

データのラベル付け不要、「3D理解」マルチモーダル事前学習の時代へ! ULIPシリーズは完全にオープンソースであり、SOTAを更新します

三次元形状、二次元画像、および対応する言語記述を調整することにより、マルチモーダル事前トレーニング方法は、3D 表現学習 の開発も促進します。
しかし、既存のマルチモーダル事前トレーニング フレームワークデータ収集方法にはスケーラビリティが欠けており、マルチモーダル学習の可能性が大幅に制限されています。最も大きなボトルネックは、言語モダリティの拡張性と包括性にあります。
最近、Salesforce AI はスタンフォード大学 大学およびテキサス大学オースティン校と提携して、新しいプロジェクトを主導する ULIP (CVP R2023) および ULIP-2 プロジェクトをリリースしました。 3Dで理解できる章です。

# 論文リンク: https://arxiv.org/pdf/2212.05171.pdf
#論文リンク: https://arxiv.org/pdf/2305.08275.pdfコードリンク: https: / /github.com/salesforce/ULIP
研究者らは、独自のアプローチを使用して、3D 点群、画像、テキストを使用してモデルを事前トレーニングし、統一された特徴に合わせて調整しました。空間。このアプローチにより、3D 分類タスクで最先端の結果が得られ、画像から 3D への検索などのクロスドメイン タスクの新たな可能性が開かれます。
そして ULIP-2 により、手動によるアノテーションなしでこのマルチモーダルな事前トレーニングが可能になり、大規模なスケーラビリティが可能になります。
ULIP-2 は、ModelNet40 のダウンストリーム ゼロショット分類で大幅なパフォーマンス向上を達成し、最高精度 74.0% に達しました。実際の ScanObjectNN ベンチマークでは、わずか 140 万を使用しました。たった 1 つのパラメーターで全体の精度 91.5% が達成され、人間による 3D アノテーションを必要としない、スケーラブルなマルチモーダル 3D 表現学習における画期的な成果となりました。
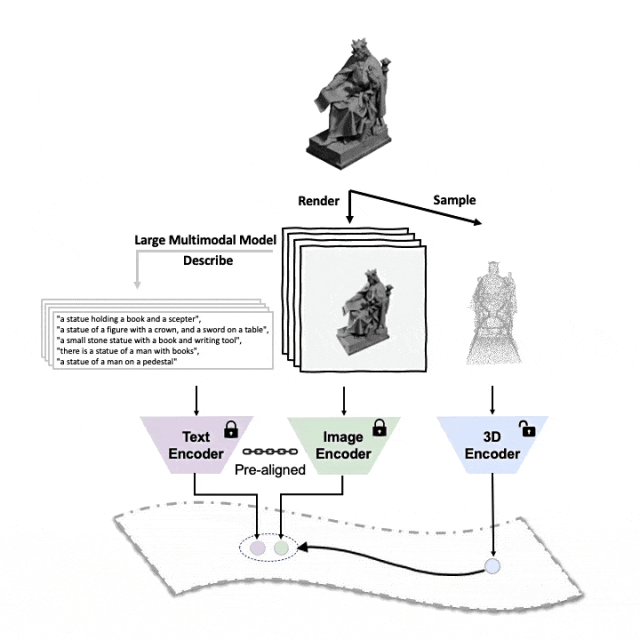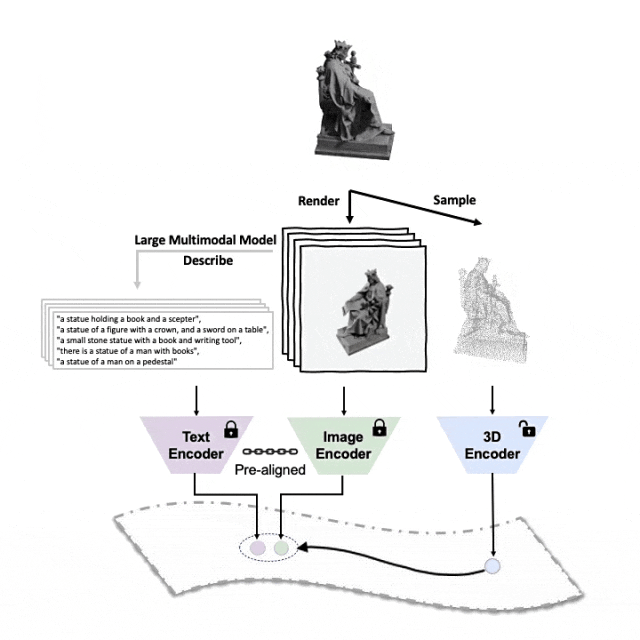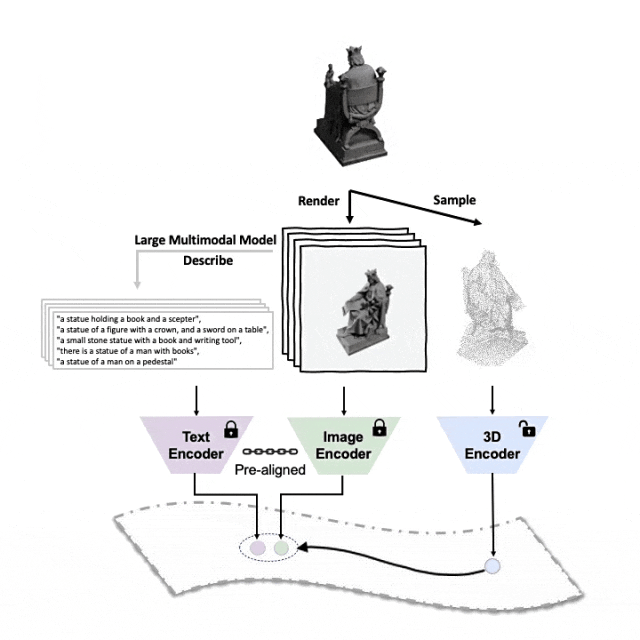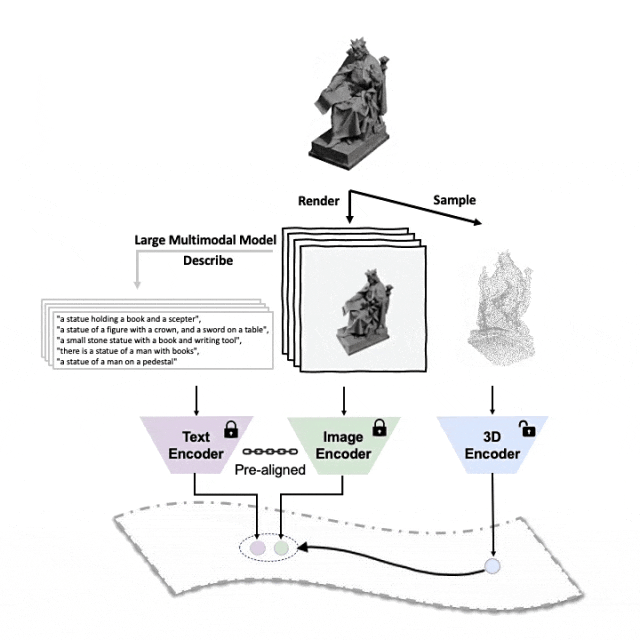
コードとリリースされた大規模な 3 峰性データ セット (「ULIP - Objaverse Triplets」および「ULIP - ShapeNet Triplets」) はオープン ソースです。 。
背景
3D 理解は人工知能の分野の重要な部分であり、これにより機械が人間と同じように 3 次元空間を認識し、対話できるようになります。この機能は、自動運転車、ロボット工学、仮想現実、拡張現実などの分野で重要な用途に使用されます。
しかし、3D データの処理と解釈の複雑さ、および 3D データの収集と注釈付けのコストにより、3D の理解は常に大きな課題に直面しています。
ULIP
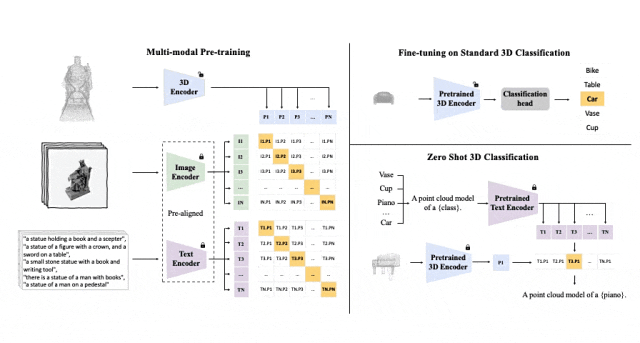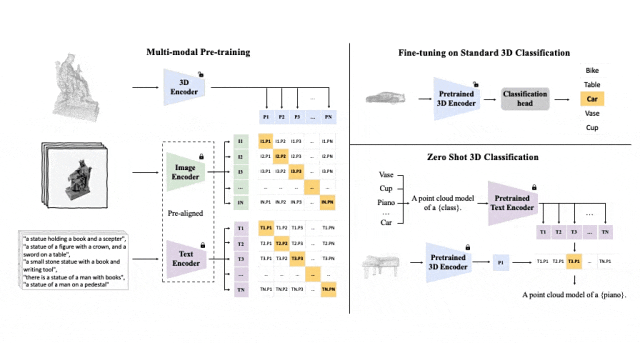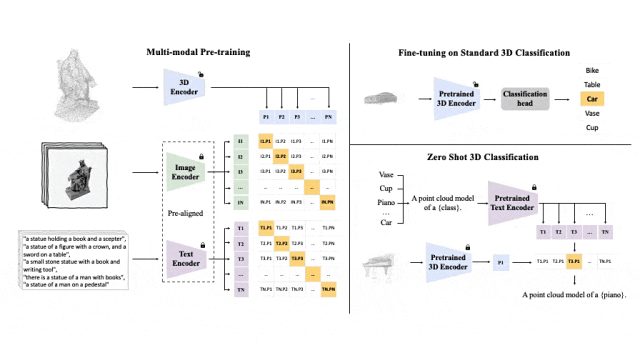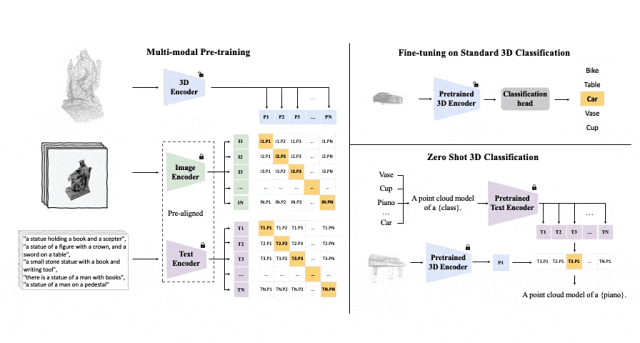
ULIP (すでに CVPR2023 で承認されています) は、3D 点群、画像、テキストを使用してモデルを事前トレーニングし、それらを統一された表現空間に配置する独自のアプローチを採用しています。
このアプローチは、3D 分類タスクで最先端の結果を達成し、画像から 3D への取得などのクロスドメイン タスクの新しい可能性を開きます。
ULIP の成功の鍵は、多数の画像とテキストのペアで事前トレーニングされた、CLIP などの事前調整された画像エンコーダーとテキスト エンコーダーの使用です。
これらのエンコーダーは、3 つのモダリティの機能を統一された表現空間に調整し、モデルが 3D オブジェクトをより効果的に理解して分類できるようにします。
この改善された 3D 表現学習により、3D データのモデルの理解が強化されるだけでなく、3D エンコーダーがマルチモーダル コンテキストを取得するため、ゼロショット 3D 分類や画像から 3D への取得などのクロスモーダル アプリケーションも可能になります。
ULIP の事前学習損失関数は次のとおりです。
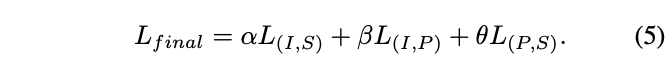
のデフォルト設定では、 ULIP、α は 0、β と θ は 1 に設定され、各 2 つのモード間の対比学習損失関数は次のように定義されます。ここで、M1 と M2 は 3 つのモードのうちの任意の 2 つのモードを指します。
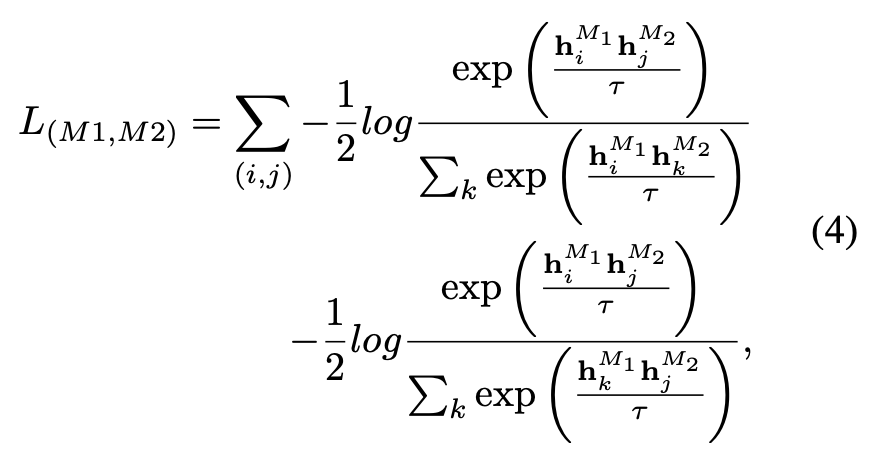
ULIP は画像から 3D への検索の実験も行いました。その結果は次のとおりです:

実験結果は、ULIP 事前トレーニング モデルが画像と 3D 点群の間で意味のあるマルチモーダル特徴を学習できたことを示しています。
驚くべきことに、他の取得された 3D モデルと比較して、最初に取得された 3D モデルの外観がクエリ画像に最も似ています。
たとえば、さまざまな種類の航空機 (戦闘機と旅客機) の画像を取得 (2 行目と 3 行目) に使用する場合、取得された最も近い 3D 点群は依然としてクエリ画像の微妙な違いです。保存されています。
#ULIP-2
##マルチアングルのテキスト説明を生成する 3D オブジェクトは次のとおりです。例。まず、一連のビューから 3D オブジェクトを 2D 画像にレンダリングし、次に大規模なマルチモーダル モデルを使用して、生成されたすべての画像の説明を生成します。
ULIP の ULIP-2基本的に、大規模なマルチモーダル モデルを使用して、3D オブジェクトに対応する包括的な言語記述を生成します。これにより、手動のアノテーションなしでスケーラブルなマルチモーダル事前トレーニング データを収集し、事前トレーニング プロセスとトレーニング済みモデルをより効率的にし、適応力を高めました。ULIP-2 のメソッドには、各 3D オブジェクトに対してマルチアングルおよび異なる言語の説明を生成し、これらの説明を使用してモデルをトレーニングすることが含まれています。これにより、3D オブジェクト、2D 画像、および言語が説明を組み合わせることができます。 特徴空間の位置合わせは一貫しています。
このフレームワークを使用すると、手動アノテーションなしで大規模な 3 モーダル データセットを作成できるため、マルチモーダル事前トレーニングの可能性を最大限に活用できます。
ULIP-2 は、生成された大規模な 3 つのモーダル データ セット「ULIP - Objaverse Triplets」および「ULIP - ShapeNet Triplets」もリリースしました。

実験結果
ULIP シリーズは、マルチモーダルな下流タスクや 3D 表現の微調整実験で驚くべき結果を達成しました。特に ULIP-2 の事前学習は、手動によるアノテーションなしで達成できます。
ULIP-2 は、ModelNet40 の下流ゼロショット分類タスクで大幅な向上 (トップ 1 精度 74.0%) を達成しました。実際の ScanObjectNN ベンチマークでは、全体的な精度を達成しました。わずか 140 万のパラメータで 91.5% が達成され、手動の 3D アノテーションを必要としないスケーラブルなマルチモーダル 3D 表現学習における画期的な成果となりました。
アブレーション実験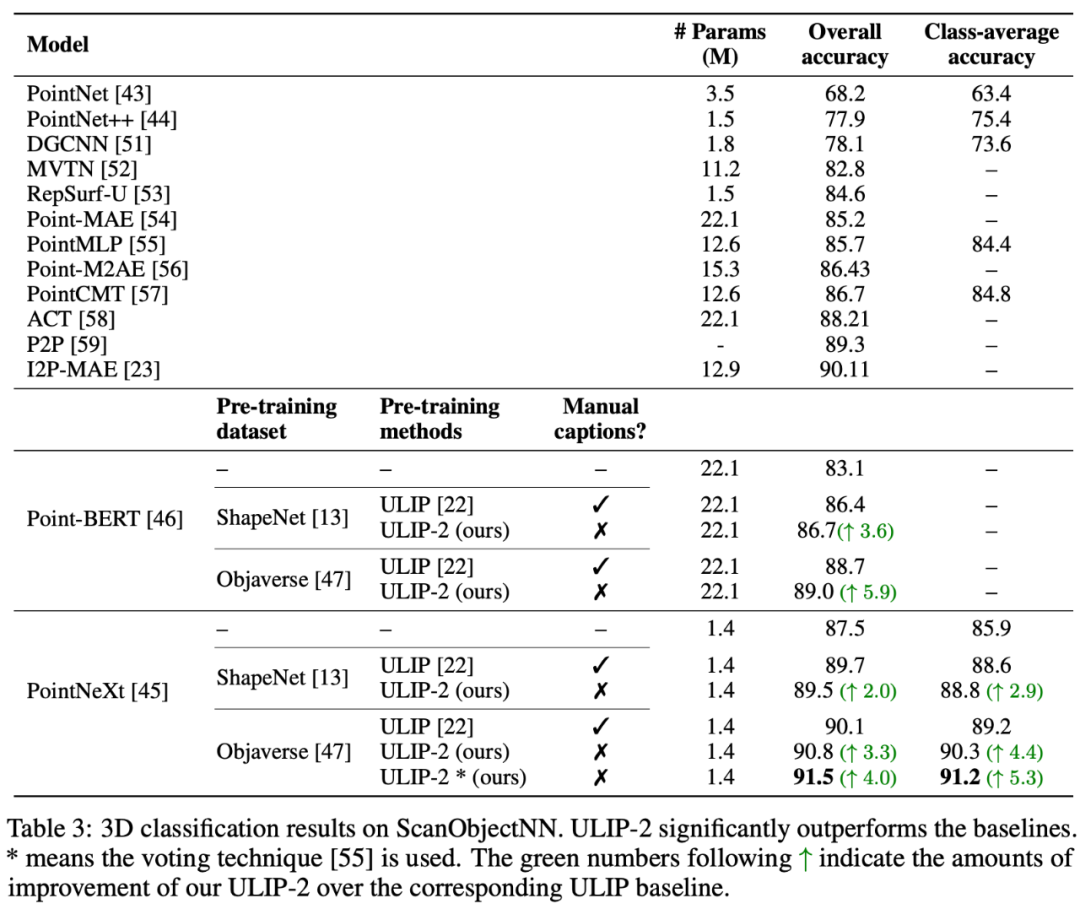
どちらの論文も詳細なアブレーション実験を実施しました。
「ULIP: Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding」では、ULIP の事前トレーニング フレームワークには 3 つのモダリティの参加が含まれるため、著者は実験を使用して2 つのモードを揃えるのが良いのか、それとも 3 つのモードをすべて揃えるのが良いのか? 実験結果は次のとおりです。実験結果から、異なる 3D バックボーンでは、2 つのモダリティのみを整列させるよりも 3 つのモダリティを整列させる方が優れており、これは ULIP の事前トレーニング フレームワークの合理性も証明しています。
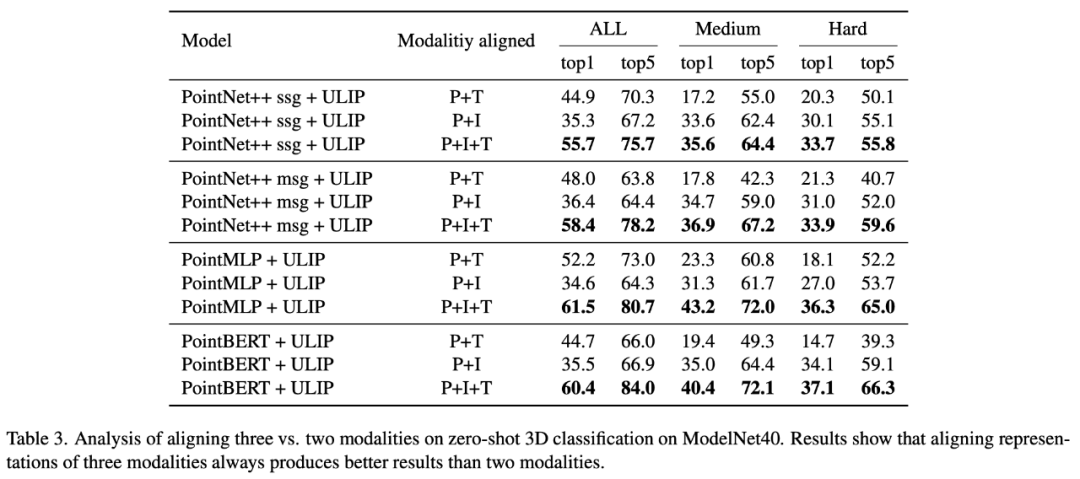 「ULIP-2: 3D 理解のためのスケーラブルなマルチモーダル事前トレーニングに向けて」では、著者は事前トレーニング フレームワークに対するさまざまな大規模マルチモーダル モデルの影響を調査しています。
「ULIP-2: 3D 理解のためのスケーラブルなマルチモーダル事前トレーニングに向けて」では、著者は事前トレーニング フレームワークに対するさまざまな大規模マルチモーダル モデルの影響を調査しています。
実験結果は、ULIP-2 フレームワークの事前トレーニングの効果が、大規模なメソッドを使用することでアップグレードできることがわかります。 -スケールマルチモーダルモデル、そしてプロモーションにはある程度の成長があります。
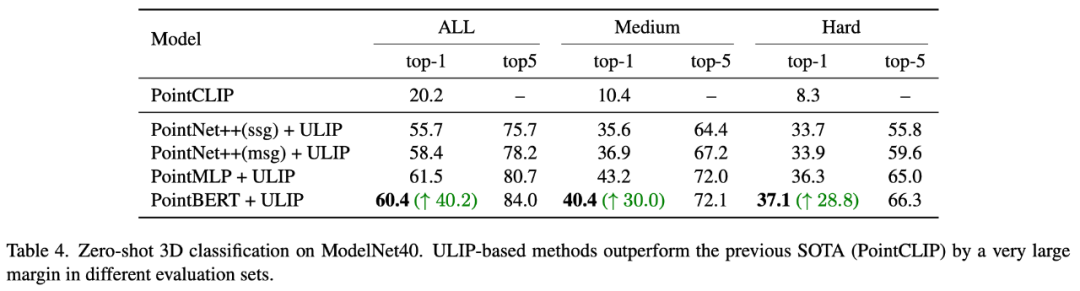 ULIP-2 では、著者は、異なる数のビューを使用して三峰性データセットを生成することが、全体的な事前トレーニングのパフォーマンスにどのような影響を与えるかを調査しました。実験結果は次のとおりです。 :
ULIP-2 では、著者は、異なる数のビューを使用して三峰性データセットを生成することが、全体的な事前トレーニングのパフォーマンスにどのような影響を与えるかを調査しました。実験結果は次のとおりです。 :
#実験結果は、使用される視点の数が増加するにつれて、事前トレーニングされたモデルのゼロショット分類の効果が低下することを示しています。も増えます。
 これは、より包括的で多様な言語記述がマルチモーダル事前トレーニングにプラスの効果をもたらすという ULIP-2 の点も裏付けています。
これは、より包括的で多様な言語記述がマルチモーダル事前トレーニングにプラスの効果をもたらすという ULIP-2 の点も裏付けています。
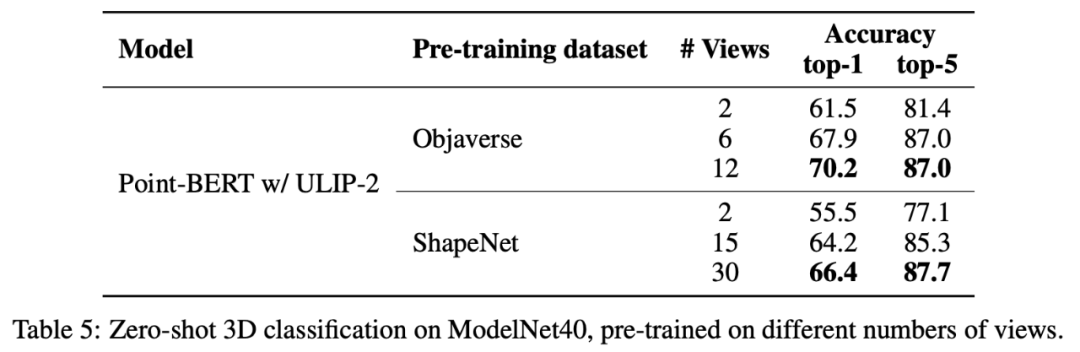
さらに、ULIP-2 では、CLIP によってソートされたさまざまな topk の言語記述がマルチモーダル事前トレーニングに及ぼす影響も調査しました。実験結果は次のとおりです。
##実験結果は、ULIP-2 フレームワークがさまざまな topk に対してある程度の堅牢性を持っていることを示しています。論文では上位 5 がデフォルト設定として使用されています。
結論
 Salesforce AI、スタンフォード大学、テキサス大学オースティン校が共同でリリースした ULIP プロジェクト (CVPR2023) と ULIP-2 は、医療分野を変えています。 3Dの理解。
Salesforce AI、スタンフォード大学、テキサス大学オースティン校が共同でリリースした ULIP プロジェクト (CVPR2023) と ULIP-2 は、医療分野を変えています。 3Dの理解。
ULIP は、さまざまなモダリティを統一空間に統合し、3D 機能の学習を強化し、クロスモーダル アプリケーションを可能にします。
ULIP-2 は、3D オブジェクトの総合的な言語記述を生成し、多数の 3 モーダル データ セットを作成してオープンソースにするためにさらに開発されており、このプロセスには手動の注釈は必要ありません。 。
これらのプロジェクトは、3D 理解における新たなベンチマークを設定し、機械が 3 次元の世界を真に理解する未来への道を切り開きます。
チームSalesforce AI:
Le Xue (Xue Le)、Mingfei Gao (Gao Mingfei)、Chen Xing (Xingchen)、Ning Yu (Yu Ning)、Shu Zhang (张捍)、Junnan Li (李俊 Nan)、Caiming Xiong (Xiong Caiming)、Ran Xu (Xu Ran)、Juan Carlos niebles、Silvio Savarese。
スタンフォード大学:
シルビオ・サバレーゼ教授、フアン・カルロス・ニーブルズ教授、ジャジュン・ウー教授(ウー・ジアジュン)。
UT オースティン:
ロベルト マルティン マルティン教授。
以上がデータのラベル付け不要、「3D理解」マルチモーダル事前学習の時代へ! ULIPシリーズは完全にオープンソースであり、SOTAを更新しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7517
7517
 15
1378
52
79
11
21
66
15
1378
52
79
11
21
66

 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 Microsoft Teams の 3D Fluent 絵文字について学ぶ
Apr 24, 2023 pm 10:28 PM
Microsoft Teams の 3D Fluent 絵文字について学ぶ
Apr 24, 2023 pm 10:28 PM
特に Teams ユーザーの場合は、Microsoft が仕事中心のビデオ会議アプリに 3DFluent 絵文字の新しいバッチを追加したことを覚えておく必要があります。 Microsoft が昨年 Teams と Windows 向けの 3D 絵文字を発表した後、その過程で実際に 1,800 を超える既存の絵文字がプラットフォーム用に更新されました。この大きなアイデアと Teams 用の 3DFluent 絵文字アップデートの開始は、公式ブログ投稿を通じて最初に宣伝されました。 Teams の最新アップデートでアプリに FluentEmojis が追加 Microsoft は、更新された 1,800 個の絵文字を毎日利用できるようになると発表
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 Windows 11 のペイント 3D: ダウンロード、インストール、および使用ガイド
Apr 26, 2023 am 11:28 AM
Windows 11 のペイント 3D: ダウンロード、インストール、および使用ガイド
Apr 26, 2023 am 11:28 AM
新しい Windows 11 が開発中であるというゴシップが広まり始めたとき、すべての Microsoft ユーザーは、新しいオペレーティング システムがどのようなもので、何をもたらすのかに興味を持ちました。憶測を経て、Windows 11が登場しました。オペレーティング システムには新しい設計と機能の変更が加えられています。いくつかの追加に加えて、機能の非推奨と削除が行われます。 Windows 11 に存在しない機能の 1 つは Paint3D です。描画、落書き、落書きに適したクラシックなペイントは引き続き提供していますが、3D クリエイターに最適な追加機能を提供する Paint3D は廃止されています。追加機能をお探しの場合は、最高の 3D デザイン ソフトウェアとして Autodesk Maya をお勧めします。のように
 カード1枚で30秒でバーチャル3D嫁をゲット! Text to 3D は、毛穴の詳細が明確な高精度のデジタル ヒューマンを生成し、Maya、Unity、その他の制作ツールとシームレスに接続します
May 23, 2023 pm 02:34 PM
カード1枚で30秒でバーチャル3D嫁をゲット! Text to 3D は、毛穴の詳細が明確な高精度のデジタル ヒューマンを生成し、Maya、Unity、その他の制作ツールとシームレスに接続します
May 23, 2023 pm 02:34 PM
ChatGPT は AI 業界に鶏の血を注入し、かつては考えられなかったすべてのことが今日では基本的な慣行になりました。進化を続ける Text-to-3D は、AIGC 分野において Diffusion(画像)、GPT(テキスト)に次ぐホットスポットとされ、前例のない注目を集めています。いいえ、ChatAvatar と呼ばれる製品が控えめなパブリック ベータ版として公開され、すぐに 700,000 回を超えるビューと注目を集め、Spacesoftheweek で特集されました。 △ChatAvatarは、AIが生成した単一視点/多視点の原画から3Dの様式化されたキャラクターを生成するImageto3D技術にも対応しており、現在のベータ版で生成された3Dモデルは広く注目を集めています。
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
 自動運転のための 3D 視覚認識アルゴリズムの詳細な解釈
Jun 02, 2023 pm 03:42 PM
自動運転のための 3D 視覚認識アルゴリズムの詳細な解釈
Jun 02, 2023 pm 03:42 PM
自動運転アプリケーションの場合、最終的には 3D シーンを認識することが必要になります。理由は簡単で、車両は画像から得られる知覚結果に基づいて運転することはできませんし、人間のドライバーであっても画像に基づいて運転することはできません。物体までの距離やシーンの奥行き情報は2D認識結果に反映できないため、自動運転システムが周囲の環境を正しく判断するための鍵となります。一般に、自動運転車の視覚センサー(カメラなど)は、車体上部または車内のバックミラーに設置されます。どこにいても、カメラが取得するのは、現実世界を透視図 (PerspectiveView) (世界座標系から画像座標系) に投影したものです。この視点は人間の視覚システムに非常に似ており、
