

Transformer BEV を使用して自動運転の極限状況を克服するにはどうすればよいですか?

自動運転システムは、実際のアプリケーションにおいて、さまざまな複雑なシナリオ、特に自動運転の認識能力と意思決定能力に高い要件が課されるコーナーケース (極端な状況) に直面する必要があります。コーナーケースとは、交通事故、悪天候、複雑な道路状況など、実際の運転中に発生する可能性のある極端またはまれな状況を指します。 BEV テクノロジーは、グローバルな視点を提供することで自動運転システムの認識能力を強化し、これらの極端な状況に対処する際により優れたサポートを提供すると期待されています。この記事では、BEV (Bird's Eye View) テクノロジーが自動運転システムがコーナーケースに対処し、システムの信頼性と安全性を向上させるのにどのように役立つかを検討します。
 写真
写真
Transformer は、自己注意メカニズムに基づく深層学習モデルであり、自然言語処理タスクで最初に使用されました。 . .中心となるアイデアは、セルフ アテンション メカニズムを通じて入力シーケンス内の長距離依存関係をキャプチャし、それによってシーケンス データを処理するモデルの能力を向上させることです。
上記 2 つの効果的な組み合わせも、自動運転戦略において非常に人気のある新興テクノロジーです。
01 BEV 技術優位性分析
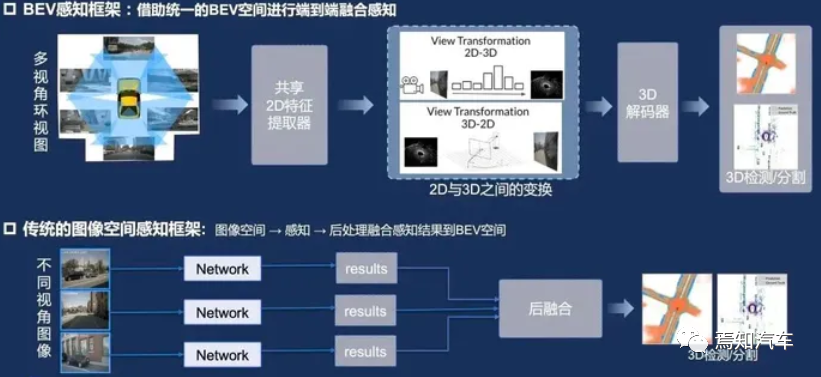
BEV は、3 次元の環境情報を 2 次元平面に投影し、それを表示する手法です。トップダウンの視点 環境内のオブジェクトと地形。自動運転の分野では、BEV はシステムが周囲の環境をよりよく理解し、認識と意思決定の精度を向上させるのに役立ちます。環境認識段階では、BEV はライダー、レーダー、カメラなどのマルチモーダル データを同じ平面上で融合できます。この方法により、データ間のオクルージョンやオーバーラップの問題が解消され、オブジェクトの検出と追跡の精度が向上します。同時に、BEV は、後続の予測および意思決定段階のための環境を明確に表現できるため、システム全体のパフォーマンスを向上させるのに役立ちます。
1. LiDAR と BEV テクノロジーの比較:
まず第一に、BEV テクノロジーは環境認識のグローバルな視点を提供し、複雑なシナリオにおける自動運転システムのパフォーマンスを向上させます。ただし、距離と空間情報の点では LIDAR の方が高い精度を持っています。
第二に、BEV テクノロジーはカメラを通じて画像をキャプチャし、色とテクスチャの情報を取得できますが、この点における LIDAR のパフォーマンスは弱いです。
さらに、BEV テクノロジーのコストは比較的低く、大規模な商業展開に適しています。
2. BEV テクノロジーと従来のシングルビュー カメラの比較
従来のシングルビュー カメラは、一般的に使用されている車両センシング デバイスです。車両周囲の環境情報を取得できます。ただし、単視点カメラには視野と情報取得に関して一定の制限があります。 BEV テクノロジーは、複数のカメラからの画像を統合して、グローバルな視点と車両周囲の環境のより包括的な理解を提供します。
 写真
写真
BEV テクノロジーは、複雑なシーンや厳しい気象条件において、単視点カメラと比較して優れた環境認識能力を備えています。 BEV はさまざまな角度からの画像情報を融合できるため、システムによる環境の認識が向上します。
BEV テクノロジーは、自動運転システムが複雑な道路状況、狭い道路や封鎖された道路などの特殊な状況にうまく対処できるようにするのに役立ちますが、このような状況では単視点カメラがうまく機能しない可能性があります。 。
もちろん、コストとリソース使用量の観点から、BEV はさまざまな視野角からの画像認識、再構成、結合を必要とするため、より多くのコンピューティング パワーとストレージ リソースを消費します。 BEV テクノロジーには複数のカメラの導入が必要ですが、全体的なコストは依然として LIDAR よりも低く、そのパフォーマンスはシングルビュー カメラと比較して大幅に向上しています。
要約すると、BEV テクノロジーには、自動運転分野における他の認識テクノロジーと比較して、一定の利点があります。特にコーナーケースの処理に関しては、BEV テクノロジーは環境認識のグローバルな視点を提供し、複雑なシナリオにおける自動運転システムのパフォーマンスの向上に役立ちます。しかし、BEV技術の利点を最大限に活かすためには、画像処理能力やセンサーフュージョン技術、異常挙動予測などの性能向上のため、さらなる研究開発が必要です。同時に、他の認識技術 (LIDAR など) やディープラーニング、機械学習アルゴリズムと組み合わせることで、さまざまなシナリオにおける自動運転システムの安定性と安全性をさらに向上させることができます。
02 変圧器とBEVによる自動運転システム
同時に、Bird's Eye View (BEV)が効果的な環境認識として機能します自動運転システムでは方法が重要な役割を果たします。 Transformer と BEV の利点を組み合わせることで、高精度の認識、予測、意思決定を実現するエンドツーエンドの自動運転システムを構築できます。この記事では、変圧器と BEV を効果的に組み合わせて自動運転の分野に適用してシステムのパフォーマンスを向上させる方法についても検討します。
具体的な手順は次のとおりです:
1. データの前処理:
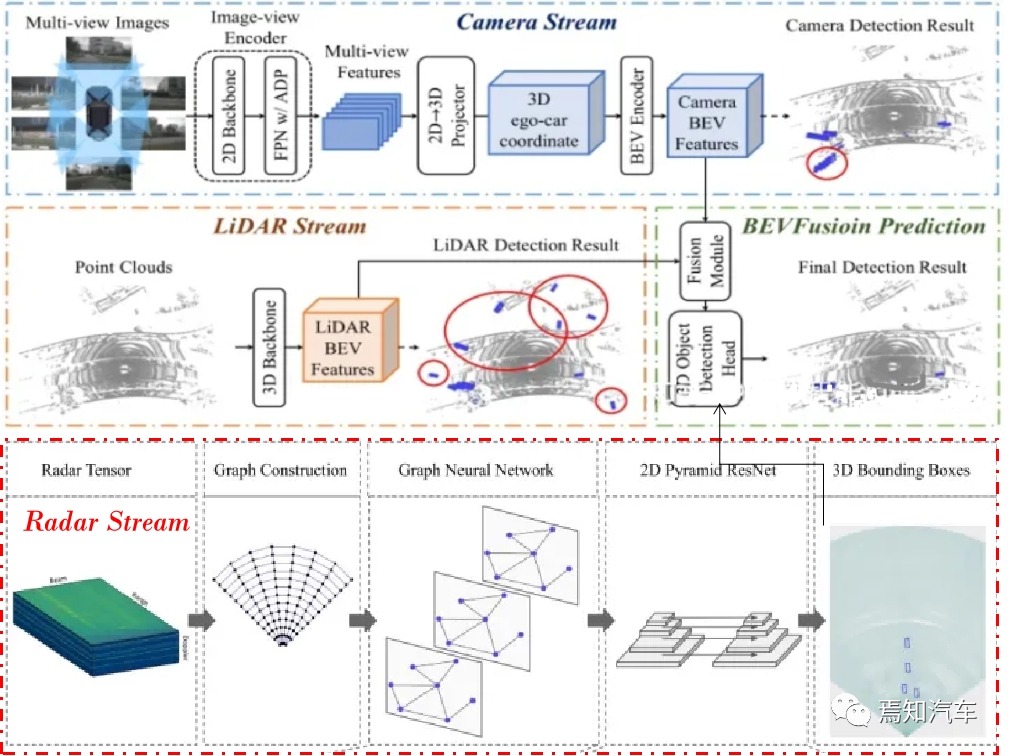
LIDAR を結合します。 , レーダーやカメラなどのマルチモーダルデータがBEVフォーマットに融合され、データ強調や正規化など必要な前処理操作が行われます。
まず、LIDAR、レーダー、カメラなどのマルチモーダル データを BEV 形式に変換する必要があります。 LIDAR 点群データの場合は、3 次元の点群を 2 次元平面に投影し、その平面をラスタライズして高さマップを生成できます。レーダー データの場合は、距離と角度の情報を高さマップに変換できます。次に、カール座標は BEV 平面上でラスター化され、カメラ データの場合は、画像データを BEV 平面に投影して、カラーまたは強度マップを生成できます。
 写真
写真
2. 知覚モジュール:
自動運転段階での知覚、Transformer モデルを使用して、LIDAR 点群、画像、レーダー データなどのマルチモーダル データの特徴を抽出できます。これらのデータに対してエンドツーエンドのトレーニングを実施することで、Transformer はこれらのデータの本質的な構造と相互関係を自動的に学習し、環境内の障害物を効果的に特定して位置を特定できます。
Transformer モデルを使用して BEV データから特徴を抽出し、障害物を検出して位置を特定します。
これらの BEV フォーマット データを重ね合わせて、マルチ チャネル BEV 画像を形成します。ライダーの BEV 高さマップを H(x, y)、レーダーの BEV 距離マップを R(x, y)、カメラの BEV 強度マップを I(x, y) とすると、マルチチャンネル BEV 画像は次のように表すことができます:
##B(x, y) = [H(x, y), R(x, y), I(x, y)]
ここで、B(x, y) は座標 (x, y) におけるマルチチャネル BEV 画像のピクセル値を表し、[] はチャネルの重ね合わせを表します。
3. 予測モジュール:
認識モジュールの出力に基づいて、Transformer モデルを使用して、将来の動作と軌道を予測します。他の交通参加者。 Transformer は、過去の軌跡データを学習することで、交通参加者の移動パターンや相互作用を捕捉できるため、自動運転システムに対してより正確な予測を提供できます。
具体的には、まず Transformer を使用してマルチチャネル BEV 画像から特徴を抽出します。入力 BEV 画像が B(x, y) であると仮定すると、多層セルフ アテンション メカニズムと位置エンコーディングを通じて特徴 F(x, y) を抽出できます。 x, y) = Transformer(B(x, y))
ここで、F(x, y) は特徴マップ、つまり座標 (x, y) での特徴値を表します。
次に、抽出された特徴 F(x, y) を使用して、他の交通参加者の行動と軌跡を予測します。 Transformer のデコーダを使用して、次のように予測結果を生成できます。
P(t) = Decoder(F(x, y), t)
# ここで、P(t) は時間 t における予測結果を表し、Decoder は Transformer デコーダを表します。上記の手順により、Transformer と BEV に基づいたデータの融合と予測を実現できます。特定の Transformer の構造とパラメータ設定は、実際のアプリケーション シナリオに応じて調整して、最適なパフォーマンスを実現できます。
4. 意思決定モジュール:
予測モジュールの結果に基づいて、交通ルールや車両ダイナミクス モデルと組み合わせて、変圧器モデルは、適切な運転戦略を生成するために使用されます。 ###############写真######
環境情報、交通ルール、車両ダイナミクスモデルをモデルに統合することで、Transformer は効率的で安全な運転戦略を学習できます。経路計画、速度計画など。さらに、Transformer のマルチヘッド セルフ アテンション メカニズムを使用すると、異なる情報ソース間の重みを効果的にバランスさせて、複雑な環境でより合理的な意思決定を行うことができます。
#この方法を採用するための具体的な手順は次のとおりです:
1. データの収集と前処理:
まず、車両の状態情報(速度、加速度、ハンドル角度など)、道路状況情報(道路の種類、交通標識、道路状況など)を含む大量の走行データを収集する必要があります。車線など)、周囲の環境情報(他車両、歩行者、自転車など)、ドライバーの行動。これらのデータは、データ クリーニング、標準化、特徴抽出などの前処理が行われます。
2. データのエンコードとシリアル化:
収集したデータを、Transformer モデルの入力に適した形式にエンコードします。これには通常、連続数値データを離散化し、離散化されたデータをベクトル形式に変換することが含まれます。同時に、Transformer モデルがタイミング情報を処理できるように、データをシリアル化する必要があります。
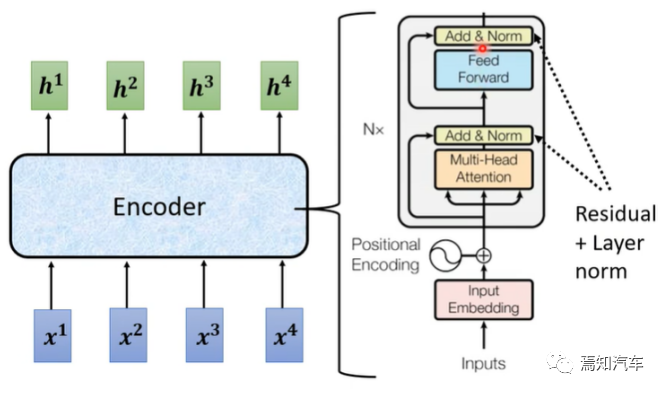
2.1. トランスフォーマー エンコーダー
トランスフォーマー エンコーダーは、複数の同一のサブレイヤーで構成されます。部分: マルチヘッド アテンションとフィードフォワード ニューラル ネットワーク。
マルチヘッドセルフアテンション: まず入力シーケンスを h 個の異なるヘッドに分割し、各ヘッドのセルフアテンションを個別に計算してから、これらのヘッドの出力をつなぎ合わせます。これにより、入力シーケンス内のさまざまなスケールで依存関係がキャプチャされます。
 写真
写真
雄牛の自己注意力の計算式は次のとおりです:
MHA (X) = Concat(head_1, head_2, ..., head_h) * W_O
ここで、MHA(X) はマルチヘッドセルフアテンションの出力を表し、head_i はi 番目の head の出力、W_O は出力重み行列です。
フィードフォワード ニューラル ネットワーク: 次に、多頭自己注意の出力がフィードフォワード ニューラル ネットワークに渡されます。フィードフォワード ニューラル ネットワークには、通常、完全に接続された 2 つの層と 1 つの活性化関数 (ReLU など) が含まれています。フィードフォワード ニューラル ネットワークの計算式は次のとおりです:
FFN(x) = max(0, xW_1 b_1) * W_2 b_2
ここでFFN (x) はフィードフォワード ニューラル ネットワークの出力を表し、W_1 と W_2 は重み行列、b_1 と b_2 はバイアス ベクトル、max(0, x) は ReLU 活性化関数を表します。
さらに、エンコーダーの各サブレイヤーには、残留接続とレイヤー正規化 (レイヤー正規化) が含まれており、これはモデルのトレーニングの安定性と収束速度の向上に役立ちます。
2.2. Transformer デコーダー
エンコーダーと同様に、Transformer デコーダーも同じレイヤーの複数の層で構成されています。各サブ層は、マルチヘッド セルフ アテンション、エンコーダ デコーダ アテンション (Encoder-Decoder Attender アテンション)、およびフィードフォワード ニューラル ネットワークの 3 つの部分で構成されます。
マルチヘッド セルフ アテンション: エンコーダのマルチヘッド セルフ アテンションと同じで、デコーダ入力シーケンス内の各要素間の相関度を計算するために使用されます。
エンコーダ-デコーダ アテンション: デコーダ入力シーケンスとエンコーダ出力シーケンスの間の相関度を計算するために使用されます。計算方法はセルフ アテンションと似ていますが、クエリ ベクトルがデコーダの入力シーケンスから取得され、キー ベクトルと値ベクトルがエンコーダの出力シーケンスから取得される点が異なります。
フィードフォワード ニューラル ネットワーク: エンコーダーのフィードフォワード ニューラル ネットワークと同じです。デコーダの各サブレイヤには、残留接続とレイヤの正規化も含まれます。エンコーダーとデコーダーの複数のレイヤーを積み重ねることにより、Transformer は複雑な依存関係を持つシーケンス データを処理できるようになります。
3. Transformer モデルの構築:
適切な層とヘッドの数の設定を含む、自動運転シナリオに適した Transformer モデルを構築します。 . と隠れ層のサイズ。さらに、駆動ポリシーを使用してタスクの損失関数を生成するなど、タスクの要件に応じてモデルを微調整する必要もあります。
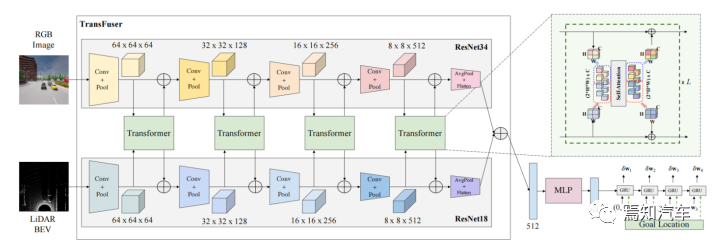
まず、MLP によって特徴ベクトルを取得して低次元ベクトルを取得します。このベクトルは、GRU によって実装された自動回帰パス ポイント ネットワークに渡され、GRU の隠れ状態の初期化に使用されます。さらに、現在位置と目標位置も入力されるため、ネットワークは隠れた状態の関連コンテキストに焦点を当てます。
 #図
#図
単層 GRU を使用し、線形層を使用して隠れ状態からのパス ポイント オフセットを予測します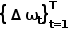 、予測されたパス ポイント
、予測されたパス ポイント 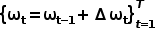 を取得します。 GRU への入力が原点です。
を取得します。 GRU への入力が原点です。
コントローラーは 2 つの PID コントローラーを使用して、予測された経路点に基づいてそれぞれ水平方向と前後方向の制御を実行し、ステアリング、ブレーキ、スロットルの値を取得します。連続するフレームのパス ポイント ベクトルの加重平均を実行すると、縦方向コントローラーの入力はそのモジュール長になり、横方向コントローラーの入力はその方向になります。
現在のフレームの自車座標系におけるエキスパート軌道経路点と予測軌道経路点の L1 損失、つまり
# を計算します。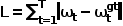
収集したデータ セットを使用して、Transformer モデルをトレーニングします。トレーニング プロセス中に、モデルを検証して一般化能力を確認する必要があります。データ セットは、モデルを評価するためにトレーニング セット、検証セット、テスト セットに分割できます。
5. 運転戦略の生成:
実際のアプリケーションでは、現在の車両状態、道路状況情報に基づいて事前学習データが入力されます。および周囲の環境情報 変圧器のモデル。モデルは、これらの入力に基づいて、加速、減速、ステアリングなどの運転戦略を生成します。
6. 運転戦略の実行と最適化:
生成された運転戦略を自動運転システムに渡し、車両を制御します。同時に、モデルのさらなる最適化と反復のために、実際の実行プロセスからのデータが収集されます。
上記の手順により、Transformer モデルに基づく手法を使用して、自動運転の意思決定段階で適切な運転戦略を生成できます。なお、自動運転分野では高い安全性が要求されるため、実際の導入時にはさまざまなシナリオでモデルの性能と安全性を確保する必要がある。
03 コーナーケースを解決する変圧器 BEV 技術の事例
このセクションでは、コーナーケースを解決する BEV 技術の 3 つの事例を詳しく紹介します例には、複雑な道路状況、厳しい気象条件、異常な動作の予測などが含まれます。次の図は、自動運転におけるいくつかの例外的なシナリオを示しています。 Transformer BEV のテクノロジーは、現在識別できるほとんどのエッジ シーンを効果的に識別して処理できます。
写真
複雑な道路状況で交通渋滞、複雑な交差点、不規則な路面などの状況下で、Transformer BEV テクノロジーはより包括的な環境認識を提供できます。車両周囲の複数のカメラからの画像を統合することにより、BEV は連続的な俯瞰ビューを生成し、自動運転システムが車線境界線、障害物、歩行者、その他の交通参加者を明確に識別できるようにします。たとえば、複雑な交差点では、BEV テクノロジーを利用して自動運転システムが各交通参加者の位置と進行方向を正確に識別できるようになり、それによって経路計画と意思決定の信頼できる基盤が提供されます。
2. 悪天候への対処
雨、雪、霧などの悪天候では、従来のカメラとLIDAR 自動運転システムの感知能力に影響を及ぼし、低下する可能性があります。変圧器 BEV テクノロジーは、さまざまな角度からの画像情報を融合できるため、このような状況でも一定の利点を持っており、それによってシステムの環境認識が向上します。厳しい気象条件下で Transformer BEV テクノロジーのパフォーマンスをさらに強化するには、このような状況での可視光カメラの欠点を補うために、赤外線カメラや熱画像カメラなどの補助機器の使用を検討できます。
実際の道路環境では、歩行者や自転車などの交通参加者が突然道路を横断したり、交通違反をしたりするなどの異常行動を起こす可能性があります。ルールなどBEV テクノロジーは、自動運転システムがこうした異常な動作をより適切に予測できるように支援します。 BEV は世界的な視野で完全な環境情報を提供できるため、自動運転システムが歩行者やその他の交通参加者の動態をより正確に追跡および予測できるようになります。さらに、Transformer BEV テクノロジーは、機械学習と深層学習アルゴリズムを組み合わせることで、異常動作の予測精度をさらに向上させ、自動運転システムが複雑なシナリオでより合理的な意思決定を行えるようにします。 狭いまたは封鎖された道路環境では、従来のカメラや LIDAR では効果的な環境を実現するための適切な情報を取得することが困難になる場合があります。感知。ただし、Transformer BEV テクノロジーは、複数のカメラでキャプチャされた画像を統合して、より包括的なビューを生成できるため、このような状況で活躍します。これにより、自動運転システムは車両の周囲の環境をより深く理解し、狭い通路の障害物を特定し、これらのシナリオを安全にナビゲートできるようになります。 高速道路などのシナリオでは、自動運転システムは車両の合流や交通の合流などの複雑さに対処する必要があります。トラフィックのマージ。タスク。システムは安全な合流と交通合流を確保するために周囲の車両の位置と速度をリアルタイムで評価する必要があるため、これらのタスクでは自動運転システムの認識能力に高い要求が課せられます。 Transformer BEV テクノロジーを使用すると、自動運転システムはグローバルな視点を獲得し、車両周囲の交通状況を明確に理解できるようになります。これは、自動運転システムが適切な合流戦略を開発し、車両が交通の流れに安全に統合できるようにするのに役立ちます。 交通事故、通行止め、緊急事態などの緊急事態においては、自動運転システムの高速性が求められます。安全な運転を確保するための決定を下します。このような場合、Transformer BEV テクノロジーは自動運転システムにリアルタイムで包括的な環境認識を提供し、システムが現在の道路状況を迅速に評価できるようにします。リアルタイム データと高度な経路計画アルゴリズムを組み合わせることで、自動運転システムは潜在的なリスクを回避するための適切な緊急戦略を開発できます。 これらの例を通じて、Transformer BEV テクノロジーがコーナーケースに対処する上で大きな可能性を秘めていることがわかります。しかし、Transformer BEV技術の利点を最大限に発揮するには、画像処理能力やセンサーフュージョン技術、異常挙動予測などの性能向上について、さらなる研究開発が必要です。 この記事では、自動運転における変圧器と BEV テクノロジーの原理と応用、特にコーナーケース問題の解決方法についてまとめます。 。 Transformer BEV テクノロジーは、グローバルな視点と正確な環境認識を提供することで、極限状況に直面した場合の自動運転システムの信頼性と安全性を向上させることが期待されています。ただし、現在のテクノロジーには、悪天候時のパフォーマンス低下など、依然として一定の制限があります。今後の研究では、より高いレベルの自動運転の安全性を達成するために、BEV 技術の改善と他のセンシング技術との統合に引き続き重点を置く必要があります。 3. 異常行動の予測
4. 狭いまたは封鎖された道路
5. 車両の合流と交通の合流
6. 緊急時対応
04 結論
以上がTransformer BEV を使用して自動運転の極限状況を克服するにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1666
1666
 14
1425
52
1328
25
1273
29
1253
24
14
1425
52
1328
25
1273
29
1253
24

 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3 の論文がついに登場しました!このモデルは2週間前にリリースされ、Soraと同じDiT(DiffusionTransformer)アーキテクチャを採用しており、リリースされると大きな話題を呼びました。前バージョンと比較して、StableDiffusion3で生成される画像の品質が大幅に向上し、マルチテーマプロンプトに対応したほか、テキスト書き込み効果も向上し、文字化けが発生しなくなりました。 StabilityAI は、StableDiffusion3 はパラメータ サイズが 800M から 8B までの一連のモデルであると指摘しました。このパラメーター範囲は、モデルを多くのポータブル デバイス上で直接実行できることを意味し、AI の使用を大幅に削減します。
 DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
この論文では、自動運転においてさまざまな視野角 (遠近法や鳥瞰図など) から物体を正確に検出するという問題、特に、特徴を遠近法 (PV) 空間から鳥瞰図 (BEV) 空間に効果的に変換する方法について検討します。 Visual Transformation (VT) モジュールを介して実装されます。既存の手法は、2D から 3D への変換と 3D から 2D への変換という 2 つの戦略に大別されます。 2D から 3D への手法は、深さの確率を予測することで高密度の 2D フィーチャを改善しますが、特に遠方の領域では、深さ予測に固有の不確実性により不正確さが生じる可能性があります。 3D から 2D への方法では通常、3D クエリを使用して 2D フィーチャをサンプリングし、Transformer を通じて 3D と 2D フィーチャ間の対応のアテンション ウェイトを学習します。これにより、計算時間と展開時間が増加します。
 SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
原題: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving 論文リンク: https://arxiv.org/pdf/2402.02519.pdf コードリンク: https://github.com/HKUST-Aerial-Robotics/SIMPL 著者単位: 香港科学大学DJI 論文のアイデア: この論文は、自動運転車向けのシンプルで効率的な動作予測ベースライン (SIMPL) を提案しています。従来のエージェントセントとの比較
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
