

Intel Zhang Yu: エッジ コンピューティングは AI エコシステム全体で重要な役割を果たしています

[グローバル ネットワーク テクノロジー レポーター 林 孟雪] 現在、生成 AI と大型モデルは世界中で高い人気を示しており、つい最近開催された 2023 年の世界人工知能会議 (WAIC 2023) では、さまざまなメーカーも参入しました。組織委員会によると、「百模型戦争」では合計30以上の大規模模型プラットフォームが公開・公開され、オフラインブースの60%で生成AI技術の関連紹介や応用が展示され、参加者の80%が議論した。内容は大型モデルを中心に展開します。
WAIC 2023 開催中、インテル コーポレーションのシニアチーフ AI エンジニアであり、中国ネットワークおよびエッジ部門の最高技術責任者である Zhang Yu 氏は、このラウンドの人工知能の開発を促進する中心的な要因は、実際にはコンピューティングの継続的な進歩であると信じていました。通信およびストレージ技術を促進します。大規模モデルであれ AI フュージョンであれ、AI エコシステム全体において、エッジは重要な役割を果たします。
Zhang Yu 氏は、「業界のデジタル変革に伴い、アジャイルな接続、リアルタイムのビジネス、アプリケーション インテリジェンスに対する人々の要求により、エッジ人工知能の開発が促進されています。しかし、エッジ人工知能のアプリケーションのほとんどはまだ実用化されていません。」エッジでの推論段階、つまり、データセンターでモデルをトレーニングするには大量のデータと膨大な計算能力が必要であり、トレーニング結果をフロントエンドにプッシュして推論操作を実行します。これは、エッジにおける人工知能の現在の使用法です。model."
「このモデルでは必然的にモデル更新の頻度が制限されますが、実際に多くのスマート産業でモデル更新の需要があることもわかりました。自動運転はさまざまな道路状況に適応でき、自動車の運転に適している必要があります。しかし、自動車工場でロール モデルをトレーニングする場合、使用されるトレーニング データと動的運転中に生成されるデータの間には、特定の違いがあることがよくあります。この違いは、モデルの一般化能力に影響を与えます。新しい道路状況や新しい運転行動に適応する能力。このプロセスを前進させるには、エッジでモデルを継続的にトレーニングし、最適化する必要がある」と同氏は述べた。
したがって、Zhang Yu は、人工知能開発の第 2 段階はエッジトレーニング段階であるべきだと提案しました。 「エッジトレーニングを実装したい場合は、データアノテーションからモデルトレーニング、モデル展開までの完全な開発プロセスを完了するために、より多くの自動化された手段とツールが必要です。」彼は、エッジ人工知能の次の開発方向はそれであるべきだと述べました。自主学習です。
実際の開発プロセスでは、エッジ人工知能も多くの課題に直面します。 Zhang Yu 氏の見解では、エッジ トレーニングの課題に加えて、エッジ機器の課題もあります。 「提供されるコンピューティング能力が実行できる消費電力は多くの場合制限されているため、限られたリソースでエッジ推論とトレーニングを実装する方法は、チップのパフォーマンスと消費電力比に対するより高い要件を提示します。」と同氏は指摘しています。エッジ デバイスの断片化は非常に明白であり、ソフトウェアを使用して異なるプラットフォーム間の移行を実現する方法についても、より多くの要件が提示されます。
また、人工知能の発展は計算能力と密接に関係しており、その計算能力の背後には巨大なデータ基盤があり、膨大なデータ資産を前に、データをどのように保護するかが人工知能の開発においてホットなテーマとなっています。エッジ人工知能。 AI がエッジに導入されると、これらのモデルはサービス プロバイダーの制御を超えます。現時点でモデルを保護するにはどうすればよいでしょうか?また、保管時や運用時に優れた保護効果を達成する必要があり、これがエッジ人工知能が直面する課題です。 「
「インテルはデータ企業であり、当社の製品はコンピューティング、通信、ストレージのあらゆる側面をカバーしています。コンピューティングに関しては、インテルは CPU、GPU、FPGA、さまざまな人工知能アクセラレーション チップを含む多くの製品を提供しています。ユーザーのコンピューティング能力に対するさまざまな要件を満たします。たとえば、大規模な人工知能モデルに関して言えば、Intel の Habana によって発売された Gaudi2 製品は、大規模なモデルのトレーニングで優れたパフォーマンスを示した業界全体の唯一の製品です。推論の場合、インテルが提供する OpenVINO 深層学習展開ツール スイートを使用すると、オープン人工知能フレームワーク上で開発者が設計およびトレーニングしたモデルをさまざまなハードウェア プラットフォームに迅速に展開して、推論操作を実行できます。」
以上がIntel Zhang Yu: エッジ コンピューティングは AI エコシステム全体で重要な役割を果たしていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7488
7488
 15
1377
52
77
11
19
40
15
1377
52
77
11
19
40

 Intel Core Ultra 9 285K プロセッサーの公開: CineBench R23 マルチコアの実行スコアは i9-14900K より 18% 高い
Jul 25, 2024 pm 12:25 PM
Intel Core Ultra 9 285K プロセッサーの公開: CineBench R23 マルチコアの実行スコアは i9-14900K より 18% 高い
Jul 25, 2024 pm 12:25 PM
7月25日のこのサイトのニュースによると、情報源のJaykihn氏は昨日(7月24日)、Xプラットフォームにツイートを投稿し、Intel Core Ultra9285K「ArrowLake-S」デスクトッププロセッサの実行スコアデータを共有した結果を示した。 Core 14900K よりも 18% 高速です。このウェブサイトはツイートの内容を引用し、情報源はインテル Core Ultra9285K プロセッサーの ES2 および QS バージョンの実行スコアを共有し、Core i9-14900K プロセッサーと比較しました。レポートによると、CinebenchR23、Geekbench5、SpeedoMeter、WebXPRT4、CrossMark などのワークロードを実行する場合の ArrowLake-SQS の TD
 Intel、CNVio3インターフェースをサポートするWi-Fi 7 BE201ネットワークカードを発表
Jun 07, 2024 pm 03:34 PM
Intel、CNVio3インターフェースをサポートするWi-Fi 7 BE201ネットワークカードを発表
Jun 07, 2024 pm 03:34 PM
6月1日の当サイトのニュースによると、インテルは5月27日にサポート文書を更新し、コードネーム「Fillmore Peak2」というWi-Fi7(802.11be)BE201ネットワークカードの製品詳細を発表した。上の画像の出典: Benchlife Web サイト 注: PCIe/USB インターフェイスを使用する既存の BE200 および BE202 とは異なり、BE201 は最新の CNVio3 インターフェイスをサポートします。 BE201 ネットワーク カードの主な仕様は BE200 と同様で、2x2TX/RX ストリーミングをサポートし、2.4 GHz、5 GHz、および 6 GHz をサポートします。最大ネットワーク速度は、標準の最大速度 40 Gbit よりもはるかに低い 5 Gbps に達します。 /秒。 BE201 は Bluetooth 5.4 および Bluetooth LE もサポートします。
 Intel N250 低電力プロセッサを公開: 4 コア、4 スレッド、周波数 1.2 GHz
Jun 03, 2024 am 10:26 AM
Intel N250 低電力プロセッサを公開: 4 コア、4 スレッド、周波数 1.2 GHz
Jun 03, 2024 am 10:26 AM
5月16日のこのサイトのニュースによると、情報源@InstLatX64は最近、IntelがN200シリーズ「AlderLake-N」シリーズに代わる低電力プロセッサの新しいN250「TwinLake」シリーズの発売を準備しているとツイートした。出典: videocardz N200 シリーズ プロセッサは、低コストのラップトップ、シン クライアント、組み込みシステム、セルフサービスおよび POS 端末、NAS、家電製品で人気があります。 「TwinLake」は新しいプロセッサ シリーズのコード名で、リング バス (RingBus) レイアウトを使用するシングルチップ プロセッサ Die に似ていますが、コンピューティング能力を完成させるために E コア クラスタを備えています。このサイトに添付されているスクリーンショットは次のとおりです: AlderLake-N
 MSI、Intel Alder Lake-N N100プロセッサを搭載した新しいMS-C918ミニコンソールを発売
Jul 03, 2024 am 11:33 AM
MSI、Intel Alder Lake-N N100プロセッサを搭載した新しいMS-C918ミニコンソールを発売
Jul 03, 2024 am 11:33 AM
本ウェブサイトは7月3日、現代企業の多様化するニーズに応えるため、MSIの子会社であるMSIIPCが産業用ミニホスト「MS-C918」を発売したと報じた。公開価格はまだ見つかっていない。 MS-C918 は、コスト効率、使いやすさ、携帯性を重視する企業向けに位置付けられており、重要でない環境向けに特別に設計されており、3 年間の耐用年数保証を提供します。 MS-C918 は、超低電力ソリューション向けに特別に調整された Intel AlderLake-NN100 プロセッサを使用したハンドヘルド産業用コンピュータです。当サイトに添付されているMS-C918の主な機能と特長は以下のとおりです。 コンパクトサイズ:80mm×80mm×36mmの手のひらサイズで、操作が簡単でモニターの後ろに隠れます。表示機能: 2 HDMI2 経由。
 ASUS、Intelの第13/14世代Coreプロセッサーの不安定性の問題を軽減するため、Z790マザーボード用のBIOSアップデートをリリース
Aug 09, 2024 am 12:47 AM
ASUS、Intelの第13/14世代Coreプロセッサーの不安定性の問題を軽減するため、Z790マザーボード用のBIOSアップデートをリリース
Aug 09, 2024 am 12:47 AM
8 月 8 日のこの Web サイトのニュースによると、MSI と ASUS は本日、Intel Core 第 13 世代および第 14 世代デスクトップ プロセッサの不安定性の問題に対応して、一部の Z790 マザーボード用の 0x129 マイクロコード アップデートを含む BIOS のベータ版をリリースしました。 BIOS アップデートを提供する ASUS の最初のマザーボードには、ROGMAXIMUSZ790HEROBetaBios2503ROGMAXIMUSZ790DARKHEROBetaBios1503ROGMAXIMUSZ790HEROBTFBetaBios1503ROGMAXIMUSZ790HEROEVA-02 統合バージョン BetaBios2503ROGMAXIMUSZ790A が含まれます。
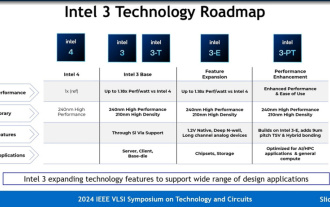 インテルはインテル 3 プロセスを詳細に説明しています。より多くの EUV リソグラフィーを適用し、同じ電力消費の周波数を最大 18% 増加させます。
Jun 19, 2024 pm 10:53 PM
インテルはインテル 3 プロセスを詳細に説明しています。より多くの EUV リソグラフィーを適用し、同じ電力消費の周波数を最大 18% 増加させます。
Jun 19, 2024 pm 10:53 PM
6 月 19 日のこのサイトのニュースによると、2024 IEEEVLSI セミナー活動の一環として、Intel は最近、公式 Web サイトで Intel3 プロセス ノードの技術詳細を紹介しました。 Intel の最新世代の FinFET トランジスタ テクノロジは、Intel4 と比較して、EUV を使用するための手順が追加されており、基本的な Intel3 と 3 つのバリアントを含む、ファウンドリ サービスを長期間提供するノード ファミリになります。ノード。その中で、Intel3-E はアナログ モジュールの製造に適した 1.2V の高電圧をネイティブでサポートしていますが、将来の Intel3-PT では全体のパフォーマンスがさらに向上し、より微細な 9μm ピッチの TSV とハイブリッド ボンディングがサポートされる予定です。インテルは次のように主張しています
 Intel Panther Lake モバイル プロセッサの仕様を公開: 最大「4+8+4」16 コア CPU、12 Xe3 コア ディスプレイ
Jul 18, 2024 pm 04:43 PM
Intel Panther Lake モバイル プロセッサの仕様を公開: 最大「4+8+4」16 コア CPU、12 Xe3 コア ディスプレイ
Jul 18, 2024 pm 04:43 PM
7 月 16 日のこのサイトのニュースによると、ArrowLake デスクトップ プロセッサと BartlettLake デスクトップ プロセッサの仕様が明らかになった後、ブロガー @jaykihn0 が早朝に Intel PantherLake プロセッサのモバイル U および H バージョンの仕様を公開しました。 Panther Lake モバイル プロセッサは Core Ultra300 シリーズと名付けられる予定で、次のバージョンで入手可能になります: PTL-U: 4P+0E+4LPE+4Xe、15WPL1PTL-H: 4P+8E+4LPE+12Xe、25WPL1PTL-H : 4P+8E+4LPE+ 4Xe、25WPL1 ブロガーは、PantherLake プロセッサの 12Xe コア ディスプレイ バージョンもリリースしました。
 6700E が 6 月 6 日に中国でデビュー、インテルが Xeon 6 シリーズ プロセッサを正式に発売
Jun 06, 2024 am 10:51 AM
6700E が 6 月 6 日に中国でデビュー、インテルが Xeon 6 シリーズ プロセッサを正式に発売
Jun 06, 2024 am 10:51 AM
当サイトは6月4日、Intelが今から来年第1四半期にかけて新世代のXeonプロセッサを順次発売する計画で、その中のXeon 6700Eは6月6日に中国で発売されると報じた。 Intelは、最大128コアのXeon 6900P「Granite Rapids」を2024年の第3四半期に、最大288コアのXeon 6900E「Sierra Forest」を2025年の第1四半期に国際市場で発売する予定だ。 「Xeon 6」シリーズはEシリーズとPシリーズに分かれています。 Pシリーズ Pシリーズは主に、ハイパフォーマンスコンピューティング、データベースと分析、人工知能、ネットワーク、エッジ、インフラストラクチャ/ストレージなどのコンピューティング集約型およびAIワークロードを対象としています。 、最大 128 個の Personal パフォーマンス コア (6900P/を含む)
