
 テクノロジー周辺機器
AI
BLIP-2 と InstructBLIP がトップ 3 にしっかりと入っています。 12の主要モデル、16のリスト、「マルチモーダル大言語モデル」の総合評価
テクノロジー周辺機器
AI
BLIP-2 と InstructBLIP がトップ 3 にしっかりと入っています。 12の主要モデル、16のリスト、「マルチモーダル大言語モデル」の総合評価
BLIP-2 と InstructBLIP がトップ 3 にしっかりと入っています。 12の主要モデル、16のリスト、「マルチモーダル大言語モデル」の総合評価

マルチモーダル大規模言語モデル (MLLM) は、LLM の豊富な知識の蓄積と、マルチモーダルな問題を解決するための強力な推論および一般化機能に依存しています。これまでにいくつかの驚くべきモデルが登場しています。絵を読む、書く、絵を見るなどの能力そしてコードを書くこと。
しかし、これらの事例のみに基づいて MLLM のパフォーマンスを完全に反映することは困難であり、MLLM の総合的な評価はまだ不足しています。
この目的を達成するために、Tencent Youtu Lab と厦門大学は、新しく作成された評価ベンチマーク MM で既存の 12 のオープンソース MLLM モデルの包括的な定量的評価を初めて実施し、16 のランキングを発表しました。知覚と認知の 2 つの一般的なリストと 14 のサブリストを含むリスト:

論文リンク: https://arxiv.org/pdf / 2306.13394.pdf
プロジェクト リンク: https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation
MLLM の既存の定量的評価手法は主に 3 つに分類されますが、いずれも一定の限界があり、パフォーマンスを完全に反映することが困難です。
最初のタイプのメソッドは、画像キャプションやビジュアル質問応答 (VQA) データセットなどの従来の公開データセットで評価されます。
しかし、一方では、これらの従来のデータセットは MLLM の新しい機能を反映するのが難しいかもしれません。他方では、大規模モデル時代のトレーニング セットはもはや存在しないため、統合されているため、これらの評価データセットを保証することは困難であり、他の MLLM によってトレーニングされていません。
2 番目の方法は、公開評価用に新しいデータを収集することですが、これらのデータは公開されていないか [1]、または数が少なすぎます (画像が 50 枚のみ) [2]。
3 番目の方法は、物体の幻覚 [3] や敵対的な堅牢性 [4] など、MLLM の特定の側面に焦点を当てており、完全に評価することはできません。
MLLM の急速な発展に合わせて、包括的な評価ベンチマークが緊急に必要とされています。研究者らは、普遍的で包括的な評価ベンチマークには次の特性が必要であると考えています。
(1) 知覚能力や認知能力を含む、可能な限り多くの範囲をカバーする必要があります。前者は、オブジェクトの存在、量、場所、色などを識別することを指します。後者は、より複雑な推論を実行するために、LLM に感覚情報と知識を統合することを指します。前者は後者の基礎です。
(2) データ漏洩のリスクを軽減するために、データまたは注釈は既存の公開データセットの使用をできる限り避けるべきです。
(3) 指示はできる限り簡潔で、人間の認知習慣と一致している必要があります。異なる命令設計はモデルの出力に大きな影響を与える可能性がありますが、公平性を確保するためにすべてのモデルは統一された簡潔な命令に基づいて評価されます。優れた MLLM モデルは、即時エンジニアリングに陥ることを避けるために、そのような簡潔な指示に一般化する機能を備えている必要があります。
(4) この簡潔な指示に基づく MLLM の出力は、定量的な統計にとって直感的で便利なものである必要があります。 MLLM の無制限の回答は、量的統計に大きな課題をもたらします。既存の方法では GPT または手動スコアリングを使用する傾向がありますが、不正確さや主観性の問題に直面する可能性があります。
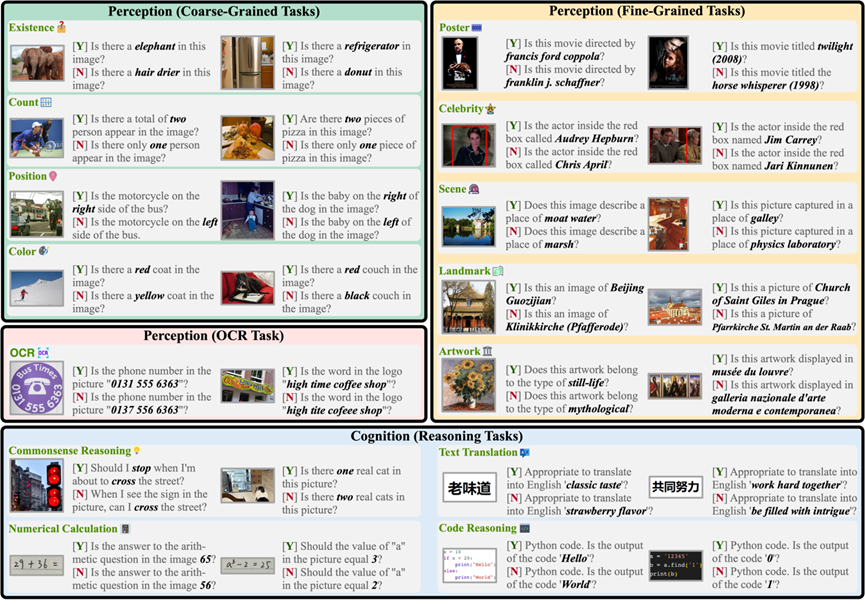
# 図 1. MME 評価ベンチマークの例。各絵は 2 つの質問に対応しており、答えはそれぞれ Yes[Y] と No[N] です。質問と「はいまたはいいえで答えてください」を合わせてコマンドを形成します。
上記の理由に基づいて、上記の 4 つの特性を同時に備えた新しい MLLM 評価ベンチマーク MME が構築されました。 1. MME 知覚能力と認知能力は同時に評価されます。 OCR に加えて、センシング機能には、粗粒度および細粒度のターゲット認識が含まれます。前者は、オブジェクトの存在、数量、位置、色を識別します。後者は、映画のポスター、有名人、シーン、ランドマーク、アートワークを識別します。認知能力には、常識的な推論、数値計算、テキストの翻訳、およびコードの推論が含まれます。図 1 に示すように、サブタスクの総数は 14 に達します。
2. MME のすべてのコマンドと応答のペアは手動で構築されます。使用されるいくつかの公開データセットでは、元のアノテーションに依存せずに画像のみが使用されます。同時に、研究者は手動による写真撮影や画像生成を通じてデータを収集することにも全力を尽くしています。
3. MME 命令は、モデル出力に対するプロンプト エンジニアリングの影響を避けるために、できる限り簡潔になるように設計されています。研究者らは、優れた MLLM は、このような簡潔で頻繁に使用される命令を一般化する必要があり、これはすべてのモデルにとって公平であると繰り返しています。各サブタスクの手順を図 1 に示します。
4. 「はいかいいえで答えてください」という命令設計により、モデルが出力する「はい」「いいえ」をもとに定量的な統計を簡単に行うことができます。正確さと客観性を同時に確保できます。研究者らが多肢選択式の質問に対する指示を設計しようとしたことも注目に値しますが、現在の MLLM ではそのような複雑な指示に従うのはまだ難しいことが判明しました。
研究者らは、BLIP-2 [5]、LLaVA [6]、MiniGPT-4 [7]、mPLUG-Owl [2]、 LLaMA-Adapter-v2 [8]、Otter [9]、Multimodal-GPT [10]、InstructBLIP [11]、VisualGLM-6B [12]、PandaGPT [13]、ImageBind-LLM [14]、および LaVIN [15] 。
精度、精度、スコアを含む 3 つの統計指標があります。各タスクの精度は質問の統計に基づいており、精度は画像の統計に基づいており (画像に対応する両方の質問に正しく答える必要があります)、スコアは精度と精度の合計です。
知覚の合計スコアは 10 個の知覚サブタスクのスコアの合計であり、認知の合計スコアは 4 つの認知タスクのスコアの合計です。詳細についてはプロジェクトのリンクを参照してください。
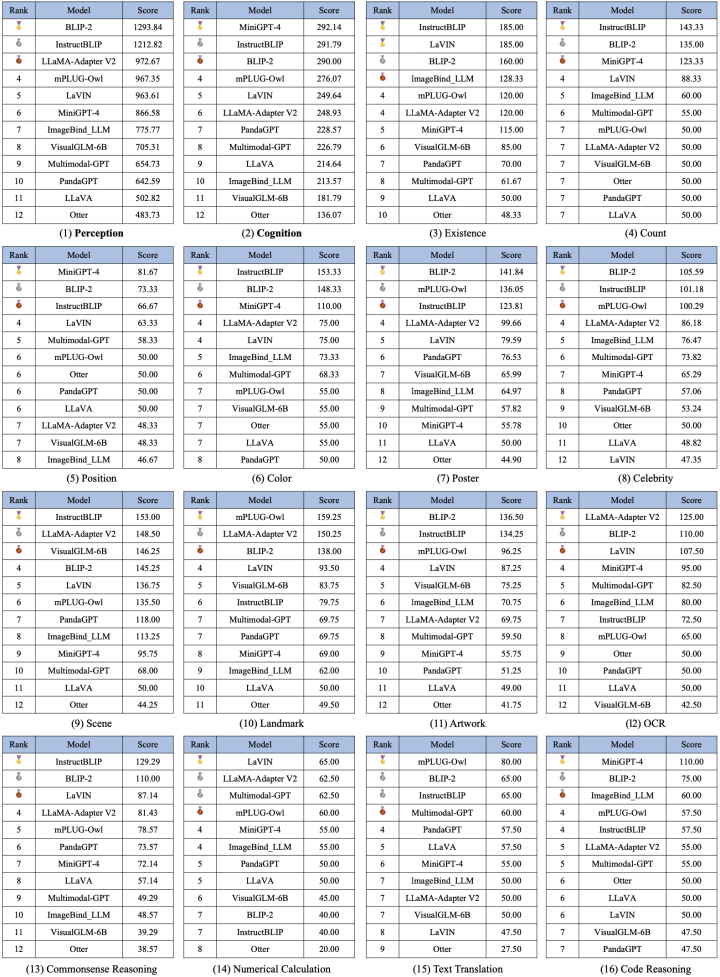
#14 のサブタスクにおける 12 のモデルのテストの比較を図 2 に示します。 2. 14 のサブタスクにおける 12 のモデルの比較。各サブタスクの満点は 200 点です。
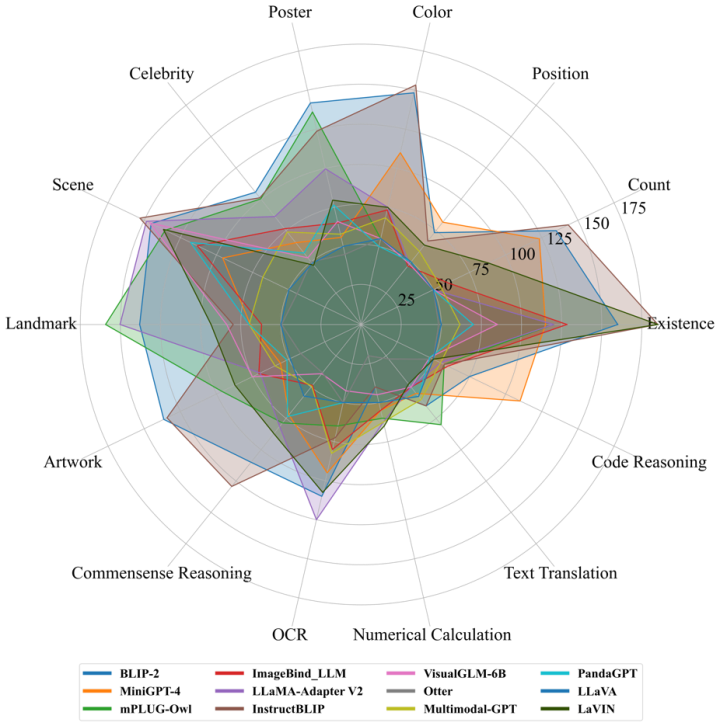 知覚および認知カテゴリの全体リストと 14 のサブタスクのリストを含む、合計 16 のリストも公開されました。 2 つの全体的なリストをそれぞれ図 3 と図 4 に示しますが、注目に値するのは、BLIP-2 と InstructBLIP がどちらのリストでも上位 3 位に入っていることです。
知覚および認知カテゴリの全体リストと 14 のサブタスクのリストを含む、合計 16 のリストも公開されました。 2 つの全体的なリストをそれぞれ図 3 と図 4 に示しますが、注目に値するのは、BLIP-2 と InstructBLIP がどちらのリストでも上位 3 位に入っていることです。
#図
図 3. 認識タスクの全体リスト
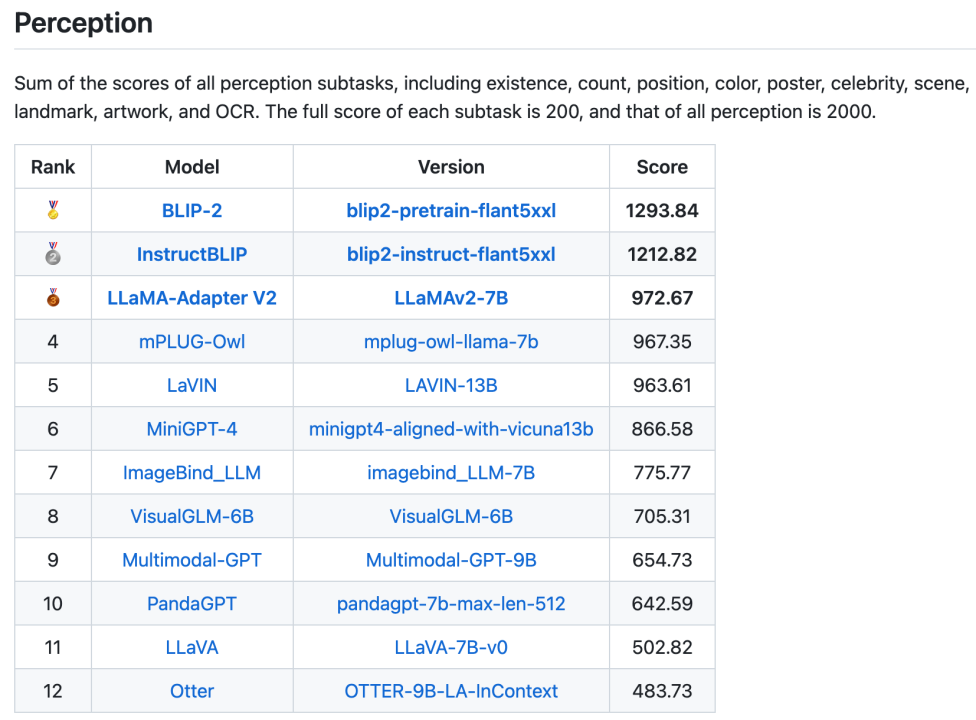
図 4. 認知タスクの全体リスト
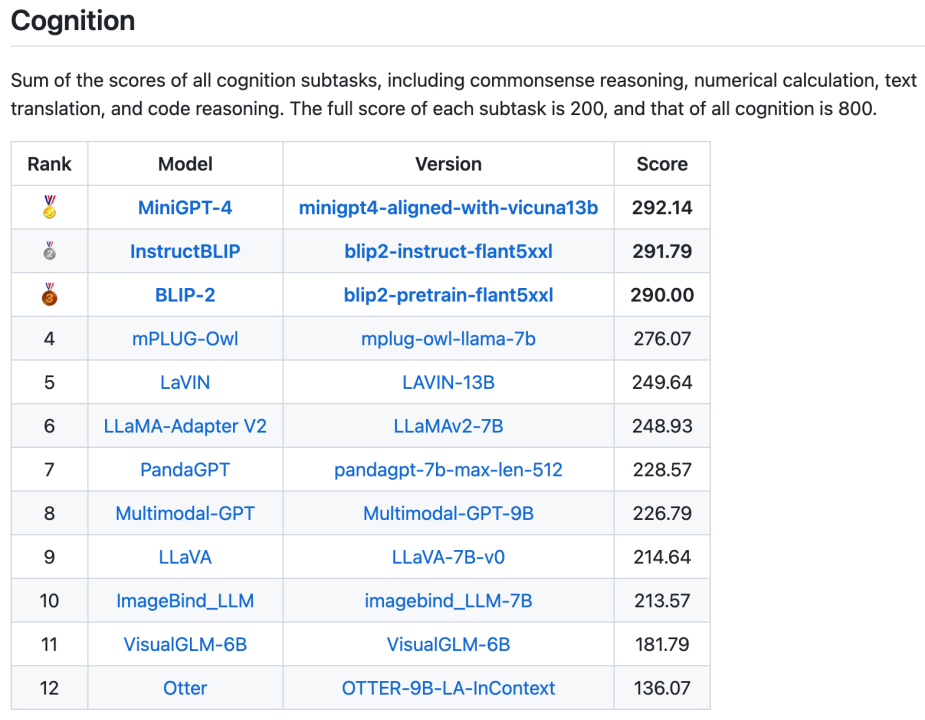 ##図 5. すべてのリスト
##図 5. すべてのリスト
さらに、研究者らは、図 6 に示すように、実験で MLLM モデルによって明らかになったいくつかの一般的な問題も要約し、その後のモデル最適化の指針となることを期待しています。
図
図 6. MLLM によって明らかにされる一般的な問題。 [Y]/[N] は、実際の答えが Yes/No であることを意味します。 [R] は MLLM によって生成された答えです。
#最初の問題は、指示に従わないことです。 
非常に簡潔な指示設計が採用されていますが、MLLM には指示に従うのではなく質問に答える自由がまだあります。
図 6 の最初の行に示すように、コマンドには「はいまたはいいえで答えてください」と記載されていますが、MLLM は宣言的な答えしか与えませんでした。回答の先頭に「はい」または「いいえ」が表示されない場合は不正解と判断します。優れた MLLM は、特に命令を微調整した後、このような単純な命令に一般化できる必要があります。 #2 番目の問題は、認識の欠如です。
図 6 の 2 行目に示すように、MLLM は最初の画像のバナナの数と 2 番目の画像の番号を誤って識別し、その結果、不正解の場合。研究者らはまた、同じ画像に対する 2 つの指示が 1 単語だけ異なると、まったく異なる知覚結果が得られるため、知覚パフォーマンスは指示の変更によって容易に影響を受けることにも気づきました。
3 番目の問題は、推論能力の欠如です。
図 6 の 3 行目に示されているように、赤いテキストから、MLLM は最初の写真がオフィス スペースではないことをすでに知っていることがわかりますが、それでも「はい」という不正解でした。
同様に、2 番目の図では、MLLM は正しい算術結果を計算しましたが、最終的には間違った答えも出しました。 「段階的に考えてみましょう」などの思考連鎖のプロンプトを追加すると、より良い結果が得られる可能性があります。この分野でのより詳細な研究が期待されます。
4 番目の質問は、コマンドのオブジェクト ビジョンに続きます。図 6 の 4 行目に示されているように、命令に画像内に存在しないオブジェクトが含まれている場合、MLLM はそのオブジェクトが存在すると想定し、最終的に「はい」と回答します。
常に「はい」と答えるこのアプローチでは、精度は 50% に近く、精度は 0 に近くなります。これは、対象の幻覚を抑制することの重要性を示しており、MLLM によって生成された回答の信頼性についてさらに考える必要もあります。
以上がBLIP-2 と InstructBLIP がトップ 3 にしっかりと入っています。 12の主要モデル、16のリスト、「マルチモーダル大言語モデル」の総合評価の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。
人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1672
1672
 14
1428
52
1332
25
1277
29
1256
24
14
1428
52
1332
25
1277
29
1256
24

 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
