

Meta、わずか 2 秒で実際の人間の音声をシミュレートするオーディオ AI モデルをリリース

最近、Meta は、オーディオ シミュレーションにおいて大きな利点を持つ Voicebox AI モデルをリリースしました。
Voicebox が音声の詳細と音色を正確に識別し、テキスト結果に基づいて音声出力に変換するには、2 秒の音声サンプルのみが必要であると報告されています。

Voicebox は、オーディオの編集、サンプリング、スタイリングに役立つ生成 AI モデルです。
このテクノロジーは、将来クリエイターがオーディオ トラックを簡単に編集できるようにするために使用できると同時に、声帯を損傷した人々を支援し、再び「聞こえる」ようにすることもできます。視覚障害者が友人の書いたメッセージを音で聞くことができるようにするとともに、自分の声で外国語を話せるようにします。
同時に、音声クリップの前後の内容に基づいて、不足している内容を自動的に埋めることもできます。
Meta によると、Voicebox は将来のメタバースの AI アシスタントや NPC に自然でリアルな音声効果を提供し、使用時のユーザーの没入感を大幅に向上させることができます。
Voicebox の多用途性により、次のようなさまざまなタスクがサポートされます。
コンテキストに応じたテキスト読み上げ合成: わずか 2 秒のオーディオ サンプルを使用して、Voicebox はオーディオ スタイルを照合し、テキスト読み上げの生成に使用できます。
音声編集とノイズリダクション: Voicebox は、音声全体を再録音することなく、ノイズによって中断された音声の一部を再作成したり、言い間違えた単語を置き換えたりすることができます。たとえば、犬の吠えによって中断された音声のセグメントを特定し、切り取って、オーディオ編集用の消しゴムのように、Voicebox にそのセグメントを再生成するように指示できます。
言語間変換: 誰かのスピーチのサンプルと、英語、フランス語、ドイツ語、スペイン語、ポーランド語、またはポルトガル語のテキストが与えられると、Voicebox は、サンプルが異なる場合でも、これらの言語のいずれかでテキストの読みを生成できます。音声とテキストは別の言語です。将来的には、言語が理解できなくても、人々はこの機能を使用して、より自然かつ本物の方法でコミュニケーションできるようになるでしょう。
フロー マッチングは、Voicebox で使用される方法で、拡散モデルのパフォーマンスを向上させることが証明されています。 Voicebox は、現在の最先端の英語モデルである VALL-E よりも、明瞭度 (単語誤り率 5.9% 対 1.9%) と音声の類似性 (0.580 対 0.681) で優れており、20 倍高速です。言語間のスタイル転送に関しては、Voicebox は YourTTS よりも優れており、平均単語誤り率が 10.9% から 5.2% に減少し、音声の類似性が 0.335 から 0.481 に向上しました。
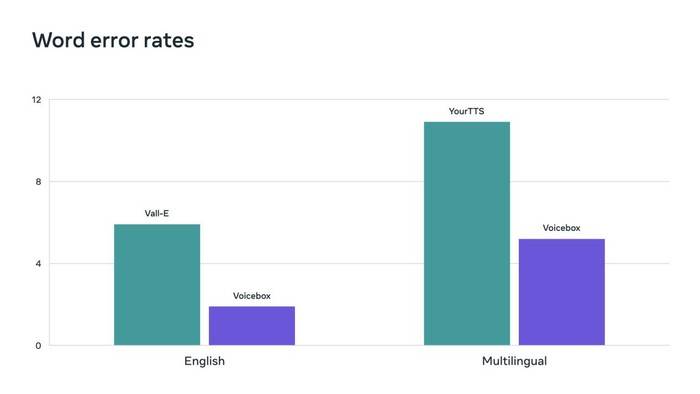
Voicebox は、単語エラー率において Vall-E や YourTTS を上回る、新しい最先端の結果を実現します。
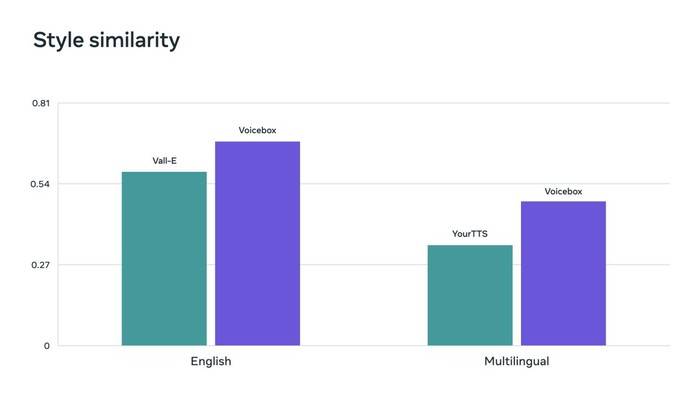
Voicebox は、英語と多言語のベンチマークにおけるオーディオ スタイルの類似性メトリックに関しても、それぞれ最先端の結果を達成しています。
Meta は現在、Voicebox が偽造の分野で使用される場合に存在する潜在的な害を認識しているため、実際の音声と Voicebox で生成された音声を区別する方法を模索していることは言及する価値があります。
解決策が見つかるまで、Meta は不必要な損害を避けるために Voicebox AI モデルを一般公開しません。
編集者のコメント: AIは現在さまざまな分野で応用されていますが、Voiceboxはタスクの汎化に成功した最初の多機能かつ効率的なモデルとして、音声生成AIの新時代を築くことができると信じています。 Meta が音声詐欺に効果的に対処できない場合、Voicebox テクノロジーが無効になる可能性があります。
以上がMeta、わずか 2 秒で実際の人間の音声をシミュレートするオーディオ AI モデルをリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1671
1671
 14
1428
52
1331
25
1276
29
1256
24
14
1428
52
1331
25
1276
29
1256
24

 GPT4o レベルを超える初のオープンソース モデル! Llama 3.1 がリーク: 4,050 億のパラメータ、ダウンロード リンク、モデル カードが利用可能
Jul 23, 2024 pm 08:51 PM
GPT4o レベルを超える初のオープンソース モデル! Llama 3.1 がリーク: 4,050 億のパラメータ、ダウンロード リンク、モデル カードが利用可能
Jul 23, 2024 pm 08:51 PM
GPUを準備しましょう!ついにLlama3.1が登場しましたが、ソースはMeta公式ではありません。今日、新しい Llama 大型モデルのリーク ニュースが Reddit で話題になり、基本モデルに加えて、8B、70B、最大パラメータ 405B のベンチマーク結果も含まれています。以下の図は、Llama3.1 の各バージョンと OpenAIGPT-4o および Llama38B/70B の比較結果を示しています。 70B バージョンでも複数のベンチマークで GPT-4o を上回っていることがわかります。画像ソース: https://x.com/mattshumer_/status/1815444612414087294 明らかに、8B と 70 のバージョン 3.1
 最強モデルLlama 3.1 405Bが正式リリース、ザッカーバーグ氏:オープンソースが新時代をリード
Jul 24, 2024 pm 08:23 PM
最強モデルLlama 3.1 405Bが正式リリース、ザッカーバーグ氏:オープンソースが新時代をリード
Jul 24, 2024 pm 08:23 PM
たった今、待望の Llama 3.1 が正式にリリースされました。 Metaは「オープンソースは新たな時代を導く」と公式に声を上げた。 Meta 氏は公式ブログで、「今日まで、オープンソースの大規模言語モデルは、機能とパフォーマンスの点でクローズド モデルに比べてほとんど遅れを取ってきました。今、私たちはオープンソースが主導する新しい時代の到来を告げています。私たちは MetaLlama3.1405B を一般公開しました」と述べました。これは世界で最大かつ最も強力なオープンソースの基本モデルであると私たちは信じています。現在までに、Llama のすべてのバージョンの合計ダウンロード数は 3 億回を超えており、Meta の創設者兼 CEO のザッカーバーグ氏も次のように書いています。」長い記事「OpenSourceAIsthePathForward」、
 新しくリリースされた Llama 3 を体験する 6 つの簡単な方法!
Apr 19, 2024 pm 12:16 PM
新しくリリースされた Llama 3 を体験する 6 つの簡単な方法!
Apr 19, 2024 pm 12:16 PM
昨夜、Meta は Llama38B および 70B モデルをリリースしました。Llama3 の命令調整モデルは、会話/チャットのユースケース向けに微調整および最適化されており、一般的なベンチマークで多くの既存のオープンソース チャット モデルを上回っています。たとえば、Gemma7B や Mistral7B などです。 Llama+3 モデルはデータとスケールを改善し、新たな高みに到達します。これは、Meta によって最近リリースされた 2 つのカスタム 24K GPU クラスター上の 15T トークンを超えるデータでトレーニングされました。このトレーニング データセットは Llama2 の 7 倍大きく、4 倍のコードが含まれています。これにより、Llama モデルの機能が現在の最高レベルになり、Llama2 の 2 倍である 8K を超えるテキスト長がサポートされます。下
 Llama3が突然やってくる!オープンソース コミュニティが再び沸騰: GPT4 レベルのモデルに無料でアクセスできる時代が到来
Apr 19, 2024 pm 12:43 PM
Llama3が突然やってくる!オープンソース コミュニティが再び沸騰: GPT4 レベルのモデルに無料でアクセスできる時代が到来
Apr 19, 2024 pm 12:43 PM
ラマ3が登場!先ほどMetaの公式サイトが更新され、Llamaの380億バージョンと700億パラメータのバージョンが公式から発表されました。そして、それは発売後のオープンソース SOTA です。メタ公式データは、Llama38B および 70B バージョンがそれぞれのパラメーター スケールですべての対戦相手を上回っていることを示しています。 8B モデルは、MMLU、GPQA、HumanEval などの多くのベンチマークで Gemma7B および Mistral7BInstruct を上回ります。 70B モデルは人気のクローズドソース フライド チキン Claude3Sonnet を超え、Google の GeminiPro1.5 と行ったり来たりしています。 Huggingface のリンクが公開されるとすぐに、オープンソース コミュニティは再び興奮しました。目の鋭い盲目の学生たちもすぐに発見した
 新しい手頃な価格の Meta Quest 3S VR ヘッドセットが FCC に登場、発売が近いことを示唆
Sep 04, 2024 am 06:51 AM
新しい手頃な価格の Meta Quest 3S VR ヘッドセットが FCC に登場、発売が近いことを示唆
Sep 04, 2024 am 06:51 AM
Meta Connect 2024イベントは9月25日から26日に予定されており、このイベントで同社は新しい手頃な価格の仮想現実ヘッドセットを発表すると予想されている。 Meta Quest 3S であると噂されている VR ヘッドセットが FCC のリストに掲載されたようです。この提案
 アナリストが噂のMeta Quest 3S VRヘッドセットの発売価格について語る
Aug 27, 2024 pm 09:35 PM
アナリストが噂のMeta Quest 3S VRヘッドセットの発売価格について語る
Aug 27, 2024 pm 09:35 PM
Meta による Quest 3 の最初のリリース (Amazon で現在 499.99 ドル) から 1 年以上が経過しました。それ以来、Apple はかなり高価な Vision Pro を出荷し、Byte Dance は中国で Pico 4 Ultra を発表しました。ただし、
 2024年にメタは「Orion」と呼ばれる革新的なARメガネのプロトタイプを発売する予定であると予想されている
Jan 04, 2024 pm 09:35 PM
2024年にメタは「Orion」と呼ばれる革新的なARメガネのプロトタイプを発売する予定であると予想されている
Jan 04, 2024 pm 09:35 PM
12 月 24 日のニュースによると、ソーシャル メディア業界で大きな影響力を持つテクノロジー企業であるメタ社は、次世代コンピューティング プラットフォームと考えられているテクノロジーである拡張現実 (AR) メガネに強い期待を寄せています。最近、メタ社のテクニカルディレクター、アンドリュー・ボズワース氏はインタビューで、同社がコードネーム「オリオン」という先進的なARグラスのプロトタイプを2024年に発売する予定であることを明らかにした。メタ社は長年にわたり、他の分野と同様にAR技術に投資しており、iPhoneに匹敵する革新的な製品の実現を目指し、数十億ドルに達する巨額の資金を投資してきました。昨年オリオングラスの量産計画の終了を発表しましたが、
 メタってどういう意味ですか?
Mar 05, 2024 pm 12:18 PM
メタってどういう意味ですか?
Mar 05, 2024 pm 12:18 PM
META は通常、メタバースと呼ばれる仮想世界またはプラットフォームを指します。メタバースとは、人間がデジタル技術を用いて構築した、現実世界を反映または超越し、現実世界と相互作用できる仮想世界であり、新たな社会システムを備えたデジタル生活空間です。
