

Tencent TRS のメタ学習とクロスドメイン レコメンデーションの業界実践


1. メタ学習
##1. パーソナライズされたモデリングの問題点##推奨シナリオでは、28-20 のデータ分散の問題が発生します。シナリオの 20% がサンプルの 80% を適用するため、問題が発生します。単一モデルの方が使いやすいということです。大規模シナリオの推定まで。さまざまなシナリオを考慮してモデルのパーソナライゼーション機能を向上させる方法は、パーソナライズされたモデリングにおける課題です。 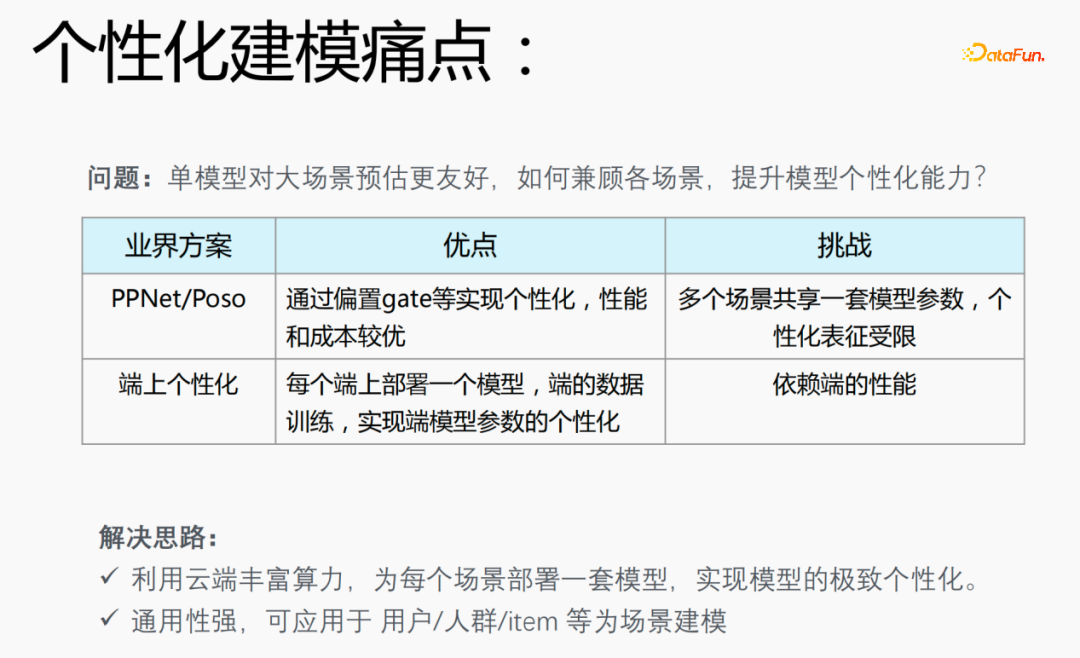
業界ソリューション:
PPNet/Poso: オフセットゲートなどによりパーソナライゼーションを実現し、性能とコストは向上しますが、複数のシナリオはモデル パラメーターのセットを共有しており、パーソナライズされた表現は制限されています。- エンドオンエンドのパーソナライゼーション: 各エンドにモデルをデプロイし、エンドのリアルタイム データをトレーニングに使用して、エンド エンドのパーソナライゼーションを実現します。 -end モデルパラメータですが、端末の性能に依存し、モデルを特に大きくすることはできないため、トレーニングには小さなモデルを使用する必要があります。
- #インダストリ モデルに存在する問題を考慮して、次の解決策を提案しました。
クラウドの豊富なコンピューティング能力を利用して、シナリオごとに一連のモデルをデプロイし、モデルの究極のパーソナライゼーションを実現します。
- モデルは次のとおりです。汎用性が高く、ユーザー/群集/アイテムなどのパーソナライズされたモデリング シナリオに適用できます。
- #2. メタ学習はモデルのパーソナライゼーションの問題を解決します

- ソリューションの選択: 一連のモデルがユーザーごとにデプロイされている場合、モデルの構造とモデルのパラメーターが異なるため、モデルのトレーニングとサービスに問題が発生します。コストは比較的高いです。モデルのパーソナライゼーションの問題を解決するために、同じモデル構造の下で各シナリオにパーソナライズされたモデル パラメーターを提供することを検討します。
- デプロイメント場所: モデルをクラウド上にデプロイし、クラウド上の豊富なコンピューティング能力を計算に使用すると同時に、モデルをクラウド上で柔軟に制御したい。クラウド上のモデル。
- アルゴリズムのアイデア: 従来のメタ学習は、少数のサンプルとコールド スタートの問題を解決します。アルゴリズムを完全に理解することで、レコメンデーションの分野で、モデルの極端なパーソナライゼーションの問題を解決するためのメタ学習イノベーションの使用。
- 全体的なアイデアは、メタ学習を使用して各ユーザーにパーソナライズされたモデル パラメーターのセットをクラウドに展開し、最終的には損失のない効果を達成することです。コストとパフォーマンス。
3. メタ学習の紹介
メタ学習とは学習を指します 一般的な知識が使用されます新しいタスクのアルゴリズムをガイドし、ネットワークに迅速な学習機能を提供します。例: 上の図の分類タスク: 猫と鳥、花と自転車。この分類タスクを K ショート N クラス分類タスクとして定義し、メタ学習を通じて分類知識を学習することを期待しています。微調整を推定するプロセスでは、犬やカワウソなどの分類タスクでは、微調整が非常に少ないサンプルで最終的な推定効果を達成できることを期待しています。また、四則混合演算を学ぶ場合、まず足し算と引き算、次に掛け算と割り算を学び、この二つの知識を習得すると、二つの知識を組み合わせて計算する方法を学ぶことができます。 、減算、乗算、除算を個別に計算するのではなく、加算、減算、乗算、除算に基づいて、最初に乗算と除算、次に加算と減算の演算ルールを学習し、次にいくつかのサンプルを使用してこれをトレーニングします。このルールをすぐに理解するために、ルールを使用します。これにより、新しい推定でデータに関してより良い結果が得られます。メタ学習の考え方もこれに似ています。 
従来の学習手法は、すべてのデータに対して最適な θ、つまり大域的に最適な θ を学習することを目的としています。メタ学習では、タスクをシーン内の一般的な 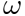 を学習する次元として捉え、損失はすべてのシーンで最適なレベルに達することができます。従来の学習方法で学習された θ は、大きなシーンでは群衆に近く、大きなシーンではより良い予測が得られ、ロングテール予測には平均的な効果があります。メタ学習とは、各シーンで類似した点を学習し、それを使用することです。各シーン データまたは新しいシーン データは、この時点で微調整され、各シーンに最適なポイントが得られます。したがって、最終的なパーソナライゼーションの目標を達成するために、各シナリオでパーソナライズされたモデル パラメーターを構築することが可能です。上記の例では群衆をメタ学習のタスクとして使用していますが、ユーザーやアイテムをモデリングのタスクとして使用することもできます。
を学習する次元として捉え、損失はすべてのシーンで最適なレベルに達することができます。従来の学習方法で学習された θ は、大きなシーンでは群衆に近く、大きなシーンではより良い予測が得られ、ロングテール予測には平均的な効果があります。メタ学習とは、各シーンで類似した点を学習し、それを使用することです。各シーン データまたは新しいシーン データは、この時点で微調整され、各シーンに最適なポイントが得られます。したがって、最終的なパーソナライゼーションの目標を達成するために、各シナリオでパーソナライズされたモデル パラメーターを構築することが可能です。上記の例では群衆をメタ学習のタスクとして使用していますが、ユーザーやアイテムをモデリングのタスクとして使用することもできます。
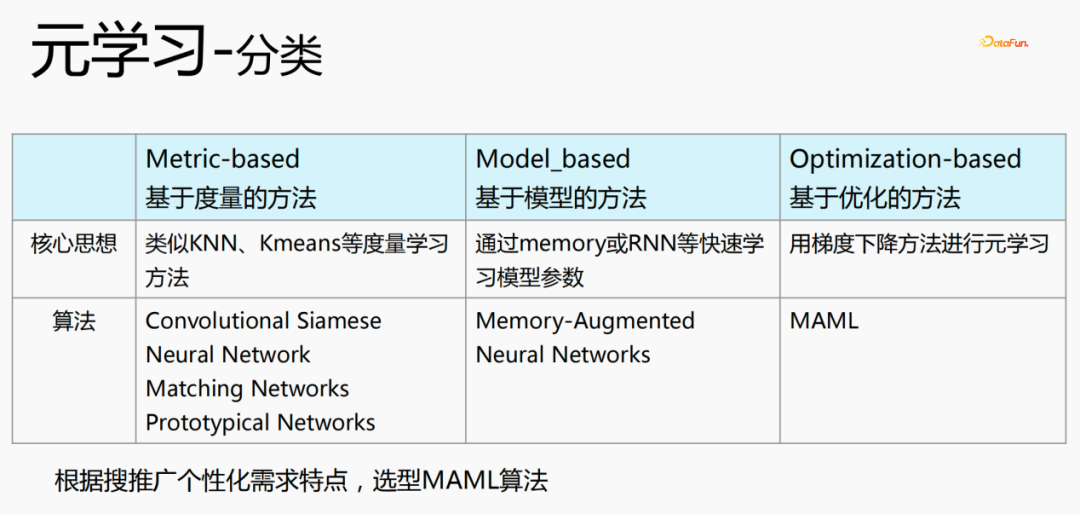
メタ学習には 3 つの分類があります:
- Metric-ベースの手法 ( Metric-based): KNN や K-means などの計量学習手法を使用して、新しいシーンと既存のシーンの間の距離を学習し、それらがどのカテゴリに属するかを推定します。代表的なアルゴリズムには、畳み込みシャム、ニューラル ネットワーク、マッチング ネットワーク、
- # モデルベースの手法 (Model_based): メモリや RNN などを通じてモデルのパラメータを迅速に学習します。代表的なアルゴリズムは次のとおりです。ニューラルネットワーク
- 最適化ベース法 (Optimization-based): 近年よく使われる手法で、勾配降下法を用いて損失を計算します。最適なパラメータは、パーソナライズされたモデリングに現在使用されているアルゴリズム MAML を表します。

meta-train には初期化 θ があり、シーン サンプリングとフィールド内サンプル サンプリングの 2 つのサンプリングを実行します。最初のステップはシーン サンプリングです。サンプリング プロセスのこのラウンドでは、合計サンプルには数十万、さらには数百万のタスクが含まれており、数百万のタスクから n 個のタスクがサンプリングされます。第 2 ステップでは、各シーンでバッチサイズのサンプルをサンプリングします。このシーンでは、バッチサイズのサンプルを 2 つの部分に分割し、1 つの部分はサポート セット、もう 1 つの部分はクエリ セットです。サポート セットを使用して、確率的勾配降下法を使用して各シーンのシータを更新します。3 番目のステップでは、クエリ セットを使用します。セットは損失を計算します。シーンごとに、4 番目のステップで、すべての損失を加算し、勾配を θ に戻します。終了条件が満たされるまで、複数ラウンドの計算が全体として実行されます。
このうち、Support Set はトレーニング セット、Query Set は検証セットとして理解できます。
 #Finetune プロセスはメタトレイン プロセスに非常に近く、θ を特定のシーンに配置すると、そのシーンのサポート セットが取得されます。 、勾配降下法 (SGD) が使用され、シーン
#Finetune プロセスはメタトレイン プロセスに非常に近く、θ を特定のシーンに配置すると、そのシーンのサポート セットが取得されます。 、勾配降下法 (SGD) が使用され、シーン
の最適なパラメーターを取得します。 を使用して、サンプル (クエリ セット) の推定結果を生成します。タスクシーンで採点されます。
を使用して、サンプル (クエリ セット) の推定結果を生成します。タスクシーンで採点されます。 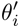 5. メタ学習の産業化への挑戦
5. メタ学習の産業化への挑戦
 メタ学習アルゴリズムを産業シナリオに適用すると、メタ学習アルゴリズムのメタトレイン プロセスには、シーン サンプリングとサンプル サンプリングという 2 つのサンプリングが含まれます。サンプルの場合、サンプルを整理してシーン順に保存して処理する必要があり、同時にサンプルとシーンの対応関係を記憶する辞書テーブルも必要となり、この処理に多くの時間を費やします。同時に、サンプルを従業員が消費するために使用することは、産業シナリオにとって非常に大きな課題となります。
メタ学習アルゴリズムを産業シナリオに適用すると、メタ学習アルゴリズムのメタトレイン プロセスには、シーン サンプリングとサンプル サンプリングという 2 つのサンプリングが含まれます。サンプルの場合、サンプルを整理してシーン順に保存して処理する必要があり、同時にサンプルとシーンの対応関係を記憶する辞書テーブルも必要となり、この処理に多くの時間を費やします。同時に、サンプルを従業員が消費するために使用することは、産業シナリオにとって非常に大きな課題となります。
次のソリューションがあります:
- 解決策 1: メタトレーニング バッチ内でサンプル選択を実行します。同時に、数千万のモデル トレーニングに対して、メタ学習サンプルの編成をサポートするように無限フレームワークを変更します。数千万の大規模モデルのトレーニング。従来のモデルのデプロイ方法では、すべてのシナリオで一連のモデルをデプロイしますが、これにより、モデルのサイズが数千万個という非常に大きくなり、トレーニングとサービスのコストが増加します。調整して使用してリリースする方法を使用して、モデル パラメーターのセットを 1 つだけ保存します。これにより、モデル サイズの増加を回避できます。同時に、パフォーマンスを節約するために、コアネットワーク部分のみを調査します。
- #解決策 2: 提供プロセス中に微調整を実行します。従来のサンプル ストレージ リンクではサンプルのメンテナンス コストが高くなります。そのため、従来の方法を放棄し、メタ学習の入力として中間層のデータのみを保存します。
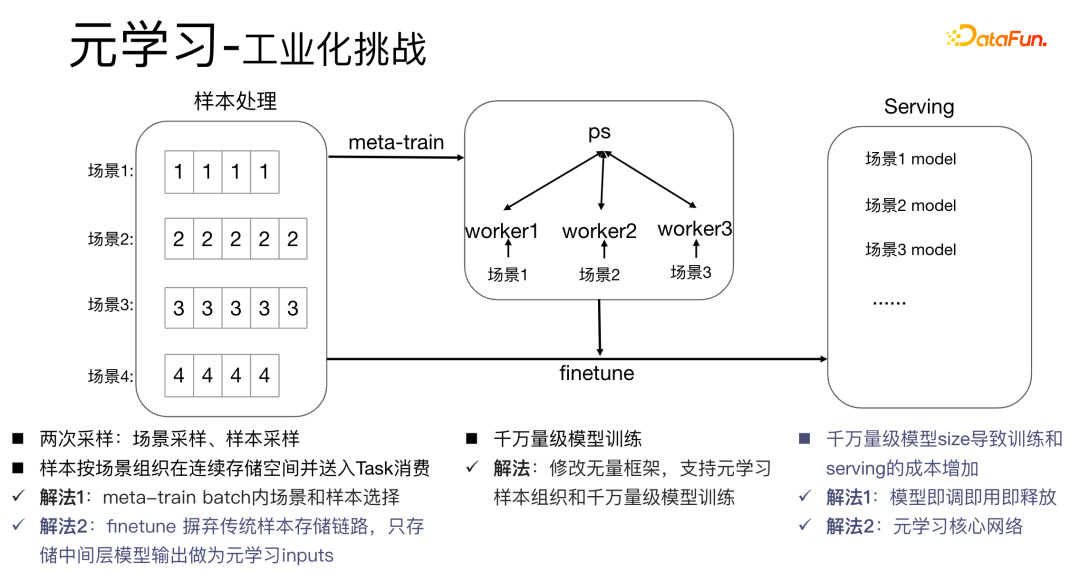
6. メタ学習スキーム
最初のメタトレーニングバッチ内のシーンとサンプルの選択を実現するには、各バッチに複数のデータがあり、各データはタスクに属します。バッチ内では、これらのデータがタスクに従って抽出され、抽出されたサンプルがメタトレイン トレーニング プロセスに投入されるため、シーン選択とサンプル選択のための処理リンクのセットを個別に維持する必要があるという問題が解決されます。

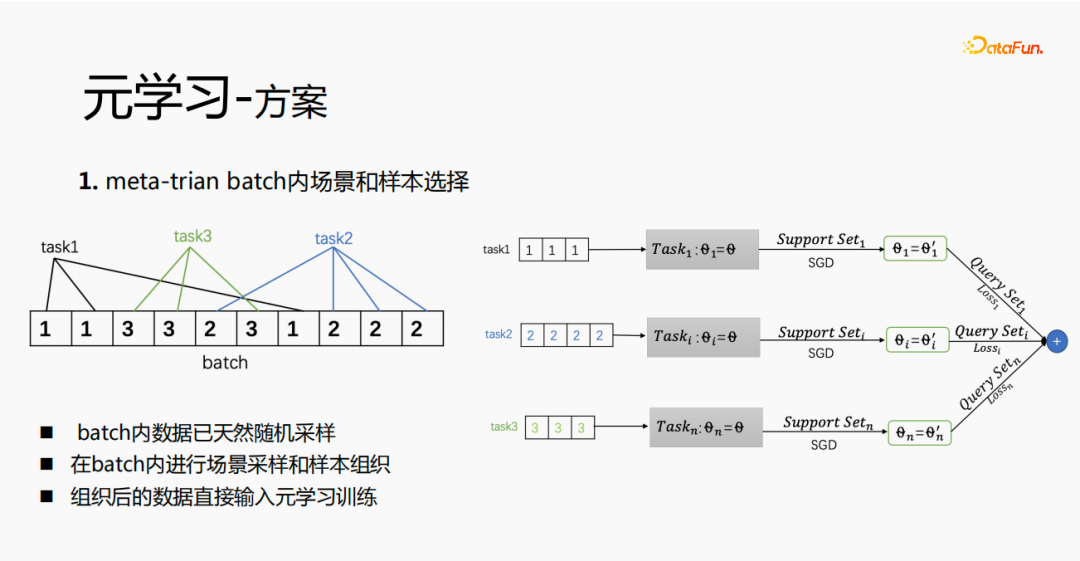
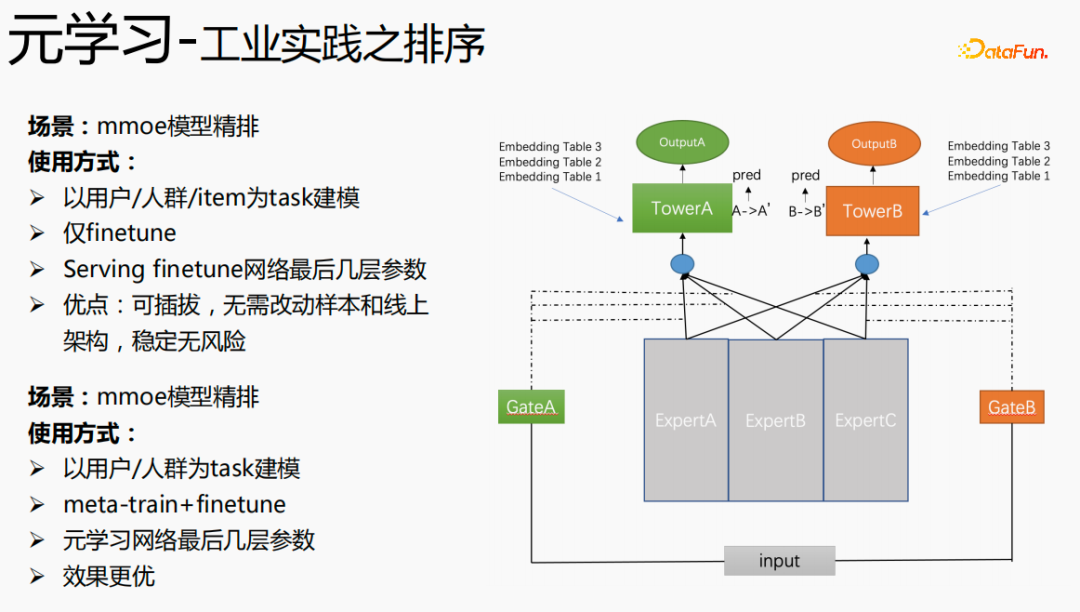
実験研究と論文の読書を通じて、微調整とメタ学習プロセスにおいて、予測層に近づくほど、モデルが優れているほど、予測効果に大きな影響を与えますが、同時に、emb 層はモデルの予測効果に大きな影響を与え、中間層は予測効果に大きな影響を与えません。したがって、メタ学習は予測層に近いパラメータのみを選択するという考えになりますが、コストの観点から見ると、emb 層の学習コストが増加し、emb 層はメタ学習用にトレーニングされなくなります。
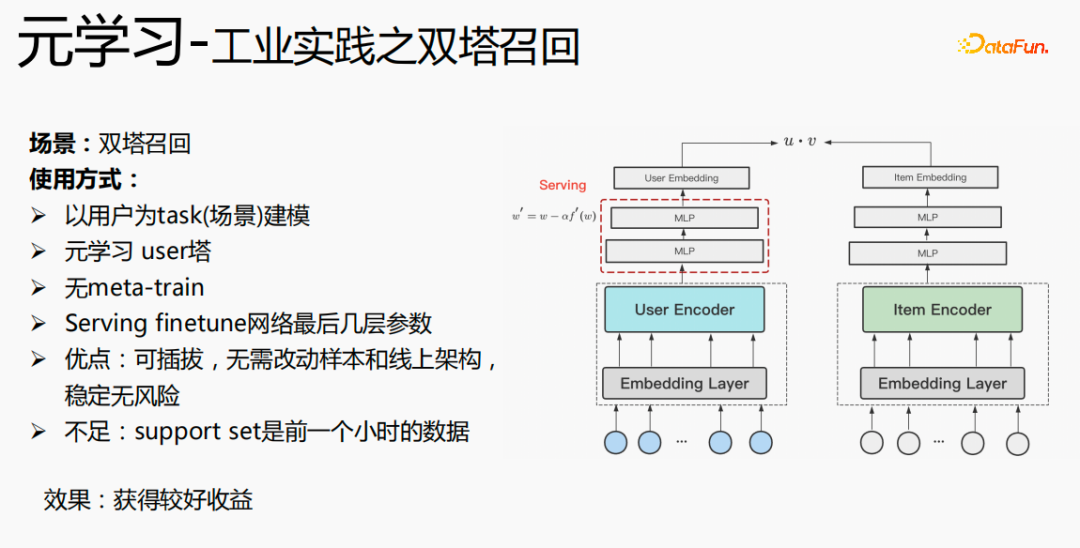
全体的なトレーニング プロセスは、上の図の mmoe トレーニング ネットワークに示されているように、タワー層のパラメーターとパラメーターを学習します。他のシーンはオリジナルのトレーニング方法に基づいて学習します。サンプルはユーザーをディメンションとして編成されています。各ユーザーは独自のトレーニング データを持っています。トレーニング データは 2 つの部分に分かれており、1 つの部分はサポート セットで、もう 1 つの部分はクエリ セットです。サポート セットでは、タワーの更新とパラメーターのトレーニングのためにローカル側のコンテンツのみが学習されます。その後、クエリ セット データを使用してネットワーク全体の損失が計算され、その後、勾配が返されてネットワーク全体のパラメーターが更新されます。 。
したがって、学習プロセス全体は、ネットワーク全体の元の学習方法は変更されず、メタ学習はコア ネットワークのみを学習し、コストを考慮してエンベディングはメタ学習には参加しません。 -学習; 損失 = 元の損失 元の損失; fintune の場合、emb を格納します。サービス提供プロセスでは、emb を使用してコア ネットワークを微調整し、スイッチを使用してメタ学習のオンとオフを制御できます。
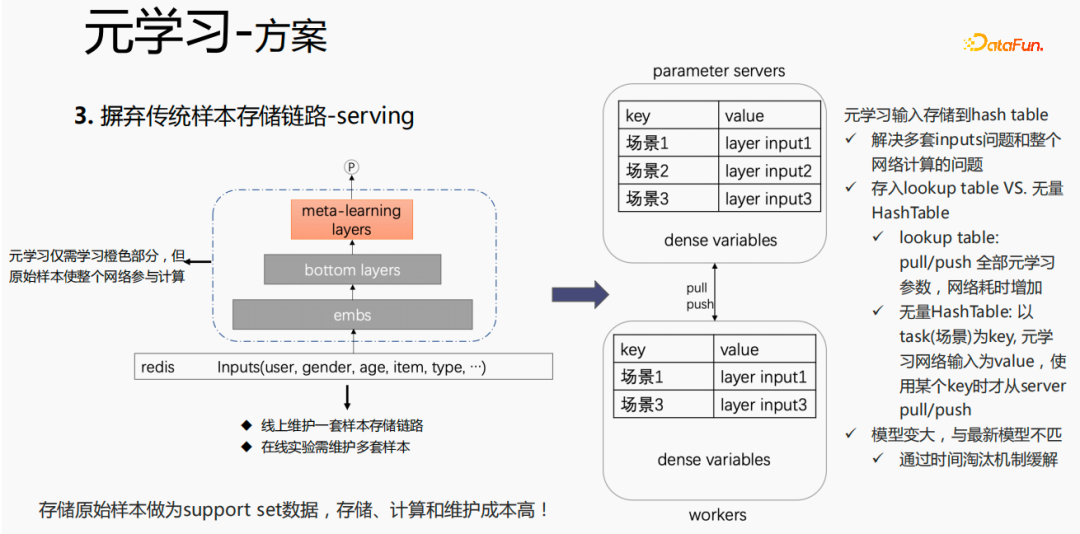
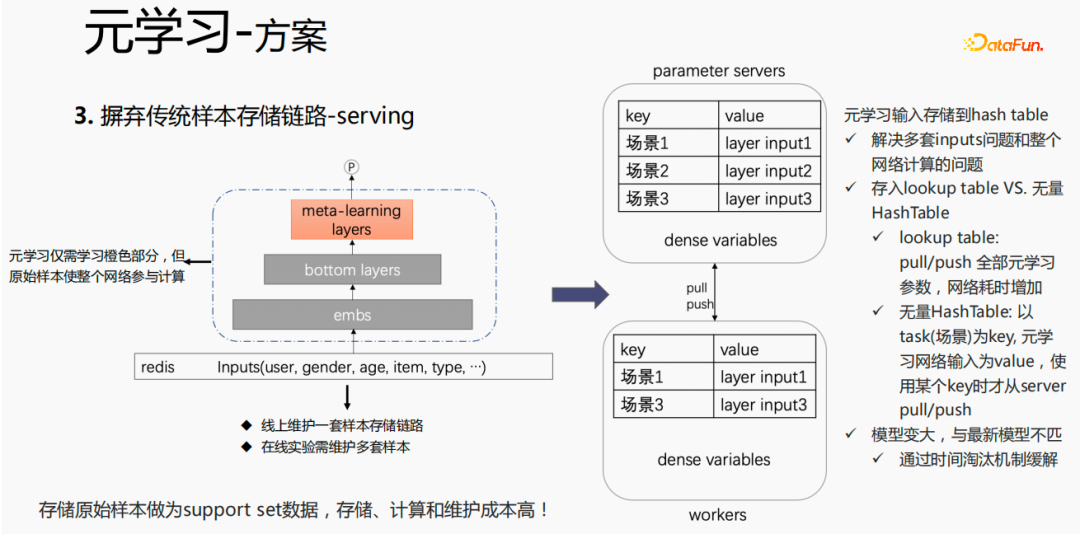
#従来のサンプル保管方法の場合、提供プロセス中に微調整が直接実行される場合、問題: 1 セットのサンプル ストレージ リンクをオンラインで維持する必要があるが、複数のオンライン実験では複数のサンプル セットを維持する必要がある。同時に、微調整プロセスでは、元のサンプルが微調整に使用されます。サンプルは、emb 層、最下位層、メタ学習層を通過します。ただし、メタ学習は、サービス内のメタ学習層のみを学習する必要があります。プロセスを実行し、他の部分は気にしません。サービス提供プロセス中にモデルへのメタ学習入力のみを保存することを検討します。これにより、サンプル リンクのメンテナンスが省略され、一定の効果が得られます。emb 部分のみを保存する場合、この部分の計算コストとメンテナンス コストは、救われます。
次の方法を使用します:
モデルのルックアップ テーブルにストレージを置きます。ルックアップ テーブルは密な変数とみなされ、ps に格納されます。すべてのパラメーターがワーカーにプルされます。更新されると、すべてのパラメーターがワーカーにプッシュされます。ワーカー変数、これによりネットワークの消費時間が増加します。もう 1 つの方法は、無限の HashTable を使用することです。HashTable はキーと値の形式で保存されます。キーはシーンで、値はメタ レイヤーの入力です。この利点は、入力をインポートするだけでよいことです。 ps から必要なシーンのレイヤーを取得します。プッシュまたはプルは全体としてネットワーク時間を節約するため、このメソッドをサンプリングしてメタ レイヤーの入力を保存します。同時に、メタ学習層をモデルに格納すると、モデルが大きくなり、有効期限の問題が発生し、現在のモデルとの不一致が生じます。この問題を解決するために、時間消去を使用します。これにより、モデルが小さくなるだけでなく、リアルタイムの問題も解決されます。
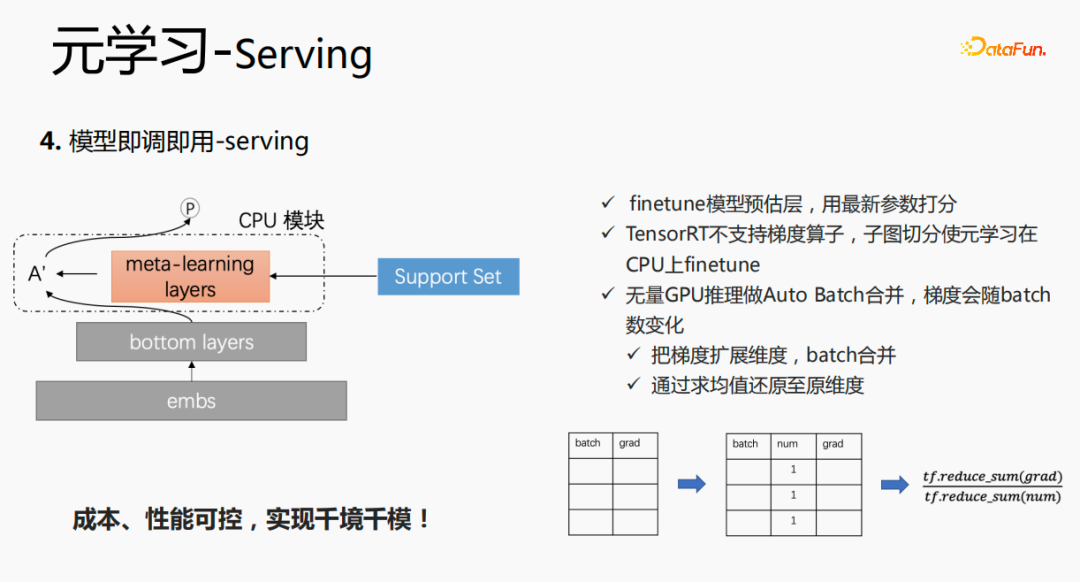
このモデルは、サービス提供ステージでエンベディングを使用します。エンベディングは最下位レイヤーに入力されます。スコアリングの際、それは、元の方法ですが、メタ学習レイヤーを通じてサポート セット内のデータを取得し、このレイヤーのパラメーターを更新し、更新されたパラメーターをスコアリングに使用します。この処理はGPUでは計算できないため、CPU上で処理を実行します。同時に、Wuliang GPU 推論は自動バッチ マージを実行して複数のリクエストをマージします。マージされたリクエストは GPU 上で計算されます。このようにして、バッチが増加するにつれて勾配が変化します。この問題に対処するには、batch と grad On を使用します。を基礎として、num 次元を追加します。勾配を計算するとき、勾配を追加し、勾配の安定性を維持するために num に従って処理します。最終的には、コストとパフォーマンスを制御でき、さまざまなシナリオとモデルが実現されます。
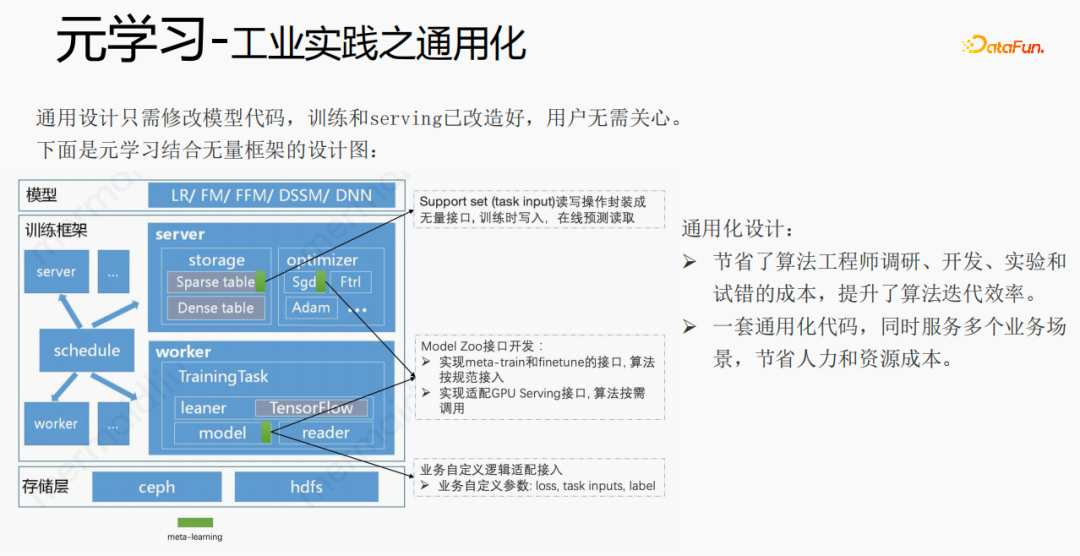
#7. メタ学習の産業化された実践

2. クロスドメインの推奨事項
1. クロスドメインの推奨事項の問題点
各シーンには複数の推奨入口があり、シーンごとに想起、大まかなランキングから細かいランキングまでの一連のリンクを確立する必要があり、コストがかかります。特に小規模なシーンと中規模およびロングテールのトラフィック データはまばらであり、最適化スペースは限られています。コストを節約し、結果を向上させるために、同様のレコメンデーション ポータル、オフライン トレーニング、およびオンライン サービスのサンプルを 1 つの製品に統合してセットにすることはできますか?
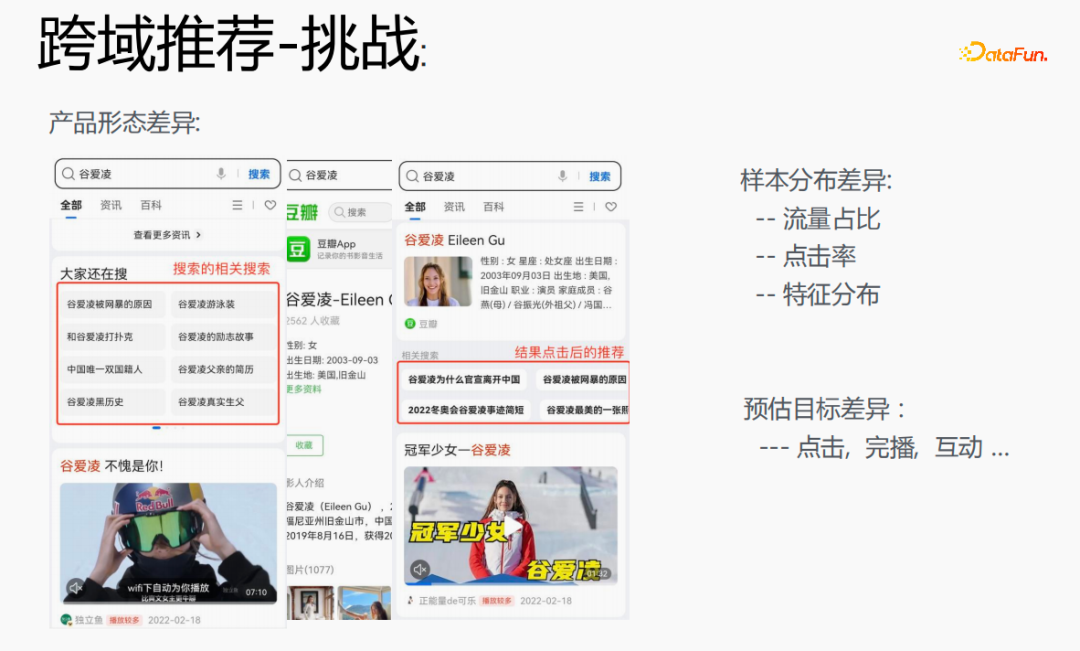
# ただし、これにはいくつかの課題があります。ブラウザで「Gu Ailing」を検索すると、関連する検索語が表示されます。特定のコンテンツをクリックして戻った後、結果をクリックした後の推奨事項が表示されます。両者のトラフィックの割合、クリックスルー率、および機能の分布は非常に優れています。同時に、推定されるターゲットにも違いがあります。
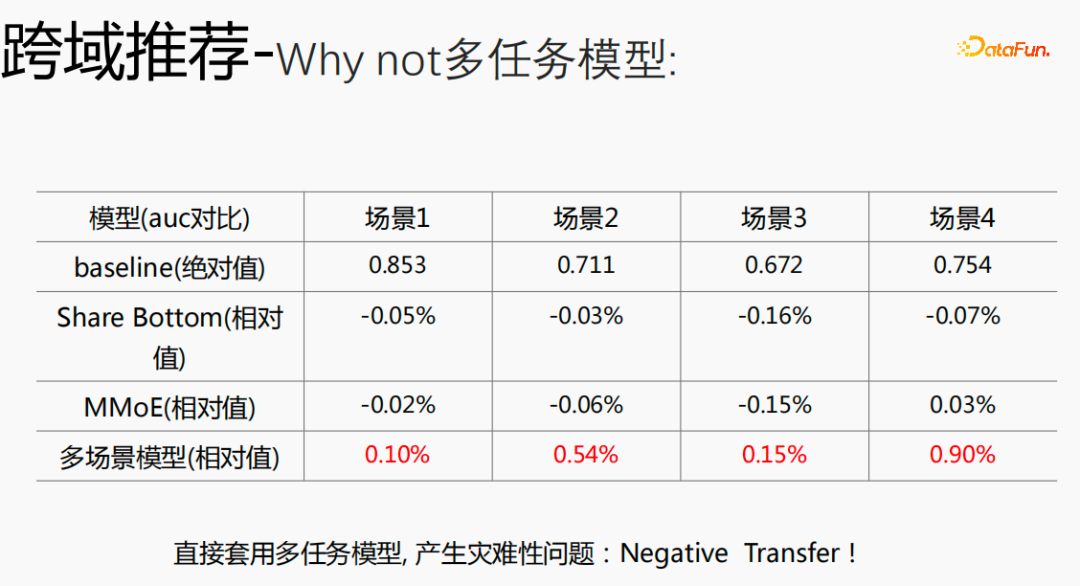
#マルチタスク モデルをクロスドメイン モデルに使用すると、深刻な問題が発生し、改善できなくなります。利点。
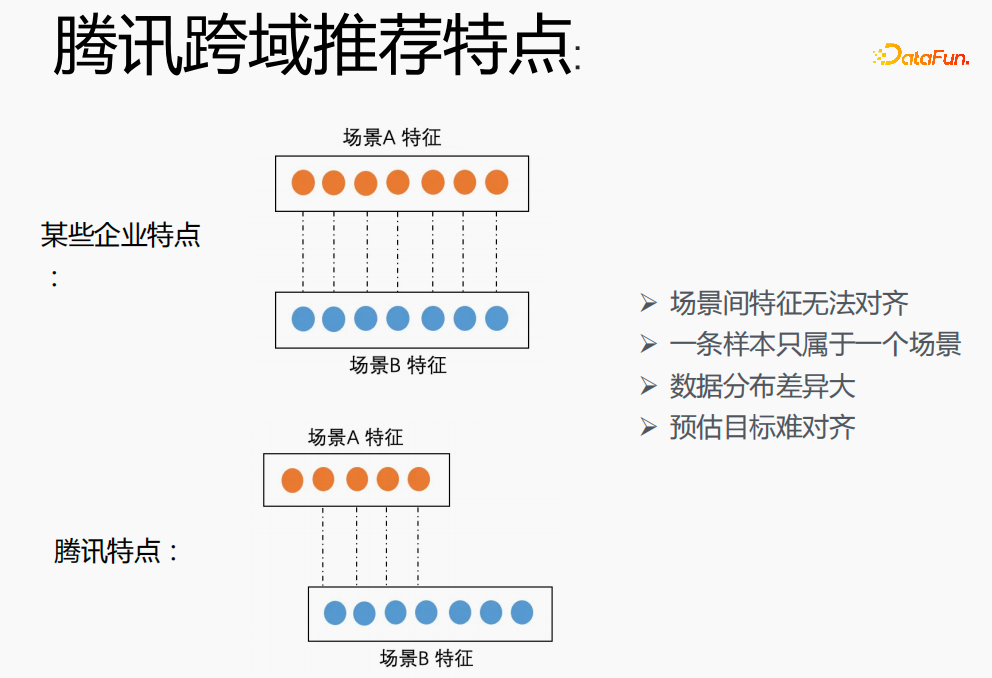
# Tencent でクロスシナリオ モデリングを実装することは大きな課題です。まず、他社では 2 つのシナリオの特徴を 1 対 1 に対応させることができますが、テンセントのクロスドメインレコメンデーション分野では 2 つのシナリオの特徴を一致させることができず、1 つのサンプルは 1 つのシナリオにのみ属することができます。分布は大きく異なり、推定されたターゲットを調整することは困難です。
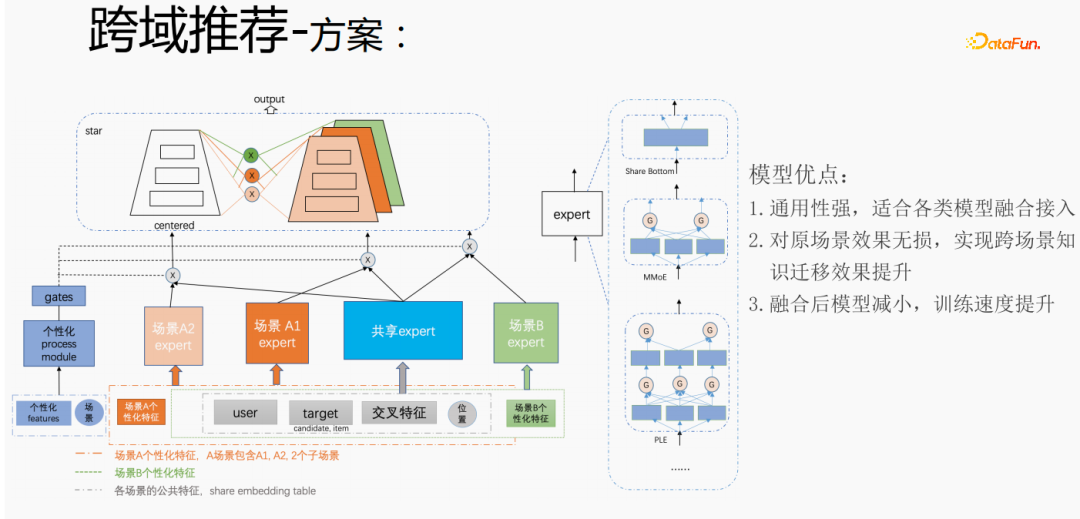
上記の方法は、Tencent のクロスドメイン レコメンデーション シナリオのパーソナライズされたニーズに対応するために使用されます。共通の特徴については、共有埋め込みが実行されます。シーンのパーソナライズされた特徴には、独自の独立した埋め込みスペースがあります。モデル部分には、共有エキスパートとパーソナライズされたエキスパートがあります。すべてのデータは共有エキスパートと各シーンのサンプルに流れ込みますエキスパートをパーソナライズし、パーソナライズされたゲートを介して共有エキスパートとパーソナライズされたエキスパートを統合し、それらをタワーに入力し、スター法を使用してさまざまなシナリオでターゲットの疎性の問題を解決します。エキスパート部分では、シェアボトム、MMoE、PLE、またはビジネスシナリオの完全なモデル構造など、任意のモデル構造を使用できます。この方法の利点は、モデルの汎用性が高く、さまざまなモデルの融合アクセスに適していること、シーンエキスパートを直接移行できるため、元のシーン効果が損なわれず、シナリオを越えた知識伝達の効果が向上することです。融合後はモデルが縮小され、トレーニング速度が向上します。コストを節約しながら改善されます。
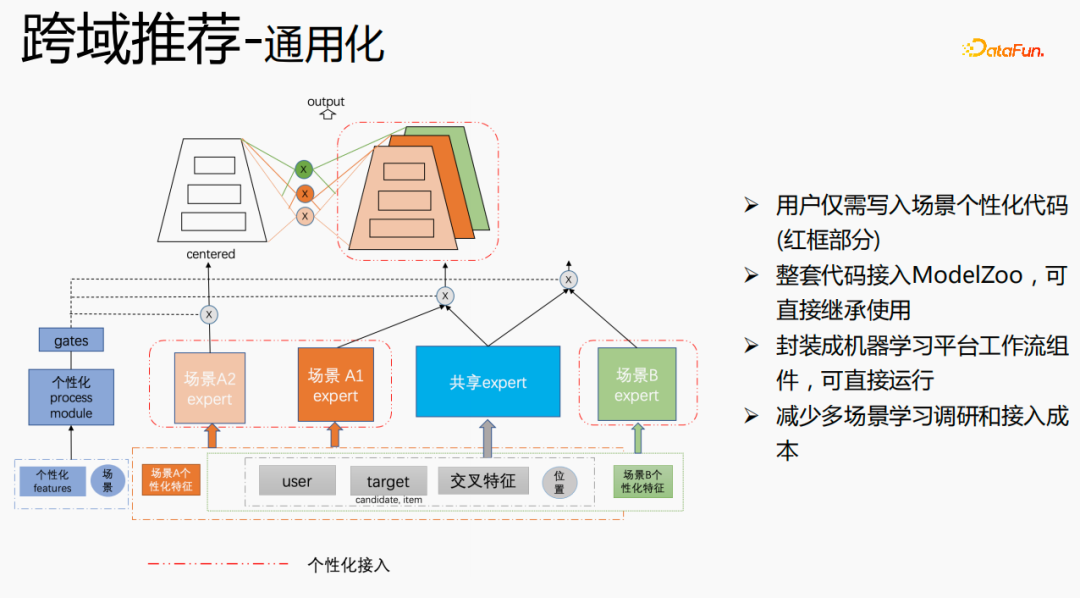
# ユニバーサル構築を実施しました。赤い部分は、パーソナライズされた機能、パーソナライズされたモデル構造など、パーソナライズされたアクセスが必要なコンテンツです。 . 、ユーザーはパーソナライズされたコードを記述するだけで済みます。他の部分では、コードのセット全体を ModelZoo に接続し、直接継承して使用でき、機械学習プラットフォームのワークフロー コンポーネントにカプセル化して直接実行できます。この方法により、マルチシナリオ学習の研究コストが削減され、アクセス。
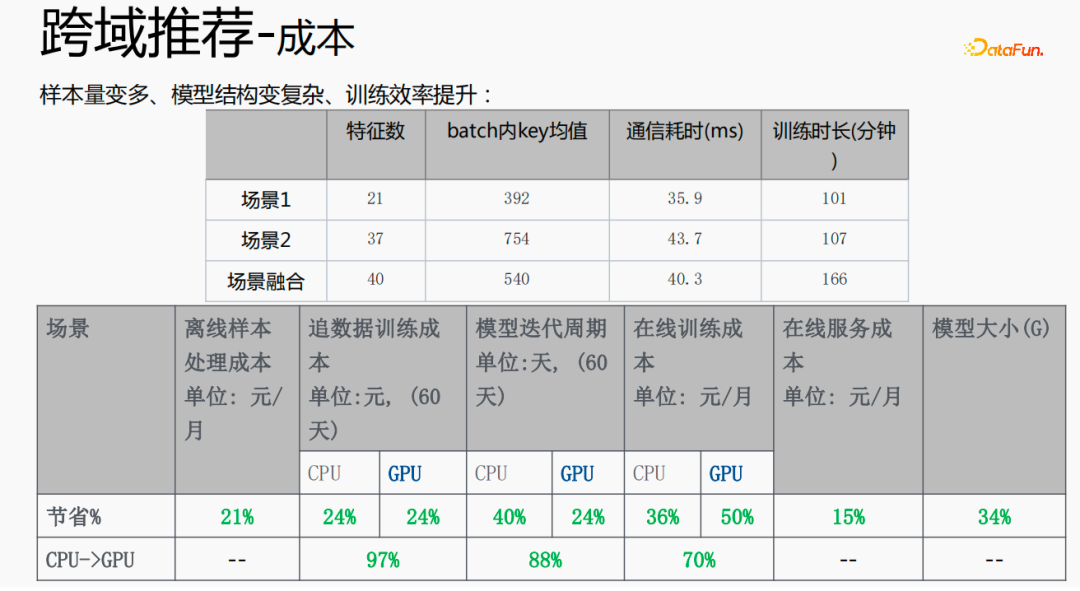
この方法では、サンプル サイズが増加し、モデル構造が複雑になりますが、効率は向上します。その理由は、一部の特徴量を共有しているため、融合された特徴量の数が 2 つのシーンの特徴量の合計よりも少ないこと、共有埋め込みの機能により、バッチ内の平均キー値が2 つのシーンの合計; 減少 サーバー側からプルまたはプッシュする時間を節約し、通信時間を節約し、全体のトレーニング時間を短縮します。
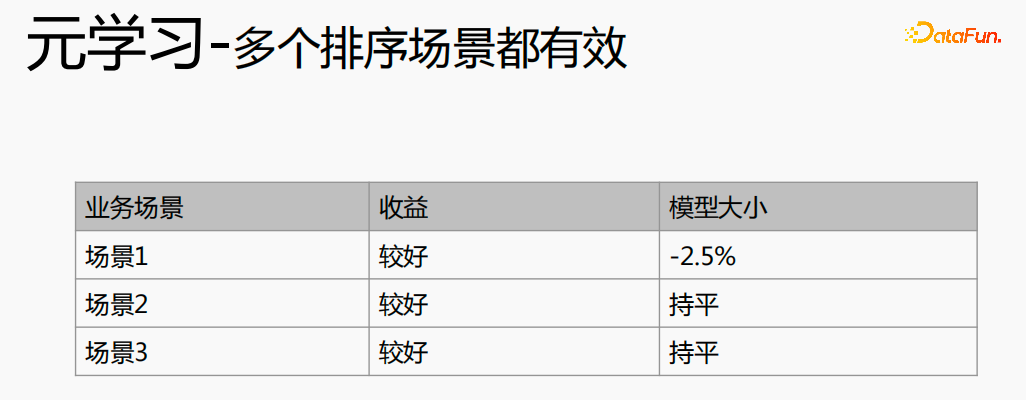
複数のシナリオを融合すると、全体的なコストを削減できます。オフライン サンプル処理ではコストを 21% 削減できます。CPU を使用してデータを追跡することで、コストの 24% を節約し、反復回数を削減できます。モデルの時間も 40% 削減され、オンライン トレーニング コスト、オンライン サービス コスト、モデル サイズがすべて削減されるため、リンク全体のコストが削減されます。同時に、複数のシーンのデータを統合する方が GPU コンピューティングに適しており、2 つの単一シーンの CPU を GPU に統合すると、より高い割合で節約できます。
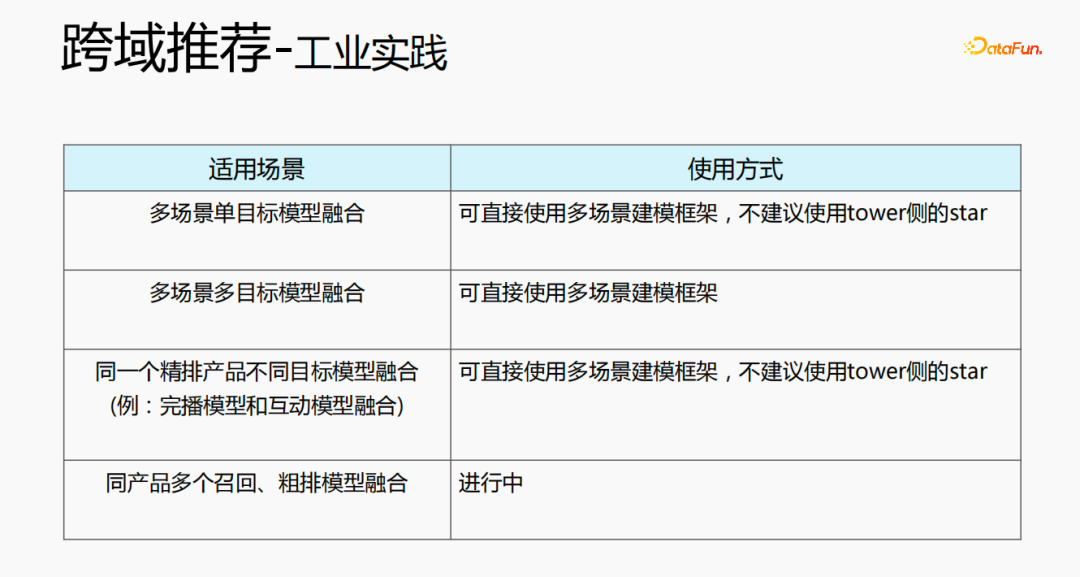
クロスドメインの推奨事項は、さまざまな方法で使用できます。 1 つ目はマルチシーンの単一目的モデル構造で、マルチシーン モデリング フレームワークを直接使用できます。タワー側のスターの使用はお勧めできません。2 つ目はマルチシーンとマルチシーンの融合です。 -objective であり、マルチシーン モデリング フレームワークを直接使用できます。 ; 3 番目のタイプは、同じリファインされた製品に対する異なるターゲット モデルの融合であり、マルチシナリオ モデリング フレームワークを直接使用できます。タワー側に星印、最後のモデルは、同じ製品に対する複数のリコール モデルと大まかなランキング モデルを融合したもので、現在開発中です。
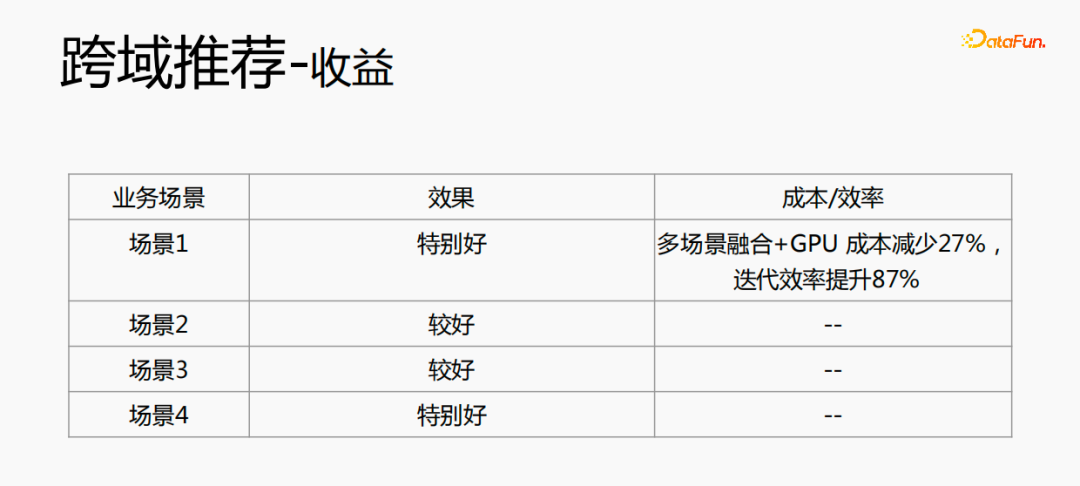
クロスドメイン レコメンデーションは、効果を向上させるだけでなく、コストを大幅に節約します。
以上がTencent TRS のメタ学習とクロスドメイン レコメンデーションの業界実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7493
7493
 15
1377
52
77
11
19
41
15
1377
52
77
11
19
41

 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の最下層はマージ ソートを使用し、その複雑さは O(nlogn) で、クイック ソート、ヒープ ソート、安定したソートなど、さまざまなソート アルゴリズムの選択肢を提供します。
 人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能 (AI) と法執行機関の融合により、犯罪の予防と検出の新たな可能性が開かれます。人工知能の予測機能は、犯罪行為を予測するためにCrimeGPT (犯罪予測技術) などのシステムで広く使用されています。この記事では、犯罪予測における人工知能の可能性、その現在の応用、人工知能が直面する課題、およびこの技術の倫理的影響について考察します。人工知能と犯罪予測: 基本 CrimeGPT は、機械学習アルゴリズムを使用して大規模なデータセットを分析し、犯罪がいつどこで発生する可能性があるかを予測できるパターンを特定します。これらのデータセットには、過去の犯罪統計、人口統計情報、経済指標、気象パターンなどが含まれます。人間のアナリストが見逃す可能性のある傾向を特定することで、人工知能は法執行機関に力を与えることができます
 改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
01 今後の概要 現時点では、検出効率と検出結果の適切なバランスを実現することが困難です。我々は、光学リモートセンシング画像におけるターゲット検出ネットワークの効果を向上させるために、多層特徴ピラミッド、マルチ検出ヘッド戦略、およびハイブリッドアテンションモジュールを使用して、高解像度光学リモートセンシング画像におけるターゲット検出のための強化されたYOLOv5アルゴリズムを開発しました。 SIMD データセットによると、新しいアルゴリズムの mAP は YOLOv5 より 2.2%、YOLOX より 8.48% 優れており、検出結果と速度のバランスがより優れています。 02 背景と動機 リモート センシング技術の急速な発展に伴い、航空機、自動車、建物など、地表上の多くの物体を記述するために高解像度の光学式リモート センシング画像が使用されています。リモートセンシング画像の判読における物体検出
 Jiuzhang Yunji DataCanvas マルチモーダル大規模モデル プラットフォームの実践と考察
Oct 20, 2023 am 08:45 AM
Jiuzhang Yunji DataCanvas マルチモーダル大規模モデル プラットフォームの実践と考察
Oct 20, 2023 am 08:45 AM
1. マルチモーダル大型モデルの発展の歴史 上の写真は、1956 年に米国のダートマス大学で開催された最初の人工知能ワークショップです。このカンファレンスが人工知能開発の始まりとも考えられています。記号論理学の先駆者たち(前列中央の神経生物学者ピーター・ミルナーを除く)。しかし、この記号論理理論は長い間実現できず、1980 年代と 1990 年代に最初の AI の冬の到来さえもたらしました。最近の大規模な言語モデルが実装されて初めて、ニューラル ネットワークが実際にこの論理的思考を担っていることがわかりました。神経生物学者ピーター ミルナーの研究は、その後の人工ニューラル ネットワークの開発に影響を与えました。彼が参加に招待されたのはこのためです。このプロジェクトでは。
 58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
1. 58 Portraits プラットフォーム構築の背景 まず、58 Portraits プラットフォーム構築の背景についてお話ししたいと思います。 1. 従来のプロファイリング プラットフォームの従来の考え方ではもはや十分ではありません。ユーザー プロファイリング プラットフォームを構築するには、複数のビジネス分野からのデータを統合して、ユーザーの行動や関心を理解するためのデータ マイニングも必要です。最後に、ユーザー プロファイル データを効率的に保存、クエリ、共有し、プロファイル サービスを提供するためのデータ プラットフォーム機能も必要です。自社構築のビジネス プロファイリング プラットフォームとミドルオフィス プロファイリング プラットフォームの主な違いは、自社構築のプロファイリング プラットフォームは単一のビジネス ラインにサービスを提供し、オンデマンドでカスタマイズできることです。ミッドオフィス プラットフォームは複数のビジネス ラインにサービスを提供し、複雑な機能を備えていることです。モデリングを提供し、より一般的な機能を提供します。 2.58 中間プラットフォームのポートレート構築の背景のユーザーのポートレート 58
 SOTA をリアルタイムで追加すると、大幅に増加します。 FastOcc: より高速な推論と展開に適した Occ アルゴリズムが登場しました。
Mar 14, 2024 pm 11:50 PM
SOTA をリアルタイムで追加すると、大幅に増加します。 FastOcc: より高速な推論と展開に適した Occ アルゴリズムが登場しました。
Mar 14, 2024 pm 11:50 PM
上記と著者の個人的な理解は、自動運転システムにおいて、認識タスクは自動運転システム全体の重要な要素であるということです。認識タスクの主な目的は、自動運転車が道路を走行する車両、路側の歩行者、運転中に遭遇する障害物、道路上の交通標識などの周囲の環境要素を理解して認識できるようにすることで、それによって下流のシステムを支援できるようにすることです。モジュール 正しく合理的な決定と行動を行います。自動運転機能を備えた車両には、通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなど、さまざまな種類の情報収集センサーが装備されており、自動運転車が正確に認識し、認識できるようにします。周囲の環境要素を理解することで、自動運転車が自動運転中に正しい判断を下せるようになります。頭
