

紙のイラストも拡散モデルを使用して自動生成でき、ICLR にも受け入れられます。

生成 AI は人工知能コミュニティに旋風を巻き起こし、個人も企業も、Vincent 写真、Vincent ビデオ、Vincent 音楽など、関連するモーダル変換アプリケーションの作成に熱心になり始めています。
最近、ServiceNow Research や LIVIA などの科学研究機関の数名の研究者が、テキストの説明に基づいて論文内のグラフを生成しようとしました。この目的のために、彼らは FigGen の新しい手法を提案し、関連する論文も ICLR 2023 の Tiny Paper として掲載されました。
 写真
写真
論文アドレス: https://arxiv.org/pdf/2306.00800.pdf
論文内のグラフを生成するのがそんなに難しいのかと疑問に思う人もいるかもしれません。これは科学研究にどのように役立ちますか?
科学研究チャートの生成は、研究結果を簡潔かつわかりやすい方法で広めるのに役立ちます。チャートの自動生成は、時間とエネルギーを節約するなど、研究者に多くのメリットをもたらします。グラフをゼロからデザインすることに労力を費やしてください。また、視覚的にわかりやすく図をデザインすることで、より多くの人に論文を読んでもらうことができます。
ただし、図の生成には、ボックス、矢印、テキストなどの個別のコンポーネント間の複雑な関係を表現する必要があるという課題もあります。自然画像の生成とは異なり、紙のグラフでは概念が異なる表現を持ち、詳細な理解が必要となる場合があります。たとえば、ニューラル ネットワーク グラフの生成には、分散が大きい不正設定問題が含まれます。
したがって、この論文の研究者は、紙の図のペアのデータセットで生成モデルをトレーニングし、図のコンポーネントと論文内の対応するテキストの間の関係を把握しました。これには、さまざまな長さ、高度に専門的なテキストの説明、さまざまなグラフ スタイル、画像のアスペクト比、テキスト レンダリングのフォント、サイズ、向きの問題に対処する必要があります。
具体的な実装プロセスでは、研究者たちは最近のテキストから画像への結果からインスピレーションを得て、拡散モデルを使用してチャートを生成し、科学研究チャートを生成するための普及の可能性を提案しました。テキストの説明。モデル - FigGen。
この普及モデルのユニークな特徴は何ですか?詳細に進みましょう。
モデルと手法
研究者たちは、潜在拡散モデルをゼロからトレーニングしました。
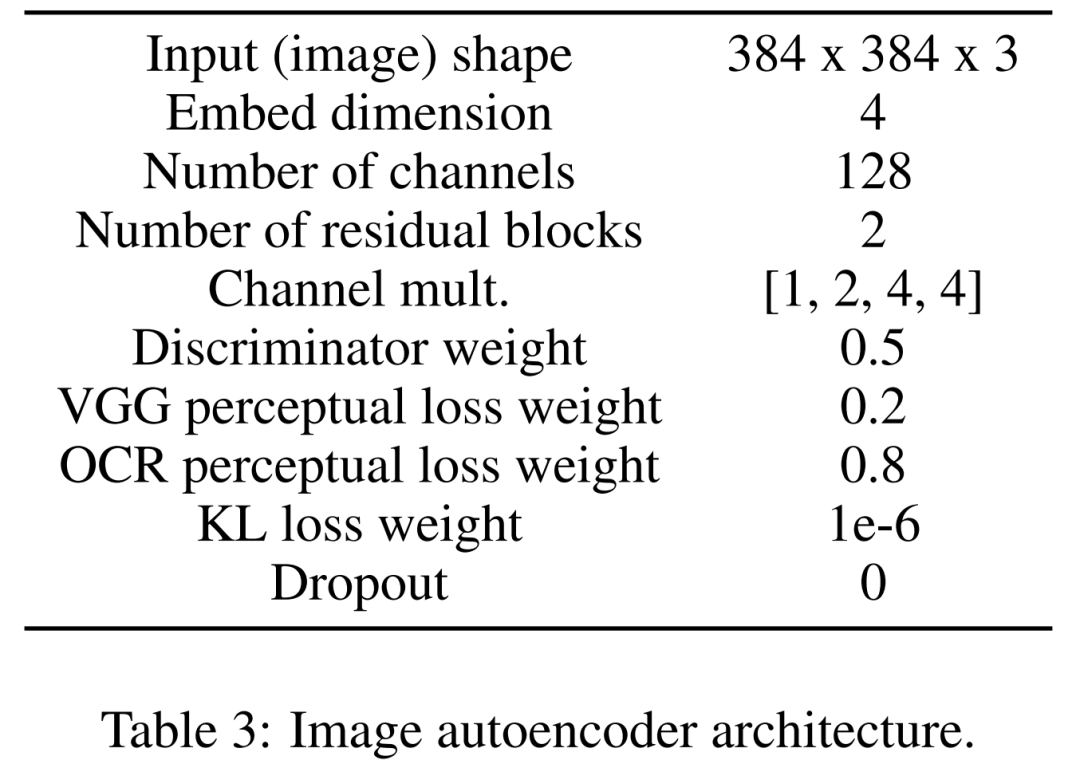
まず、画像を圧縮された潜在表現にマッピングするための画像オートエンコーダーを学習します。画像エンコーダは、KL 損失と OCR 知覚損失を使用します。条件付けに使用されるテキスト エンコーダーは、この拡散モデルのトレーニングでエンドツーエンドで学習されます。以下の表 3 は、画像オートエンコーダ アーキテクチャの詳細なパラメータを示しています。
拡散モデルは潜在空間で直接対話し、データ破損したフォワード スケジューリングを実行しながら、時間的およびテキストの条件付きノイズ除去 U-Net を利用してプロセスから回復する方法を学習します。
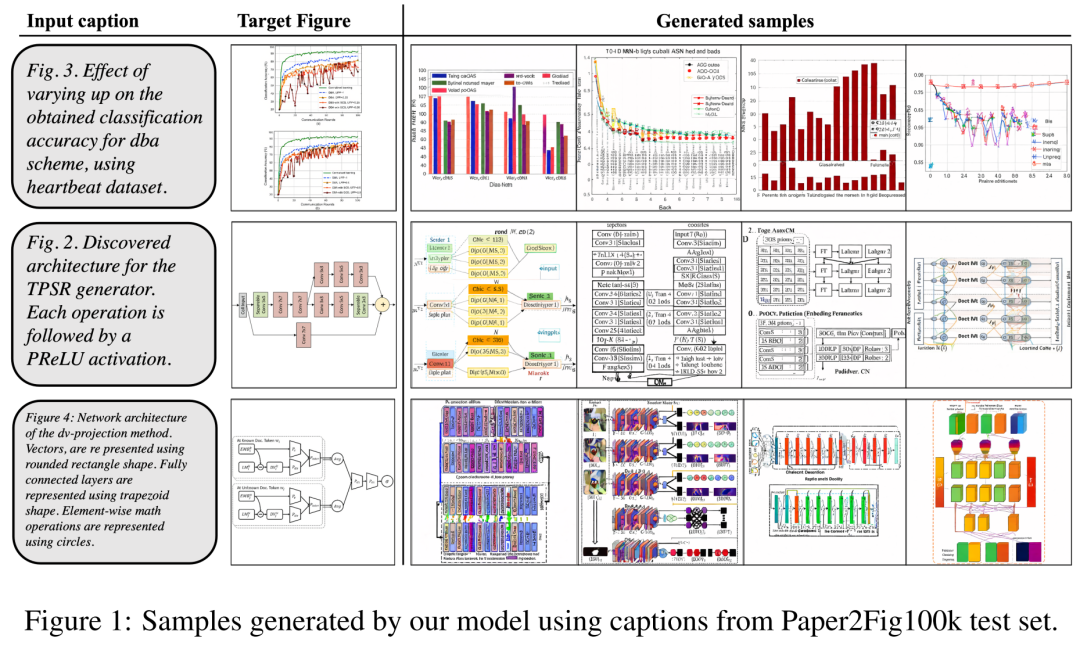
## データセットとして、研究者らは Paper2Fig100k を使用しました。これは論文内のグラフとテキストのペアで構成され、81,194 個のデータが含まれています。トレーニング サンプルと 21,259 の検証サンプル。以下の図 1 は、Paper2Fig100k テスト セットのテキスト説明を使用して生成された図の例です。
#モデル詳細
まずは画像エンコーダー。最初の段階では、画像オートエンコーダーがピクセル空間から圧縮された潜在表現へのマッピングを学習し、拡散モデルのトレーニングを高速化します。また、画像エンコーダーは、図の重要な詳細 (テキストのレンダリング品質など) を失うことなく、潜像をピクセル空間にマップし直す方法を学習する必要があります。この目的を達成するために、研究者らは、因子 f=8 で画像をダウンサンプリングするボトルネックを備えた畳み込みコーデックを定義しました。エンコーダーは、ガウス分布を使用して KL 損失、VGG 認識損失、OCR 認識損失を最小限に抑えるようにトレーニングされています。
2 番目はテキスト エンコーダーです。研究者らは、汎用テキスト エンコーダがグラフ生成タスクには適していないことを発見しました。したがって、彼らは、サイズ 512 の埋め込みチャネルを使用する拡散プロセスで最初からトレーニングされた Bert トランスフォーマーを定義しました。これは、U-Net のクロスアテンション層を調整する埋め込みサイズでもあります。研究者らは、さまざまな設定(8、32、128)下での変圧器層の数の変化も調査しました。
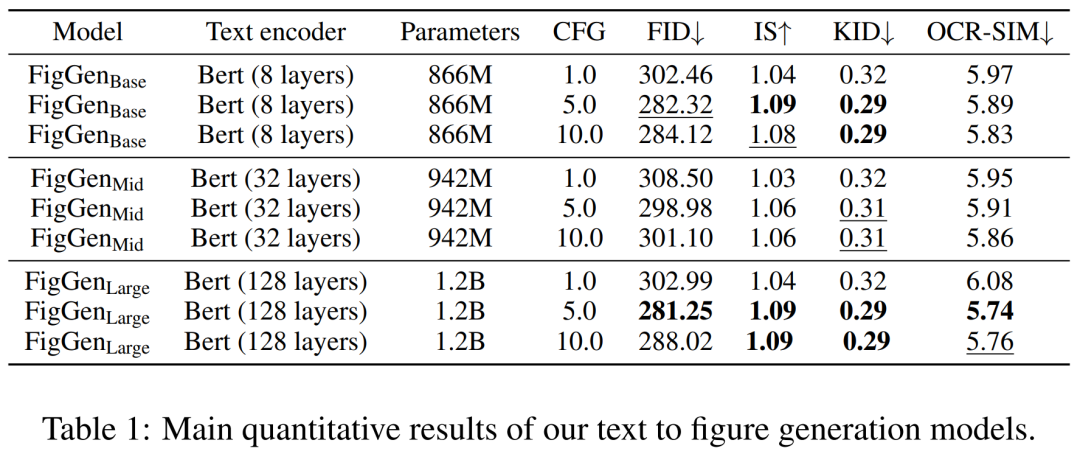
最後に、潜在拡散モデルがあります。以下の表 2 は、U-Net のネットワーク アーキテクチャを示しています。画像の知覚的に等価な潜在表現に対して拡散プロセスを実行します。この場合、画像の入力サイズは 64x64x4 に圧縮され、拡散モデルが高速になります。彼らは 1,000 の拡散ステップと線形ノイズ スケジューリングを定義しました。 トレーニングの詳細 潜在拡散モデルをトレーニングするために、研究者らは、有効バッチ サイズ 32、学習率 1e−4 の Adam オプティマイザーも使用しました。 Paper2Fig100k データセットでモデルをトレーニングするとき、8 枚の 80GB NVIDIA A100 グラフィックス カードを使用しました。 実験結果 以下の表 1 は、さまざまなテキスト エンコーダーの結果を示しています。大きなテキスト エンコーダが最良の定性的結果を生成し、CFG のサイズを増やすことで条件生成を改善できることがわかります。定性サンプルは問題を解決するには十分な品質ではありませんが、FigGen はテキストと画像の関係を把握しました。
写真 写真 研究の詳細については、元の論文を参照してください。 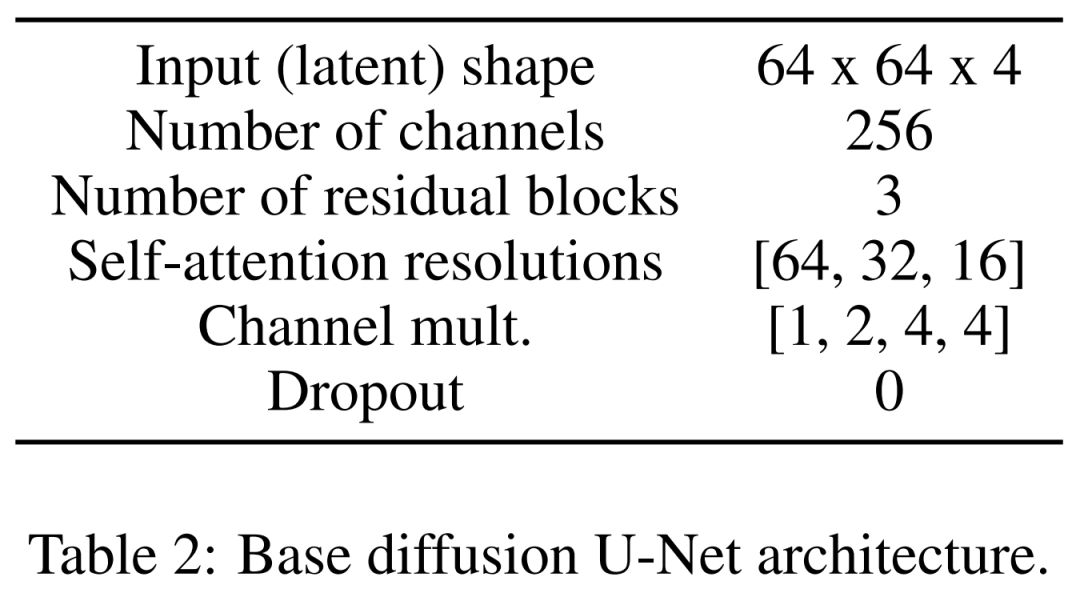
生成プロセスでは、研究者は 200 ステップの DDIM サンプラーを使用し、12,000 のサンプルを生成して FID、IS、 KIDとOCR-SIM1。ハイパーコンディショニングをテストするための分類子なしガイダンス (CFG) の強力な使用。
 # 以下の図 2 は、Classifier-Free Guide (CFG) パラメーターを調整するときに生成される追加の FigGen サンプルを示しています。研究者らは、CFG のサイズを大きくすると画質が向上することを観察しました。これは定量的にも実証されました。
# 以下の図 2 は、Classifier-Free Guide (CFG) パラメーターを調整するときに生成される追加の FigGen サンプルを示しています。研究者らは、CFG のサイズを大きくすると画質が向上することを観察しました。これは定量的にも実証されました。 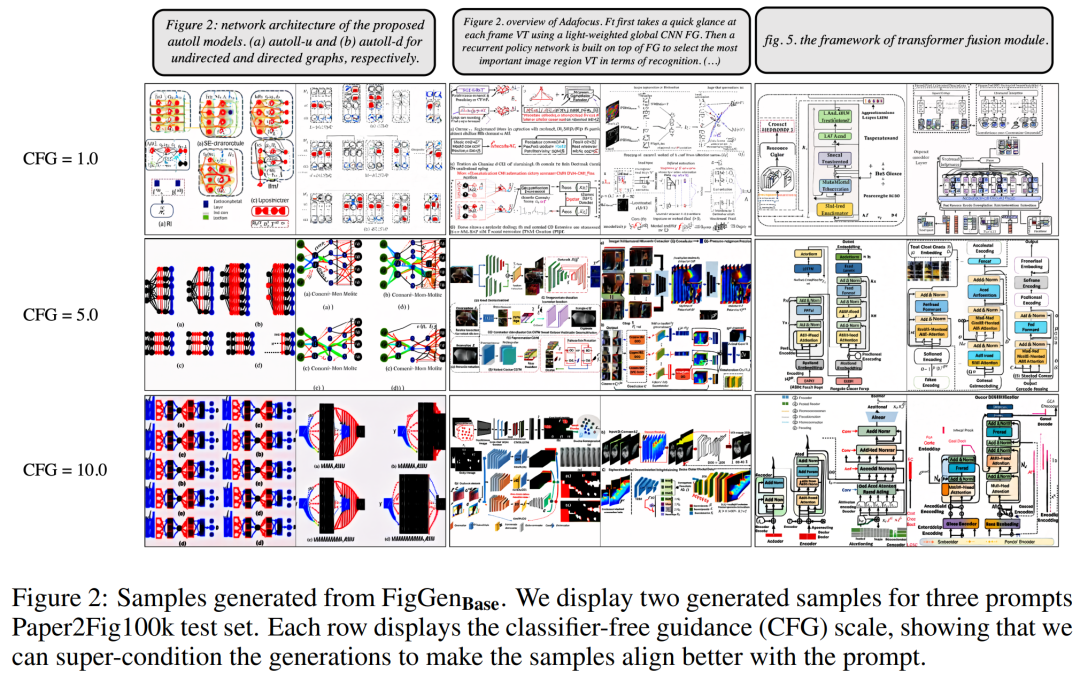 下の図 3 は、FigGen からのその他の生成例を示しています。理解可能な画像を正しく生成するモデルの難易度に密接に影響するテキスト記述の技術レベルだけでなく、サンプル間の長さの違いにも注意してください。
下の図 3 は、FigGen からのその他の生成例を示しています。理解可能な画像を正しく生成するモデルの難易度に密接に影響するテキスト記述の技術レベルだけでなく、サンプル間の長さの違いにも注意してください。  ただし、研究者らは、これらの生成されたグラフは論文の著者にとって実際的な助けにはならないが、彼らはまだそれを有望な探求の方向とみなすことができます。
ただし、研究者らは、これらの生成されたグラフは論文の著者にとって実際的な助けにはならないが、彼らはまだそれを有望な探求の方向とみなすことができます。
以上が紙のイラストも拡散モデルを使用して自動生成でき、ICLR にも受け入れられます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7479
7479
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
sqllimit句:クエリ結果の行数を制御します。 SQLの制限条項は、クエリによって返される行数を制限するために使用されます。これは、大規模なデータセット、パジネートされたディスプレイ、テストデータを処理する場合に非常に便利であり、クエリ効率を効果的に改善することができます。構文の基本的な構文:SelectColumn1、column2、... FromTable_nameLimitnumber_of_rows; number_of_rows:返された行の数を指定します。オフセットの構文:SelectColumn1、column2、... FromTable_nameLimitoffset、number_of_rows; offset:skip
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLプライマリキーは、データベース内の各行を一意に識別するキー属性であるため、空にすることはできません。主キーが空になる可能性がある場合、レコードを一意に識別することはできません。これにより、データの混乱が発生します。一次キーとして自己挿入整数列またはUUIDを使用する場合、効率やスペース占有などの要因を考慮し、適切なソリューションを選択する必要があります。
 MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
Hash値として保存されているため、Navicatを介してMongoDBパスワードを直接表示することは不可能です。紛失したパスワードを取得する方法:1。パスワードのリセット。 2。構成ファイルを確認します(ハッシュ値が含まれる場合があります)。 3.コードを確認します(パスワードをハードコードできます)。
 SQLで条項ごとに注文をマスターする:効果的にデータを並べ替える
Apr 08, 2025 pm 07:03 PM
SQLで条項ごとに注文をマスターする:効果的にデータを並べ替える
Apr 08, 2025 pm 07:03 PM
SQLORDERBY句の詳細な説明:Data OrderBY句の効率的なソートは、クエリ結果セットをソートするために使用されるSQLの重要なステートメントです。単一の列または複数の列で昇順(ASC)または下降順序(DESC)で配置でき、データの読みやすさと分析効率を大幅に改善できます。 Orderby Syntax SelectColumn1、column2、... fromTable_nameOrderByColumn_name [asc | desc]; column_name:列ごとに並べ替えます。 ASC:昇順の注文ソート(デフォルト)。 DESC:降順で並べ替えます。 Orderbyの主な機能:マルチコラムソート:複数の列のソートをサポートし、列の順序によりソートの優先度が決まります。以来
 MySQLにストアドプロシージャはありますか
Apr 08, 2025 pm 03:45 PM
MySQLにストアドプロシージャはありますか
Apr 08, 2025 pm 03:45 PM
MySQLは、複雑なロジックをカプセル化し、コードの再利用性とセキュリティを向上させる事前コンパイルされたSQLコードブロックであるストアドプロシージャを提供します。そのコア関数には、ループ、条件付きステートメント、カーソル、トランザクションコントロールが含まれます。ストアドプロシージャを呼び出すことにより、ユーザーは内部実装に注意を払うことなく、単に入力および出力するだけでデータベース操作を完了できます。ただし、構文エラー、許可の問題、ロジックエラーなどの一般的な問題に注意を払い、パフォーマンスの最適化とベストプラクティスの原則に従う必要があります。
