
 テクノロジー周辺機器
AI
Google AudioPaLM は、スピーキングとリスニングの両方に対応する大規模なモデルである「テキスト + オーディオ」デュアルモーダル ソリューションを実装しています。
テクノロジー周辺機器
AI
Google AudioPaLM は、スピーキングとリスニングの両方に対応する大規模なモデルである「テキスト + オーディオ」デュアルモーダル ソリューションを実装しています。
Google AudioPaLM は、スピーキングとリスニングの両方に対応する大規模なモデルである「テキスト + オーディオ」デュアルモーダル ソリューションを実装しています。

大規模言語モデルは、その強力なパフォーマンスと多用途性により、オーディオ、ビデオなどの多数のマルチモーダル大規模モデルの開発を推進してきました。
言語モデルの基礎となるアーキテクチャは、主に Transformer と主にデコーダに基づいているため、モデル アーキテクチャをあまり調整せずに他のシーケンス モダリティに適応できます。
最近、Google は統合音声テキスト モデル AudioPaLM をリリースしました。これは、テキストとオーディオ トークンをマルチモーダルな共同語彙にマージし、さまざまなタスク記述タグを組み合わせてデコーダーのトレーニングを実現します。 - 従来から使用される、音声認識 (ASR)、テキスト音声合成、自動音声翻訳 (AST)、音声音声翻訳 (S2ST) などを含む、音声とテキストの混合タスクに関する専用モデル異種混合モデルによって解決されるタスクは、アーキテクチャとトレーニング プロセスに統合されます。
 写真
写真
紙のリンク: https://arxiv.org/pdf/2306.12925.pdf
リンクの例: https://google-research.github.io/seanet/audiopalm/examples/
さらに、AudioPaLM の基礎となるアーキテクチャは大規模な Transformer モデルは、テキストで事前トレーニングされた大規模な言語モデルの重みを使用して初期化でき、PaLM などのモデルの言語知識の恩恵を受けることができます。
実装結果の観点から見ると、AudioPaLM は AST および S2ST ベンチマークで最先端の結果を達成しており、ASR ベンチマークでのパフォーマンスは他のモデルと同等です。
AudioLM のオーディオ キューを活用することで、AudioPaLM モデルは、新しい話者の音声移行に対して S2ST を実行でき、音声品質と音声保存の点で既存の方法を上回ります。
AudioPaLM モデルには、トレーニングでは見られない音声入力とターゲット言語の組み合わせに対して AST タスクを実行するゼロショット機能もあります。
AudioPaLM
研究者らは、デコーダ専用の Transformer モデルを使用してテキストと音声トークンをモデル化しました。テキストと音声はモデルに入力される前に処理されています。単語のセグメンテーション。そのため、入力は単なる整数のシーケンスであり、トークン化解除された操作が出力側で実行されてユーザーに返されます。
 #画像
#画像
音声埋め込みと単語分割
##元のオーディオ波形をトークンに変換するプロセスには、既存の音声表現モデルから埋め込みを抽出し、埋め込みを限られたオーディオ トークンのセットに離散化することが含まれます
前研究では、埋め込みが w2v-BERT モデルから抽出され、k-means によって量子化されました。この論文では、研究者は 3 つのソリューションを実験しました:
w2v-BERT: w2v-BERT を使用します。モデルは純粋な英語ではなく多言語データでトレーニングされ、K 平均法クラスタリングの前に正規化処理は実行されません。そうしないと、多言語環境が発生し、中程度のパフォーマンスが低下します。次に、語彙サイズ 1024
USM-v1 のレート 25Hz でトークンを生成します。より強力な 20 億パラメータのユニバーサル スピーチ モデル (USM) エンコーダを使用して、同様の操作を実行します。中間層から埋め込みを抽出;
USM-v2: 補助的な ASR 損失でトレーニングされ、多言語をサポートするためにさらに微調整されています。
テキスト専用デコーダの変更
Transfomrer デコーダ構造内で、以下を除く入力層と最後のソフトマックス出力層では、モデリング トークンの数は関与しません。PaLM アーキテクチャでは、入力行列と出力行列の重み変数が共有されます。つまり、それらは相互に転置されます。
したがって、純粋なテキスト モデルを両方のテキストをシミュレートできるモデルに変えるには、埋め込み行列のサイズを (t × m) から (t a) × m に拡張するだけで済みます。音声のモデル。t はテキスト語彙のサイズ、a は音声語彙のサイズ、m は埋め込み次元です。
事前トレーニングされたテキスト モデルを活用するために、研究者らは、埋め込み行列に新しい行を追加することで、既存のモデルのチェックポイントを変更しました。
具体的な実装では、最初の t トークンが SentencePiece テキスト タグに対応し、次の a トークンがオーディオ タグを表します。テキスト埋め込みでは事前トレーニングされた重みが再利用されますが、オーディオ埋め込みは新しく初期化されており、トレーニングする必要があります。
実験結果は、ゼロから再トレーニングする場合と比較して、テキストベースの事前トレーニング モデルが音声とテキストのマルチモーダル タスクのパフォーマンスを向上させるのに非常に有益であることを示しています。
オーディオ トークンをネイティブ オーディオにデコードします
オーディオ波形を合成するには研究者らはオーディオ トークンから 2 つの異なる方法をテストしました:
1. AudioLM モデルと同様の自己回帰デコード
2. SoundStorm モデル 非自己回帰デコーディング
両方の方法では、最初に SoundStream トークンを生成し、次に畳み込みデコーダーを使用してそれをオーディオ波形に変換する必要があります。
#研究者らは多言語 LibriSpeech でトレーニングしました。音声条件は 3 秒間の音声サンプルであり、音声トークンと SoundStream トークンとして同時に表現されました
元の入力音声の一部を音声条件として提供することにより、話者の音声を別の言語に翻訳する際に元の話者の音声を保存し、翻訳時に繰り返し再生することで空白時間を埋めることができます。元の音声は 3 秒未満です。
#トレーニング タスク
使用されるトレーニング データ セットは音声テキスト データです:1. オーディオ オーディオ: ソース言語での音声
2. トランスクリプト: 音声データ内の音声の文字起こし
3. 翻訳された音声: 音声内の音声の音声翻訳
##4. 翻訳されたトランスクリプト: 音声内の音声の書面による翻訳
コンポーネント タスクには次のものが含まれます:
1. ASR (自動音声認識): 音声を書き起こして、書き起こされたテキストを取得します
2. AST (自動音声翻訳): 音声を翻訳して、翻訳されたトランスクリプトを取得します。
#3. S2ST (音声間翻訳): 音声を翻訳して、翻訳されたトランスクリプトを取得します。 Audio
4. TTS (Text to Speech): 音声のトランスクリプトを読みます。
5. MT (テキストからテキストへの機械翻訳): 翻訳されたトランスクリプト テキストを取得するためのトランスクリプトの翻訳
データセットは、次の目的で使用される場合があります。複数のタスクがあるため、研究者らは、与えられた入力に対してどのタスクを実行するかをモデルに通知することを選択しました。具体的な方法は、入力の前にラベルを追加し、タスクの英語名と入力言語を指定し、出力言語を指定することもできます。選択されました。
たとえば、モデルでフランス語コーパスに対して ASR を実行する場合、TTS を実行するには、単語分割後の音声入力の前にラベル [ASR French] を追加する必要があります。英語のタスクの場合は、テキストの前にラベルを追加する必要があります [TTS 英語] を追加します。英語からフランス語への S2ST タスクを実行するには、セグメント化後の英語音声の前に [S2ST 英語 フランス語]
## が追加されます。トレーニング ミックス
##研究者らは SeqIO ライブラリを使用してトレーニング データをブレンドし、より大きなデータの重みを軽減しました。セット。
#写真
実験部分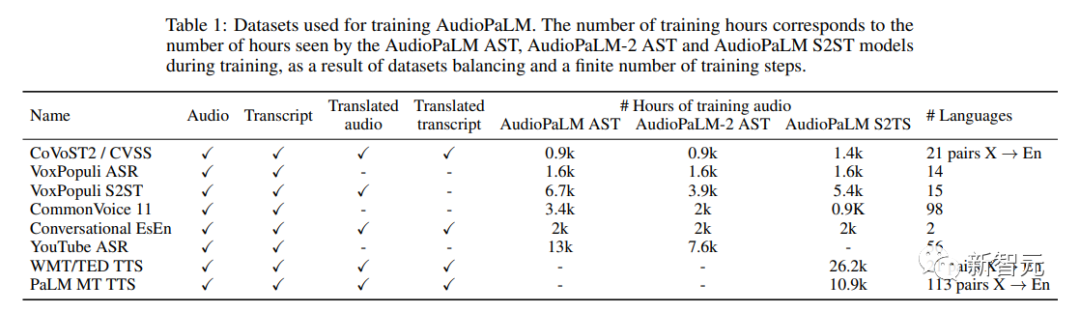 写真
写真
AudioPaLM は、AST および S2ST タスクで他のベースライン モデルを上回っており、ASR でのパフォーマンスは最適ではありませんが、効果も非常に優れています。 
客観的メトリクス
オーディオ サンプルを指定して、1 の間の非参照 MOS 推定器と同様のものを使用します。知覚されるオーディオ品質の推定値を 5 の範囲で提供します。
言語間での音声伝達の品質を測定するために、研究者らは既製の話者検証モデルを使用し、ソース (SoundStream でエンコード/デコード) と翻訳された音声の間のエンベディングを計算しました。コサイン類似度。ソース オーディオからターゲット オーディオまでの音響特性 (録音条件、バックグラウンド ノイズ) も測定します。主観的評価 研究者らは、生成された音声の品質と音声の類似性を評価するために 2 つの独立した研究を実施しました。サンプルセット。 コーパスの品質が不均一であるため、一部には、大音量で重複する音声 (たとえば、バックグラウンドで再生されているテレビ番組や歌) や、非常に強いノイズ (たとえば、衣服が擦れる音) が含まれています。マイクなど))、同様の歪み効果は人間の評価者の作業を複雑にするため、研究者らは、MOS 推定値が少なくとも 3.0 の入力のみを選択することでプレフィルタリングすることにしました。 評価は、1 (低品質、またはまったく異なるサウンド) から 5 (高品質、同じサウンド) の範囲の 5 段階スケールで提供されます。 結果から、AudioPaLM はオーディオに関して客観的測定と主観的測定の両方で優れたパフォーマンスを発揮していることがわかります。品質と音声の類似性: どちらもベースラインの Translatotron 2 システムよりも大幅に優れており、AudioPaLM は CVSS-T の実際の合成録音よりも高品質で音声の類似性が高く、ほとんどの指標で比較的大きな改善が見られます。 研究者らはまた、リソースの高いグループとリソースの少ないグループ (フランス語、ドイツ語、スペイン語、カタロニア語と他の言語) のシステムを比較し、これらのグループ間に有意な差がないことを発見しました。インジケーターで。 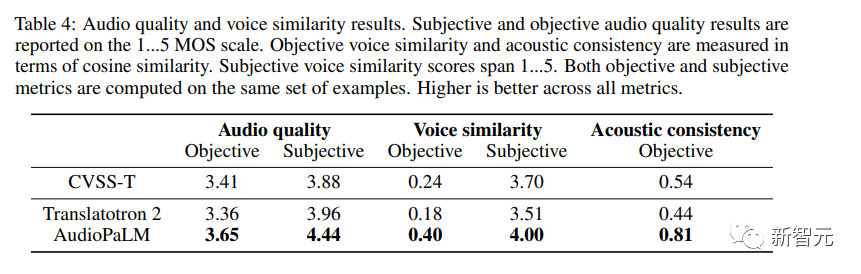 写真
写真
以上がGoogle AudioPaLM は、スピーキングとリスニングの両方に対応する大規模なモデルである「テキスト + オーディオ」デュアルモーダル ソリューションを実装しています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7662
7662
 15
1393
52
1205
24
91
11
15
1393
52
1205
24
91
11

 セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
この記事では、SESAME Open Exchange(gate.io)Webバージョンの登録プロセスとGate Tradingアプリを詳細に紹介します。 Web登録であろうとアプリの登録であろうと、公式Webサイトまたはアプリストアにアクセスして、本物のアプリをダウンロードし、ユーザー名、パスワード、電子メール、携帯電話番号、その他の情報を入力し、電子メールまたは携帯電話の確認を完了する必要があります。
 Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか? BYBITは、ユーザーにトレーディングサービスを提供する暗号通貨交換です。 Exchangeのモバイルアプリは、次の理由でAppStoreまたはGooglePlayを介して直接ダウンロードすることはできません。1。AppStoreポリシーは、AppleとGoogleがApp Storeで許可されているアプリケーションの種類について厳しい要件を持つことを制限しています。暗号通貨交換アプリケーションは、金融サービスを含み、特定の規制とセキュリティ基準を必要とするため、これらの要件を満たしていないことがよくあります。 2。法律と規制のコンプライアンス多くの国では、暗号通貨取引に関連する活動が規制または制限されています。これらの規制を遵守するために、BYBITアプリケーションは公式Webサイトまたはその他の認定チャネルを通じてのみ使用できます
 セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
ログインステップやパスワード回復プロセスなど、セサミオープンエクスチェンジWebバージョンのログイン操作の詳細な紹介も、ログイン障害、ページを開くことができず、プラットフォームにスムーズにログインするのに役立つ検証コードを受信できません。
 セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
アプリをダウンロードしてアカウントの安全を確保するために、正式なチャネルを選択することが重要です。
 Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
この記事では、Binance、Okx、Gate.io、Bitflyer、Kucoin、Bybit、Coinbase Pro、Kraken、Bydfi、Xbit分散化された交換など、注意を払う価値のある上位10の暗号通貨取引プラットフォームを推奨しています。これらのプラットフォームには、トランザクションの数量、トランザクションの種類、セキュリティ、コンプライアンス、特別な機能の点で独自の利点があります。適切なプラットフォームを選択するには、あなた自身の取引体験、リスク許容度、投資の好みに基づいて包括的な検討が必要です。 この記事があなたがあなた自身に最適なスーツを見つけるのに役立つことを願っています
 Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Webサイトログインポータルの最新バージョンにアクセスするには、これらの簡単な手順に従ってください。公式ウェブサイトに移動し、右上隅の[ログイン]ボタンをクリックします。既存のログインメソッドを選択してください。「登録」してください。登録済みの携帯電話番号または電子メールとパスワードを入力し、認証を完了します(モバイル検証コードやGoogle Authenticatorなど)。検証が成功した後、Binance公式WebサイトLogin Portalの最新バージョンにアクセスできます。
 ビットゲット取引プラットフォーム公式アプリのダウンロードとインストールアドレス
Feb 25, 2025 pm 02:42 PM
ビットゲット取引プラットフォーム公式アプリのダウンロードとインストールアドレス
Feb 25, 2025 pm 02:42 PM
このガイドは、AndroidおよびiOSシステムに適した公式Bitget Exchangeアプリの詳細なダウンロードとインストール手順を提供します。このガイドは、公式ウェブサイト、App Store、Google Playなど、複数の権威ある情報源からの情報を統合し、ダウンロードおよびアカウント管理中の考慮事項を強調しています。ユーザーは、App Store、公式WebサイトAPKダウンロード、公式Webサイトジャンプ、完全な登録、ID検証、セキュリティ設定など、公式チャネルからアプリをダウンロードできます。さらに、ガイドはよくある質問や考慮事項をカバーします。
 2025年のBitgetの最新のダウンロードアドレス:公式アプリを取得する手順
Feb 25, 2025 pm 02:54 PM
2025年のBitgetの最新のダウンロードアドレス:公式アプリを取得する手順
Feb 25, 2025 pm 02:54 PM
このガイドは、AndroidおよびiOSシステムに適した公式Bitget Exchangeアプリの詳細なダウンロードとインストール手順を提供します。このガイドは、公式ウェブサイト、App Store、Google Playなど、複数の権威ある情報源からの情報を統合し、ダウンロードおよびアカウント管理中の考慮事項を強調しています。ユーザーは、App Store、公式WebサイトAPKダウンロード、公式Webサイトジャンプ、完全な登録、ID検証、セキュリティ設定など、公式チャネルからアプリをダウンロードできます。さらに、ガイドはよくある質問や考慮事項をカバーします。
