

380億米ドルの巨大データ企業が企業に「AI」革命を起こそうとしている

著者 | ワン・チェン、リー・ユアン
編集者 | ジンユ
現地時間の 6 月 28 日、米国の有名なデータ プラットフォームである Databricks は、独自の年次カンファレンスであるデータと人工知能サミットを開催しました。この会議で、Databricks は、LakehouseIQ、Lakehouse AI、Databricks Marketplace、Lakehouse Apps などの一連の重要な新製品を発表しました。
サミットの名前にしても、新製品の名前にしても、この有名なデータ プラットフォームがビッグ言語モデルを利用して AI への変革を加速していることがわかります。

Databricks CEO の Ali Ghodsi 氏はデータと AI の包括性について語った|Databricks
「Databricks が達成したいのは、「データの包括性」と AI の包括性です。前者ではデータがすべての従業員に到達できるようになり、後者では AI がすべての製品に参入できるようになります。Databricks の CEO である Ali Ghodsi はスピーチでチームの使命を発表しました。
カンファレンスが始まる直前、DatabricksはAI分野の新勢力であるMosaicMLを13億ドルで買収すると発表したばかりで、AI分野における現在の買収記録を樹立し、同社の強さを示した。 AI変革における決意。
事前の会議に参加している PingCAP の創設者兼 CEO の Liu Qi 氏は、Geek Park に対し、Databricks プラットフォームはエンタープライズレベルの AI アプリケーションを立ち上げたばかりで、すでに 1,500 社以上の企業がそのプラットフォームでモデルをトレーニングしていると語った。数字は予想を上回っています。」同時に、Databricks のこれまでのデータ AI の蓄積により、AI が普及したときに以前のプラットフォームに基づいて新しい製品を迅速に追加し、大規模なモデルに関連するサービスを迅速に提供できるようになったと彼は考えています。
「最も重要なことはスピードです。」Liu Qi 氏は、大規模モデルの時代において、大規模モデルを既存の製品とより迅速に統合し、ユーザーの問題点を解決する方法が現時点ですべてのデータ企業にとって最大の課題である可能性があると述べました。 . 最大のチャンスでもあります。
###話のポイント###対話型インターフェイスのアップグレードにより、データ アナリストではない一般の人でも、自然言語を直接使用してデータのクエリと分析を行うことができます。
- 企業が大規模モデルをクラウド データベースに展開することがますます容易になり、完成した大規模モデル ツールを直接使用してデータを分析することも容易になります。
- AIの進化により、データの価値はますます高くなり、データの可能性はさらに解放されます。
- 01 データベースは自然言語対話を歓迎します
Databricks はカンファレンスで新しい LakehouseIQ ツールをリリースしましたが、これは「成果物」として歓迎されました。 LakehouseIQ は、Databricks の最近の最大の取り組みの 1 つであるデータ分析の汎用化を実現しており、Python や SQL をマスターしていない一般の人でも簡単に企業データにアクセスし、自然言語を使用してデータ分析を行うことができます。
この目標を達成するために、LakehouseIQ は一般のエンド ユーザーと開発者の両方が使用できる機能の集合として設計されており、ユーザーごとに異なる機能が設計されています。
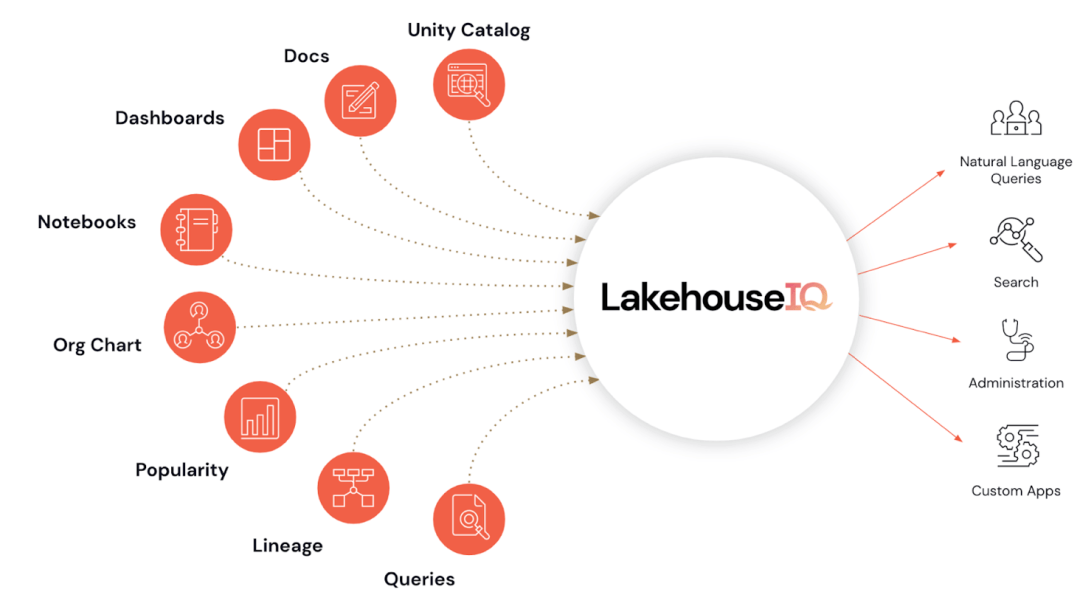 LakehouseIQ 製品写真|Databricks
LakehouseIQ 製品写真|Databricks
開発者向けに、Notebooks の LakehouseIQ がリリースされました。この機能では、LakehouseIQ は大規模な言語モデルを使用して、開発者がコードを完成、生成、解釈し、コード修復、デバッグ、レポート生成を実行できるようにします。
Databricks は、プログラマーではない一般のユーザー向けに、自然言語と直接対話できるインターフェイスを提供します。これは大規模な言語モデルによって駆動され、自然言語を直接使用してデータの検索とクエリを実行できます。同時に、この機能は Unity Catalog と統合されているため、企業はデータ検索やクエリへのアクセスを制御し、質問者に表示が許可されているデータのみを返すことができます。
大規模モデルの発表以来、自然言語を使用してデータのクエリと分析を行うことは、データ分析の方向で実際に注目のトピックとなっており、多くの企業がこの方向に向けた計画を立てています。 Databricks の古いライバルである Snowflake を含め、発表されたばかりの Document AI 機能もこの方向に焦点を当てています。
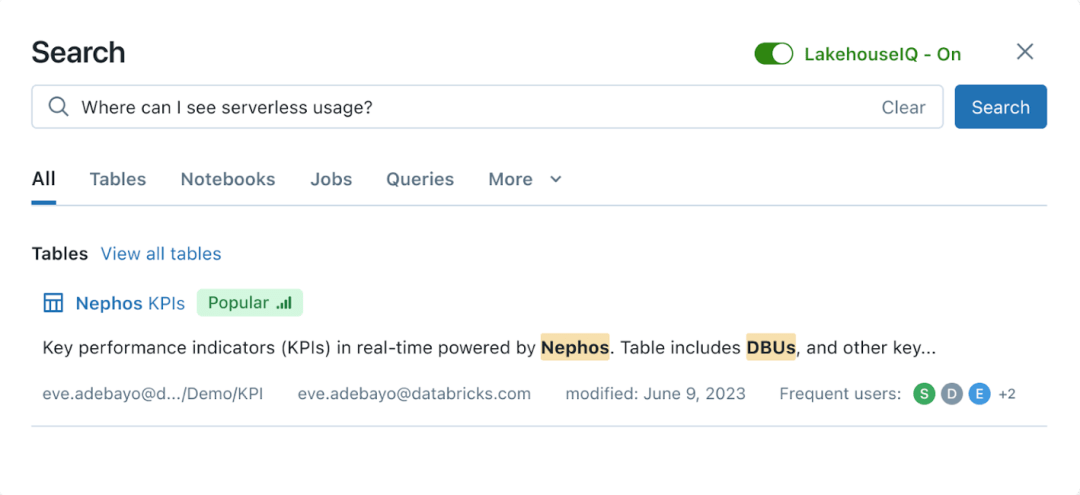 LakehouseIQ 自然言語クエリ インターフェイス|Databricks
LakehouseIQ 自然言語クエリ インターフェイス|Databricks
ただし、Databricks は機能的には LakehouseIQ の方が優れていると主張しています。汎用的な大きな言語モデルには、特定の顧客データ、内部用語、使用パターンを理解する上で限界があると指摘しています。 Databricks のテクノロジーは、顧客独自のスキーマ、ドキュメント、クエリ、人気、スレッド、ノートブック、ビジネス インテリジェンス ダッシュボードを活用して、インテリジェンスを取得し、より多くのクエリに回答します。
Databricks と Snowflake の機能にはもう 1 つの違いがあります。Snowflake プラットフォームの Document AI 機能はドキュメント内の非構造化データのクエリに限定されていますが、LakehouseIQ は構造化された Lakehouse データとコードに適しています。
02
機械学習からAIへ
Databricks と Snowflake の発売時の類似点はそれだけではありません。
このカンファレンスで、Databricks は Databricks Marketplace と Lakehouse AI をリリースしましたが、これらは Snowflake の 2 日間のカンファレンスの焦点と完全に一致しており、どちらも大規模な言語モデルをデータベース環境にデプロイすることに重点を置いています。
Databricks のビジョンでは、Databricks は将来的に顧客による大規模モデルのデプロイを支援するだけでなく、完成した大規模モデル ツールも提供できます。
Databricks は以前、Databricks Machine Learning ブランドを持っていましたが、今回の記者会見で Databricks はブランドの位置付けを完全に変更し、Lakehouse AI にアップグレードし、顧客による大規模モデルのデプロイの支援に重点を置きました。
Databricks Marketplace が Databricks で利用できるようになりました。 Databricks Marketplace では、ユーザーは、MPT-7B、Falcon-7B、Stable Diffusion などのオープンソースの大規模言語モデルの厳選されたコレクションにアクセスでき、データセットやデータ資産を発見して入手することもできます。 Lakehouse AI は、いくつかの大規模言語モデル操作 (LLMOps) 機能も提供します。
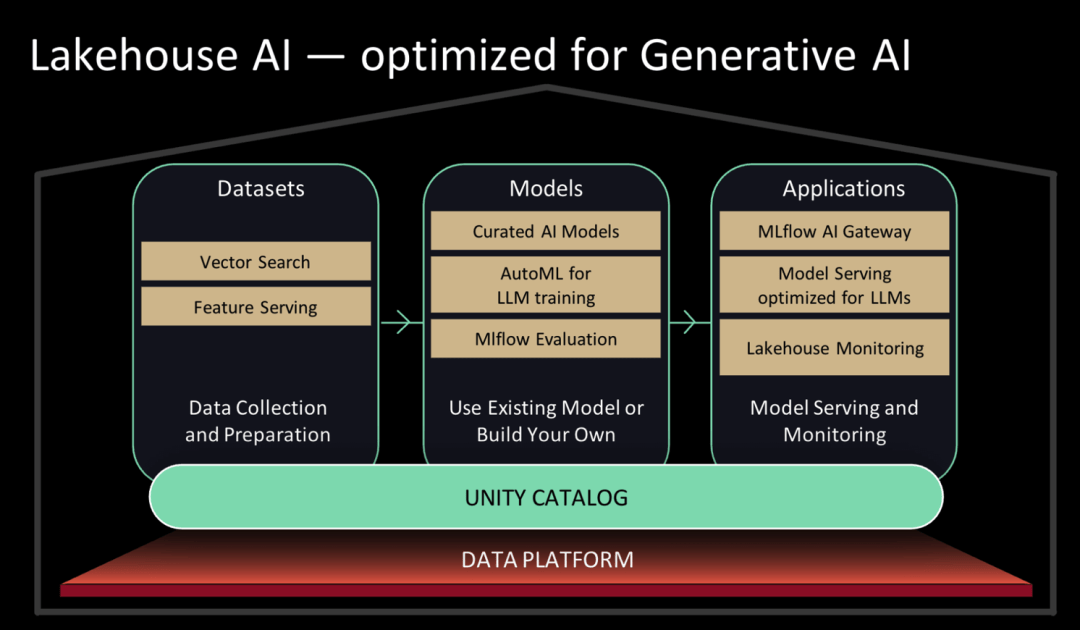
Lakehouse AI アーキテクチャ図|Databricks
Snowflake もこれを積極的に導入しており、同様の機能は Nvidia NeMo、Nvidia AI Enterprise、Dataiku、John Snow Labs によって提供されています (Nvidia との協力は Snowflake カンファレンスのハイライトの 1 つです。Geek Park のレポートを参照してください)。
Snowflake と Databricks には、顧客による大規模モデルのデプロイを支援する点での違いがあります。 Snowflake はパートナーと積極的に関わることを選択しましたが、Databricks はコア プラットフォームのネイティブ機能として機能を追加しようとしました。
完成したツールの提供に関して、Databricks は、将来的に Databricks Marketplace でも Lakehouse アプリを提供すると発表しました。 Lakehouse Apps は顧客の Databricks インスタンス上で直接実行され、顧客のデータと統合し、Databricks サービスを利用および拡張し、ユーザーがシングル サインオン エクスペリエンスを通じて対話できるようにします。データが顧客のインスタンスから流出する必要はなく、データの移動やセキュリティ/アクセスの問題はありません。
これは、名前と機能の点で Snowflake の製品と完全に一致しています。 Snowflake の同様の Snowflake Marketplace と Snowflake Native App はすでにオンラインになっており、そのローンチのハイライトの 1 つです。ブルームバーグは、ブルームバーグが提供するデータ ライセンス プラス (DL) APP を Snowflake カンファレンスで発表しました。これにより、顧客は、完全にモデル化されたブルームバーグ サブスクリプション データと、複数のベンダーからの ESG コンテンツを使用して、すぐに使用できる環境をクラウド内に数分で構成できます。
03
データ プラットフォームは新たな変化を歓迎します
開会の基調講演で、Databricks は次の数字を発表しました。過去 30 日間で、1,500 を超える顧客が Databricks プラットフォームで Transformer モデルをトレーニングしました。
この素晴らしい数字について語るとき、PingCAP Liu Qi 氏は、これは企業が予想よりもはるかに早く AI を適用していることを示していると考えています。したがって、アプリケーションの数はこれ (数字) よりもはるかに大きくなるはずです。」
もう 1 つの観点は、これは AI 分野における Databricks の戦略的レイアウトが非常に包括的であることを示しているということです。今や、単なるデータ ウェアハウスやデータ レイクを超えています。現在では、AI トレーニング、AI サービング、モデル管理なども提供されています。 』

Ali Ghodsi は、コンピューティングとインターネットの革命を利用して、機械学習における大規模モデルの変換を比較します|Databricks
言い換えれば、基礎となるモデルは Databricks プラットフォームでトレーニングでき、最下位モデルはパラメーターを調整するだけでトレーニングできます。このモデルに加えて必要な AI サービスのために、Databricks は対応するインフラストラクチャもレイアウトしました。今日、Databricks はベクター検索と機能ストアをリリースしました。
Databricks は大規模モデルに完全にアップグレードされました。
これまで、Databricks は、インデックスの構築、データのクエリ、ワークロードの予測における効率を向上させ、待ち時間を短縮するための小さなモデルの使用など、AI に関して多くのことを蓄積してきました。しかし、これほど速いペースで大型モデルを補う能力には、依然として多くの人が驚かれています。
今日のサミットで AI レイアウトが完全に公開される前に、Databricks は Okera (AI データ ガバナンス) を買収し、独自のオープンソース大規模モデル Dolly 2.0 を立ち上げ、MosaicML を 13 億米ドルで買収しました。一連のアクションは一度に完了しました。行く。
この点に関して、シリコンバレーの教師 Xu Howie 氏は、Databricks と Snowflake の 2 つのカンファレンスからはっきりと見て取れると考えています。両社の創設者は、データベースとデータレイクに基づいて講じた行動が次に直面することになると信じています。根本的な変更。彼らが1年前にやっていたやり方は、今後数年はうまくいかないだろう。
同様に、大型モデルを迅速に完成させることができるということは、大型モデルによってもたらされる追加的な市場を獲得できることも意味します。
Liu Qi は、大型モデルの出現により、大型モデルが存在しない前には存在しなかった多くの新しい需要が引き起こされたと考えています。データのサポートがなければ、特に差別化の点でモデルは機能しません。誰もが大きなモデルであれば、あなたと他の人の間に違いはないかもしれません。 』
しかし、小型モデルには速度、コスト、安全性などの利点があるため、サミットの聴衆は大型モデルに比べて小型モデルにより多くの注目を集めているようでした。 Liu Qi 氏は、独自のデータに基づいて差別化されたモデルを作成できるとし、モデルは十分に安価、十分に高速、十分に安全であるという 3 つの要件を満たすのに十分な大きさでなければならないと述べました。
Databricks と Snowflake の両方が最近収益データを発表し、プラットフォームの年間収益成長率が 60% を超えていることは注目に値します。この成長率は、市場全体のソフトウェア支出の減速を背景にデータへの注目が高まっていることに反映されています。今回の Databricks Summit では、データ プラス AI をテーマに、大規模モデルの登場によりデータの価値がクローズアップされました。
大規模モデルの導入により、データの自動生成が可能となり、データ量は飛躍的に増加すると予想されます。データに簡単にアクセスする方法、さまざまなデータ形式をサポートする方法、データの背後にある価値を掘り出す方法が、ますます頻繁に必要になるでしょう。
一方、今日多くの企業は依然として大規模なモデルをエンタープライズ ソフトウェアに統合することを模索し、待っていますが、セキュリティ、プライバシー、コストを考慮すると、それを直接使用する勇気のある企業はまだほとんどありません。データを移動せずに大規模なモデルが企業データに直接デプロイされると、大規模なモデルをデプロイするための敷居がさらに低くなり、データ消費の量と速度がさらに解放されます。
以上が380億米ドルの巨大データ企業が企業に「AI」革命を起こそうとしているの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7690
7690
 15
1639
14
1393
52
1287
25
1229
29
15
1639
14
1393
52
1287
25
1229
29

 クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
この記事では、トップAIアートジェネレーターをレビューし、その機能、創造的なプロジェクトへの適合性、価値について説明します。 Midjourneyを専門家にとって最高の価値として強調し、高品質でカスタマイズ可能なアートにDall-E 2を推奨しています。
 ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4は現在利用可能で広く使用されており、CHATGPT 3.5のような前任者と比較して、コンテキストを理解し、一貫した応答を生成することに大幅な改善を示しています。将来の開発には、よりパーソナライズされたインターが含まれる場合があります
 Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
メタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
この記事では、ChatGpt、Gemini、ClaudeなどのトップAIチャットボットを比較し、自然言語の処理と信頼性における独自の機能、カスタマイズオプション、パフォーマンスに焦点を当てています。
 トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
この記事では、Grammarly、Jasper、Copy.ai、Writesonic、RytrなどのトップAIライティングアシスタントについて説明し、コンテンツ作成のためのユニークな機能に焦点を当てています。 JasperがSEOの最適化に優れているのに対し、AIツールはトーンの維持に役立つと主張します
 AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
2024年は、コンテンツ生成にLLMSを使用することから、内部の仕組みを理解することへの移行を目撃しました。 この調査は、AIエージェントの発見につながりました。これは、最小限の人間の介入でタスクと決定を処理する自律システムを処理しました。 buildin
 ファルコン3にアクセスする方法は? - 分析Vidhya
Mar 31, 2025 pm 04:41 PM
ファルコン3にアクセスする方法は? - 分析Vidhya
Mar 31, 2025 pm 04:41 PM
ファルコン3:革新的なオープンソースの大規模な言語モデル LLMSの称賛されたFalconシリーズの最新のイテレーションであるFalcon 3は、AIテクノロジーの重要な進歩を表しています。 Technology Innovation Institute(TII)によって開発されたこのオープン
 最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
この記事では、Google Cloud、Amazon Polly、Microsoft Azure、IBM Watson、DecriptなどのトップAI音声ジェネレーターをレビューし、機能、音声品質、さまざまなニーズへの適合性に焦点を当てています。
