

NTU と上海 AI ラボが 300 以上の論文を編集: Transformer に基づくビジュアル セグメンテーションの最新レビューがリリース

SAM (Segment Anything) は、基本的な視覚セグメンテーション モデルとして、わずか 3 か月で多くの研究者の注目を集め、フォローアップされました。 SAM の背後にあるテクノロジーを体系的に理解し、進化のペースに追いつき、独自の SAM モデルを作成できるようにしたい場合は、このトランスフォーマーベースのセグメンテーション調査をお見逃しなく。最近、南洋理工大学と上海人工知能研究所の数人の研究者が Transformer ベースのセグメンテーションに関するレビューを書き、近年の Transformer に基づくセグメンテーションおよび検出モデルを体系的にレビューし、研究を行っています。今年の6月から!同時に、このレビューには関連分野の最新の論文や多数の実験分析と比較も含まれており、幅広い展望を持つ将来の研究の方向性を多数明らかにしています。
ビジュアル セグメンテーションは、画像、ビデオ フレーム、または点群を複数のセグメントまたはグループにセグメント化することを目的としています。このテクノロジーは、自動運転、画像編集、ロボットの認識、医療分析など、多くの実世界で応用されています。過去 10 年間で、深層学習ベースの手法がこの分野で大きな進歩を遂げました。最近、Transformer は、もともと自然言語処理用に設計されたセルフ アテンション メカニズムに基づくニューラル ネットワークとなり、さまざまな視覚処理タスクにおける以前の畳み込みまたは再帰的手法を大幅に上回りました。具体的には、Vision Transformer は、さまざまなセグメンテーション タスクに対して、強力で統合されたさらにシンプルなソリューションを提供します。このレビューでは、Transformer ベースのビジュアル セグメンテーションの包括的な概要を提供し、最近の進歩を要約します。まず、この記事 では、問題定義、データ セット、以前の畳み込み手法などの背景 を確認します。次に、このペーパーでは、最近の Transformer ベースのメソッドをすべて統合する メタ アーキテクチャ について概要を説明します。このメタ アーキテクチャに基づいて、 この記事では、このメタ アーキテクチャと関連アプリケーションの修正を含む、さまざまな方法の設計を検討します。 さらに、この記事では、3D 点群セグメンテーション、基本的なモデル調整、ドメイン適応セグメンテーション、効率的なセグメンテーション、医療セグメンテーションなど、いくつかの関連設定も紹介します。さらに、この論文では、いくつかの広く認識されているデータセットに基づいてこれらの手法を編集し、再評価します。最後に、この論文はこの分野における未解決の課題を特定し、将来の研究の方向性を提案しています。この記事では、Transformer ベースの最新のセグメンテーションおよび検出方法を継続して追跡します。
 写真
写真
プロジェクトアドレス: https://github.com/lxtGH/Awesome-Segmentation-With-Transformer
論文アドレス: https://arxiv.org/pdf/2304.09854.pdf
研究動機
- ViT と DETR の出現により、セグメンテーションと検出の分野は完全に進歩し、現在、ほぼすべてのデータセット ベンチマークで上位にランクされる手法は、Transformer に基づいています。このため、この方向の手法や技術的特徴を体系的にまとめ、比較する必要がある。
- マルチモーダル モデルやセグメンテーション基本モデル (SAM) など、最近の大規模モデル アーキテクチャはすべて Transformer 構造に基づいており、さまざまな視覚タスクが統合モデル モデリングに近づいています。
- セグメンテーションと検出により、多くの関連する下流タスクが派生し、これらのタスクの多くも Transformer 構造を使用して解決されます。
概要機能
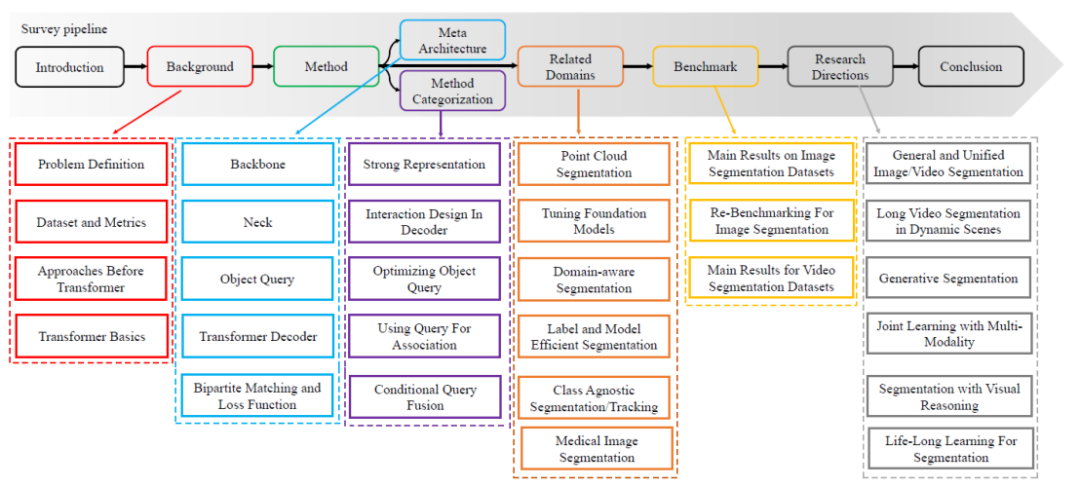
- 体系的で読みやすい。 この記事では、セグメンテーションの各タスク定義、および関連するタスク定義と評価指標を体系的にレビューします。そして、この記事ではコンボリューション手法から始まり、ViTとDETRに基づくメタアーキテクチャをまとめます。このレビューでは、このメタアーキテクチャに基づいて、関連する手法を整理してまとめ、最近の手法を体系的にレビューします。具体的な技術検討ルートを図1に示します。
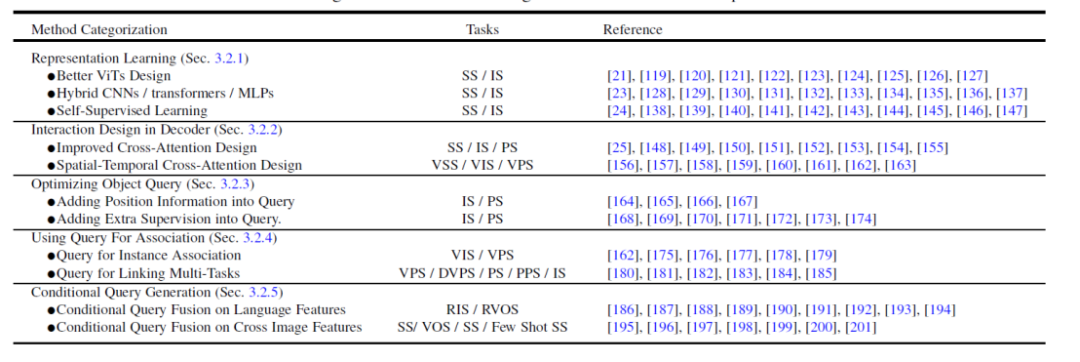
- 技術的な観点からの詳細な分類。 以前の Transformer レビューと比較して、この記事のメソッドの分類はより詳細になります。この記事では、同様のアイデアを持つ論文をまとめ、その類似点と相違点を比較します。たとえば、この記事では、メタ アーキテクチャのデコーダ側を同時に変更する手法を、画像ベースのクロス アテンションとビデオ ベースの時空間クロス アテンション モデリングに分類します。
- 研究課題の包括性。 この記事では、画像、ビデオ、点群のセグメンテーション タスクなど、セグメンテーションのあらゆる方向を体系的にレビューします。同時に、この記事では、オープンセットのセグメンテーションと検出モデル、教師なしセグメンテーション、弱教師セグメンテーションなどの関連する方向性についてもレビューします。
 図
図
図 1. 調査内容のロードマップ
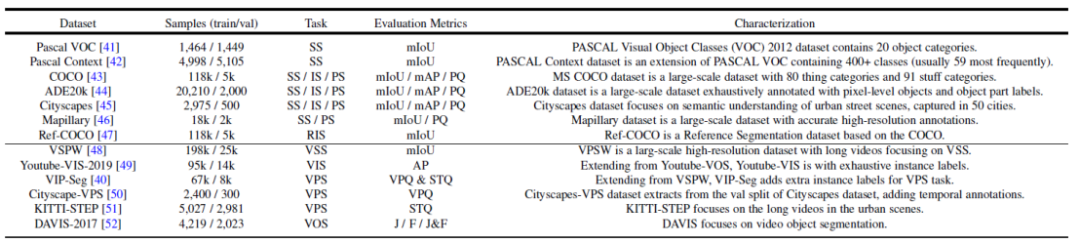
図 2. 一般的に使用されるデータ セットとセグメンテーション タスクの概要
トランスフォーマー ベースのセグメンテーションと検出の概要方法と比較
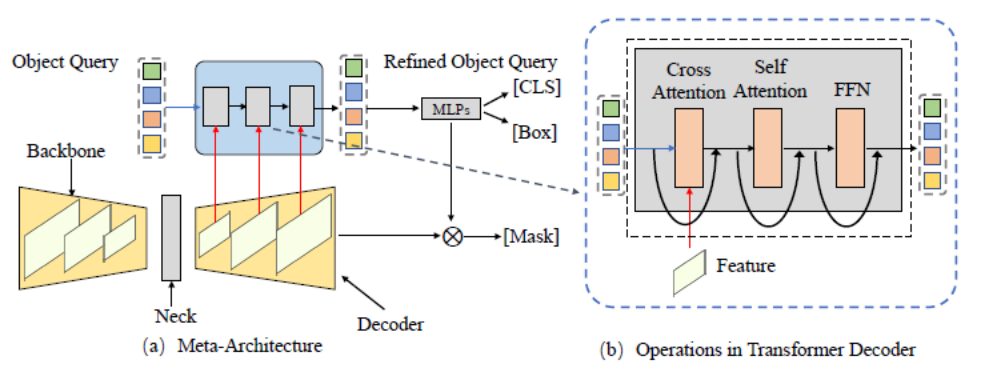
図 3. 一般的なメタ アーキテクチャ フレームワーク
## この記事では、まず概要を説明します。 DETR および MaskFormer フレームワークに基づくメタ アーキテクチャ。このモデルには、次のさまざまなモジュールが含まれています。
- バックボーン: 特徴抽出器。画像の特徴を抽出するために使用されます。
- ネック: マルチスケール オブジェクトを処理するためにマルチスケール フィーチャを構築します。
- オブジェクト クエリ: クエリ オブジェクト。前景オブジェクトや背景オブジェクトなど、シーン内の各エンティティを表すために使用されます。
- デコーダ: デコーダ。オブジェクト クエリと対応する機能を段階的に最適化するために使用されます。
- エンドツーエンドのトレーニング: オブジェクト クエリに基づく設計は、エンドツーエンドの最適化を実現できます。
# 図 5 は、これら 5 つの異なる方向における代表的な作業の比較を示しています。より具体的な手法の詳細と比較については、論文の内容を参照してください。 #図 #関連研究分野の手法の概要と比較 #写真 さまざまな方法の実験結果の比較
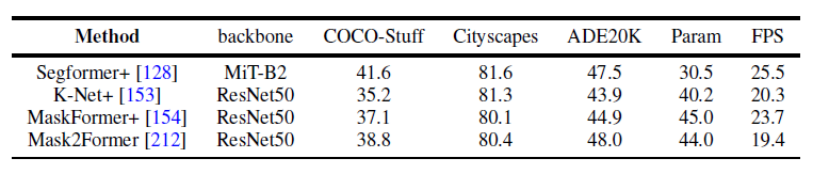
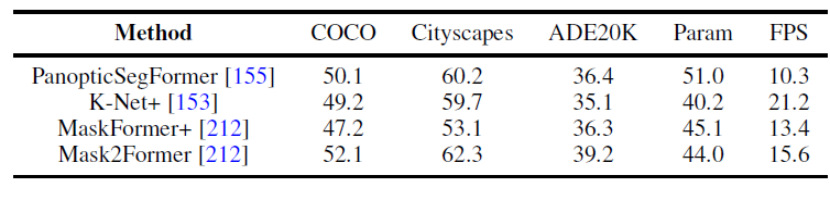
図 8. パノラマ セグメンテーション データ セットのベンチマーク実験 この記事では、同じ実験計画条件を一律に使用して、複数のデータセットに対するパノラマ セグメンテーションとセマンティック セグメンテーションに関するいくつかの代表的な研究の結果を比較します。同じトレーニング戦略とエンコーダーを使用すると、メソッドのパフォーマンスの差が縮まることがわかりました。 さらに、この記事では、複数の異なるデータ セットおよびタスクに対する最近の Transformer ベースのセグメンテーション手法の結果も比較します。 (セマンティック セグメンテーション、インスタンス セグメンテーション、パノラマ セグメンテーション、および対応するビデオ セグメンテーション タスク) さらに、この記事では次のようなことも示しています。将来の研究の方向性についての分析。ここでは例として 3 つの異なる方向を示します。 研究の方向性の詳細については、元の論文を参照してください。
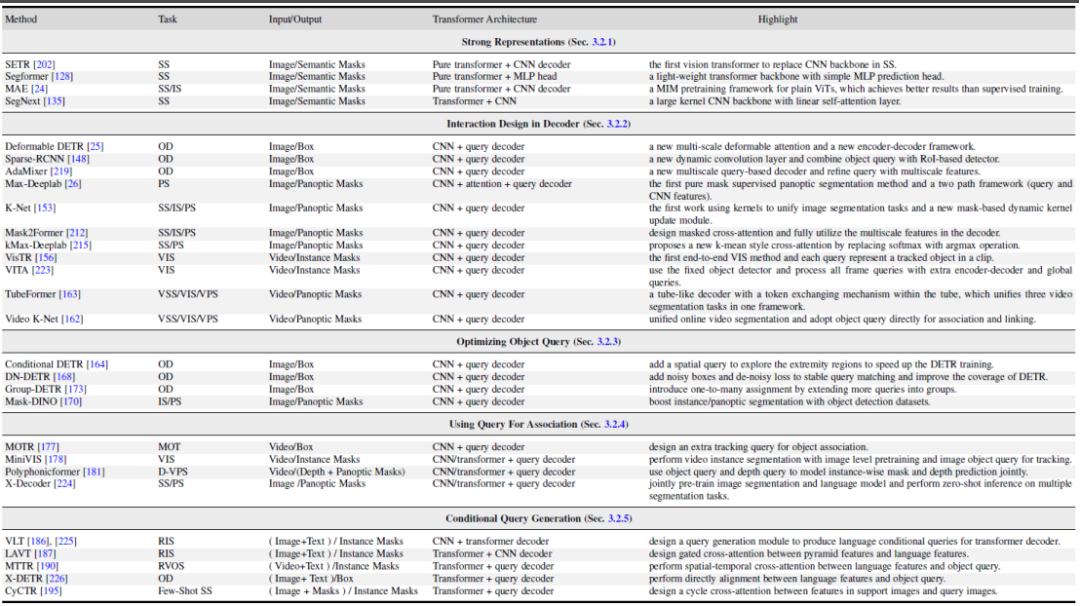
##この記事では、いくつかの関連分野についても説明します。 1. Transformer に基づく点群セグメンテーション手法。 2. ビジョンとマルチモーダル大規模モデルのチューニング。 3. ドメイン転移学習やドメイン汎化学習など、ドメイン関連のセグメンテーション モデルの研究。 4. 効率的なセマンティック セグメンテーション: 教師なしセグメンテーション モデルと弱く教師ありセグメンテーション モデル。 5. クラスに依存しないセグメンテーションと追跡。 6. 医療画像のセグメンテーション。
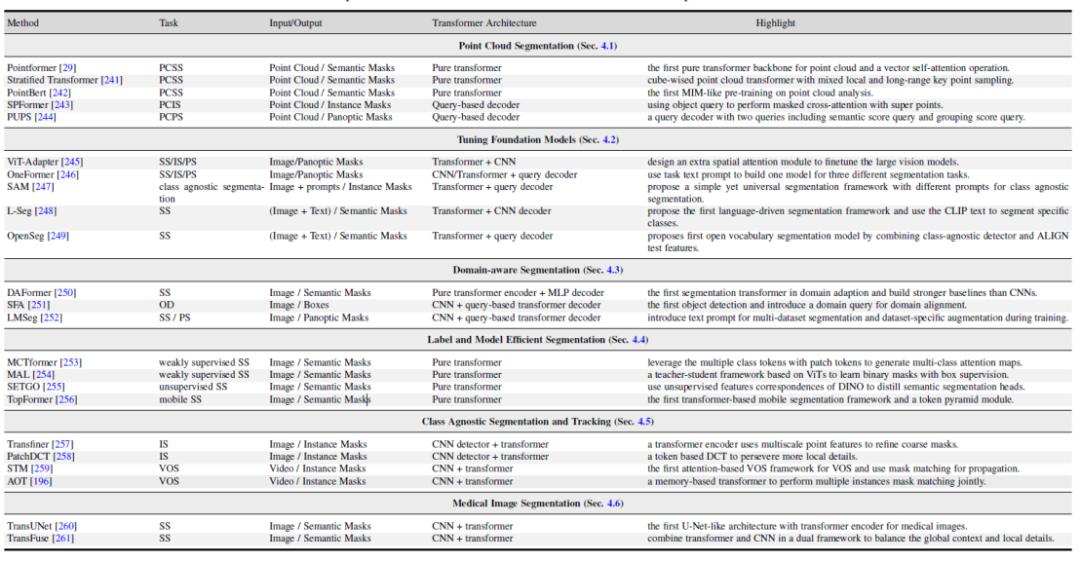 図 6. 関連研究分野における Transformer ベースの手法の概要と比較
図 6. 関連研究分野における Transformer ベースの手法の概要と比較図 7. セマンティック セグメンテーション データ セットのベンチマーク実験
将来の方向
以上がNTU と上海 AI ラボが 300 以上の論文を編集: Transformer に基づくビジュアル セグメンテーションの最新レビューがリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7470
7470
 15
1377
52
77
11
19
29
15
1377
52
77
11
19
29

 Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3 の論文がついに登場しました!このモデルは2週間前にリリースされ、Soraと同じDiT(DiffusionTransformer)アーキテクチャを採用しており、リリースされると大きな話題を呼びました。前バージョンと比較して、StableDiffusion3で生成される画像の品質が大幅に向上し、マルチテーマプロンプトに対応したほか、テキスト書き込み効果も向上し、文字化けが発生しなくなりました。 StabilityAI は、StableDiffusion3 はパラメータ サイズが 800M から 8B までの一連のモデルであると指摘しました。このパラメーター範囲は、モデルを多くのポータブル デバイス上で直接実行できることを意味し、AI の使用を大幅に削減します。
 ICCV'23論文賞「Fighting of Gods」! Meta Divide Everything と ControlNet が共同で選ばれました、審査員を驚かせた記事がもう 1 つありました
Oct 04, 2023 pm 08:37 PM
ICCV'23論文賞「Fighting of Gods」! Meta Divide Everything と ControlNet が共同で選ばれました、審査員を驚かせた記事がもう 1 つありました
Oct 04, 2023 pm 08:37 PM
フランスのパリで開催されたコンピュータービジョンのトップカンファレンス「ICCV2023」が閉幕しました。今年の論文賞はまさに「神と神の戦い」です。たとえば、最優秀論文賞を受賞した 2 つの論文には、ヴィンセント グラフ AI の分野を覆す研究である ControlNet が含まれていました。 ControlNet はオープンソース化されて以来、GitHub で 24,000 個のスターを獲得しています。拡散モデルであれ、コンピュータ ビジョンの全分野であれ、この論文の賞は当然のことです。最優秀論文賞の佳作は、同じく有名なもう 1 つの論文、Meta の「Separate Everything」「Model SAM」に授与されました。 「Segment Everything」は、発売以来、後発のものも含め、さまざまな画像セグメンテーション AI モデルの「ベンチマーク」となっています。
 NeRFと自動運転の過去と現在、10本近くの論文をまとめました!
Nov 14, 2023 pm 03:09 PM
NeRFと自動運転の過去と現在、10本近くの論文をまとめました!
Nov 14, 2023 pm 03:09 PM
Neural Radiance Fieldsは2020年に提案されて以来、関連論文の数が飛躍的に増加し、3次元再構成の重要な分野となっただけでなく、自動運転の重要なツールとして研究の最前線でも徐々に活発になってきています。 NeRF は、過去 2 年間で突然出現しました。その主な理由は、特徴点の抽出とマッチング、エピポーラ幾何学と三角形分割、PnP とバンドル調整、および従来の CV 再構成パイプラインのその他のステップをスキップし、メッシュ再構成、マッピング、ライト トレースさえもスキップするためです。 、2D から直接入力画像を使用して放射線野を学習し、実際の写真に近いレンダリング画像が放射線野から出力されます。言い換えれば、ニューラル ネットワークに基づく暗黙的な 3 次元モデルを指定されたパースペクティブに適合させます。
 紙のイラストも拡散モデルを使用して自動生成でき、ICLR にも受け入れられます。
Jun 27, 2023 pm 05:46 PM
紙のイラストも拡散モデルを使用して自動生成でき、ICLR にも受け入れられます。
Jun 27, 2023 pm 05:46 PM
生成 AI は人工知能コミュニティに旋風を巻き起こし、個人も企業も、Vincent 写真、Vincent ビデオ、Vincent 音楽など、関連するモーダル変換アプリケーションの作成に熱心になり始めています。最近、ServiceNow Research や LIVIA などの科学研究機関の数人の研究者が、テキストの説明に基づいて論文内のグラフを生成しようとしました。この目的のために、彼らは FigGen の新しい手法を提案し、関連する論文も TinyPaper として ICLR2023 に掲載されました。絵用紙のアドレス: https://arxiv.org/pdf/2306.00800.pdf 絵用紙のチャートを生成するのは何がそんなに難しいのかと疑問に思う人もいるかもしれません。これは科学研究にどのように役立ちますか?
 チャットのスクリーンショットから AI レビューの隠されたルールが明らかになります。 AAAI 3000元は強力に受け入れられますか?
Apr 12, 2023 am 08:34 AM
チャットのスクリーンショットから AI レビューの隠されたルールが明らかになります。 AAAI 3000元は強力に受け入れられますか?
Apr 12, 2023 am 08:34 AM
AAAI 2023 の論文提出期限が近づいていたとき、AI 投稿グループの匿名チャットのスクリーンショットが突然 Zhihu に表示されました。そのうちの1人は、「3,000元で強力なサービスを提供できる」と主張した。このニュースが発表されるとすぐに、ネットユーザーの間で国民の怒りを引き起こした。ただし、まだ急ぐ必要はありません。 Zhihuのボス「Fine Tuning」は、これはおそらく単に「言葉による喜び」である可能性が高いと述べた。 『ファイン・チューニング』によると、挨拶や集団犯罪はどの分野でも避けられない問題だという。 openreview の台頭により、cmt のさまざまな欠点がますます明らかになり、小さなサークルが活動できる余地は将来的には小さくなるでしょうが、余地は常にあります。これは個人の問題であり、投稿システムや仕組みの問題ではないからです。オープンRの紹介
 CVPR 2023 ランキング発表、採択率は 25.78%! 2,360 件の論文が受理され、投稿数は 9,155 件に急増しました。
Apr 13, 2023 am 09:37 AM
CVPR 2023 ランキング発表、採択率は 25.78%! 2,360 件の論文が受理され、投稿数は 9,155 件に急増しました。
Apr 13, 2023 am 09:37 AM
ちょうど今、CVPR 2023 が次のような記事を発表しました: 今年は記録的な 9,155 件の論文 (CVPR2022 より 12% 増) を受け取り、2,360 件の論文を受理し、受理率は 25.78% でした。統計によると、CVPRへの投稿数は2010年から2016年の7年間で1,724件から2,145件に増加しただけです。 2017年以降は急上昇して高度成長期に入り、2019年には初めて5,000件を超え、2022年には投稿数が8,161件に達した。ご覧のとおり、今年は合計 9,155 件の論文が投稿され、確かに記録を樹立しました。流行が緩和された後、今年のCVPRサミットはカナダで開催される予定だ。今年はシングルトラックカンファレンスとなり、従来の口頭選考は中止される。グーグルリサーチ
 中国チームが最優秀論文賞と最優秀システム論文賞を受賞し、CoRLの研究成果が発表されました。
Nov 10, 2023 pm 02:21 PM
中国チームが最優秀論文賞と最優秀システム論文賞を受賞し、CoRLの研究成果が発表されました。
Nov 10, 2023 pm 02:21 PM
2017 年に初めて開催されて以来、CoRL はロボット工学と機械学習の交差点における世界トップクラスの学術会議の 1 つになりました。 CoRL は、理論と応用を含むロボット工学、機械学習、制御などの複数のトピックをカバーするロボット学習研究のための単一テーマのカンファレンスであり、2023 年 CoRL カンファレンスは 11 月 6 日から 9 日まで米国アトランタで開催されます。公式データによると、今年は25か国から199本の論文がCoRLに選ばれた。人気のあるトピックには、演算、強化学習などが含まれます。 CoRLはAAAIやCVPRといった大規模なAI学会に比べて規模は小さいものの、今年は大型モデル、身体化知能、ヒューマノイドロボットなどの概念の人気が高まる中、関連研究も注目されるだろう。
 Microsoft の新しいホット ペーパー: Transformer が 10 億トークンに拡大
Jul 22, 2023 pm 03:34 PM
Microsoft の新しいホット ペーパー: Transformer が 10 億トークンに拡大
Jul 22, 2023 pm 03:34 PM
誰もが独自の大規模モデルのアップグレードと反復を継続するため、コンテキスト ウィンドウを処理する LLM (大規模言語モデル) の能力も重要な評価指標になりました。たとえば、スター モデル GPT-4 は 32,000 のトークンをサポートしており、これは 50 ページのテキストに相当します。OpenAI の元メンバーによって設立された Anthropic は、Claude のトークン処理能力を 100,000 (約 75,000 ワード) に増加させました。 「ハリー・ポッター」をワンクリックで要約するのと同じ「まず。 Microsoft の最新の調査では、今回は Transformer を 10 億トークンまで直接拡張しました。これにより、コーパス全体やインターネット全体を 1 つのシーケンスとして扱うなど、非常に長いシーケンスをモデル化するための新しい可能性が開かれます。比較のため、一般的な
