

時間と空間を制御可能なビデオ生成が現実となり、アリババの新しい大規模モデルVideoComposerが人気に

AI絵画の分野では、アリババが提案したComposerとスタンフォードが提案した安定拡散に基づくControlNetが、制御可能な画像生成の理論開発を主導してきました。ただし、制御可能なビデオ生成に関する業界の探求はまだ比較的空白です。
画像生成と比較して、制御可能なビデオは、ビデオコンテンツの空間の制御性に加えて、時間次元の制御性も満たす必要があるため、より複雑です。これに基づいて、アリババとアントグループの研究チームが率先して試みを行い、複合生成パラダイムによって時間と空間の両方の次元でのビデオ制御性を同時に実現するVideoComposerを提案しました。

- 論文アドレス: https://arxiv.org/abs/2306.02018
- プロジェクトのホームページ: https://videocomposer.github.io
少し前に、Alibaba Wensheng ビデオ モデルは控えめで、Moda コミュニティと Hugging Face でオープンソース化されていました。予想外に国内外の開発者から幅広い注目を集めました。モデルによって生成されたビデオには、マスク氏自身からも返答がありました。このモデルは注文を受けましたModa コミュニティでは何日も続けてアクセスされ、1 日に数万人の海外からのアクセスがありました。
##Text-to-Video on Twitter
VideoComposer 研究チームの最新の成果として、再び国際的な注目を集めています。コミュニティに焦点を当てます。

 #Twitter の VideoComposer
#Twitter の VideoComposer
実際、制御性はビジュアル コンテンツ作成のより高い基準となり、カスタマイズされた画像生成においては大きな進歩を遂げていますが、ビデオ生成の分野にはまだ 3 つの問題があります。大きな課題: 実験結果によると、VideoComposer は、単一の写真や手描きの絵などから特定のビデオを生成するなど、ビデオの時間と空間のパターンを柔軟に制御でき、さらには簡単に使用することもできます。シンプルな手書きの指示で、ターゲットの移動スタイルを制御します。この調査では、9 つの異なる古典的なタスクで VideoComposer のパフォーマンスを直接テストし、すべて満足のいく結果を達成し、VideoComposer の多用途性を証明しました。
ビデオ LDM ## 隠れた空間。 ビデオ LDM は、まず、入力ビデオ を潜在空間式にマッピングするための事前トレーニングされたエンコーダーを導入します。ここで、 にマッピングします。 VideoComposer では、パラメータは に設定されます。 #拡散モデル。 実際のビデオ コンテンツの配信について学ぶには , 拡散モデルは、正規分布ノイズから徐々にノイズを除去して実際の視覚コンテンツを復元することを学習します。このプロセスは、実際には、長さ T=1000 の可逆マルコフ連鎖をシミュレートしています。潜在空間で可逆プロセスを実行するために、Video LDM は
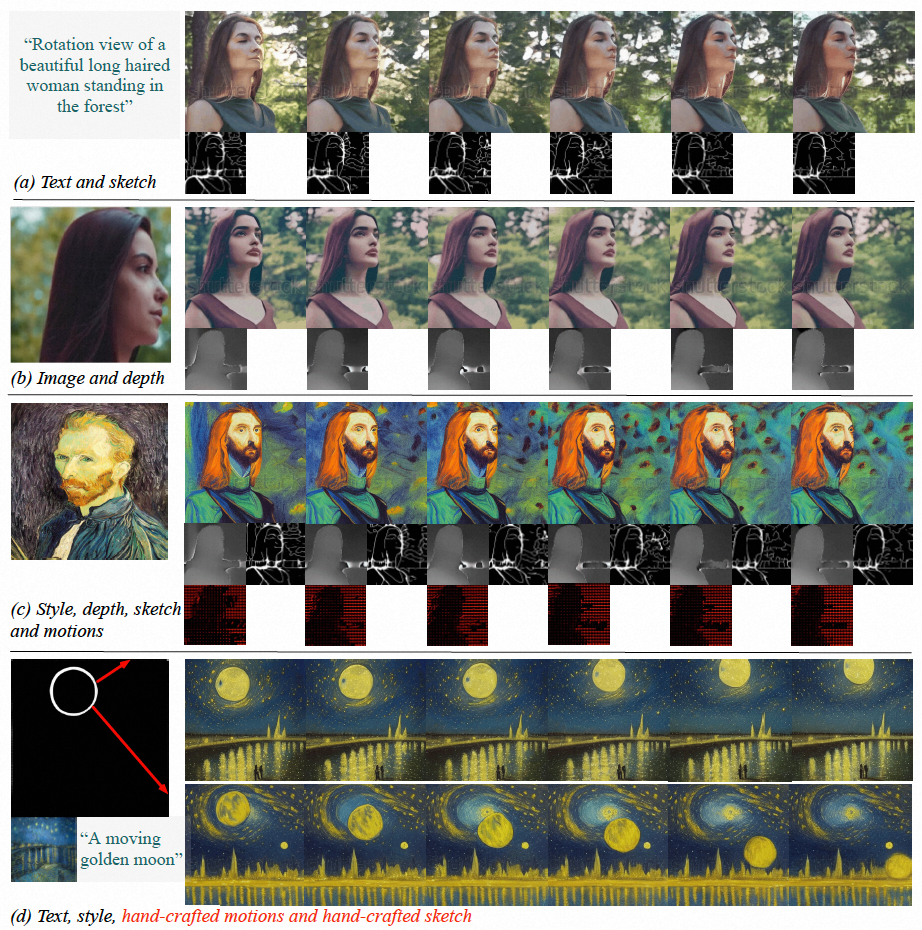 #図 (a ~ c) VideoComposer は、テキスト、空間的および時間的条件、またはそのサブセットを満たすビデオを生成できます。 (d) VideoComposer は、期待される動きモード (赤いストローク) と形状モード (白いストローク) を満たしながら、ゴッホのスタイルを満たすビデオを生成するために 2 つのストロークのみを使用できます。 #メソッドの紹介
#図 (a ~ c) VideoComposer は、テキスト、空間的および時間的条件、またはそのサブセットを満たすビデオを生成できます。 (d) VideoComposer は、期待される動きモード (赤いストローク) と形状モード (白いストローク) を満たしながら、ゴッホのスタイルを満たすビデオを生成するために 2 つのストロークのみを使用できます。 #メソッドの紹介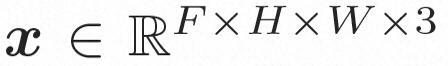
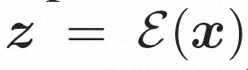
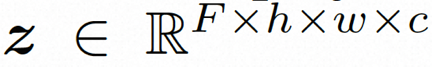
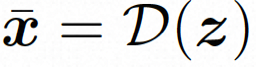
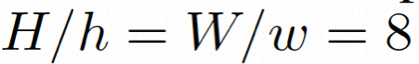
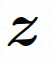
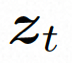
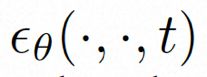
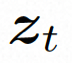
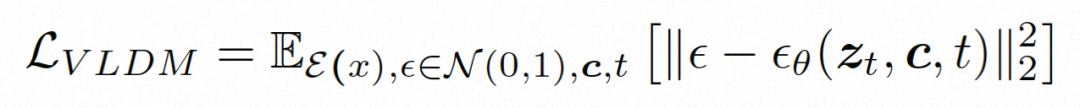
空間ローカル誘導バイアスの使用とノイズ除去のためのシーケンス時間誘導バイアスの使用を完全に調査するために、VideoComposer は 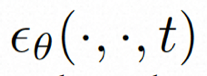
##VideoComposer
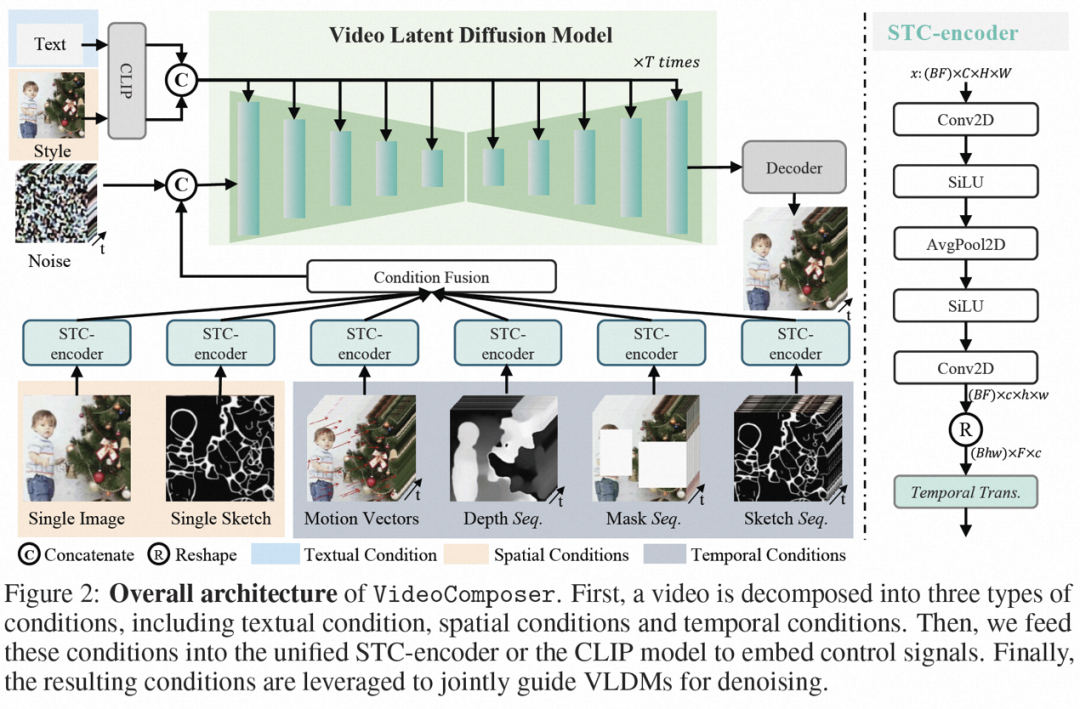
組み合わせ条件。 VideoComposer は、ビデオを 3 つの異なるタイプの条件 (テキスト条件、空間条件、クリティカル タイミング条件) に分解します。これらの条件が組み合わさって、ビデオ内の空間的および時間的パターンを決定します。 VideoComposer は、一般的な構成可能なビデオ生成フレームワークであるため、以下にリストされているものに限定されず、ダウンストリーム アプリケーションに基づいて、よりカスタマイズされた条件を VideoComposer に組み込むことができます。
- #テキスト条件: テキストdescription は、大まかなビジュアル コンテンツとモーションの側面を含む、ビデオの視覚的な指示を提供します。これは、T2V でよく使用される条件でもあります。
- 空間条件:
- 単一画像。指定されたビデオの最初のフレームを空間条件として選択し、画像からビデオを生成し、ビデオのコンテンツと構造を表現します。
- 単一スケッチ。PiDiNet を使用して、最初のビデオ フレームのスケッチを 2 番目の空間条件として抽出します。
- Style (スタイル)。単一画像のスタイルを合成ビデオにさらに転送し、スタイル ガイドとして画像の埋め込みを選択します;
- タイミング条件:
- 映像特有の要素である動きベクトル(Motion Vector)は、2次元のベクトルとして表現されます。 、水平方向と垂直方向。 2 つの隣接するフレーム間のピクセルごとの動きを明示的にエンコードします。動きベクトルの自然な特性により、この状態は時間的に滑らかに合成された動き制御信号として扱われ、圧縮ビデオから標準 MPEG-4 形式で動きベクトルを抽出します;
- 深度シーケンス(深度シーケンス)、ビデオレベルの深度情報を導入するには、PiDiNet の事前トレーニング済みモデルを使用してビデオ フレームの深度マップを抽出します。
- マスク シーケンス (マスク シーケンス) )、管状マスクを導入してローカルの時空間コンテンツをマスクし、観察可能な情報に基づいてマスクされた領域をモデルに強制的に予測させます。
- スケッチ シーケンス。単一のスケッチと比較して、スケッチ シーケンスは次のことができます。細部をより細かく制御して、正確なカスタム構成を実現します。
# 時空間条件付きエンコーダー。 シーケンス条件には豊富で複雑な時空間依存関係が含まれており、制御可能な命令に大きな課題をもたらします。入力条件の時間的認識を強化するために、この研究では、時空間関係を組み込む時空間条件エンコーダー (STC エンコーダー) を設計しました。具体的には、2 つの 2D 畳み込みと avgPooling を含む軽量の空間構造が最初に適用されてローカル空間情報が抽出され、その結果の条件シーケンスが時間モデリングのために時間 Transformer レイヤーに入力されます。このようにして、STC エンコーダは時間的キューの明示的な埋め込みを容易にし、多様な入力に対する条件付き埋め込みのための統合されたエントリを提供することで、フレーム間の一貫性を強化できます。さらに、この研究では、単一の画像と単一のスケッチの空間条件を時間次元で繰り返して、時間条件との一貫性を確保し、条件埋め込みプロセスを容易にしました。
条件が STC エンコーダーを通じて処理された後、最終的な条件シーケンスは STC エンコーダーと同じ空間形状を持ち、要素ごとの加算によって融合されます。最後に、マージされた条件付きシーケンスは、制御信号としてチャネル次元に沿って連結されます。テキストとスタイルの条件については、クロスアテンション メカニズムを利用してテキストとスタイルのガイダンスを挿入します。
#トレーニングと推論
2 段階のトレーニング戦略。 VideoComposer は画像 LDM の事前トレーニングを通じて初期化でき、トレーニングの難易度をある程度軽減できますが、モデルが時間的なダイナミクスを認識する能力を持つことは困難です。複数の条件を同時に生成できるため、組み合わせたビデオ生成のトレーニングの難易度が高くなります。したがって、この研究では 2 段階の最適化戦略を採用しました。第 1 段階では、最初に T2V トレーニングを通じてモデルにタイミング モデリング機能が装備され、第 2 段階では、組み合わせトレーニングを通じて VideoComposer が最適化され、パフォーマンスが向上しました。
推論。 推論プロセス中、推論効率を向上させるために DDIM が使用されます。また、分類子を使用しないガイダンスを採用して、生成された結果が指定された条件を確実に満たすようにします。生成プロセスは次のように形式化できます:
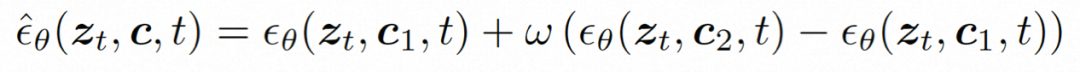
ここで、ω は誘導率、c1 と c2 は 2 つの条件セットです。この誘導メカニズムは 2 つの条件のセットによって判断され、強度制御を通じてモデルをより柔軟に制御できます。
実験結果実験的調査では、研究では、VideoComposer がユニバーサル生成フレームワークを備えた統合モデルとして機能することを実証し、9 つの古典的なタスクに対する VideoComposer の機能を検証しました。 。
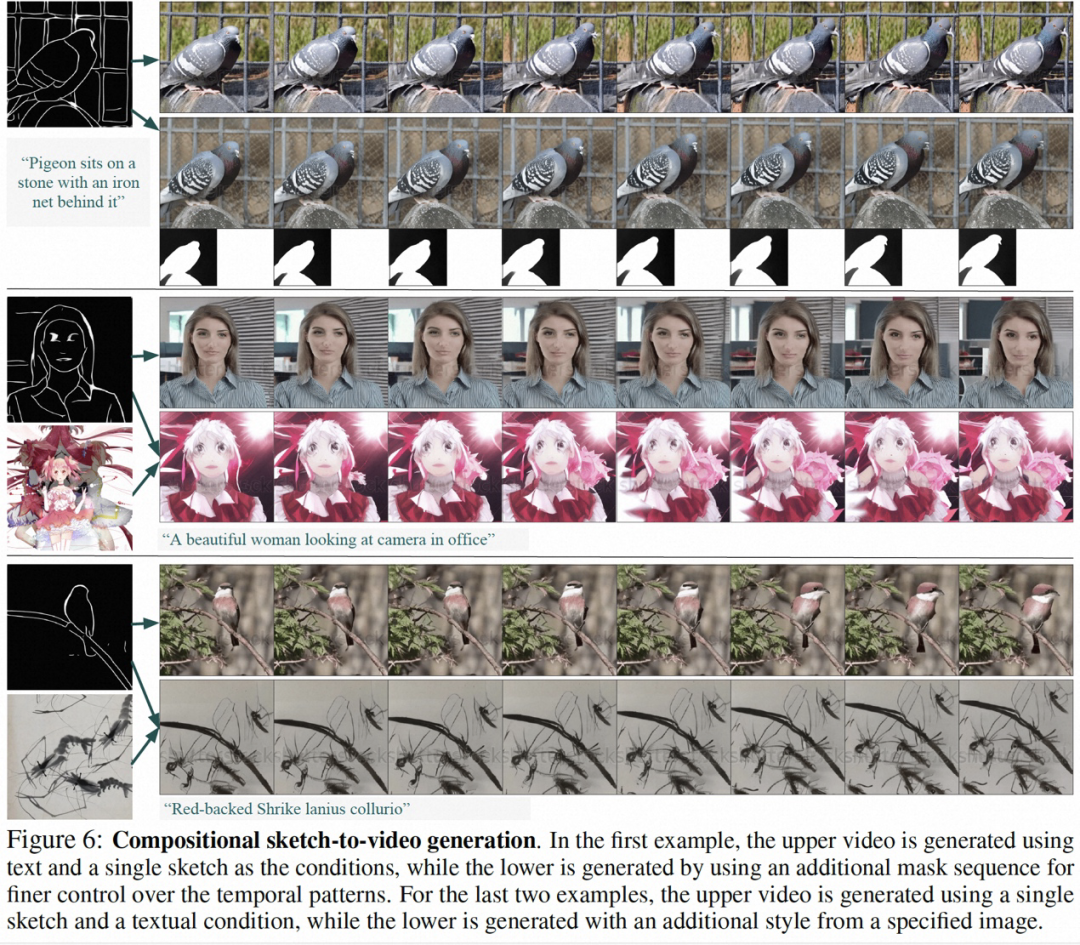
この研究結果の一部は、静止画像からビデオの生成 (図 4)、ビデオの修復 (図 5)、静的なスケッチのビデオから生成 (図 6) です。 、手描きのモーション コントロール ビデオ (図 8) とモーション転送 (図 A12) は両方とも、制御可能なビデオ生成の利点を反映できます。



以上が時間と空間を制御可能なビデオ生成が現実となり、アリババの新しい大規模モデルVideoComposerが人気にの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7554
7554
 15
1382
52
83
11
28
96
15
1382
52
83
11
28
96

 他人の動画をDouyinに投稿することは侵害になりますか?侵害せずにビデオを編集するにはどうすればよいですか?
Mar 21, 2024 pm 05:57 PM
他人の動画をDouyinに投稿することは侵害になりますか?侵害せずにビデオを編集するにはどうすればよいですか?
Mar 21, 2024 pm 05:57 PM
ショートビデオプラットフォームの台頭により、Douyinはみんなの日常生活に欠かせないものになりました。 TikTokでは世界中の面白い動画を見ることができます。他人のビデオを投稿することを好む人もいますが、「Douyin は他人のビデオを投稿することを侵害しているのでしょうか?」という疑問が生じます。この記事では、この問題について説明し、著作権を侵害せずに動画を編集する方法と、著作権侵害の問題を回避する方法について説明します。 1.Douyin による他人の動画の投稿は侵害ですか?私の国の著作権法の規定によれば、著作権者の著作物を著作権者の許可なく無断で使用することは侵害となります。したがって、オリジナルの作者または著作権所有者の許可なしに他人のビデオをDouyinに投稿することは侵害となります。 2. 著作権を侵害せずにビデオを編集するにはどうすればよいですか? 1. パブリックドメインまたはライセンスされたコンテンツの使用: パブリック
 Douyin に動画を投稿して収益を得るにはどうすればよいですか?初心者はどうやってDouyinでお金を稼ぐことができますか?
Mar 21, 2024 pm 08:17 PM
Douyin に動画を投稿して収益を得るにはどうすればよいですか?初心者はどうやってDouyinでお金を稼ぐことができますか?
Mar 21, 2024 pm 08:17 PM
全国的なショートビデオプラットフォームであるDouyinは、自由な時間にさまざまな興味深く斬新なショートビデオを楽しむことができるだけでなく、自分自身を示し、自分の価値観を実現するステージも提供します。では、Douyin に動画を投稿してお金を稼ぐにはどうすればよいでしょうか?この記事ではこの質問に詳しく答え、TikTokでより多くのお金を稼ぐのに役立ちます。 1.Douyin に動画を投稿してお金を稼ぐにはどうすればよいですか?動画を投稿し、Douyin で一定の再生回数を獲得すると、広告共有プランに参加できるようになります。この収入方法はDouyinユーザーにとって最も馴染みのある方法の1つであり、多くのクリエイターにとって主な収入源でもあります。 Douyin は、アカウントの重み、動画コンテンツ、視聴者のフィードバックなどのさまざまな要素に基づいて、広告共有の機会を提供するかどうかを決定します。 TikTok プラットフォームでは、視聴者がギフトを送ったり、
 iPhoneのビデオからスローモーションを削除する2つの方法
Mar 04, 2024 am 10:46 AM
iPhoneのビデオからスローモーションを削除する2つの方法
Mar 04, 2024 am 10:46 AM
iOS デバイスでは、カメラ アプリを使用してスローモーション ビデオを撮影できます。最新の iPhone を使用している場合は、1 秒あたり 240 フレームのビデオを撮影することもできます。この機能により、高速アクションを詳細にキャプチャできます。ただし、ビデオの詳細やアクションをよりよく理解するために、スローモーション ビデオを通常の速度で再生したい場合もあります。この記事では、iPhone上の既存のビデオからスローモーションを削除するすべての方法を説明します。 iPhoneでビデオからスローモーションを削除する方法[2つの方法] 写真アプリまたはiMovieアプリを使用して、デバイス上のビデオからスローモーションを削除できます。方法 1: 写真アプリを使用して iPhone で開く
 小紅書ビデオ作品を公開するにはどうすればよいですか?動画を投稿する際に注意すべきことは何ですか?
Mar 23, 2024 pm 08:50 PM
小紅書ビデオ作品を公開するにはどうすればよいですか?動画を投稿する際に注意すべきことは何ですか?
Mar 23, 2024 pm 08:50 PM
短編ビデオ プラットフォームの台頭により、Xiaohongshu は多くの人々が自分の生活を共有し、自分自身を表現し、トラフィックを獲得するためのプラットフォームになりました。このプラットフォームでは、ビデオ作品の公開が非常に人気のある交流方法です。では、小紅書ビデオ作品を公開するにはどうすればよいでしょうか? 1.小紅書ビデオ作品を公開するにはどうすればよいですか?まず、共有できるビデオ コンテンツがあることを確認します。携帯電話やその他のカメラ機器を使用して撮影することもできますが、画質と音声の明瞭さには注意する必要があります。 2.ビデオを編集する:作品をより魅力的にするために、ビデオを編集できます。 Douyin、Kuaishou などのプロ仕様のビデオ編集ソフトウェアを使用して、フィルター、音楽、字幕、その他の要素を追加できます。 3. 表紙を選択する: 表紙はユーザーのクリックを誘致するための鍵です。ユーザーのクリックを誘致するために、表紙には鮮明で興味深い写真を選択してください。
 Alibaba ID はどこで確認できますか?
Mar 08, 2024 pm 09:49 PM
Alibaba ID はどこで確認できますか?
Mar 08, 2024 pm 09:49 PM
Alibaba ソフトウェアでは、アカウントの登録が完了すると、システムによって一意の ID が割り当てられ、これがプラットフォーム上での ID として機能します。しかし、多くのユーザーは自分の ID を照会したいと考えていますが、その方法がわかりません。次に、この Web サイトの編集者が以下の戦略手順を詳しく紹介します。お役に立てれば幸いです。 Alibaba ID: [Alibaba]-[My] に対する答えはどこで見つかりますか。 1. まず Alibaba ソフトウェアを開きます. ホームページに入ったら、右下隅の [My] をクリックする必要があります; 2. その後、My ページにアクセスすると、ページの上部に [id] が表示されます; Alibaba ID はタオバオと同じですか? アリババ ID とタオバオ ID は異なりますが、この 2 つは同じです
 画質を圧縮せずにWeiboに動画を投稿する方法_画質を圧縮せずにWeiboに動画を投稿する方法
Mar 30, 2024 pm 12:26 PM
画質を圧縮せずにWeiboに動画を投稿する方法_画質を圧縮せずにWeiboに動画を投稿する方法
Mar 30, 2024 pm 12:26 PM
1. まず携帯電話で Weibo を開き、右下隅の [Me] をクリックします (図を参照)。 2. 次に、右上隅の [歯車] をクリックして設定を開きます (図を参照)。 3. 次に、[一般設定] を見つけて開きます (図を参照)。 4. 次に、[Video Follow] オプションを入力します (図を参照)。 5. 次に、[ビデオアップロード解像度]設定を開きます(図を参照)。 6. 最後に、圧縮を避けるために [オリジナルの画質] を選択します (図を参照)。
 アリババの杭州世界本社は5月10日に使用開始された
May 07, 2024 pm 02:43 PM
アリババの杭州世界本社は5月10日に使用開始された
May 07, 2024 pm 02:43 PM
本ウェブサイトは5月7日、杭州未来科学技術城にあるアリババのグローバル本社(西渓エリアC)が5月10日に正式に使用開始され、同時にアリババ北京朝陽科技園区もオープンすると報じた。 。これにより、アリババ本社のオフィスビルは世界中で 4 棟に達します。 ▲アリババグローバル本社(西西区Cゾーン) 5月10日はアリババにとって20回目となる「アリババの日」でもあり、毎年この日、アリババは祝賀行事を開催し、アリババの親族、友人、卒業生向けに2つの新しいパークを開放する。西渓エリア C は現在アリババ最大の自己所有公園であり、事務作業のために 30,000 人を収容できます。 ▲アリババ北京朝陽科技園区 アリババグローバル本社は杭州未来科技城に位置し、文義西路の北、高角路の東にあり、総建築面積は984,500平方メートルで、そのうち
 DAMOアカデミーが2024年アリババ世界数学コンペティションの最終テスト問題を発表: 5トラック、結果は8月に
Jun 23, 2024 pm 06:36 PM
DAMOアカデミーが2024年アリババ世界数学コンペティションの最終テスト問題を発表: 5トラック、結果は8月に
Jun 23, 2024 pm 06:36 PM
6月23日の当サイトのニュースによると、当サイトはDAMO WeChat公式アカウントから、北京時間6月22日24時に2024年アリババ世界数学コンテストの決勝戦が正式に終了したことを知った。今年の決勝戦には、世界 17 の国と地域から 800 名を超える出場者が最終候補者として選ばれました。次に、専門家グループによる自主採点の段階に入ります。格付けには、事前評価、反対尋問、最終検証などのプロセスが含まれます。最終的な 5 つのトラックでは、結果に基づいて金メダル 1 件、銀メダル 2 件、銅メダル 4 件、優秀賞 10 件が授与されます。合計 85 名の受賞者が 8 月に発表されます。アリババ・ダモ・アカデミーはまた、数学決勝戦のテーマを次の 5 つのトラックに分けて発表した。1. 代数と数論、3. 解析と方程式、5. 応用。そして計算。
