモデル内でトレーニングが必要な唯一のパラメーターですが、SLM のパラメーターはトレーニング プロセス中に変更されないため、モデルの動作の一貫性が保証されます。キュー ベクトルを挿入することで、SLM が入力からタスク固有の情報を抽出し、特定の音声生成タスクと一致する出力を生成する可能性が高まります。このアプローチにより、基礎となるパラメーターを変更することなく、SLM の動作を微調整して調整することができます。
一般に、私たちの研究方法は新しいフレームワーク SpeechGen に基づいています。これは、プロンプト ベクトルをトレーニングすることでモデルの生成プロセスをガイドし、特定の音声を効果的に生成できるようにします。 出力を生成します。タスクの。
実験
私たちのフレームワークは、あらゆる音声 LM やさまざまな生成タスクに使用でき、大きな可能性を秘めています。私たちの実験では、VALL-E と AudioLM はオープンソースではないため、ケーススタディの音声 LM として Unit mBART を使用することを選択しました。私たちのフレームワークの機能を示す例として、音声翻訳、音声修復、音声継続を使用します。これら 3 つのタスクの概略図を以下に示します。すべてのタスクは音声入力、音声出力であり、テキストによるヘルプは必要ありません。
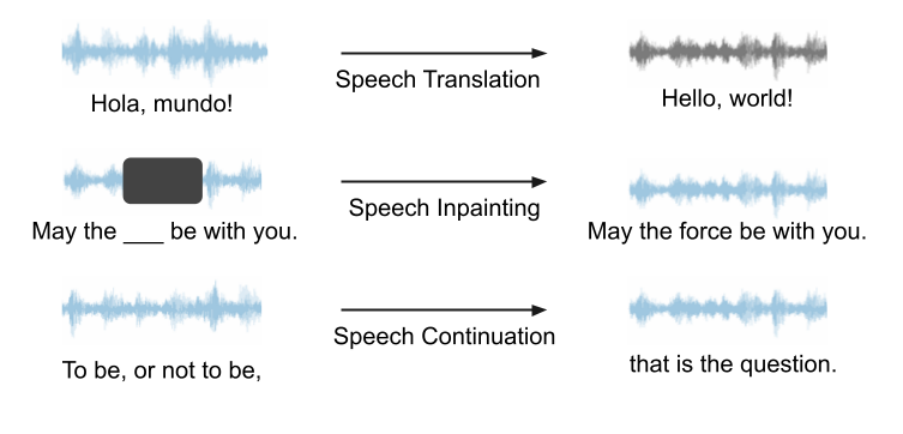
#音声翻訳
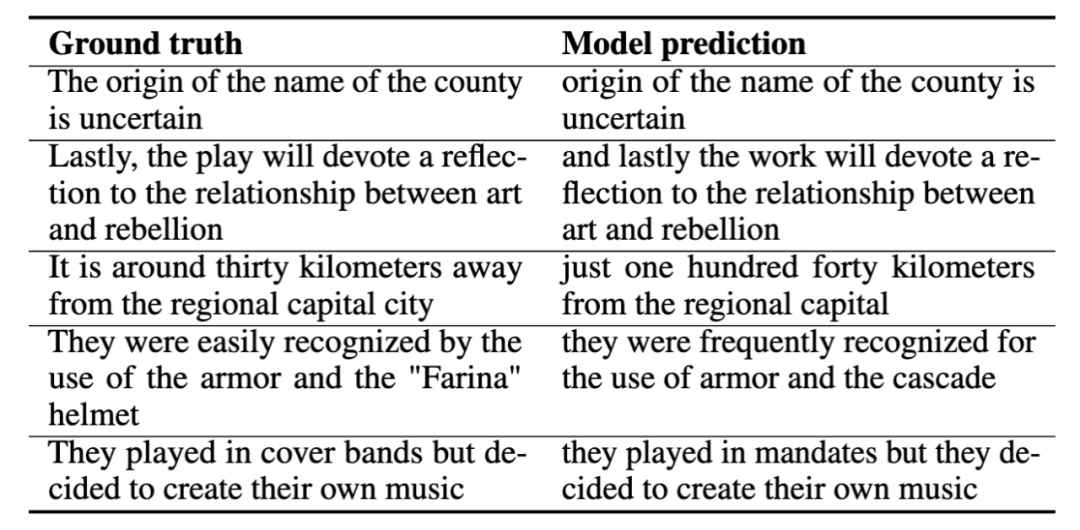
トレーニング中です音声翻訳を行う場合は、スペイン語から英語へのタスクが使用されます。スペイン語の音声をモデルに入力し、モデルがプロセス全体でテキストの助けなしで英語の音声を生成することを期待します。以下に音声翻訳の例をいくつか示します。正解 (グラウンド トゥルース) とモデル予測 (モデル予測) を示します。これらのデモンストレーション例は、モデルの予測が正解の中心的な意味を捉えていることを示しています。
音声修復
音声修復の実験では、特に 2.5 秒を超える音声クリップを対象にしました。後続の処理のターゲット音声として選択され、ランダム選択プロセスを通じて 0.8 ~ 1.2 秒の範囲の継続時間の音声クリップが選択されます。次に、選択したセグメントをマスクして、音声修復タスクで欠落または破損した部分をシミュレートします。損傷セグメントの修復の程度を評価するための指標として単語誤り率 (WER) と文字誤り率 (CER) を使用しました。
SpeechGen によって生成された出力と損傷した音声の比較分析により、私たちのモデルは話し言葉を大幅に再構築し、WER を 41.68% から 28.61% に、CER を 25.10% から 10.75% に削減できます。以下の表に示すように。これは、私たちが提案する方法が音声再構成の能力を大幅に向上させ、最終的に音声出力の正確さと理解しやすさを促進できることを意味します。

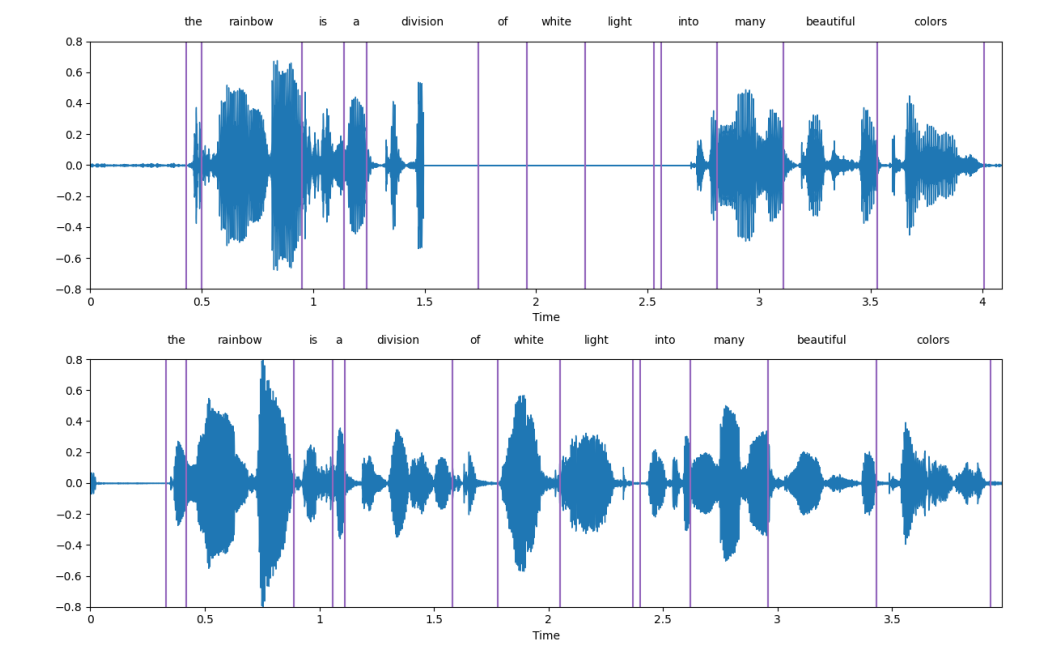
次の図は表示例です。上のサブ画像は破損した音声、下のサブ画像は、写真は SpeechGen によって生成された音声です。SpeechGen が損傷した音声を非常にうまく修復していることがわかります。
#連続音声
合格しますLJSpeech は、音声連続タスクの実際的なアプリケーションを示します。トレーニング プロンプト (プロンプト) 中に、私たちの戦略は、モデルにフラグメントのシード セグメントのみを表示させることです。このシード セグメントは、音声の全長の一部を占めます。これを条件比 (条件比、r) と呼びます。 、そしてモデルは後続の音声を生成し続けます。
以下はいくつかの例です。黒いテキストはシード セグメントを表し、赤いテキストは SpeechGen によって生成された文です (ここでのテキストは音声認識によって最初に取得されます。トレーニング中および推論プロセス中、モデルは音声合成タスクを完全に実行し、テキスト情報をまったく受け取りません)。異なる条件比率により、SpeechGen はさまざまな長さの文を生成して一貫性を実現し、完全な文を完成させることができます。品質の観点から見ると、生成された文は基本的にシード フラグメントと構文的に一貫しており、意味的に関連しています。ただし、生成された音声はまだ完全な意味を完全に伝えることはできません。この問題は、将来、より強力な音声モデルで解決されると予想されます。
欠点と今後の方向性# 音声言語モデルと音声生成は急成長段階にあり、私たちのフレームワークは強力な言語モデルを賢く活用する方法を提供します 音声生成の可能性。しかし、この枠組みにはまだ改善の余地があり、さらに検討する価値のある問題が数多くあります。
1. テキストベースの言語モデルと比較すると、音声言語モデルはまだ開発の初期段階にあります。私たちが提案したキューイング フレームワークは、音声言語モデルに音声生成タスクを実行させることはできますが、優れたパフォーマンスを達成することはできません。ただし、GSLM から Unit mBART への大転換など、音声言語モデルの継続的な進歩により、プロンプトのパフォーマンスは大幅に向上しました。特に、以前は GSLM にとって困難であったタスクが、Unit mBART の下でより優れたパフォーマンスを示すようになりました。将来的には、より高度な音声言語モデルが登場すると予想されます。
2. コンテンツ情報を超えて: 現在の音声言語モデルは話者や感情の情報を完全には捉えることができず、この情報を効果的に処理する際の現在の音声プロンプト フレームワークに課題をもたらしています。この制限を克服するために、話者と感情の情報をフレームワークに特別に注入するプラグアンドプレイ モジュールを導入します。今後、将来の音声言語モデルでは、パフォーマンスを向上させ、音声生成タスクの話者と感情に関連する側面をより適切に処理するために、これらを超えた情報が統合および活用されることが予想されます。
3. プロンプト生成の可能性: プロンプト生成には柔軟なオプションがあり、テキストや画像の指示を含むさまざまなタイプの指示を統合できます。この記事のように、トレーニングされた埋め込みをヒントとして使用する代わりに、画像またはテキストを入力として受け取るようにニューラル ネットワークをトレーニングできると想像してください。この訓練されたネットワークはヒント生成器となり、フレームワークに多様性を加えます。このアプローチにより、プロンプト生成がより面白く、カラフルになります。
結論
この論文では、さまざまな生成タスクにわたって音声言語モデルのパフォーマンスを解き放つためのヒントの使用について検討しました。私たちは、SpeechGen と呼ばれる統合フレームワークを提案します。このフレームワークには、トレーニング可能なパラメーターが 1,000 万個しかありません。私たちが提案するフレームワークには、テキスト不要、多用途性、効率性、転送可能性、手頃な価格など、いくつかの主要な特性があります。 SpeechGen フレームワークの機能を実証するために、Unit mBART をケーススタディとして使用し、音声翻訳、音声修復、音声継続という 3 つの異なる音声生成タスクに関する実験を実施します。
この論文が arXiv に提出されたとき、Google はより高度な音声言語モデル SPECTRON を提案しました。これにより、音声言語モデルが話者と感情などの情報の可能性をモデル化できることが示されました。これは間違いなくエキサイティングなニュースであり、高度な音声言語モデルが提案され続ける中、私たちの統一フレームワークには大きな可能性が秘められています。
以上がPrompt は音声言語モデル生成機能のロックを解除し、SpeechGen は音声翻訳と複数のタスクのパッチ適用を実装します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7554
7554
 15
1382
52
83
11
24
96
15
1382
52
83
11
24
96

 Java フレームワークの商用サポートの費用対効果を評価する方法
Jun 05, 2024 pm 05:25 PM
Java フレームワークの商用サポートの費用対効果を評価する方法
Jun 05, 2024 pm 05:25 PM
Java フレームワークの商用サポートのコスト/パフォーマンスを評価するには、次の手順が必要です。 必要な保証レベルとサービス レベル アグリーメント (SLA) 保証を決定します。研究サポートチームの経験と専門知識。アップグレード、トラブルシューティング、パフォーマンスの最適化などの追加サービスを検討してください。ビジネス サポートのコストと、リスクの軽減と効率の向上を比較検討します。
 PHP フレームワークの学習曲線は他の言語フレームワークと比較してどうですか?
Jun 06, 2024 pm 12:41 PM
PHP フレームワークの学習曲線は他の言語フレームワークと比較してどうですか?
Jun 06, 2024 pm 12:41 PM
PHP フレームワークの学習曲線は、言語熟練度、フレームワークの複雑さ、ドキュメントの品質、コミュニティのサポートによって異なります。 PHP フレームワークの学習曲線は、Python フレームワークと比較すると高く、Ruby フレームワークと比較すると低くなります。 Java フレームワークと比較すると、PHP フレームワークの学習曲線は中程度ですが、開始までの時間は短くなります。
 PHP フレームワークの軽量オプションはアプリケーションのパフォーマンスにどのような影響を与えますか?
Jun 06, 2024 am 10:53 AM
PHP フレームワークの軽量オプションはアプリケーションのパフォーマンスにどのような影響を与えますか?
Jun 06, 2024 am 10:53 AM
軽量の PHP フレームワークは、サイズが小さくリソース消費が少ないため、アプリケーションのパフォーマンスが向上します。その特徴には、小型、高速起動、低メモリ使用量、改善された応答速度とスループット、および削減されたリソース消費が含まれます。 実際のケース: SlimFramework は、わずか 500 KB、高い応答性と高スループットの REST API を作成します。
 Java フレームワークのパフォーマンス比較
Jun 04, 2024 pm 03:56 PM
Java フレームワークのパフォーマンス比較
Jun 04, 2024 pm 03:56 PM
ベンチマークによると、小規模で高性能なアプリケーションの場合、Quarkus (高速起動、低メモリ) または Micronaut (TechEmpower に優れた) が理想的な選択肢です。 SpringBoot は大規模なフルスタック アプリケーションに適していますが、起動時間とメモリ使用量が若干遅くなります。
 Golang フレームワークのドキュメントのベスト プラクティス
Jun 04, 2024 pm 05:00 PM
Golang フレームワークのドキュメントのベスト プラクティス
Jun 04, 2024 pm 05:00 PM
明確で包括的なドキュメントを作成することは、Golang フレームワークにとって非常に重要です。ベスト プラクティスには、Google の Go コーディング スタイル ガイドなど、確立されたドキュメント スタイルに従うことが含まれます。見出し、小見出し、リストなどの明確な組織構造を使用し、ナビゲーションを提供します。スタート ガイド、API リファレンス、概念など、包括的で正確な情報を提供します。コード例を使用して、概念と使用法を説明します。ドキュメントを常に最新の状態に保ち、変更を追跡し、新機能を文書化します。 GitHub の問題やフォーラムなどのサポートとコミュニティ リソースを提供します。 API ドキュメントなどの実践的なサンプルを作成します。
 さまざまなアプリケーションシナリオに最適な Golang フレームワークを選択する方法
Jun 05, 2024 pm 04:05 PM
さまざまなアプリケーションシナリオに最適な Golang フレームワークを選択する方法
Jun 05, 2024 pm 04:05 PM
アプリケーションのシナリオに基づいて最適な Go フレームワークを選択します。アプリケーションの種類、言語機能、パフォーマンス要件、エコシステムを考慮します。一般的な Go フレームワーク: Jin (Web アプリケーション)、Echo (Web サービス)、Fiber (高スループット)、gorm (ORM)、fasthttp (速度)。実際のケース: REST API (Fiber) の構築とデータベース (gorm) との対話。フレームワークを選択します。主要なパフォーマンスには fasthttp、柔軟な Web アプリケーションには Jin/Echo、データベース インタラクションには gorm を選択してください。
 golang フレームワーク開発の実践的な詳細な説明: 質疑応答
Jun 06, 2024 am 10:57 AM
golang フレームワーク開発の実践的な詳細な説明: 質疑応答
Jun 06, 2024 am 10:57 AM
Go フレームワーク開発における一般的な課題とその解決策は次のとおりです。 エラー処理: 管理にはエラー パッケージを使用し、エラーを一元的に処理するにはミドルウェアを使用します。認証と認可: サードパーティのライブラリを統合し、資格情報を確認するためのカスタム ミドルウェアを作成します。同時処理: ゴルーチン、ミューテックス、チャネルを使用してリソース アクセスを制御します。単体テスト: 分離のために getest パッケージ、モック、スタブを使用し、十分性を確保するためにコード カバレッジ ツールを使用します。デプロイメントとモニタリング: Docker コンテナを使用してデプロイメントをパッケージ化し、データのバックアップをセットアップし、ログ記録およびモニタリング ツールでパフォーマンスとエラーを追跡します。
 Golang フレームワークの学習プロセスでよくある誤解は何ですか?
Jun 05, 2024 pm 09:59 PM
Golang フレームワークの学習プロセスでよくある誤解は何ですか?
Jun 05, 2024 pm 09:59 PM
Go フレームワークの学習には、フレームワークへの過度の依存と柔軟性の制限という 5 つの誤解があります。フレームワークの規則に従わない場合、コードの保守が困難になります。古いライブラリを使用すると、セキュリティと互換性の問題が発生する可能性があります。パッケージを過度に使用すると、コード構造が難読化されます。エラー処理を無視すると、予期しない動作やクラッシュが発生します。
