

Tian Yuandong チームによる新しい研究: 1000 ステップ未満の微調整、LLaMA コンテキストを 32K まで拡張

誰もが独自の大規模モデルのアップグレードと反復を続けるにつれて、コンテキスト ウィンドウを処理する LLM (大規模言語モデル) の能力も重要な評価指標になりました。
たとえば、OpenAI の gpt-3.5-turbo は 16,000 トークンのコンテキスト ウィンドウ オプションを提供し、AnthropicAI は Claude のトークン処理能力を 100,000 に増加しました。大規模なモデル処理コンテキスト ウィンドウの概念は何ですか? たとえば、GPT-4 は 32,000 のトークンをサポートします。これは 50 ページのテキストに相当します。つまり、GPT-4 は会話または生成するときに最大約 50 ページのコンテンツを記憶できます。文章。
一般的に、大規模な言語モデルがコンテキスト ウィンドウのサイズを処理できるかどうかは、あらかじめ決まっています。たとえば、Meta AI によってリリースされた LLaMA モデルの場合、その入力トークン サイズは 2048 未満である必要があります。
ただし、長い会話を行ったり、長い文書を要約したり、長期計画を実行したりするようなアプリケーションでは、事前に設定されたコンテキスト ウィンドウの制限を超えることがよくあるため、これ以上長い時間を処理することは困難です。コンテキスト ウィンドウ。LLM の方が一般的です。
しかし、これには新たな問題があり、長いコンテキスト ウィンドウを使用して LLM を最初からトレーニングするには多大な投資が必要です。これは当然、既存の事前トレーニング済み LLM のコンテキスト ウィンドウを拡張できるか?という疑問につながります。
単純なアプローチは、既存の事前トレーニング済み Transformer を微調整して、より長いコンテキスト ウィンドウを取得することです。ただし、経験的な結果は、この方法でトレーニングされたモデルが長いコンテキスト ウィンドウに適応するのが非常に遅いことを示しています。 10000 回のトレーニング バッチの後でも、有効コンテキスト ウィンドウの増加は依然として非常に小さく、2048 年から 2560 年までの期間のみです (実験セクションの表 4 に見られるように)。これは、このアプローチがより長いコンテキスト ウィンドウへのスケーリングにおいて非効率であることを示唆しています。
この記事では、Meta の研究者が 位置補間 (PI) を既存の事前トレーニング済み LLM (LLaMA を含む) に導入しました。コンテキスト ウィンドウが展開されます。結果は、LLaMA コンテキスト ウィンドウを 2k から 32k にスケーリングするのに必要な微調整ステップは 1000 ステップ未満であることを示しています。
 写真
写真
論文アドレス: https://arxiv.org/pdf/2306.15595.pdf
この研究の重要なアイデアは、外挿を実行することではなく、最大位置インデックスが事前トレーニング段階のコンテキスト ウィンドウの制限と一致するように位置インデックスを直接減らすことです。言い換えれば、より多くの入力トークンに対応するために、この研究では、トレーニングされた位置を超えて外挿するのではなく、位置エンコーディングが非整数位置に適用できるという事実を利用して、隣接する整数位置で位置エンコーディングを内挿します。後者は壊滅的な価値をもたらす可能性があります。
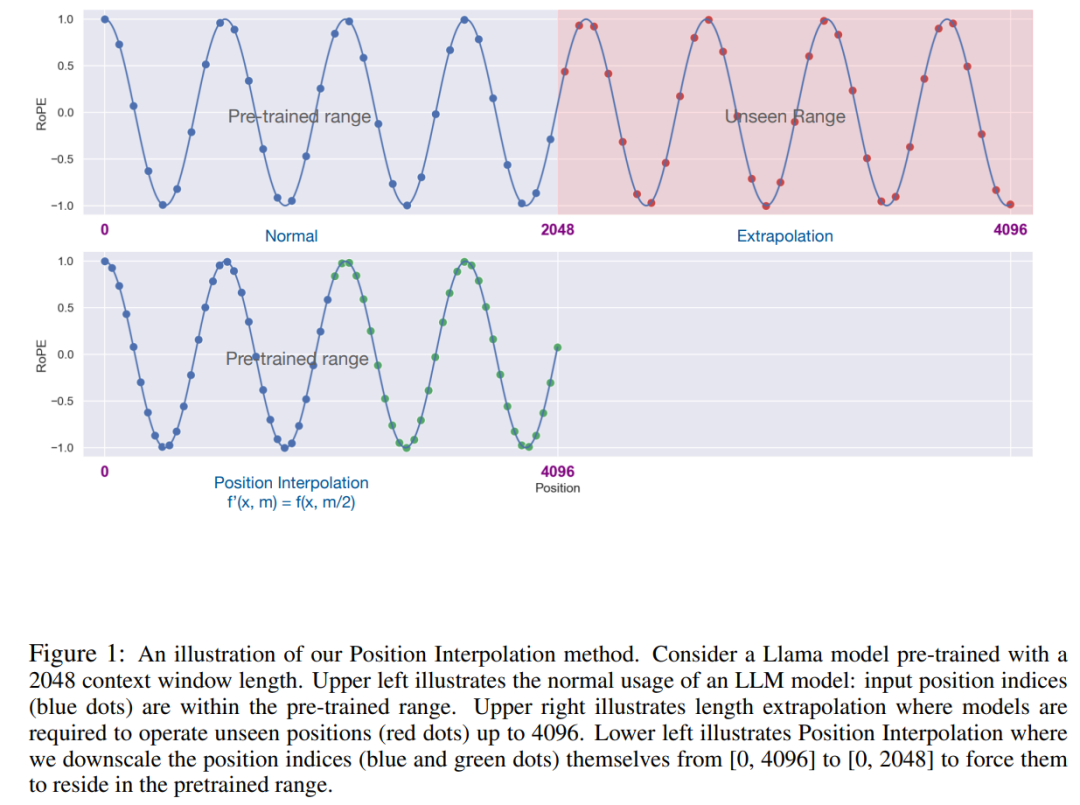
PI メソッドは、RoPE (回転位置) に基づいて、事前トレーニングされた LLM (LLaMA など) のコンテキスト ウィンドウ サイズを拡張します。この研究では、最小限の微調整 (1000 ステップ以内) で最大 32768 まで、検索、言語モデリング、LLaMA 7B から 65B までの長い文書の要約など、長いコンテキストを必要とするさまざまなタスクでパフォーマンスの向上が達成されています。同時に、PI によって拡張されたモデルは、元のコンテキスト ウィンドウ内で比較的良好な品質を維持します。
メソッド
RoPE は、私たちがよく知っている LLaMA、ChatGLM-6B、PaLM などの大規模な言語モデルに存在します。 Zhuiyi Technology の Su Jianlin 氏らによって提案された RoPE は、絶対エンコーディングによる相対位置エンコーディングを実装します。
RoPE の注意スコアは相対位置にのみ依存しますが、外挿パフォーマンスは良好ではありません。特に、より大きなコンテキスト ウィンドウに直接スケーリングする場合、混乱が非常に高い数値 (つまり、> 10^3) に達する可能性があります。
この記事では位置補間法を使用していますが、外挿法との比較は次のとおりです。基底関数 ϕ_j が滑らかであるため、内挿はより安定しており、外れ値が発生しません。
#写真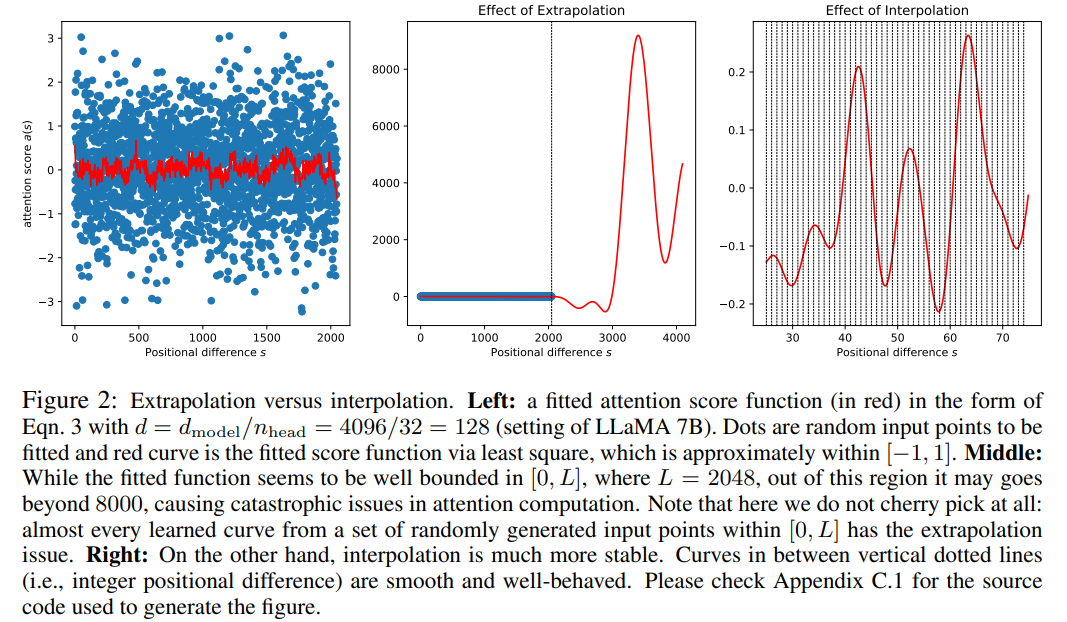
# ##### ######写真######
この研究では、位置エンコーディングの変換を位置補間と呼びます。このステップでは、RoPE を計算する前に、位置インデックスを [0, L' ) から [0, L) に減らして、元のインデックス範囲と一致させます。したがって、RoPE への入力として、任意の 2 つのトークン間の最大相対距離は L ' から L に減少しました。拡張前後で位置インデックスと相対距離の範囲を調整することで、コンテキスト ウィンドウの拡張による注意スコアの計算への影響が軽減され、モデルの適応が容易になります。
位置インデックスの再スケーリング方法では、追加の重みが導入されず、モデル アーキテクチャがまったく変更されないことは注目に値します。
実験
この研究は、位置補間によってコンテキスト ウィンドウを元のサイズの 32 倍に効果的に拡張できること、およびこの拡張だけが効果的であることを実証します。完了するには何百ものトレーニング ステップが必要です。
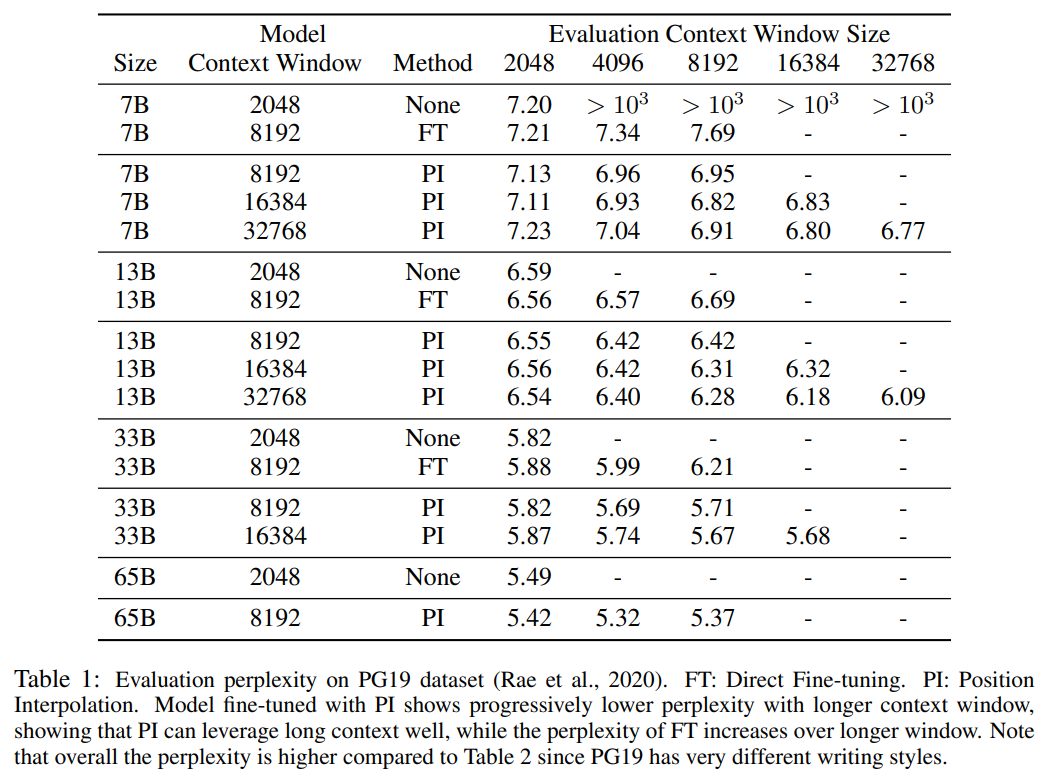
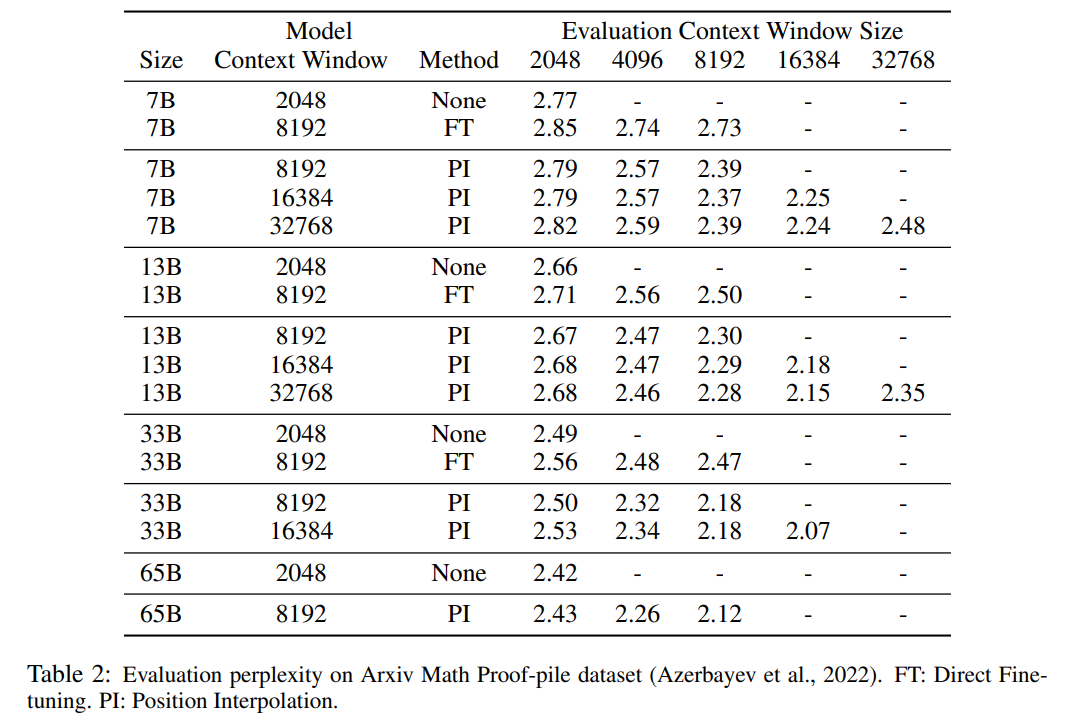
表 1 と表 2 は、PG-19 および Arxiv Math Proof-pile データ セットにおける PI モデルとベースライン モデルの複雑さを報告します。結果は、PI 法を使用して拡張されたモデルが、より長いコンテキスト ウィンドウ サイズでの混乱を大幅に改善することを示しています。
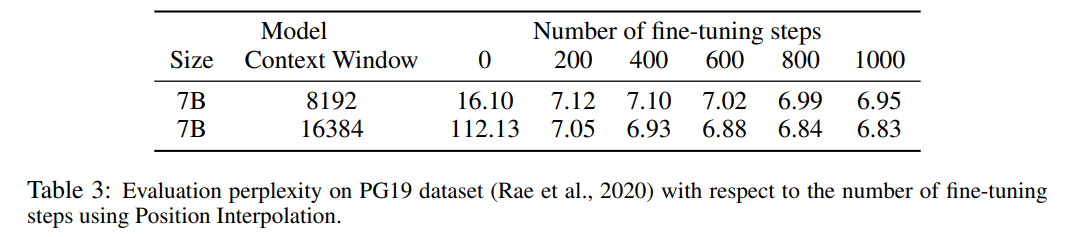
#表 3 は、PG19 データセットの PI メソッドを使用した LLaMA 7B モデルの 8192 への拡張を報告します。 16384 は、コンテキスト ウィンドウ サイズが大きい場合のパープレキシティと微調整ステップ数の関係です。
結果から、微調整なし (ステップ数は 0) で、コンテキスト ウィンドウが展開されたときなど、モデルが特定の言語モデリング機能を示すことができることがわかります。 to 8192 パープレキシティは 20 未満です (直接外挿法の場合は 10^3 を超えます)。 200 ステップでは、モデルの複雑度はコンテキスト ウィンドウ サイズ 2048 の元のモデルの複雑度を超えており、このモデルが事前トレーニングされた設定よりも長いシーケンスを言語モデリングに効果的に利用できることを示しています。 1000 ステップでは、モデルが着実に改善され、より優れた複雑性が達成されることがわかります。
 図
図
次の表は、PI によって拡張されたモデルが、有効なコンテキスト ウィンドウ サイズの点でスケーリング目標を正常に達成していることを示しています。つまり、わずか 200 ステップの微調整の後、有効コンテキスト ウィンドウ サイズは最大値に達し、7B および 33B のモデル サイズおよび最大 32768 コンテキスト ウィンドウで一貫性が保たれます。対照的に、直接微調整によってのみ拡張された LLaMA モデルの有効コンテキスト ウィンドウ サイズは 2048 から 2560 に増加するだけであり、10000 ステップを超える微調整の後でもウィンドウ サイズが大幅に加速される兆候はありませんでした。
#図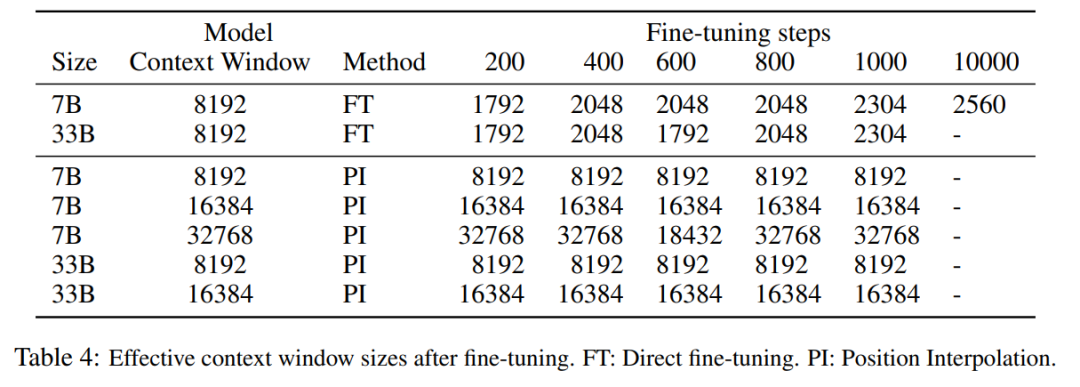
図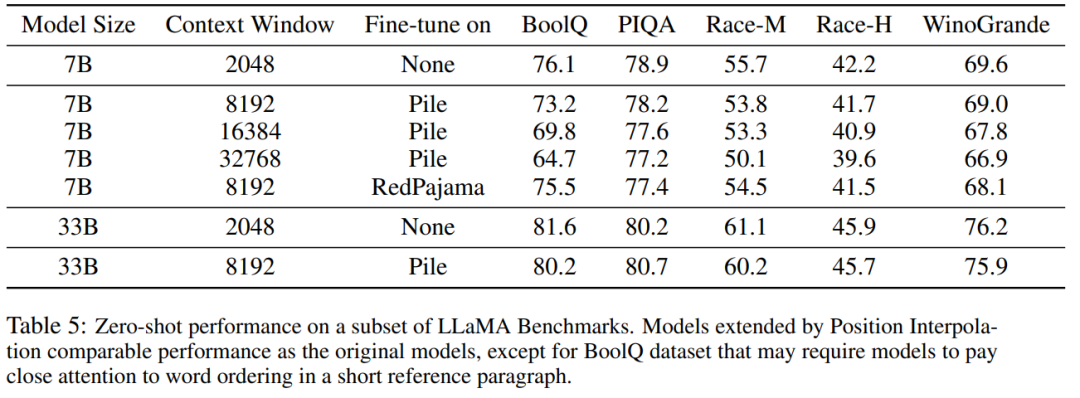
以上がTian Yuandong チームによる新しい研究: 1000 ステップ未満の微調整、LLaMA コンテキストを 32K まで拡張の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7552
7552
 15
1382
52
83
11
22
95
15
1382
52
83
11
22
95

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 新しい手頃な価格の Meta Quest 3S VR ヘッドセットが FCC に登場、発売が近いことを示唆
Sep 04, 2024 am 06:51 AM
新しい手頃な価格の Meta Quest 3S VR ヘッドセットが FCC に登場、発売が近いことを示唆
Sep 04, 2024 am 06:51 AM
Meta Connect 2024イベントは9月25日から26日に予定されており、このイベントで同社は新しい手頃な価格の仮想現実ヘッドセットを発表すると予想されている。 Meta Quest 3S であると噂されている VR ヘッドセットが FCC のリストに掲載されたようです。この提案
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
