

テンセントのロボット犬が進化:深層学習を通じて自律的な意思決定能力を習得

6 月 14 日、Tencent Robotics の意思決定能力が大幅に向上しました。
ロボット犬を人間や動物と同じように柔軟かつ安定して動かせるようにすることは、ロボット研究分野における長期的な目標です。ディープラーニング技術の継続的な進歩により、機械は「学習」を通じて関連する能力を習得し、さまざまな問題に対処する方法を学ぶことができます。複雑な変化を伴う環境が可能になります。
事前トレーニングと強化学習の紹介: ロボット犬の機敏性を高める
Tencent Robotics は、事前学習モデルと強化学習技術を導入することで、再学習する代わりに、学習した姿勢、環境認識、戦略計画に関する多層的な知識を再利用し、他のケースについて推論することができます。 1 つのインスタンスから複雑な環境に柔軟に対応する


この一連の学習は 3 つの段階に分かれています:
最初の段階では、研究者は、ゲーム テクノロジーで一般的に使用されるモーション キャプチャ システムを通じて、歩く、走る、ジャンプする、立つなどの動作を含む本物の犬の動作姿勢データを収集し、これらのデータを使用して模倣を構築しました。シミュレータで学習タスクを実行し、これらのデータ内の情報を抽象化してディープ ニューラル ネットワーク モデルに圧縮します。これらのモデルは、収集された動物の動作姿勢情報を正確にカバーできるだけでなく、高い解釈性も備えています。
テンセントロボティクスこれらのテクノロジーとデータは、物理シミュレーションベースのエージェントトレーニングと現実世界のロボット戦略の展開において一定の補助的な役割を果たします。
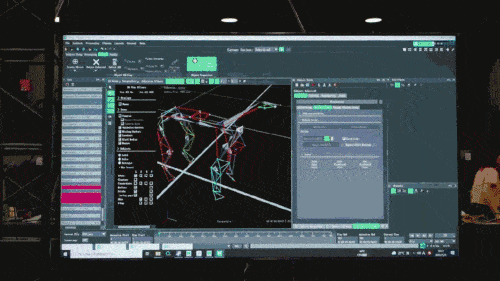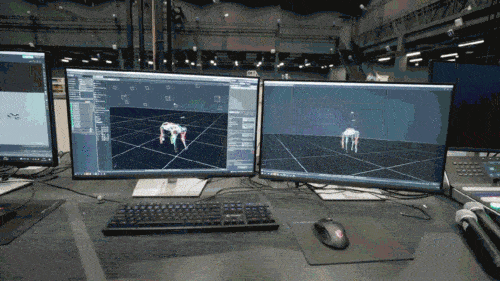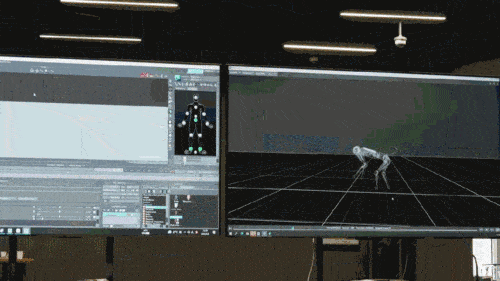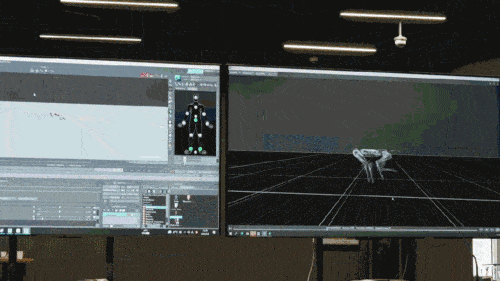
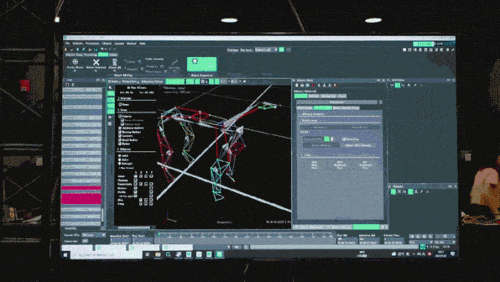

ニューラル ネットワーク モデルは、ロボット犬の固有受容情報 (運動状態など) のみを入力として受け入れ、模倣学習方法でトレーニングされます。次のステップでは、他のセンサーを使用して足元の障害物を検出するなど、周囲環境からの感覚データがモデルに組み込まれます。
第 2 段階では、追加のネットワーク パラメーターを使用して、第 1 段階で習得したロボット犬の賢い姿勢を外部の知覚と結び付け、ロボット犬が学習した賢い姿勢を通じて外部環境に反応できるようにします。 。ロボット犬がさまざまな複雑な環境に適応すると、スマートな姿勢と外部の知覚を結びつける知識も固定化され、ニューラルネットワーク構造に保存されます。



第 3 段階では、上記の 2 つの事前トレーニング段階で得られたニューラル ネットワークを使用して、ロボット犬はトップレベルのポリシー学習問題の解決に集中するための前提条件と機会を獲得し、最終的に複雑な問題を解決する能力を獲得します。エンドツーエンドのタスク。第 3 フェーズでは、ゲーム内の対戦相手や旗に関する情報の取得など、複雑なタスクに関連するデータを収集するためにネットワークが追加されます。さらに、戦略学習を担うニューラルネットワークは、あらゆる情報を総合的に分析することで、どの方向に走るか、相手の行動を予測して追いかけ続けるかどうかなど、タスクに対する高度な戦略を学習します。
上記の各段階で学習した知識は、再学習することなく拡張・調整できるため、継続的に蓄積し、継続的に学習することができます。
ロボット犬障害物追跡競技: 自律的な意思決定と制御機能を備えています
マックスが習得したこれらの新しいスキルをテストするために、研究者たちは障害物追跡ゲーム「ワールド チェイス タグ」からインスピレーションを得て、2 頭の犬による障害物追跡ゲームを設計しました。ワールド チェイス タグは、2014 年にイギリスで設立された障害物追跡競技団体です。民間の子供向けの追いかけっこを標準化したものです。一般的に、障害物追跡競技の各ラウンドでは、2 人の選手が互いに競い合います。1 人は追跡者 (アタッカーと呼ばれます)、もう 1 人は回避者 (ディフェンダーと呼ばれます) です。追跡ラウンド (つまり 20 秒) 中に相手を回避することに成功した場合 (つまり、接触が発生しなかった場合) に 1 ポイント。規定の追跡ラウンド数で最も多くのポイントを獲得したチームがゲームに勝利します。
ロボット犬障害物追いかけ競技の会場サイズは4.5メートル×4.5メートルで、その中にいくつかの障害物が点在しています。ゲーム開始時にフィールド内のランダムな位置に2匹のMAXロボット犬が配置され、1匹のロボット犬は追跡者、もう1匹は回避者の役割をランダムに割り当てられ、同時に旗が設置されます。フィールド内のランダムな場所にあります。
回避者の目標は、追跡者に捕まらずにできるだけ旗に近づくことです。追跡者の任務は回避者を捕まえることです。回避者が捕まる前に旗に触れることに成功すると、2 匹のロボット犬の役割が即座に切り替わり、旗は別のランダムな場所に再び表示されます。回避者が現在の追跡者に捕まり、追跡者の役割を果たしたロボット犬が勝利すると、ゲームは終了します。すべてのゲームにおいて、2 匹のロボット犬の平均前進速度は 0.5m/s に制限されています。
このゲームから判断すると、事前トレーニングされたモデルに基づいて、ロボット犬はすでに深層強化学習を通じて一定の推論能力と意思決定能力を備えています。
たとえば、追跡者が、旗に触れる前に回避者に追いつけないと悟った場合、追跡者は追跡を諦め、代わりに次の重要なステップを待つために回避者から離れます。設定されているフラグが表示されます。さらに、追跡者は、土壇場で回避者を捕まえようとしているとき、飛び上がって回避者に向かって「飛びかかる」動作をすることを好みます。これは、動物が獲物を捕まえるときの行動と非常によく似ています。回避者が旗に触れようとしているとき、時々同じ動作を示します。これらはすべて、ロボット犬が勝利を確実にするために講じる積極的な加速手段です。
報告によると、ゲーム内のロボット犬の制御戦略はすべてニューラル ネットワーク戦略であり、シミュレーションとゼロショット転送 (ゼロ調整転送) を通じて学習され、ニューラル ネットワークが人間の推論方法をシミュレートして識別できるようになります。新しいものを見て、その知識を実際のロボット犬に応用してください。たとえば、下の図に示すように、追跡タグ ゲームの仮想世界で障害物のあるシーンが訓練されていないにもかかわらず、ロボット犬が事前訓練モデルで学習した障害物を回避する知識がゲームで使用されます (仮想世界のみ(平地でのゲームシーンで訓練した後)、ロボット犬もタスクを正常に完了できます。
Tencent Robotics 学習テクノロジーは、ロボットの制御能力を向上させ、より柔軟にするためにロボットの分野に導入され、ロボットが現実の生活に参入して人間に奉仕するための強固な基盤を築きます。
以上がテンセントのロボット犬が進化:深層学習を通じて自律的な意思決定能力を習得の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7529
7529
 15
1378
52
81
11
21
76
15
1378
52
81
11
21
76

 ビッグモデルアプリ Tencent Yuanbao がオンラインになりました! Hunyuan がアップグレードされ、どこにでも持ち運べるオールラウンドな AI アシスタントが作成されました
Jun 09, 2024 pm 10:38 PM
ビッグモデルアプリ Tencent Yuanbao がオンラインになりました! Hunyuan がアップグレードされ、どこにでも持ち運べるオールラウンドな AI アシスタントが作成されました
Jun 09, 2024 pm 10:38 PM
5月30日、TencentはHunyuanモデルの包括的なアップグレードを発表し、Hunyuanモデルに基づくアプリ「Tencent Yuanbao」が正式にリリースされ、AppleおよびAndroidアプリストアからダウンロードできるようになりました。前のテスト段階のフンユアン アプレット バージョンと比較して、Tencent Yuanbao は、日常生活シナリオ向けの AI 検索、AI サマリー、AI ライティングなどのコア機能を提供し、Yuanbao のゲームプレイもより豊富で、複数の機能を提供します。 、パーソナルエージェントの作成などの新しいゲームプレイ方法が追加されます。 Tencent Cloud 副社長で Tencent Hunyuan 大型モデルの責任者である Liu Yuhong 氏は、「テンセントは、最初に大型モデルを開発しようとはしません。」と述べました。 Tencent Hunyuan の大型モデルは、ビジネス シナリオにおける豊富で大規模なポーランド テクノロジーを活用しながら、ユーザーの真のニーズを洞察します。
 ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
以前に書きましたが、今日は、深層学習テクノロジーが複雑な環境におけるビジョンベースの SLAM (同時ローカリゼーションとマッピング) のパフォーマンスをどのように向上させることができるかについて説明します。ここでは、深部特徴抽出と深度マッチング手法を組み合わせることで、低照度条件、動的照明、テクスチャの弱い領域、激しいセックスなどの困難なシナリオでの適応を改善するように設計された多用途のハイブリッド ビジュアル SLAM システムを紹介します。当社のシステムは、拡張単眼、ステレオ、単眼慣性、ステレオ慣性構成を含む複数のモードをサポートしています。さらに、他の研究にインスピレーションを与えるために、ビジュアル SLAM と深層学習手法を組み合わせる方法も分析します。公開データセットと自己サンプリングデータに関する広範な実験を通じて、測位精度と追跡堅牢性の点で SL-SLAM の優位性を実証しました。
 1 つの記事で理解: AI、機械学習、ディープラーニングのつながりと違い
Mar 02, 2024 am 11:19 AM
1 つの記事で理解: AI、機械学習、ディープラーニングのつながりと違い
Mar 02, 2024 am 11:19 AM
今日の急速な技術変化の波の中で、人工知能 (AI)、機械学習 (ML)、および深層学習 (DL) は輝かしい星のようなもので、情報技術の新しい波をリードしています。これら 3 つの単語は、さまざまな最先端の議論や実践で頻繁に登場しますが、この分野に慣れていない多くの探検家にとって、その具体的な意味や内部のつながりはまだ謎に包まれているかもしれません。そこで、まずはこの写真を見てみましょう。ディープラーニング、機械学習、人工知能の間には密接な相関関係があり、進歩的な関係があることがわかります。ディープラーニングは機械学習の特定の分野であり、機械学習
 超強い!深層学習アルゴリズムのトップ 10!
Mar 15, 2024 pm 03:46 PM
超強い!深層学習アルゴリズムのトップ 10!
Mar 15, 2024 pm 03:46 PM
2006 年にディープ ラーニングの概念が提案されてから、ほぼ 20 年が経過しました。ディープ ラーニングは、人工知能分野における革命として、多くの影響力のあるアルゴリズムを生み出してきました。では、ディープラーニングのトップ 10 アルゴリズムは何だと思いますか?私の考えでは、ディープ ラーニングのトップ アルゴリズムは次のとおりで、いずれもイノベーション、アプリケーションの価値、影響力の点で重要な位置を占めています。 1. ディープ ニューラル ネットワーク (DNN) の背景: ディープ ニューラル ネットワーク (DNN) は、多層パーセプトロンとも呼ばれ、最も一般的なディープ ラーニング アルゴリズムです。最初に発明されたときは、コンピューティング能力のボトルネックのため疑問視されていました。最近まで長年にわたる計算能力、データの爆発的な増加によって画期的な進歩がもたらされました。 DNN は、複数の隠れ層を含むニューラル ネットワーク モデルです。このモデルでは、各層が入力を次の層に渡し、
 Tencent QQ NTアーキテクチャバージョンのメモリ最適化の進捗が発表、チャットシーンは300M以内に制御される
Mar 05, 2024 pm 03:52 PM
Tencent QQ NTアーキテクチャバージョンのメモリ最適化の進捗が発表、チャットシーンは300M以内に制御される
Mar 05, 2024 pm 03:52 PM
Tencent QQデスクトップクライアントは一連の抜本的な改革を経たと理解されています。高いメモリ使用量、大きすぎるインストール パッケージ、遅い起動などのユーザーの問題に対応して、QQ 技術チームはメモリに関する特別な最適化を行い、段階的に進歩してきました。最近、QQ 技術チームは InfoQ プラットフォームに関する紹介記事を公開し、メモリの特別な最適化における段階的な進歩を共有しました。レポートによると、QQ の新バージョンのメモリの課題は主に次の 4 つの側面に反映されています。 製品形式: 複雑な大型パネル (さまざまな複雑さの 100 以上のモジュール) と一連の独立した機能ウィンドウで構成されます。ウィンドウとレンダリングプロセスは 1 対 1 に対応しており、ウィンドウプロセスの数は Electron のメモリ使用量に大きく影響します。その複雑な大型パネルの場合、
 Tencent Photon H Studio が杭州で人材を募集し、3A オープンワールド RPG の制作を計画中
Feb 05, 2024 pm 01:45 PM
Tencent Photon H Studio が杭州で人材を募集し、3A オープンワールド RPG の制作を計画中
Feb 05, 2024 pm 01:45 PM
最近、Tencent Interactive Entertainment Recruitment が採用情報を発表し、Photon H Studio がコンテンツ豊富な AAA レベルのオープンワールド RPG プロジェクトの開発に取り組んでいることが示されました。人気の募集職種は、UE5 エンジニア、バックエンド、レベル デザイン、アクション シーン デザイン、キャラクター モデリング、特殊効果、配信などの複数の分野をカバーしています。これらの職種の目標勤務地は、NetEase の本社がある杭州です。
 AlphaFold 3 が発売され、タンパク質とすべての生体分子の相互作用と構造をこれまでよりもはるかに高い精度で包括的に予測します。
Jul 16, 2024 am 12:08 AM
AlphaFold 3 が発売され、タンパク質とすべての生体分子の相互作用と構造をこれまでよりもはるかに高い精度で包括的に予測します。
Jul 16, 2024 am 12:08 AM
エディター | Radish Skin 2021 年の強力な AlphaFold2 のリリース以来、科学者はタンパク質構造予測モデルを使用して、細胞内のさまざまなタンパク質構造をマッピングし、薬剤を発見し、既知のあらゆるタンパク質相互作用の「宇宙地図」を描いてきました。ちょうど今、Google DeepMind が AlphaFold3 モデルをリリースしました。このモデルは、タンパク質、核酸、小分子、イオン、修飾残基を含む複合体の結合構造予測を実行できます。 AlphaFold3 の精度は、これまでの多くの専用ツール (タンパク質-リガンド相互作用、タンパク質-核酸相互作用、抗体-抗原予測) と比較して大幅に向上しました。これは、単一の統合された深層学習フレームワーク内で、次のことを達成できることを示しています。
 Up の所有者はすでに、Tencent のオープンソース「AniPortrait」を悪用し、写真に歌わせたりしゃべらせたりし始めています。
Apr 07, 2024 am 09:01 AM
Up の所有者はすでに、Tencent のオープンソース「AniPortrait」を悪用し、写真に歌わせたりしゃべらせたりし始めています。
Apr 07, 2024 am 09:01 AM
AniPortrait モデルはオープンソースであり、自由に遊ぶことができます。 「Xiaopozhan Ghost Zone の新しい生産性ツール」 最近、Tencent Open Source がリリースした新しいプロジェクトが Twitter でこのような評価を受けました。このプロジェクトは AniPortrait で、オーディオと参照画像に基づいて高品質のアニメーション ポートレートを生成します。さっそく、弁護士の手紙で警告されているデモを見てみましょう: アニメ画像も簡単に語ることができます: このプロジェクトは、立ち上げからわずか数日ですでに広く賞賛されています: GitHub スターの数は、 2,800を超えました。 AniPortrait の革新性を見てみましょう。論文タイトル: AniPortrait:Audio-DrivenSynthesisof
