
 テクノロジー周辺機器
AI
GPT のようなモデルのトレーニングが 26.5% 高速化されます。清華 Zhu Jun らは INT4 アルゴリズムを使用してニューラル ネットワークのトレーニングを高速化します
テクノロジー周辺機器
AI
GPT のようなモデルのトレーニングが 26.5% 高速化されます。清華 Zhu Jun らは INT4 アルゴリズムを使用してニューラル ネットワークのトレーニングを高速化します
GPT のようなモデルのトレーニングが 26.5% 高速化されます。清華 Zhu Jun らは INT4 アルゴリズムを使用してニューラル ネットワークのトレーニングを高速化します

アクティベーション、重み、勾配を 4 ビットに量子化することは、ニューラル ネットワークのトレーニングを高速化するために非常に有益であることを私たちは知っています。しかし、既存の 4 ビット トレーニング方法では、最新のハードウェアではサポートされていないカスタム数値形式が必要です。この記事では、Tsinghua Zhu Jun らが、INT4 アルゴリズムを使用してすべての行列乗算を実装する Transformer トレーニング方法を提案しています。
モデルが迅速にトレーニングされるかどうかは、アクティベーション値、重み、勾配、その他の要素の要件と密接に関係しています。
ニューラル ネットワークのトレーニングには一定量の計算が必要であり、低精度のアルゴリズム (完全量子化トレーニングまたは FQT トレーニング) を使用すると、コンピューティングとメモリの効率が向上することが期待されます。 FQT は、元の完全精度の計算グラフに量子化器と逆量子化器を追加し、高価な浮動小数点演算を安価な低精度浮動小数点演算に置き換えます。
FQT に関する研究は、収束速度と精度の犠牲を減らしながら、トレーニングの数値精度を下げることを目的としています。必要な数値精度は FP16 から FP8、INT32 INT8、INT8 INT5 に減少します。 FP8 トレーニングは、Transformer エンジンを備えた Nvidia H100 GPU で実行され、大規模な Transformer トレーニングを驚くほど高速化できます。
最近、トレーニング数値の精度が4ビットまで低下しました。 Sun らは、INT4 アクティベーション/重みと FP4 勾配を使用していくつかの現代ネットワークのトレーニングに成功し、Chmiel らは、精度をさらに向上させるカスタムの 4 桁の対数形式を提案しました。ただし、これらの 4 ビット トレーニング方法は、現在のハードウェアではサポートされていないカスタム数値形式を必要とするため、アクセラレーションに直接使用することはできません。
4 ビットという非常に低いレベルでのトレーニングには、最適化に関する大きな課題があります。まず、順伝播の非微分量子化器により、損失関数のグラフが不均一になります。勾配ベースのオプティマイザーは、ローカル最適化に陥りやすいです。第 2 に、勾配は低精度でしか計算できず、この不正確な勾配によりトレーニング プロセスが遅くなり、さらにはトレーニングが不安定になったり、発散したりする可能性があります。
この記事では、人気のあるニューラル ネットワーク Transformer 用の新しい INT4 トレーニング アルゴリズムを提案します。 Transformer のトレーニングに使用される高価な線形演算は、行列乗算 (MM) の形式で記述できます。 MM 形式主義により、研究者はより柔軟な量子化器を設計できます。この量子化器は、Transformer の特定のアクティベーション、重み、および勾配構造を通じて FP32 行列の乗算をより適切に近似します。この記事の量子化器は、確率的数値線形代数の新たな進歩も利用しています。
 写真
写真
論文アドレス: https://arxiv.org/pdf/2306.11987.pdf
研究によると、順伝播の場合、精度低下の主な理由はアクティベーションの外れ値であることがわかっています。この外れ値を抑制するために、変換された活性化行列を量子化するために使用されるアダマール量子化器が提案されています。この変換はブロック対角アダマール行列であり、外れ値によってもたらされる情報を外れ値の近くの行列エントリに広げ、それによって外れ値の数値範囲を狭めます。
バックプロパゲーションの場合、この研究では活性化勾配の構造的疎性を利用しています。研究によると、一部のトークンの勾配は非常に大きいですが、同時に他のほとんどのトークンの勾配は非常に小さく、より大きな勾配の量子化残差でさえも小さくなります。したがって、これらの小さな勾配を計算する代わりに、計算リソースを使用して、より大きな勾配の残差が計算されます。
この記事では、順伝播と逆伝播の量子化手法を組み合わせて、Transformer のすべての線形演算に INT4 MM を使用するアルゴリズムを提案します。この研究では、自然言語理解、質問応答、機械翻訳、画像分類など、さまざまなタスクで Transformer をトレーニングするためのアルゴリズムを評価しました。提案されたアルゴリズムは、既存の 4 ビット トレーニングの取り組みと比較して、同等以上の精度を達成します。さらに、このアルゴリズムはカスタムの数値形式 (FP4 や対数形式など) を必要としないため、最新のハードウェア (GPU など) と互換性があります。また、研究によって提案されたプロトタイプの量子化 INT4 MM オペレーターは、FP16 MM ベースラインよりも 2.2 倍高速であり、トレーニング速度が 35.1% 向上します。
順伝播
#トレーニング プロセス中、研究者らは INT4 アルゴリズムを使用してすべての線形演算子を高速化し、すべての計算をより集中的に行いました。低非線形演算子は FP16 形式に設定されます。 Transformer のすべての線形演算子は、行列乗算形式で記述することができます。デモンストレーションの目的で、彼らは次のように単純な行列乗算の高速化を検討しました。
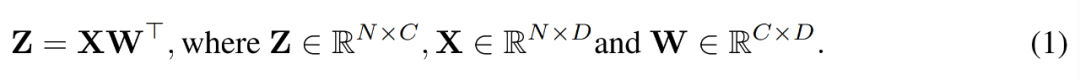 図
図
この種の行列乗算の主な使用例は、全結合層です。
学習済みステップ サイズ量子化
加速トレーニングでは、順伝播を計算するために整数演算を使用する必要があります。したがって、研究者らは学習済みステップ サイズ量子化器 (LSQ) を利用しました。静的量子化方法である LSQ の量子化スケールは入力に依存しないため、動的量子化方法よりも安価です。対照的に、動的量子化方法では、反復ごとに量子化スケールを動的に計算する必要があります。
FP 行列 X が与えられると、LSQ は次の式 (2) によって X を整数に量子化します。
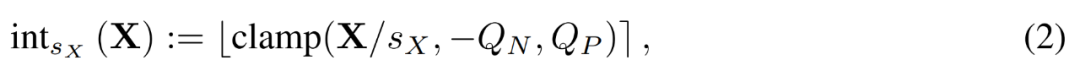 図
図
異常値のアクティブ化
簡単な適用4 ビットのアクティブ化/重み付けを使用した LSQ から FQT (完全に量子化されたトレーニング) は、外れ値のアクティブ化による精度の低下につながります。以下の図 1 (a) に示すように、アクティブ化された外れ値の項がいくつかあり、その大きさは他の項よりもはるかに大きくなります。
この場合、ステップ サイズ s_X は、量子化の粒度と表現可能な値の範囲の間のトレードオフになります。 s_X が大きい場合、他のほとんどの項を粗く表現する代わりに、外れ値を適切に表現できます。 s_X が小さい場合、[−Q_Ns_X, Q_Ps_X] の範囲外の項は切り捨てる必要があります。
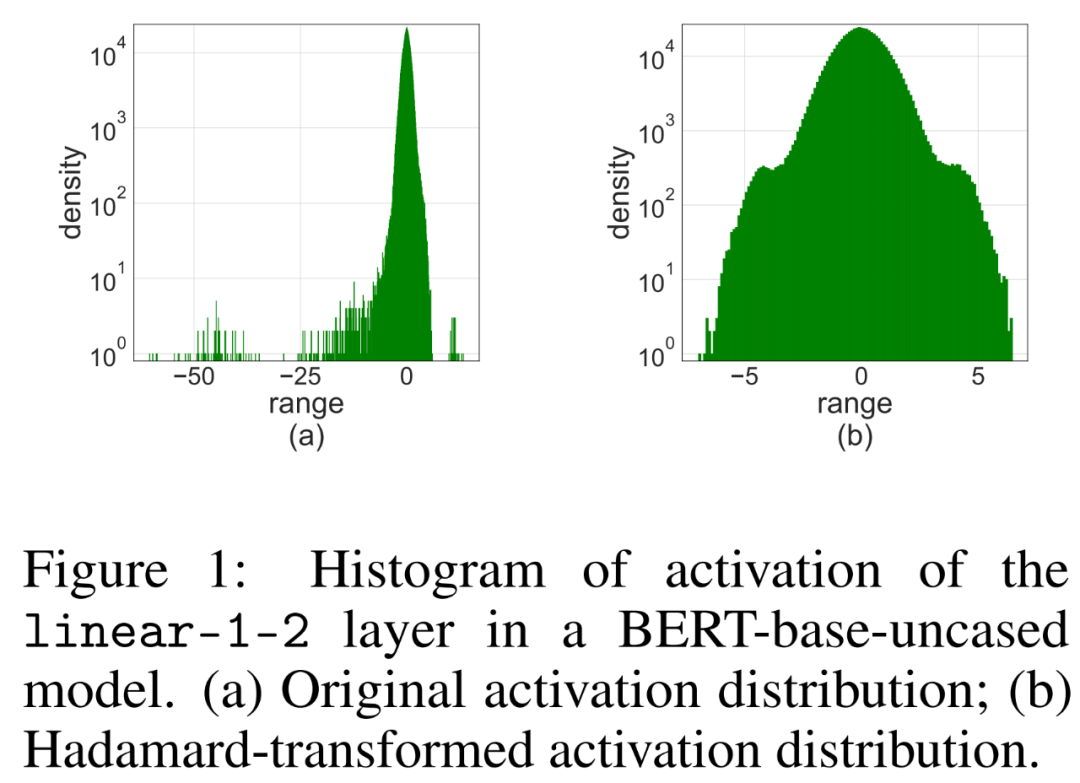
アダマール量子化
研究者は、アダマール量子化器 (HQ) を使用することを提案しました。 ) 外れ値の問題を解決するための主なアイデアは、外れ値の少ない別の線形空間で行列を量子化することです。
アクティベーション マトリックスの外れ値は、機能レベルの構造を形成する可能性があります。これらの外れ値は通常、いくつかの次元に沿ってクラスター化されています。つまり、X のいくつかの列だけが他の列よりも大幅に大きくなります。線形変換として、アダマール変換は他の項の間で外れ値を分散させることができます。具体的には、アダマール変換 H_k は 2^k × 2^k 行列です。
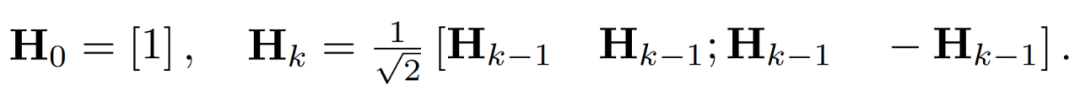
#外れ値を抑制するために、研究者は X と W の変換されたバージョンを量子化します。
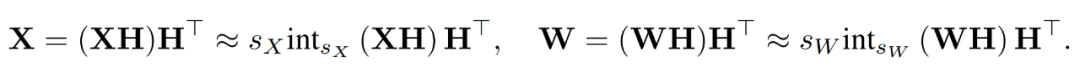
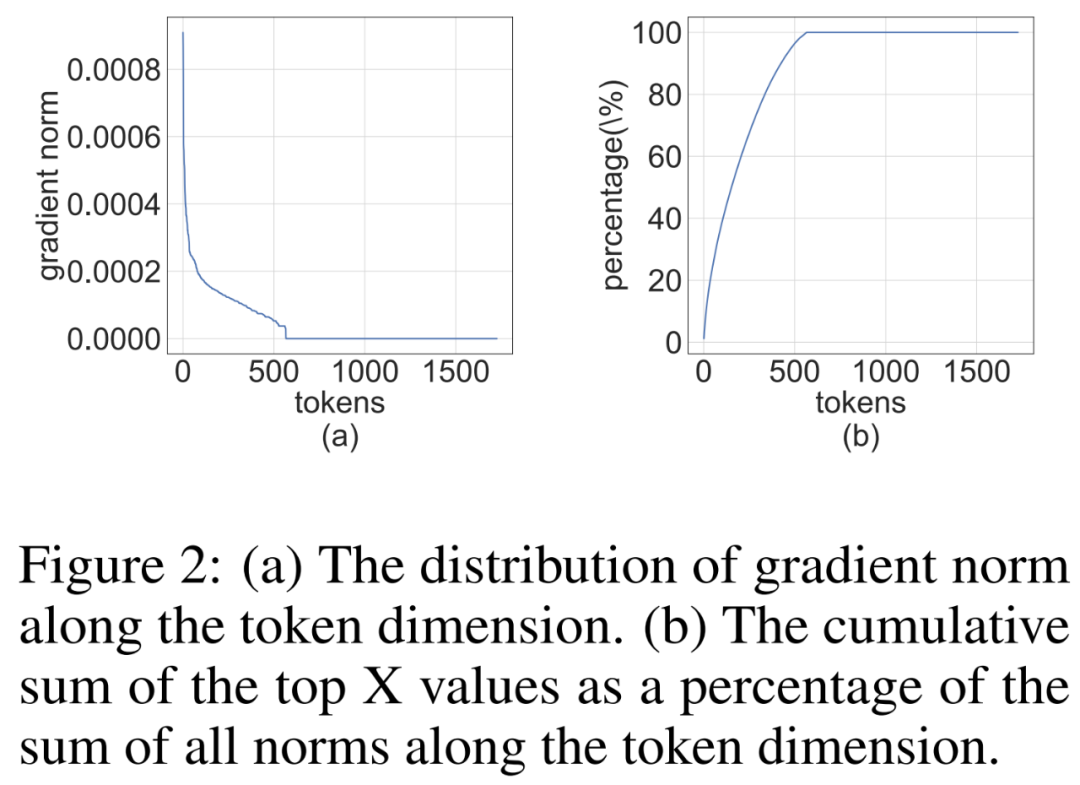
量子化された行列を結合することにより、研究者は次の結果を得ました。
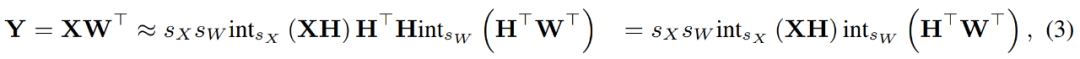
ここで、逆変換は互いに打ち消し合い、MM は次のように実装できます。
 写真
写真
バックプロパゲーション
研究者は INT4 演算を使用して、バックプロパゲーションを高速化します。直線的な層。式 (3) で定義された線形演算子 HQ-MM には 4 つの入力、つまりアクティベーション X、重み W、ステップ s_X および s_W があります。損失関数 L に対する出力勾配 ∇_YL が与えられると、これら 4 つの入力の勾配を計算する必要があります。
勾配の構造的疎性
研究者らは、勾配行列 ∇_Y がトレーニング プロセス中に非常に疎であることが多いことに気づきました。 。スパース構造は、∇_Y のいくつかの行 (つまり、トークン) が大きな項を持ち、他のほとんどの行はすべてゼロのベクトルに近いような構造です。彼らは、以下の図 2 に、すべての行の行ごとのノルム ∥(∇_Y)_i:∥ のヒストグラムをプロットしました。
 図
図
ビット分割と平均スコア サンプリング
研究者らは、構造的スパース性を利用して逆伝播中に MM を正確に計算する勾配量子化器の設計方法について議論しています。大まかな考え方は、多くの行の勾配が非常に小さいため、パラメーターの勾配への影響も小さいですが、多くの計算が無駄になるということです。さらに、大きな行は INT4 では正確に表現できません。
この疎性を利用するために、研究者は、各トークンの勾配を上位 4 ビットと下位 4 ビットに分割するビット分割を提案しています。次に、RandNLA の重要度サンプリング手法である平均スコア サンプリングを通じて、最も多くの情報を持つ勾配が選択されます。
実験結果
この研究では、言語モデルの微調整、機械翻訳、画像分類。この研究では、CUDA と Cutlass2 を使用して、提案された HQ-MM および LSS-MM アルゴリズムを実装しました。単純に LSQ を埋め込み層として使用することに加えて、すべての浮動小数点線形演算子を INT4 に置き換え、最後の層分類器の完全な精度を維持しました。その際、研究者らはすべての評価モデルにデフォルトのアーキテクチャ、オプティマイザ、スケジューラ、ハイパーパラメータを採用しました。
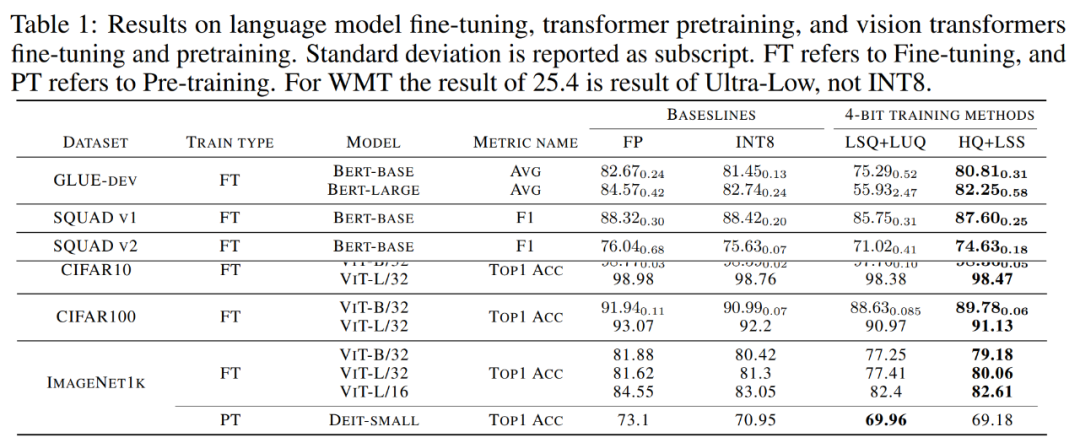
収束モデルの精度。以下の表 1 は、各タスクにおける収束モデルの精度を示しています。
 図
図
言語モデルの微調整。 LSQ LUQ と比較して、この研究で提案されたアルゴリズムは、bert-base モデルで平均精度が 5.5%、bert-large モデルで 25% 向上しました。
研究チームは、SQUAD、SQUAD 2.0、Adversarial QA、CoNLL-2003、SWAG データセットに関するアルゴリズムのさらなる結果も実証しました。すべてのタスクにおいて、この方法は LSQ LUQ と比較して優れたパフォーマンスを実現します。 LSQ LUQ と比較して、この方法は SQUAD と SQUAD 2.0 でそれぞれ 1.8% と 3.6% の改善を達成しました。より困難な敵対的 QA では、この方法により F1 スコアが 6.8% 向上しました。 SWAG と CoNLL-2003 では、この方法により精度がそれぞれ 6.7% と 4.2% 向上しました。
機械翻訳。この研究では、提案された方法を事前トレーニングにも使用しました。このメソッドは、WMT 14 En-De データセット上で機械翻訳用に Transformer ベースの [51] モデルをトレーニングします。
HQ LSS の BLEU 劣化率は約 1.0% ですが、これは Ultra-low の 2.1% よりも小さく、LUQ 論文で報告されている 0.3% よりも高くなります。それにもかかわらず、HQ LSS はこの事前トレーニング タスクにおいて既存の方法と同等のパフォーマンスを発揮し、最新のハードウェアをサポートします。
#画像の分類。事前トレーニングされた ViT チェックポイントを ImageNet21k にロードし、CIFAR-10、CIFAR-100、および ImageNet1k で微調整することを研究します。
LSQ LUQ と比較して、この研究方法では ViT-B/32 と ViT-L/32 の精度がそれぞれ 1.1% と 0.2% 向上します。 ImageNet1k では、この方法により、LSQ LUQ と比較して、ViT-B/32 で 2%、ViT-L/32 で 2.6%、ViT-L/32 で 0.2% 精度が向上します。
研究チームは、ImageNet1K 上で DeiT-Small モデルを事前トレーニングするアルゴリズムの有効性をさらにテストしました。このアルゴリズムでは、HQ LSS は LSQ と比較して同様のレベルの精度に収束できます。 LUQ は、ハードウェアもよりフレンドリーです。
アブレーション研究
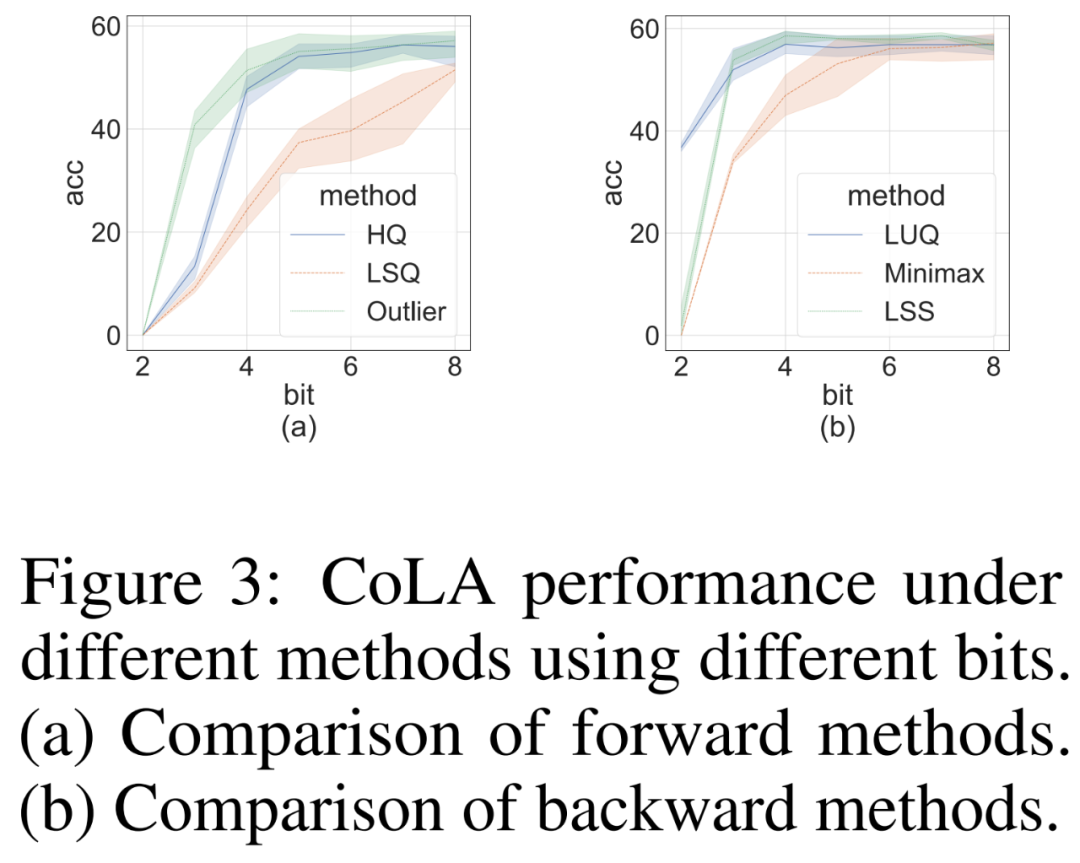
研究者らは、困難な CoLA に関するフロントエンド データを独自に実証するためにアブレーション研究を実施しました。データセット: 順方向メソッドと逆方向メソッドの有効性。順伝播におけるさまざまな量子化器の有効性を調査するために、彼らは逆伝播を FP16 に設定しました。結果を以下の図 3(a) に示します。
逆伝播の場合、研究者らは単純なミニマックス量子化器 LUQ と独自の LSS を比較し、FP16 への順伝播を設定しました。結果は次の図 3 (b) に示されており、ビット幅は 2 よりも大きいにもかかわらず、LSS は LUQ と同等か、それよりわずかに優れた結果を達成します。
 写真
写真
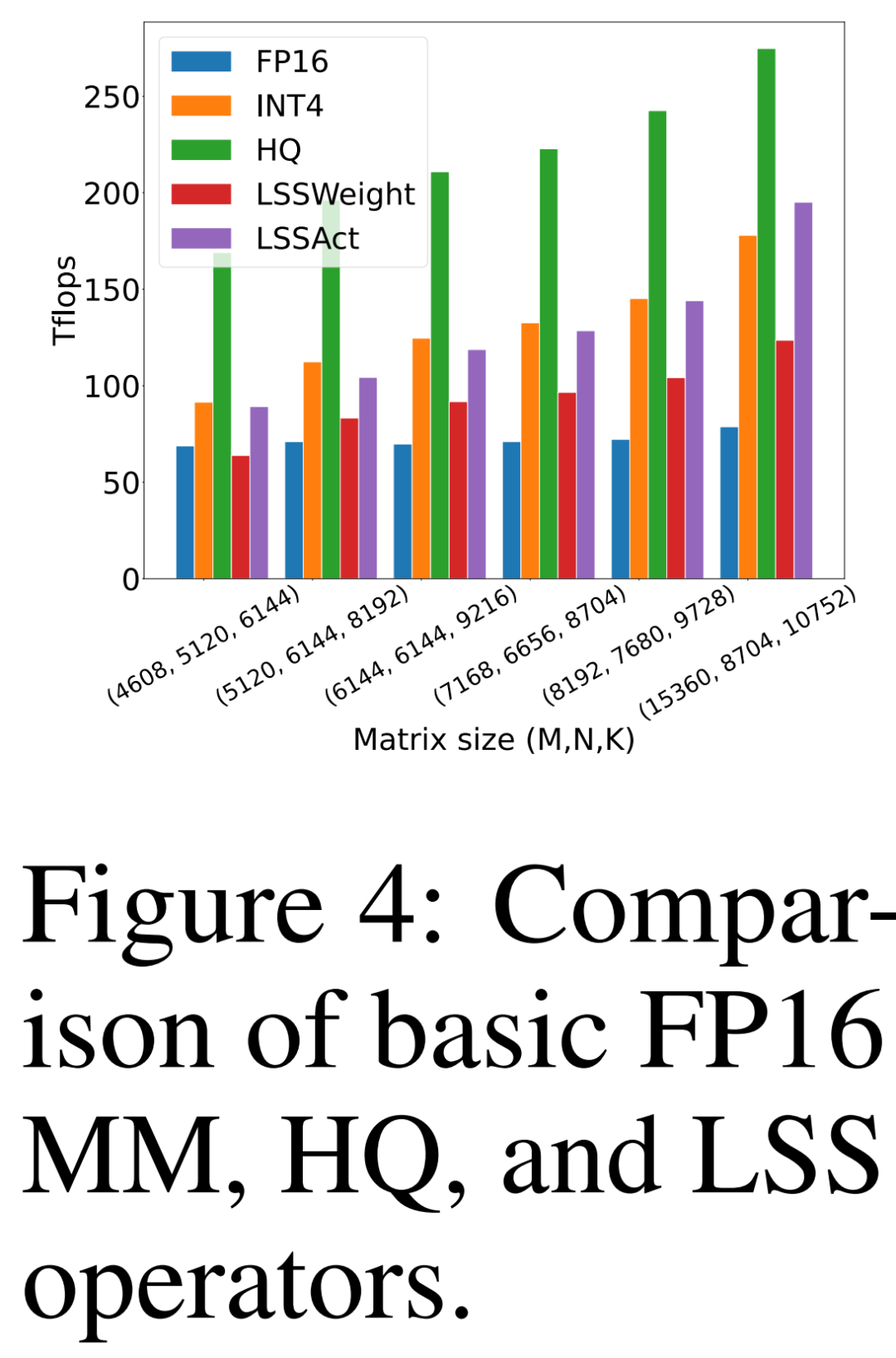
計算とメモリの効率
研究者は、同氏が提案した HQ-MM (HQ)、重み勾配を計算する LSS (LSSWeight)、活性化勾配を計算する LSS (LSSAct)、それらの平均スループット (INT4) と NVIDIA RTX 3090 のスループットを比較しました。 GPU (FP16) 上の Cutlass によって提供されるベースライン テンソル コア FP16 GEMM 実装のピーク スループットは、142 FP16 TFLOP と 568 INT4 TFLOP です。
 写真
写真
研究者はまた、FP16 PyTorch AMP と独自の INT4 トレーニング アルゴリズムを比較して、8 台の NVIDIA A100 で BERT のような言語モデルと GPT のような言語モデルをトレーニングしました。 GPU トレーニングのスループット。彼らは、隠れ層のサイズ、中間の全結合層のサイズ、およびバッチ サイズを変更し、INT4 トレーニングの高速化を以下の図 5 にプロットしました。
結果は、INT4 トレーニング アルゴリズムが BERT のようなモデルで最大 35.1% の高速化を達成し、GPT のようなモデルで最大 26.5% の高速化を達成することを示しています。 ###############写真######
以上がGPT のようなモデルのトレーニングが 26.5% 高速化されます。清華 Zhu Jun らは INT4 アルゴリズムを使用してニューラル ネットワークのトレーニングを高速化しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7697
7697
 15
1640
14
1393
52
1287
25
1229
29
15
1640
14
1393
52
1287
25
1229
29

 クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションをサポートする交換:1。Binance、2。Uniswap、3。Sushiswap、4。CurveFinance、5。Thorchain、6。1inchExchange、7。DLNTrade、これらのプラットフォームはさまざまな技術を通じてマルチチェーン資産トランザクションをサポートします。
 Web3トレーディングプラットフォームranking_web3グローバル交換トップ10の概要
Apr 21, 2025 am 10:45 AM
Web3トレーディングプラットフォームranking_web3グローバル交換トップ10の概要
Apr 21, 2025 am 10:45 AM
Binanceは、グローバルデジタルアセット取引エコシステムの大君主であり、その特性には次のものが含まれます。1。1日の平均取引量は1,500億ドルを超え、500の取引ペアをサポートし、主流の通貨の98%をカバーしています。 2。イノベーションマトリックスは、デリバティブ市場、Web3レイアウト、教育システムをカバーしています。 3.技術的な利点は、1秒あたり140万のトランザクションのピーク処理量を伴うミリ秒のマッチングエンジンです。 4.コンプライアンスの進捗状況は、15か国のライセンスを保持し、ヨーロッパと米国で準拠した事業体を確立します。
 WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)は、独自の生体認証とプライバシー保護メカニズムを備えた暗号通貨市場で際立っており、多くの投資家の注目を集めています。 WLDは、特にOpenai人工知能技術と組み合わせて、革新的なテクノロジーを備えたAltcoinsの間で驚くほど演奏しています。しかし、デジタル資産は今後数年間でどのように振る舞いますか? WLDの将来の価格を一緒に予測しましょう。 2025年のWLD価格予測は、2025年にWLDで大幅に増加すると予想されています。市場分析は、平均WLD価格が1.31ドルに達する可能性があり、最大1.36ドルであることを示しています。ただし、クマ市場では、価格は約0.55ドルに低下する可能性があります。この成長の期待は、主にWorldCoin2によるものです。
 「ブラックマンデーセル」は、暗号通貨業界にとって厳しい日です
Apr 21, 2025 pm 02:48 PM
「ブラックマンデーセル」は、暗号通貨業界にとって厳しい日です
Apr 21, 2025 pm 02:48 PM
暗号通貨市場での突入は投資家の間でパニックを引き起こし、Dogecoin(Doge)は最も困難なヒット分野の1つになりました。その価格は急激に下落し、分散財務財務(DEFI)(TVL)の総価値が激しく減少しました。 「ブラックマンデー」の販売波が暗号通貨市場を席巻し、ドゲコインが最初にヒットしました。そのdefitVLは2023レベルに低下し、通貨価格は過去1か月で23.78%下落しました。 DogecoinのDefitVLは、主にSOSO値指数が26.37%減少したため、272万ドルの安値に低下しました。退屈なDAOやThorchainなどの他の主要なDefiプラットフォームも、それぞれ24.04%と20減少しました。
 通貨サークルでのレバレッジされた交換のランキングは
Apr 21, 2025 pm 11:24 PM
通貨サークルでのレバレッジされた交換のランキングは
Apr 21, 2025 pm 11:24 PM
2025年のレバレッジド取引、セキュリティ、ユーザーエクスペリエンスで優れたパフォーマンスを持つプラットフォームは次のとおりです。1。OKX、高周波トレーダーに適しており、最大100倍のレバレッジを提供します。 2。世界中の多通貨トレーダーに適したバイナンス、125倍の高いレバレッジを提供します。 3。Gate.io、プロのデリバティブプレーヤーに適し、100倍のレバレッジを提供します。 4。ビットゲットは、初心者やソーシャルトレーダーに適しており、最大100倍のレバレッジを提供します。 5。Kraken、安定した投資家に適しており、5倍のレバレッジを提供します。 6。Altcoinエクスプローラーに適したBybit。20倍のレバレッジを提供します。 7。低コストのトレーダーに適したKucoinは、10倍のレバレッジを提供します。 8。ビットフィネックス、シニアプレイに適しています
 なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
仮想通貨価格の上昇の要因には、次のものが含まれます。1。市場需要の増加、2。供給の減少、3。刺激された肯定的なニュース、4。楽観的な市場感情、5。マクロ経済環境。衰退要因は次のとおりです。1。市場需要の減少、2。供給の増加、3。ネガティブニュースのストライキ、4。悲観的市場感情、5。マクロ経済環境。
 カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
暗号通貨の賑やかな世界では、新しい機会が常に現れます。現在、Kerneldao(Kernel)Airdropアクティビティは多くの注目を集め、多くの投資家の注目を集めています。それで、このプロジェクトの起源は何ですか? BNBホルダーはそれからどのような利点を得ることができますか?心配しないでください、以下はあなたのためにそれを一つ一つ明らかにします。
 Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Aavedaoの定足数を実装したToken Reposを導入する提案です。 Aave Project Chain(ACI)の創設者であるMarc Zellerは、これをXで発表し、契約の新しい時代をマークしていることに注目しました。 Aave Chain Initiative(ACI)の創設者であるMarc Zellerは、Aavenomicsの提案にAave Protocolトークンの変更とトークンリポジトリの導入が含まれていると発表しました。 Zellerによると、これは契約の新しい時代を告げています。 Aavedaoのメンバーは、水曜日の週に100でした。
