

中国最強のAI研究機関の大型モデルはなぜ遅れているのか?

Huxiu Technology Group が制作
著者|Qi Jian
編集者|チェン・イーファン
ヘッダー画像|FlagStudio
「OpenAI は再び大規模モデルをオープンソース化しますか?」
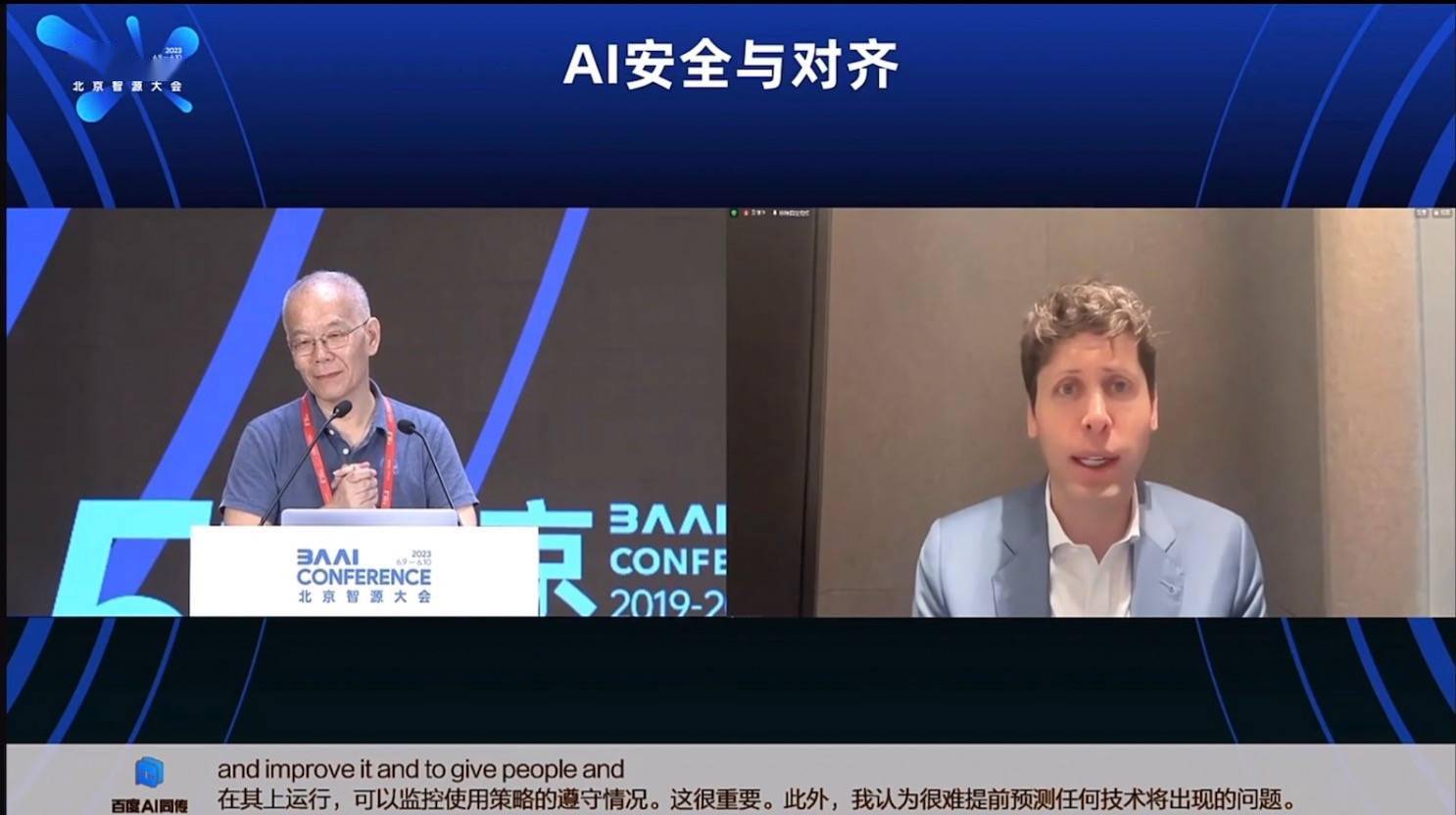
知源研究所の張宏江会長が、2023年の知源カンファレンスにオンラインで出席したOpenAIのCEO、サム・アルトマンにオープンソースの問題について尋ねると、サム・アルトマンは微笑みながら、OpenAIは今後さらに多くのコードを公開するだろうと語った。ただし、具体的なオープンソースのスケジュールはありません。
この議論は、この Zhiyuan カンファレンスのトピックの 1 つである オープンソースの大規模モデルから来ています。
6月9日、2023年知源会議が北京で開催され、全席が満席となった。カンファレンス会場では、参加者の雑談の中に「計算能力」「大型モデル」「エコロジー」といったAI関連の単語が時折登場し、またこの業界チェーンのさまざまな企業の言葉も登場した。

このカンファレンスで、Zhiyuan Research Institute は 包括的なオープンソース Wu Dao 3.0 をリリースしました。 ビジュアル大型モデルシリーズ「Vision」、言語大型モデルシリーズ「Sky Eagle」、独自大型モデル評価システム「Libra」を含む。
大規模モデルのオープンソースとは、AI 開発者が研究できるようにモデル コードを公開することを意味します。 Wu Dao 3.0 の「Sky Eagle」基本レイヤー言語モデルはまだ商用モデルであり、誰もがこの大規模なモデルを無料で使用できます。
現在、Microsoft の緊密なパートナーである OpenAI、Google、BAAI は、人工知能分野の最前線にある 3 つの機関です。 「最近のインタビューで、Microsoft 社長のブラッド スミス氏は、OpenAI や Google と同じくらい有名な中国の「最強」AI 研究機関である BAAI について言及しました。この機関は北京知源人工知能研究所です。業界の多くの人々は、次のように考えています。 、この研究所が主催する人工知能カンファレンスは、業界のトレンドのベンチマークです。
マイクロソフト社長も高く評価する知源研究所は、2020年10月には早くもAI大型モデル「Enlightenment」プロジェクトを立ち上げ、Enlightenmentモデル1.0とEnlightenmentの2バージョンを連続リリースしました。 2.0。 その中で、公式に発表されたEnlightenment 2.0のパラメータスケールは1.7兆に達します。当時、OpenAI が 1,750 億パラメータの GPT-3 モデルをリリースしてからわずか 1 年しか経っていませんでした。
しかし、このような大型 AI モデルのパイオニアは、過去 6 か月間の AI 大型モデルのブームの間、非常に控えめな態度をとっていました。大手メーカーや新興企業で大型モデルが次々と登場する中、Zhiyuanはメタ社の切り出しAI「SAM」と衝突した「SAM」以外は3カ月以上も対外的に「沈黙」を続けてきた「4 月上旬。SegGPT」では、大規模な AI モデルについてはほとんど何も公開されていません。
これに関して、AI 業界内外の多くの人が疑問を抱いていますが、AI 大型モデル分野のリーダーである智源研究所が、なぜ大型モデルの絶頂期に出遅れているように見えるのでしょうか?
オープンソース モデルは OpenAI の堀を解体するのでしょうか?
「現在、大型モデルの競争は熾烈を極めていますが、AI 大型モデルの分野では『オープンソース』の台頭が進んでおり、OpenAI も Google も外堀はありません。」
Google によって漏洩された文書の中で、Google 内部の研究者は、オープンソース モデルが将来の大規模モデル開発をリードする可能性があると考えています。この文書では、「オープンソース モデルはイテレーションが速く、カスタマイズ性がより高いです。より強力でプライベートです。」と述べられています。 、無料で制限のない代替モデルが同等の品質であれば、人々は制限付きのモデルにお金を払うことはありません。 」これは、Zhiyuan がオープンソースの大規模モデルの開発を選択した理由の 1 つである可能性もあります。
現在、オープンソースの商用大型モデルはそれほど多くありません。知源研究所は、リリースされている AI 大型モデルの一部について調査を実施しました。海外でリリースされている 39 のオープンソース言語大型モデルのうち、商用利用可能な AI 大型モデルは、大型モデルには 16 個が含まれます。中国でリリースされている 28 の主要な言語モデルのうち、合計 11 がオープンソース モデルですが、オープンソースで商用利用可能なモデルは 1 つだけです。今回 Zhiyuan がリリースした大規模言語モデルはオープンソースで商用利用可能です。また、現在商用利用可能な数少ないオープンソースの大規模言語モデルの 1 つでもあります。これはまた、このようなモデルは事前により慎重になる必要があることを判断しますそれを解放すること。
「Zhiyuan に関する限り、オープンソース モデルがあまりにも醜いものになることは絶対に望まないので、慎重にリリースします。」 Zhiyuan カンファレンスの AI 研究者は、オープンソース モデルには必然的に次のような問題が生じるだろうと述べました。オープンソースモデルの品質を確保するために、「オープンソース」によってZhiyuanの研究開発の進捗が遅れた可能性があります。
Zhiyuan Research Institute の所長、Huang Tiejun 氏は、我が国の市場における現在のオープンソースと大規模モデルのオープン性では十分とは言えないと考えています。「
私たちはオープンソースとオープンソースをさらに強化する必要があります。オープンソースとオープンソースはコンテストでもあります。本当に優れた標準と優れたアルゴリズムがあります。評価し、比較することによってのみ、技術レベルを証明できます。”
国内メーカーが大型モデルを発売する際には透明性が欠如しており、本当に自主的な研究開発を行っているのか疑問視する声も少なくありません。 API経由でChatGPTを呼び出しているという人もいれば、Metaから流出したLLaMAモデルであるChatGPTの回答データを使って学習させているという人もいるが、オープンソースモデルはこうした疑問をソースから遮断している。しかし、オープンソースモデルと技術の透明性の向上は、自分の無実を証明するためのものではなく、実際には「大きなことを成し遂げるために努力を集中する」ためのものです。 Zhiyuan のデータによると、天英ビッグ言語モデル の 1 日のトレーニング費用は 10 万元以上で、国内の「百モデル戦争」、さらには「千モデル戦争」の一般的な傾向の下で、多くの業界では、不必要に繰り返される大量のトレーニングによって発生する繰り返しの出費は天文学的な金額になる可能性があります。
そして、オープンソース モデルは、繰り返しのトレーニングを減らすことができます。モデルのニーズがある企業にとって、 大規模なオープンソースの商用 AI モデルを直接使用し、独自のデータをトレーニングに組み合わせることが、AI 実装と業界アプリケーションにとって最適なソリューションとなる可能性があります。
オープンソースのもう 1 つの考慮事項は、良好なエコシステムを構築し、将来の商用化を実現するために、初期段階でユーザーと開発者を蓄積することです。国内の大手モデル会社の創設者は Huxiu に対し、「OpenAI の GPT-1 と GPT-2 はどちらもオープンソースの大規模モデルです。これは、ユーザーを蓄積し、モデルの認知度を向上させるためです。GPT-3 のモデル機能が完全に完成したら、ディスプレイ、商用化が検討の焦点となり、このモデルは徐々にクローズドなものになっていきます。したがって、オープンソースモデルは一般的に商用利用を許可しませんが、これはその後の商用化の検討によるものでもあります。」
しかし、明らかに、Zhiyuan は非営利の研究機関として、オープンソースの問題に関して商業的な考慮は行っていません。 Zhiyuanにとって、モデルのオープンソースに関しては、一方ではAI大型モデル業界における科学研究とイノベーションを促進し、基盤となるモデルなどのオープンソースをオープンにすることで産業実装を加速したいと考えている。その一方で、オープンソース モデルに基づいてより多くのユーザー フィードバックを蓄積し、エンジニアリングにおける大規模モデルの使いやすさを向上させたいとも考えています。
ただし、オープンソースモデルは「完璧」ではありません。大手工場の AI テクニカル ディレクターは Huxiu に対し、現在の大規模 AI モデルの商用化市場は 3 つの層に分けることができる、と語った。特定のシナリオに基づいて独自のモデルをトレーニングする企業向けの第 3 層は、一般的なモデル機能のみを必要とし、ニーズを満たすために API 呼び出しを使用できる中小規模の顧客向けです。
これに関連して、オープンソース モデルは、自己調査機能を備えた主要企業がモデル開発にかかる時間とコストを大幅に節約するのに役立ちます。しかし、第 2 層および第 3 層の企業の場合、モデルのトレーニングと調整を行うために独自の技術チームを設立する必要があります。技術力の低い多くの企業にとって、これにより実装プロセスがより困難になります。プロセスはより複雑になり、オープンになります。ソースには、「無料のものが最も高価である」という感覚があるようです。
この「啓蒙」はもはやあの「啓蒙」ではない
ChiyuanのEnlightenment 3.0は、完全に再開発された大型モデルシリーズです。これも「リリースが遅い」理由の1つです。 Enlightenment 2.0 の基礎ができた今、Zhiyuan はなぜ新しいモデル システムを開発する必要があるのでしょうか?
これは、一方ではモデルの技術的方向性の調整であり、他方では、モデルの基礎となるトレーニング データの「置き換え」によるものです。「Wu Dao 2.0 の開発は 2021 年になるため、言語モデル (GLM など) であっても、ヴィンセント グラフ モデル (CogView など) であっても、ベースとなるアルゴリズム アーキテクチャは今から比較的早い段階にあります。この1年で関連分野のモデルアーキテクチャの検証や進化が多くなり、例えば言語モデルで使用されているデコーダのみのアーキテクチャは、より高品質なデータを基本モデルで取得できることが確認されました。大規模なパラメータの生成 生成パフォーマンスの向上 テキスト グラフ モデルでは、さらなる革新のために拡散ベースに切り替えました。そのため、Wu Dao 3.0 では、大規模な言語モデル、大規模なテキスト グラフの生成にこれらの更新を
採用しました。 Zhiyuan Research Institute の副社長兼チーフエンジニアの Lin Yonghua 氏は、過去のモデルの研究に基づいて、Wu Dao 3.0 は多方面から再構築されたと述べました。さらに、Wudao 3.0 は、基礎となるモデルのトレーニング データも包括的に最適化およびアップグレードされており、トレーニング データは、2021 年から現在までを含む更新された Wudao 中国データを使用し、より厳格な品質クリーニングを受けています。 hand, , 中国の書籍や文献など、高品質の中国語が大量に追加されました; さらに、高品質のコード データ セットが追加されたため、基本モデルも大幅に変更されました。
基礎となるモデルのトレーニング データはネイティブの中国語ではないため、多くの国内モデルで中国語の理解能力に問題が発生します。国内外の大規模 AI モデルの多くは、海外の膨大なオープンソース データをトレーニングに使用しています。主なソースには、有名なオープンソース データセット Common Crawl が含まれます。
Zhiyuan は 100 万件の Common Crawl Web ページ データを分析し、は 39,052 の中国語 Web ページを抽出できます。 Web サイトのソースの観点から見ると、中国語を抽出できる Web サイトは 25,842 ありますが、そのうち中国本土に IP を持つ Web サイトは 4,522 のみで、17% にすぎません。
これにより、中国のデータの精度が大幅に低下するだけでなく、セキュリティも低下します。「基本モデルのトレーニングに使用されるコーパスは、コンプライアンス、セキュリティ、AIGC アプリケーション、微調整されたモデル、その他のコンテンツによって生成される価値に大きく影響します。」 林永華氏は、天英基本モデルの中国語能力は次のとおりであると述べました。単純な翻訳ではありません。「十分な中国語の知識をこのモデルに押し込む」ことにより、 中国語のインターネット データの 99% は国内の Web サイトからのものであり、企業はそれに基づいて継続的なトレーニングを安全に実施できます。
同時に、データと数値の大量の洗練された処理とクリーニングを通じて、同じかそれ以上のパフォーマンスを持つモデルを少量のデータでトレーニングすることができます。このデータは 30 という少ないデータでも可能ですデータ量の % または 40% であり、既存のオープンソース モデルに追いつくか、超える可能性があります。
Zhiyuan にとっては、この道がより良い解決策である可能性があるようです。なぜなら、学習データの点で、Zhiyuan にはインターネット メーカーと比較して欠点があるからです。大手インターネット企業は、トレーニング用に豊富なユーザー インタラクション データと大量の著作権データを持っています。少し前に、Alibaba Damo Academy はビデオ言語データ セット Youku-mPLUG をリリースしました。そのすべてのコンテンツは、アリババが所有するビデオ プラットフォームである Youku から提供されています。
Zhiyuan には豊富なユーザー ベースがないため、学習データに関しては、著作権所有者との交渉を通じて許可を取得し、いくつかの公共福祉データ プロジェクトを通じて少しずつ収集および蓄積することしかできません。
しかし、現時点では、Zhiyuan の中国語データセットは部分的にしかオープンソースにすることができません。主な理由は、中国データの著作権がさまざまな機関の手に分散しているためです。現在、Zhiyuan のトレーニング データは、次の機関の調整を通じて取得されています。オープンソース モデルでは、オープン アクセスを研究します。データのほとんどは Zhiyuan のモデルにのみ適用でき、二次使用する権利はありません。"
中国では、データセットの産業連合を設立し、著作権者を団結させ、人工知能の学習データを統一的に計画することが非常に必要ですが、これにはトップレベルの設計の知恵が必要です。」と林永華さんは胡秀さんに語った。
国内大型模型業界の黃埔陸軍士官学校Wudao 3.0 は Wudao 2.0 とは異なるストーリーを伝えており、研究開発チームの変更もその 1 つです。 AI大型モデル業界のパイオニアである知源研究所は、国産AI大型モデルの黄埔陸軍士官学校のようなものです。
Zhiyuan の学者から草の根のエンジニアまで、彼らは今日の大型模型ブームの中で業界で人気を博しており、Zhiyuan のオリジナル チームはまた、いくつかの大規模な起業家チームを育成しています。
Wu Dao 3.0 以前の大規模モデル シリーズは、複数の外部研究所が共同でリリースした研究結果を組み合わせたものでしたが、今回の Wu Dao 3.0 は、Zhiyuan チームが完全に自社開発したモデル シリーズです。Wudao 2.0モデルは2021年にリリースされ、Wenyuan、Wenlan、Wenhui、Wensuが含まれます。このうち、2 つのコアモデルは清華大学の 2 つの研究室によって完成されました。現在、2 つのチームは独自の会社を設立し、CPM と GLM の研究開発の方向で独自の独立した製品を開発しています。
その中で、GLM の主な研究開発チームである清華大学知識工学研究所 (KEG) は、Zhipu AI と共同でオープンソース モデル ChatGLM-6B を発表し、業界で広く認知されています。コンピュータサイエンス学部の自然言語処理・社会人文計算研究室(THUNLP)のメンバーで構成された沈安科技CPMチームは、1年前の設立以来、さまざまな資本から支持されている。今年は2回の資金調達ラウンドで投資が行われ、中国、Qiji Chuangtan、その他のファンドが参加した。
Zhiyuan Research Institute に近い人物は Huxiu に次のように語った。他の会社やヘッドハンターによって優れています。」
現在、国内のAI大型モデル業界で最も不足しているのはお金であり、最も不足しているのは人材です。 Liepin、Maimai、BOSS Zhipin の 3 つのプラットフォームで ChatGPT を検索. 修士号や博士号を持つポジションの月給は一般的に 30,000 を超え、最高は 90,000 です。 「給与の面では、大手IT企業はあまり有利ではありません。大規模なAIモデルの研究開発はすべて高いレベルで行われています。スタートアップ企業が提供する給与は、より競争力があるかもしれません。」 Xihu Xinchen社COOのYu Jia氏、AI業界での才能ある戦争はますます激しくなるだろうと胡秀に語った。
「Zhiyuan の多くの従業員にとって、2 倍の給与はまったく競争力のあるものではありません。なぜなら、彼らは今、5 倍、さらには 10 倍の給与を持つ人材を引き抜いているからです。あなたがどれほど理想的で、どのように将来計画を立てていても、それは競争力に欠けます。知源氏に近い関係者は胡秀氏に、「知源氏は非営利の研究機関であるため、給与水準が大手インターネット企業に匹敵するのは難しい」と語った。支援されたスタートアップと比較して、多額の資金を背景にしている企業。
Huxiu はヘッドハンティングを通じて、自然言語処理専門家の初任給が現在 100 万を超えていることを知りました。勤続年数が長く、賃金が低い一部の従業員にとって、自分の数倍の給与を前にすると、動揺しないのは困難です。
しかし、知源研究所の現在の公開データから判断すると、知源研究所の中核プロジェクトチームリーダーのほとんどは依然として知源研究所の研究開発プロジェクトをフルタイムで担当しています。"
Enlightenment 3.0 のモデルはすべて、Tianying、Libra、Vision を含む Zhiyuan 自身の研究者によって開発されました。
" Lin Yonghua 氏は、Zhiyuan Research Institute の現在の研究開発力は世界で最高のものの一つであると述べました。業界の中でも一流です。世界を変えようとしている人、そして世界を変えたいと思っている人がHuxiu APPを利用しています
以上が中国最強のAI研究機関の大型モデルはなぜ遅れているのか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
18
20
15
1376
52
77
11
18
20

 ビッグモデルアプリ Tencent Yuanbao がオンラインになりました! Hunyuan がアップグレードされ、どこにでも持ち運べるオールラウンドな AI アシスタントが作成されました
Jun 09, 2024 pm 10:38 PM
ビッグモデルアプリ Tencent Yuanbao がオンラインになりました! Hunyuan がアップグレードされ、どこにでも持ち運べるオールラウンドな AI アシスタントが作成されました
Jun 09, 2024 pm 10:38 PM
5月30日、TencentはHunyuanモデルの包括的なアップグレードを発表し、Hunyuanモデルに基づくアプリ「Tencent Yuanbao」が正式にリリースされ、AppleおよびAndroidアプリストアからダウンロードできるようになりました。前のテスト段階のフンユアン アプレット バージョンと比較して、Tencent Yuanbao は、日常生活シナリオ向けの AI 検索、AI サマリー、AI ライティングなどのコア機能を提供し、Yuanbao のゲームプレイもより豊富で、複数の機能を提供します。 、パーソナルエージェントの作成などの新しいゲームプレイ方法が追加されます。 Tencent Cloud 副社長で Tencent Hunyuan 大型モデルの責任者である Liu Yuhong 氏は、「テンセントは、最初に大型モデルを開発しようとはしません。」と述べました。 Tencent Hunyuan の大型モデルは、ビジネス シナリオにおける豊富で大規模なポーランド テクノロジーを活用しながら、ユーザーの真のニーズを洞察します。
 Bytedance Beanbao 大型モデルがリリース、Volcano Engine フルスタック AI サービスが企業のインテリジェントな変革を支援
Jun 05, 2024 pm 07:59 PM
Bytedance Beanbao 大型モデルがリリース、Volcano Engine フルスタック AI サービスが企業のインテリジェントな変革を支援
Jun 05, 2024 pm 07:59 PM
Volcano Engine の社長である Tan Dai 氏は、大規模モデルを実装したい企業は、モデルの有効性、推論コスト、実装の難易度という 3 つの重要な課題に直面していると述べました。複雑な問題を解決するためのサポートとして、適切な基本的な大規模モデルが必要です。また、サービスは低コストの推論を備えているため、大規模なモデルを広く使用できるようになり、企業がシナリオを実装できるようにするためには、より多くのツール、プラットフォーム、アプリケーションが必要になります。 ——Huoshan Engine 01 社長、Tan Dai 氏。大きなビーンバッグ モデルがデビューし、頻繁に使用されています。モデル効果を磨き上げることは、AI の実装における最も重要な課題です。 Tan Dai 氏は、良いモデルは大量に使用することでのみ磨かれると指摘しました。現在、Doubao モデルは毎日 1,200 億トークンのテキストを処理し、3,000 万枚の画像を生成しています。企業による大規模モデルシナリオの実装を支援するために、バイトダンスが独自に開発した豆包大規模モデルが火山を通じて打ち上げられます。
 Shengteng AI テクノロジーを使用した秦嶺・秦川交通モデルは、西安のスマート交通イノベーション センターの構築を支援します
Oct 15, 2023 am 08:17 AM
Shengteng AI テクノロジーを使用した秦嶺・秦川交通モデルは、西安のスマート交通イノベーション センターの構築を支援します
Oct 15, 2023 am 08:17 AM
「高度な複雑性、高度な断片化、およびクロスドメイン」は、輸送業界のデジタル化およびインテリジェントなアップグレードに向かう上で常に主要な問題点でした。最近、チャイナビジョン、西安雁塔区政府、西安未来人工知能コンピューティングセンターが共同で構築したパラメータースケール1000億の「秦嶺・秦川交通モデル」は、スマート交通・交通分野を指向している。西安とその周辺地域にサービスを提供しており、この地域はスマート交通イノベーションの拠点となるでしょう。 「秦嶺・秦川交通モデル」は、オープンシナリオにおける西安の膨大な地元交通生態データ、中国科学ビジョンが自社開発したオリジナルの高度なアルゴリズム、そして西安未来人工知能コンピューティングセンターのShengteng AIの強力なコンピューティング能力を組み合わせたものです。道路網の監視を提供するため、緊急指令、メンテナンス管理、公共交通機関などのスマートな交通シナリオは、デジタルでインテリジェントな変化をもたらします。交通管理には都市ごとに異なる特徴があり、道路の交通状況も異なります。
 NVIDIA の大規模モデル推論フレームワークを明らかにする: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
NVIDIA の大規模モデル推論フレームワークを明らかにする: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
1. TensorRT-LLM の製品位置付け TensorRT-LLM は、NVIDIA が開発した大規模言語モデル (LLM) 向けのスケーラブルな推論ソリューションです。 TensorRT 深層学習コンパイル フレームワークに基づいて計算グラフを構築、コンパイル、実行し、FastTransformer の効率的なカーネル実装を利用します。さらに、デバイス間の通信には NCCL を利用します。開発者は、カットラスに基づいてカスタマイズされた GEMM を開発するなど、技術開発や需要の違いに基づいて特定のニーズを満たすためにオペレーターをカスタマイズできます。 TensorRT-LLM は、NVIDIA の公式推論ソリューションであり、高いパフォーマンスを提供し、実用性を継続的に向上させることに尽力しています。 TensorRT-LL
 GPT-4をベンチマーク!中国移動の九天大型モデルが二重登録を通過
Apr 04, 2024 am 09:31 AM
GPT-4をベンチマーク!中国移動の九天大型モデルが二重登録を通過
Apr 04, 2024 am 09:31 AM
4月4日のニュースによると、中国サイバースペース局は最近、登録された大型モデルのリストを発表し、その中にチャイナモバイルの「九天自然言語インタラクション大型モデル」が含まれており、チャイナモバイルの九天AI大型モデルが生成人工言語を正式に提供できることを示した。外部世界への諜報機関。チャイナモバイルは、これは中央企業が開発した初めての大規模モデルであり、国家の「生成人工知能サービス登録」と「国内深層合成サービスアルゴリズム登録」の二重登録を通過したと述べた。報告によると、Juiutian の自然言語インタラクション大規模モデルは、強化された業界能力、セキュリティ、信頼性の特徴を持ち、フルスタック ローカリゼーションをサポートしており、90 億、139 億、570 億、1000 億などのさまざまなパラメータ バージョンを形成しており、クラウド、エッジ、エンドでは状況が異なりますが、柔軟に導入できます。
 新しいテストベンチマークがリリース、最も強力なオープンソースのLlama 3が困惑
Apr 23, 2024 pm 12:13 PM
新しいテストベンチマークがリリース、最も強力なオープンソースのLlama 3が困惑
Apr 23, 2024 pm 12:13 PM
テストの問題が簡単すぎると、上位の生徒も下位の生徒も 90 点を獲得でき、その差は広がりません。Claude3、Llama3、さらには GPT-5 などのより強力なモデルが後にリリースされるため、業界はより困難で差別化されたモデルのベンチマークが緊急に必要です。大型モデルアリーナの背後にある組織 LMSYS は、次世代ベンチマーク Arena-Hard を発表し、広く注目を集めました。 Llama3 命令の 2 つの微調整されたバージョンの強度に関する最新のリファレンスもあります。全員が同様のスコアを持っていた以前の MTBench と比較すると、アリーナとハードの識別は 22.6% から 87.4% に増加し、一目で強くも弱くもなりました。 Arena-Hard は、アリーナからのリアルタイムの人間データを使用して構築されており、人間の好みとの一致率は 89.1% です。
 産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
1. 背景の紹介 まず、Yunwen Technology の開発の歴史を紹介します。 Yunwen Technology Company ...2023 年は大規模モデルが普及する時期であり、多くの企業は大規模モデルの後、グラフの重要性が大幅に低下し、以前に検討されたプリセット情報システムはもはや重要ではないと考えています。しかし、RAG の推進とデータ ガバナンスの普及により、より効率的なデータ ガバナンスと高品質のデータが民営化された大規模モデルの有効性を向上させるための重要な前提条件であることがわかり、ますます多くの企業が注目し始めています。知識構築関連コンテンツへ。これにより、知識の構築と処理がより高いレベルに促進され、探索できる技術や方法が数多く存在します。新しいテクノロジーの出現によってすべての古いテクノロジーが打ち破られるわけではなく、新旧のテクノロジーが統合される可能性があることがわかります。
 Xiaomi Byteが力を合わせます! Xiao Ai の Doubao へのアクセスの大規模モデル: 携帯電話と SU7 にすでにインストールされています
Jun 13, 2024 pm 05:11 PM
Xiaomi Byteが力を合わせます! Xiao Ai の Doubao へのアクセスの大規模モデル: 携帯電話と SU7 にすでにインストールされています
Jun 13, 2024 pm 05:11 PM
6月13日のニュースによると、Byteの「Volcano Engine」公開アカウントによると、Xiaomiの人工知能アシスタント「Xiao Ai」はVolcano Engineとの協力に達し、両社はbeanbao大型モデルに基づいて、よりインテリジェントなAIインタラクティブ体験を実現するとのこと。 。 ByteDance が作成した大規模な豆包モデルは、毎日最大 1,200 億のテキスト トークンを効率的に処理し、3,000 万個のコンテンツを生成できると報告されています。 Xiaomi は、Doubao 大型モデルを使用して、独自モデルの学習能力と推論能力を向上させ、ユーザーのニーズをより正確に把握するだけでなく、より速い応答速度とより包括的なコンテンツ サービスを提供する新しい「Xiao Ai Classmate」を作成しました。たとえば、ユーザーが複雑な科学的概念について質問する場合、&ldq
