

コンテキスト長を 256k に拡張します。LongLLaMA の無制限コンテキスト バージョンは登場しますか?

今年 2 月、Meta は LLaMA 大規模言語モデル シリーズをリリースし、オープンソース チャット ロボットの開発を促進することに成功しました。 LLaMA は、以前にリリースされた多くの大規模モデル (パラメーターの数は 70 億から 650 億の範囲) よりもパラメーターが少ないですが、パフォーマンスが優れているためです。たとえば、650 億のパラメーターを持つ最大の LLaMA モデルは、Google の Chinchilla-70B および PaLM に匹敵します。 -540B. 、公開されると多くの研究者が興奮しました。
ただし、LLaMA は学術研究者による使用のみにライセンスされているため、モデルの商用利用は制限されています。
したがって、研究者は商業目的で使用できる LLaMA を探し始めました。カリフォルニア大学バークレー校の博士課程の学生 Hao Liu 氏が始めたプロジェクト OpenLLaMA は、最も人気のあるプロジェクトの 1 つです。 LLaMA のオープン ソース コピー。元の LLaMA とまったく同じ前処理とトレーニング ハイパーパラメータを使用することで、OpenLLaMA は LLaMA のトレーニング ステップに完全に従っていると言えます。最も重要なのは、このモデルが市販されているということです。
OpenLLaMA は Together によってリリースされた RedPajama データ セットでトレーニングされました。3 つのモデル バージョン、つまり 3B、7B、13B があります。これらのモデルは 1T トークンでトレーニングされています。結果は、OpenLLaMA のパフォーマンスが、複数のタスクにおいて元の LLaMA のパフォーマンスと同等かそれを上回ることを示しています。
研究者は、新しいモデルを継続的にリリースすることに加えて、トークンを処理するモデルの能力を常に調査しています。
数日前、Tian Yuandong チームによる最新の研究により、1000 ステップ未満の微調整で LLaMA コンテキストが 32K まで拡張されました。さらに遡ると、GPT-4 は 32,000 のトークン (50 ページのテキストに相当) をサポートし、クロードは 100,000 のトークン (ワンクリックで「ハリー・ポッター」の最初の部分を要約するのにほぼ相当) を処理できます。
OpenLLaMA に基づく新しい大規模言語モデルが登場し、コンテキストの長さが 256,000 トークン以上に拡張されます。この研究は、IDEAS NCBR、ポーランド科学アカデミー、ワルシャワ大学、Google DeepMind によって共同で完了しました。
 写真
写真
LongLLaMA は OpenLLaMA をベースに完成しており、微調整方法には FOT (Focused Transformer) が使用されています。この論文では、FOT を使用して既存の大規模モデルを微調整し、コンテキストの長さを延長できることを示します。
この研究では、OpenLLaMA-3B モデルと OpenLLaMA-7B モデルを開始点として使用し、FOT を使用してそれらを微調整します。 LONGLLAMA と呼ばれる結果のモデルは、トレーニング コンテキストの長さを超えて (最大 256K まで) 外挿することができ、コンテキストの短いタスクでもパフォーマンスを維持できます。
- プロジェクト アドレス: https://github.com/CStanKonrad/long_llama
- 論文アドレス: https://arxiv. org/pdf/2307.03170.pdf
この研究を OpenLLaMA の無限コンテキスト バージョンと表現する人もいます。FOT を使用すると、モデルは次のようなより長いシーケンスに簡単に外挿できます。 8K トークンでトレーニングされたモデルは、256K ウィンドウ サイズに簡単に外挿できます。
 図
図
この記事では、Transformer モデルのプラグ アンド プレイ拡張機能である FOT メソッドを使用します。新しいモデルをトレーニングしたり、より長いコンテキストを使用して既存の大きなモデルを微調整したりできます。
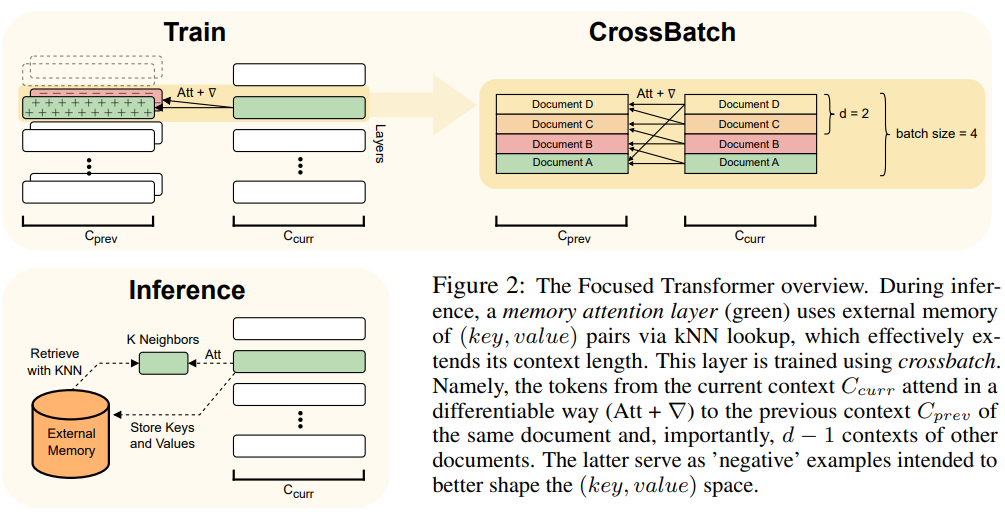
これを実現するために、FOT はメモリ アテンション レイヤーとクロスバッチ トレーニング プロセスを使用します。
- メモリ アテンション レイヤーにより、次のことが可能になります。モデルは推論時に外部メモリから情報を取得し、コンテキストを効果的に拡張します。
- クロスバッチ トレーニング プロセスにより、モデルは (key, value ) 表現、これらの表現を学習する傾向があります。メモリ アテンション レイヤーとしては非常に使いやすいです。
#FOT アーキテクチャの概要については、図 2 を参照してください:
 図
図
次の表は、LongLLaMA のモデル情報の一部を示しています:
 写真
写真
最後に、このプロジェクトは LongLLaMA も提供します。元の OpenLLaMA モデルの比較結果。
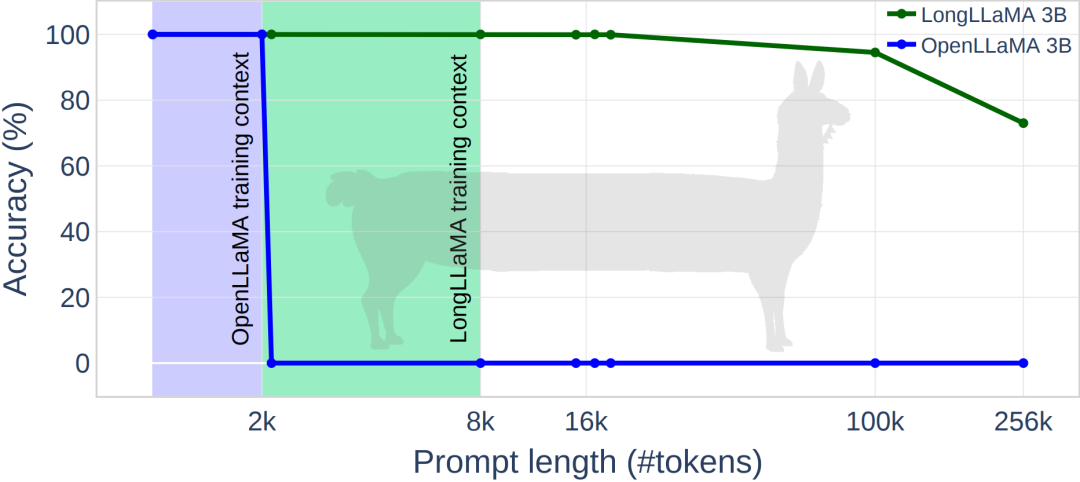
次の図は、LongLLaMA の実験結果を示しています。パスワード検索タスクでは、LongLLaMA は良好なパフォーマンスを達成しました。具体的には、LongLLaMA 3B モデルはトレーニング コンテキストの長さ 8K をはるかに超え、100k トークンに対して 94.5% の精度、256k トークンに対して 73% の精度を達成しました。
 図
図
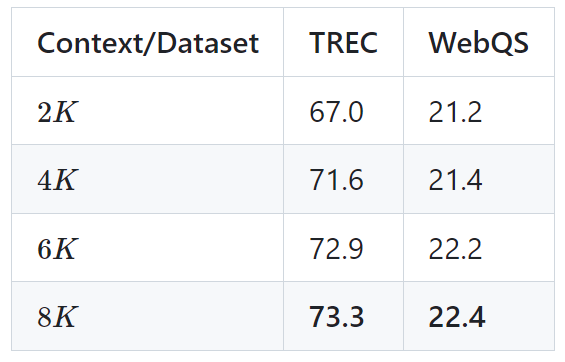
次の表は、2 つの下流タスク (TREC 質問分類と WebQS 質問) における LongLLaMA 3B モデルのパフォーマンスを示しています。回答)その結果、長いコンテキストを使用すると LongLLaMA のパフォーマンスが大幅に向上することがわかりました。
 図
図
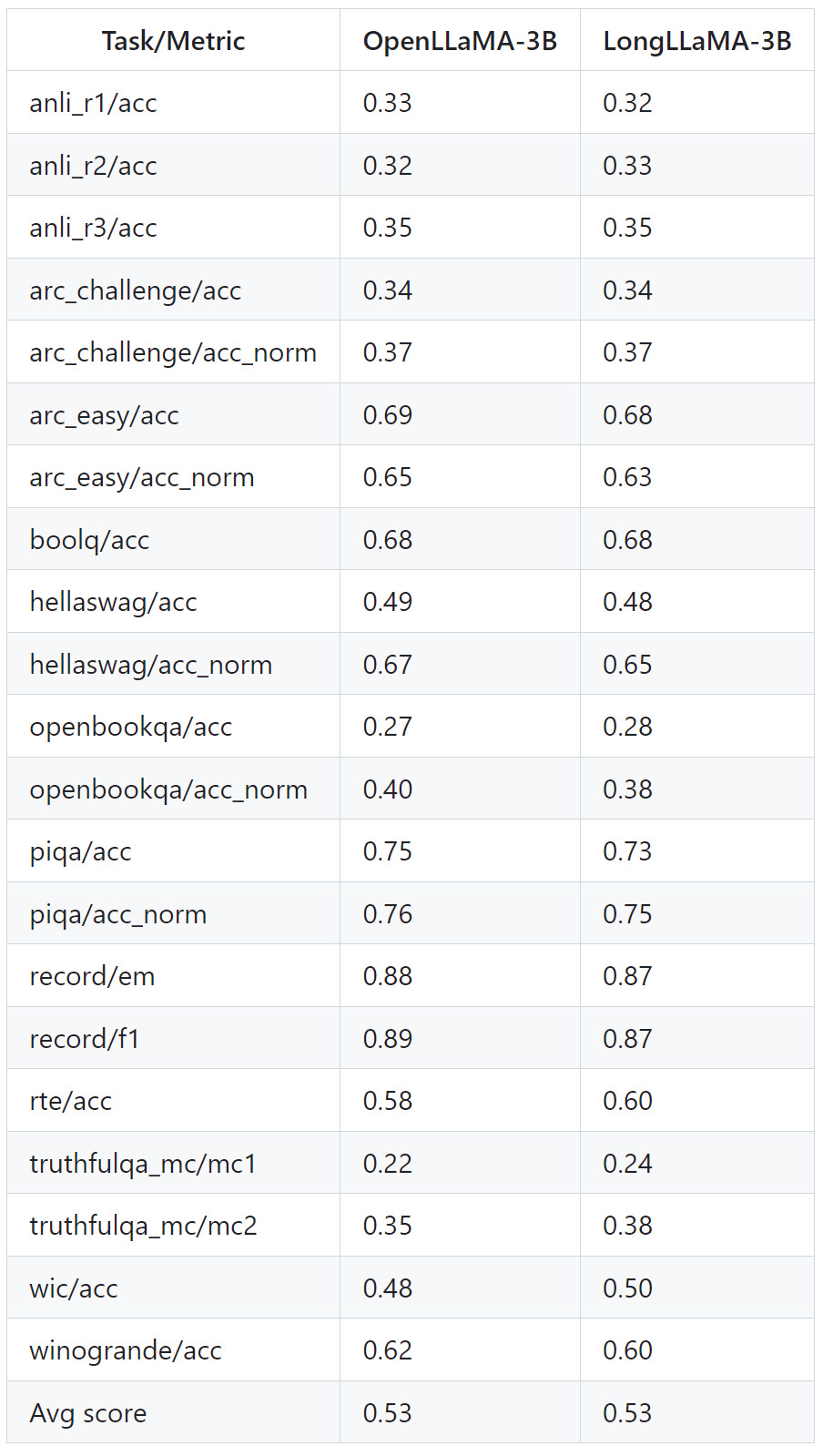
下の表は、長いコンテキストを必要としないタスクでも LongLLaMA が良好にパフォーマンスすることを示しています。実験では、ゼロサンプル設定で LongLLaMA と OpenLLaMA を比較します。
 写真
写真
詳細については、元の論文とプロジェクトを参照してください。
以上がコンテキスト長を 256k に拡張します。LongLLaMA の無制限コンテキスト バージョンは登場しますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1659
1659
 14
1415
52
1310
25
1258
29
1232
24
14
1415
52
1310
25
1258
29
1232
24

 ビットコインの価値はいくらですか
Apr 28, 2025 pm 07:42 PM
ビットコインの価値はいくらですか
Apr 28, 2025 pm 07:42 PM
ビットコインの価格は20,000ドルから30,000ドルの範囲です。 1。ビットコインの価格は2009年以来劇的に変動し、2017年には20,000ドル近くに達し、2021年にはほぼ60,000ドルに達しました。2。価格は、市場需要、供給、マクロ経済環境などの要因の影響を受けます。 3.取引所、モバイルアプリ、ウェブサイトを通じてリアルタイム価格を取得します。 4。ビットコインの価格は非常に不安定であり、市場の感情と外部要因によって駆動されます。 5.従来の金融市場と特定の関係を持ち、世界の株式市場、米ドルの強さなどの影響を受けています。6。長期的な傾向は強気ですが、リスクを慎重に評価する必要があります。
 2025年のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの1つです
Apr 28, 2025 pm 08:12 PM
2025年のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの1つです
Apr 28, 2025 pm 08:12 PM
2025年の世界の上位10の暗号通貨取引所には、Binance、Okx、Gate.io、Coinbase、Kraken、Huobi、Bitfinex、Kucoin、Bittrex、Poloniexが含まれます。これらはすべて、高い取引量とセキュリティで知られています。
 世界のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの最新バージョンです
Apr 28, 2025 pm 08:09 PM
世界のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの最新バージョンです
Apr 28, 2025 pm 08:09 PM
世界の上位10の暗号通貨取引プラットフォームには、Binance、Okx、Gate.io、Coinbase、Kraken、Huobi Global、Bitfinex、Bittrex、Kucoin、Poloniexが含まれます。これらはすべて、さまざまな取引方法と強力なセキュリティ対策を提供します。
 復号化GATE.IO戦略のアップグレード:Memebox 2.0でCrypto Asset Managementを再定義する方法は?
Apr 28, 2025 pm 03:33 PM
復号化GATE.IO戦略のアップグレード:Memebox 2.0でCrypto Asset Managementを再定義する方法は?
Apr 28, 2025 pm 03:33 PM
Memebox 2.0は、革新的なアーキテクチャとパフォーマンスのブレークスルーを通じて、暗号資産管理を再定義します。 1)3つの主要な問題点を解決します。資産サイロ、収入の減少、セキュリティと利便性のパラドックスです。 2)インテリジェントアセットハブ、動的リスク管理およびリターンエンハンスメントエンジン、クロスチェーン移動速度、平均降伏率、およびセキュリティインシデント応答速度が向上します。 3)ユーザーに、ユーザー価値の再構築を実現し、資産の視覚化、ポリシーの自動化、ガバナンス統合を提供します。 4)生態学的なコラボレーションとコンプライアンスの革新により、プラットフォームの全体的な有効性が向上しました。 5)将来的には、スマート契約保険プール、予測市場統合、AI主導の資産配分が開始され、引き続き業界の発展をリードします。
 トップ10の仮想通貨取引アプリは何ですか?最新のデジタル通貨交換ランキング
Apr 28, 2025 pm 08:03 PM
トップ10の仮想通貨取引アプリは何ですか?最新のデジタル通貨交換ランキング
Apr 28, 2025 pm 08:03 PM
Binance、OKX、Gate.ioなどの上位10のデジタル通貨交換は、システムを改善し、効率的な多様化したトランザクション、厳格なセキュリティ対策を改善しました。
 トップ通貨取引プラットフォームは何ですか?トップ10の最新の仮想通貨交換
Apr 28, 2025 pm 08:06 PM
トップ通貨取引プラットフォームは何ですか?トップ10の最新の仮想通貨交換
Apr 28, 2025 pm 08:06 PM
現在、上位10の仮想通貨交換にランクされています。1。Binance、2。Okx、3。Gate.io、4。CoinLibrary、5。Siren、6。HuobiGlobal Station、7。Bybit、8。Kucoin、9。Bitcoin、10。BitStamp。
 推奨される信頼できるデジタル通貨取引プラットフォーム。世界のトップ10のデジタル通貨交換。 2025
Apr 28, 2025 pm 04:30 PM
推奨される信頼できるデジタル通貨取引プラットフォーム。世界のトップ10のデジタル通貨交換。 2025
Apr 28, 2025 pm 04:30 PM
推奨される信頼できるデジタル通貨取引プラットフォーム:1。OKX、2。Binance、3。Coinbase、4。Kraken、5。Huobi、6。Kucoin、7。Bitfinex、8。Gemini、9。Bitstamp、10。Poloniex、これらのプラットフォームは、セキュリティ、ユーザーエクスペリエンス、ユーザーエクスペリエンス、ユーザーエクスペリエンス、ユーザーエクスペリエンスのデジタルエクスペリエンス、デジタルエクスペリエンスのデジタルエクスペリエンス、デジタルエクスペリエンスのために知られています。
 CでChronoライブラリを使用する方法は?
Apr 28, 2025 pm 10:18 PM
CでChronoライブラリを使用する方法は?
Apr 28, 2025 pm 10:18 PM
CでChronoライブラリを使用すると、時間と時間の間隔をより正確に制御できます。このライブラリの魅力を探りましょう。 CのChronoライブラリは、時間と時間の間隔に対処するための最新の方法を提供する標準ライブラリの一部です。 Time.HとCtimeに苦しんでいるプログラマーにとって、Chronoは間違いなく恩恵です。コードの読みやすさと保守性を向上させるだけでなく、より高い精度と柔軟性も提供します。基本から始めましょう。 Chronoライブラリには、主に次の重要なコンポーネントが含まれています。STD:: Chrono :: System_Clock:現在の時間を取得するために使用されるシステムクロックを表します。 STD :: Chron
