

Microsoft の新しいホット ペーパー: Transformer が 10 億トークンに拡大

誰もが独自の大規模モデルのアップグレードと反復を続けると、コンテキスト ウィンドウを処理する LLM (大規模言語モデル) の能力も重要な評価指標になります。
たとえば、スターラージモデル GPT-4 は、50 ページのテキストに相当する 32,000 個のトークンをサポートしています。OpenAI の元メンバーによって設立された Anthropic は、Claude のトークン処理能力を100k、約 75,000 1 単語は、「ハリー・ポッター」の最初の部分を 1 回クリックで要約するのにほぼ相当します。
Microsoft の最新の調査では、今回は Transformer を 10 億トークンまで直接拡張しました。これにより、コーパス全体やインターネット全体を 1 つのシーケンスとして扱うなど、非常に長いシーケンスをモデル化するための新しい可能性が開かれます。
比較のために、平均的な人は約 5 時間で 100,000 トークンを読み取ることができますが、情報を消化、記憶、分析するにはさらに時間がかかる可能性があります。クロードはこれを 1 分以内に実行できます。これを Microsoft の調査に換算すると、驚異的な数字になります。
 写真
写真
- 論文アドレス: https://arxiv.org/pdf/2307.02486.pdf
- プロジェクト アドレス: https://github.com/microsoft/unilm/tree/master
具体的には、この研究では LONGNET を提案しています。短いシーケンスのパフォーマンスを犠牲にすることなく、シーケンスの長さを 10 億トークンを超えるまで拡張できるトランスフォーマーのバリアント。この記事では、モデルの知覚範囲を指数関数的に拡大できる拡張注意も提案しています。
LONGNET には次の利点があります:
1) 線形計算の複雑さがあります;
2) より長いシーケンスの分散トレーナーとして使用できます;
3) 拡張された注意は標準の注意をシームレスに置き換えることができ、統合された既存の Transformer ベースの最適化手法とシームレスに連携できます。
実験結果は、LONGNET が長いシーケンス モデリングと一般的な言語タスクの両方で優れたパフォーマンスを発揮することを示しています。
研究動機について論文では、近年ニューラルネットワークの拡張がトレンドとなっており、性能の良いネットワークが数多く研究されていると述べています。その中で、ニューラル ネットワークの一部としてのシーケンスの長さは、理想的には無限である必要があります。しかし、現実はその逆であることが多いため、シーケンスの長さの制限を破ることは大きな利点をもたらします。
- 第一に、モデルに大容量のメモリと受容野が提供されます。 . 人間や世界と効果的に対話できるようにします。
- 第 2 に、より長いコンテキストには、モデルがトレーニング データで利用できるより複雑な因果関係と推論パスが含まれます。逆に、依存関係が短いと偽の相関が多くなり、モデルの一般化には役立ちません。
- 3 番目に、シーケンスの長さが長いと、モデルがより長いコンテキストを探索するのに役立ちます。また、非常に長いコンテキストは、モデルが壊滅的な忘却の問題を軽減するのにも役立ちます。
#ただし、シーケンスの長さを拡張する際の主な課題は、計算の複雑さとモデルの表現力の間の適切なバランスを見つけることです。
たとえば、RNN スタイル モデルは主にシーケンスの長さを増やすために使用されます。ただし、その逐次的な性質により、トレーニング中の並列化が制限されます。これは、長いシーケンスのモデリングでは重要です。
最近、状態空間モデルはシーケンス モデリングにとって非常に魅力的なものになっており、トレーニング中に CNN として実行でき、テスト時に効率的な RNN に変換できます。ただし、このタイプのモデルは、通常の長さではトランスフォーマーほどのパフォーマンスは得られません。
シーケンスの長さを拡張するもう 1 つの方法は、Transformer の複雑さ、つまり自己注意の 2 次複雑さを軽減することです。現段階では、低ランク アテンション、カーネル ベースの方法、ダウンサンプリング方法、検索ベースの方法など、いくつかの効率的な Transformer ベースのバリアントが提案されています。ただし、これらのアプローチでは、まだ Transformer を 10 億トークンの規模まで拡張することはできません (図 1 を参照)。
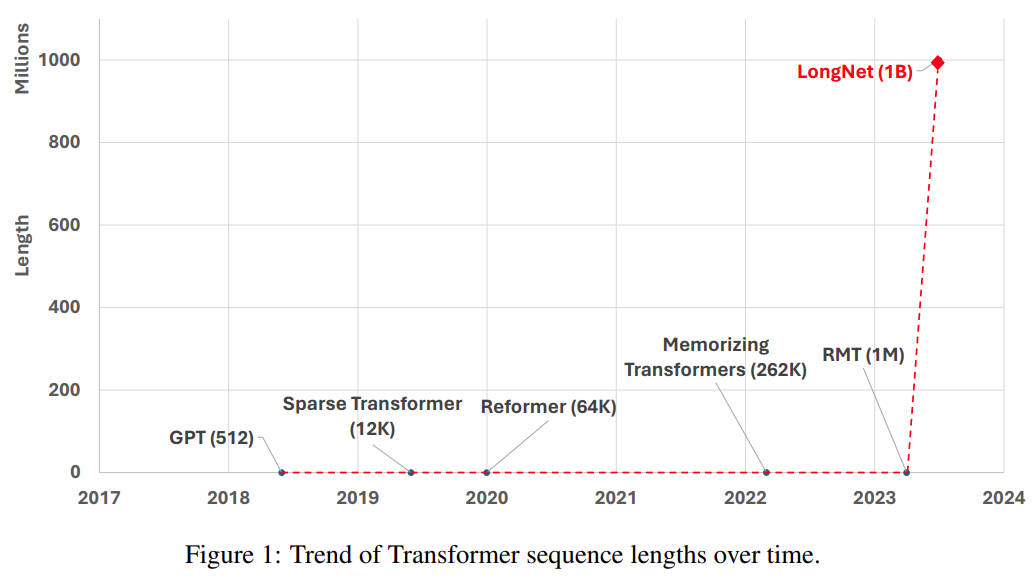 図
図
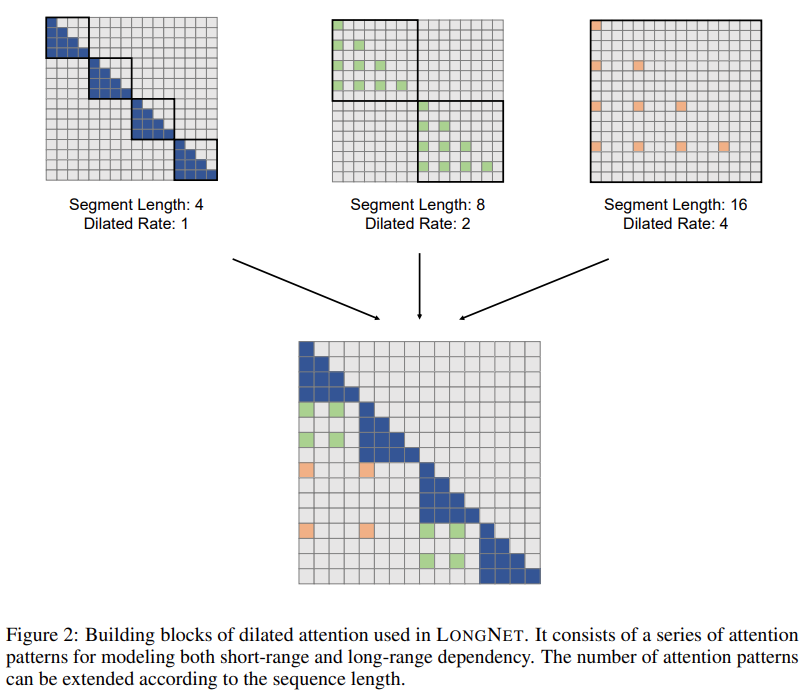
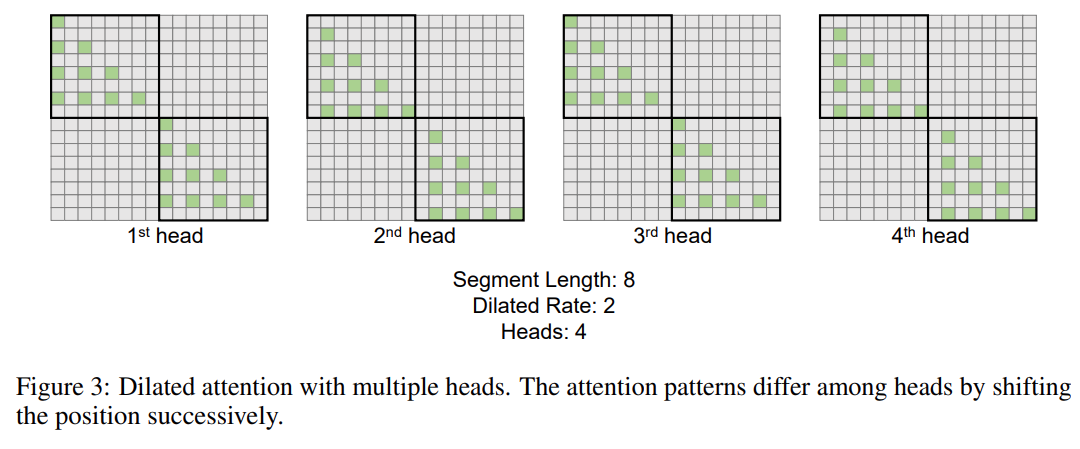
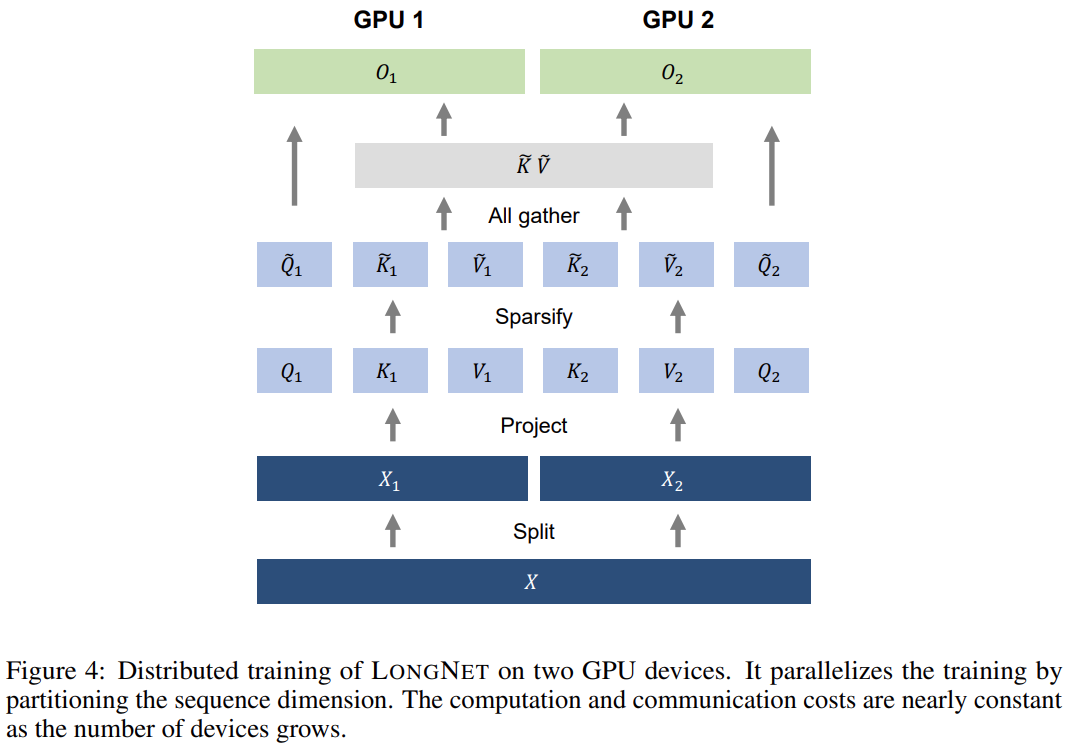
次の表は、さまざまな計算方法の計算の複雑さを比較しています。 N はシーケンスの長さ、d は隠れ次元です。 ###############写真###### 研究のソリューションである LONGNET は、シーケンスの長さを 10 億トークンまで拡張することに成功しました。具体的には、本研究は、拡張された注意と呼ばれる新しいコンポーネントを提案し、バニラトランスフォーマーの注意メカニズムを拡張された注意に置き換えます。一般的な設計原則は、トークン間の距離が増加するにつれて、注意の割り当てが指数関数的に減少するというものです。この研究は、この設計アプローチにより線形の計算複雑さとトークン間の対数依存性が得られることを示しています。これにより、限られた注意リソースとすべてのトークンへのアクセスの間の競合が解決されます。 実装プロセス中に、LONGNET を高密度の Transformer に変換して、既存の Transformer 固有の機能をシームレスにサポートできます。最適化手法 (カーネル融合、量子化、分散トレーニングなど)。線形複雑性を利用して、分散アルゴリズムを使用してコンピューティングとメモリの制約を打ち破り、LONGNET をノード間で並行してトレーニングできます。 最終的に、次の図に示すように、研究によりシーケンス長が 1B トークンまで効果的に拡張され、実行時間はほぼ一定になりました。対照的に、バニラの Transformer のランタイムは 2 次の複雑さの影響を受けます。 #この研究では、多頭拡張型注意メカニズムをさらに紹介します。以下の図 3 に示すように、この研究では、クエリ-キー-値のペアのさまざまな部分をスパース化することで、さまざまなヘッドにわたってさまざまな計算を実行します。 #写真 分散トレーニング##拡張された注意の計算の複雑さは大幅に軽減されましたが、コンピューティングとメモリの制限により、単一の GPU でシーケンスの長さを数百万レベルに拡張することは現実的ではありません。のデバイス。大規模モデルのトレーニングには、モデル並列 [SPP 19]、シーケンス並列 [LXLY21、KCL 22]、パイプライン並列 [HCB 19] などの分散トレーニング アルゴリズムがいくつかありますが、これらの手法は LONGNET にとって十分ではありません。シーケンスの次元が非常に大きい場合。 この研究では、LONGNET の線形計算の複雑さをシーケンス次元の分散トレーニングに利用しています。以下の図 4 は、2 つの GPU 上の分散アルゴリズムを示しています。これは、任意の数のデバイスにさらに拡張できます。 ##実験 さらに、この研究では絶対位置エンコーディングを削除しました。まず、結果は、トレーニング中にシーケンスの長さを増加させると、一般的により良い言語モデルが得られることを示しています。第 2 に、長さがモデルがサポートするよりもはるかに大きい場合、推論におけるシーケンス長の外挿方法は適用されません。最後に、LONGNET は常にベースライン モデルを上回るパフォーマンスを示し、言語モデリングにおけるその有効性を示しています。
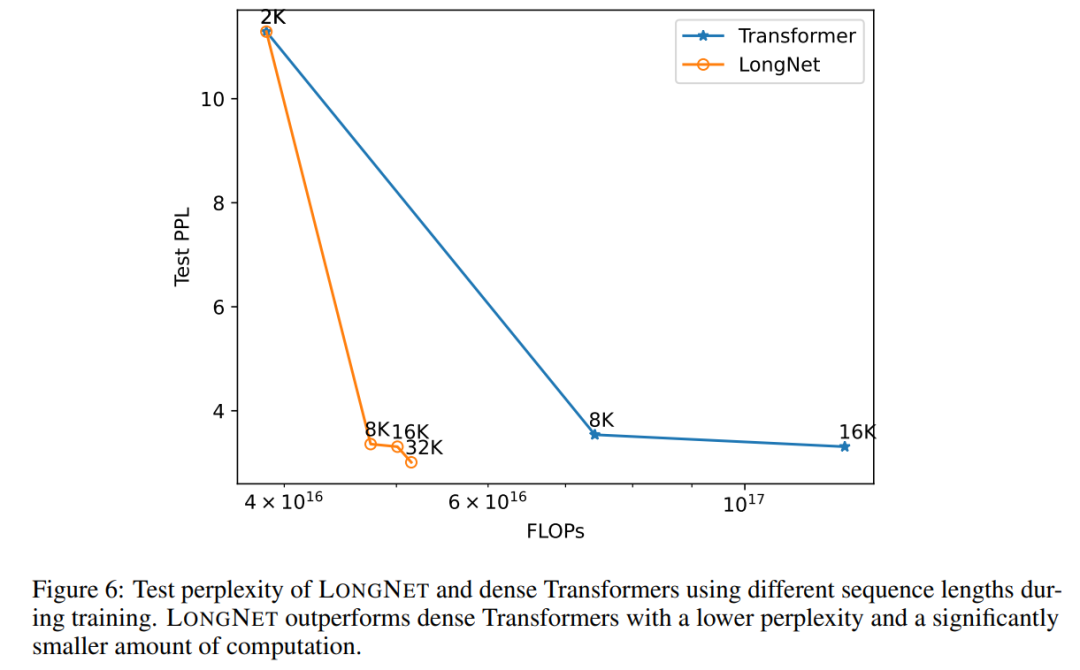
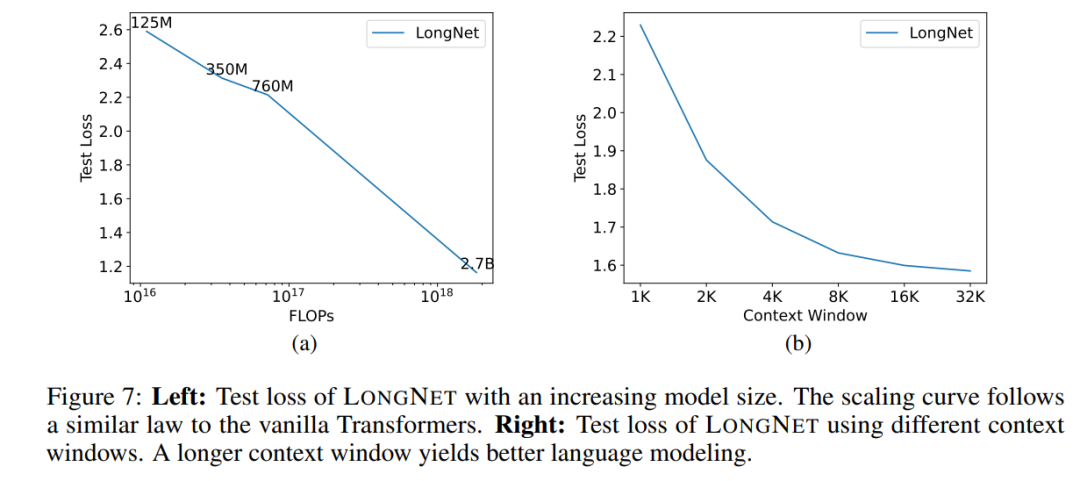
#配列長の展開曲線 図 6 は、バニラ トランスフォーマーと LONGNET のシーケンス長拡張曲線をプロットしています。この研究では、行列乗算の合計フロップ数をカウントすることで計算量を推定します。結果は、バニラ トランスフォーマーと LONGNET の両方がトレーニングからより長いコンテキスト長を達成していることを示しています。ただし、LONGNET はコンテキストの長さをより効率的に拡張できるため、より少ない計算量でより低いテスト損失を実現できます。これは、外挿よりも長いトレーニング入力の利点を示しています。実験によれば、LONGNET は言語モデルのコンテキスト長を拡張するより効率的な方法です。これは、LONGNET がより長い依存関係をより効率的に学習できるためです。 ##モデル サイズの拡張 大規模な言語モデルの重要な特性は、計算量が増加するにつれて損失がべき乗則で拡大することです。 LONGNET が依然として同様のスケーリング ルールに従っているかどうかを検証するために、この研究では、異なるモデル サイズ (1 億 2,500 万から 27 億のパラメーター) で一連のモデルをトレーニングしました。 27 億のモデルは 3,000 億のトークンでトレーニングされ、残りのモデルは約 4,000 億のトークンを使用しました。図 7 (a) は、計算に対する LONGNET の展開曲線をプロットしています。この研究では、同じテストセットの複雑さを計算しました。これは、LONGNET が依然としてべき乗則に従うことができることを証明しています。これは、高密度 Transformer が言語モデルを拡張するための前提条件ではないことも意味します。さらに、LONGNET によりスケーラビリティと効率が向上します。 ##長いコンテキスト プロンプト この研究では、プレフィックス (prefixes) をプロンプトとして保持し、そのサフィックス (suffixes) の複雑さをテストします。さらに、調査の過程で、プロンプトは 2K から 32K まで徐々に拡張されました。公平に比較するために、接尾辞の長さは一定に保たれますが、接頭辞の長さはモデルの最大長まで増加します。図 7(b) は、テスト セットの結果を示しています。コンテキスト ウィンドウが増加するにつれて、LONGNET のテスト損失が徐々に減少することがわかります。これは、言語モデルを改善するために長いコンテキストを最大限に活用する点で LONGNET の優位性を証明しています。 方法
 図
図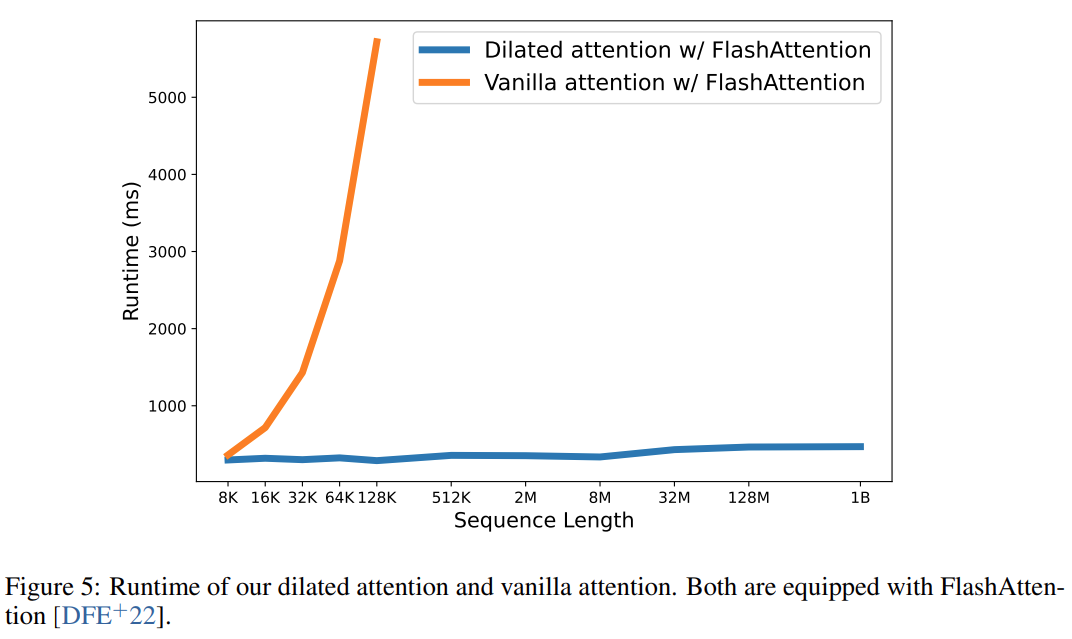
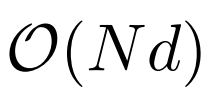
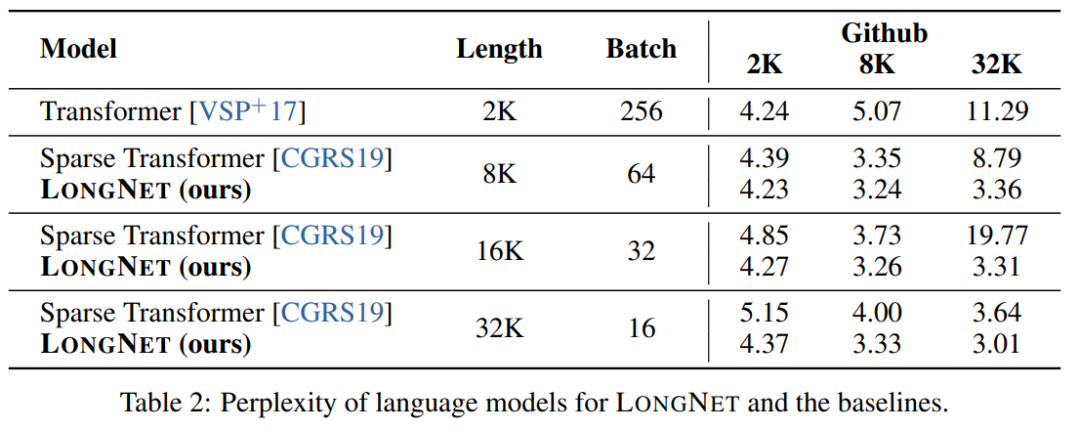
この調査では LONGNET の比較を行います。バニラトランスフォーマーとスパーストランスフォーマーで作成されました。アーキテクチャ間の違いは注目層ですが、他の層は同じです。研究者らは、これらのモデルのシーケンス長を 2K から 32K に拡張しながら、各バッチ内のトークンの数が変わらないようにバッチ サイズを削減しました。 表 2 は、スタック データセットでのこれらのモデルの結果をまとめたものです。研究では評価指標として複雑さを使用します。モデルは、2k から 32k の範囲のさまざまなシーケンス長を使用してテストされました。入力の長さがモデルでサポートされる最大長を超える場合、研究では言語モデル推論のための最先端の外挿方法であるブロックごとの因果的注意 (BCA) [SDP 22] が実装されます。
以上がMicrosoft の新しいホット ペーパー: Transformer が 10 億トークンに拡大の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7469
7469
 15
1376
52
77
11
19
29
15
1376
52
77
11
19
29

![タスクバーにインターネット速度を表示する方法[簡単な手順]](https://img.php.cn/upload/article/000/465/014/169088173253603.png?x-oss-process=image/resize,m_fill,h_207,w_330) タスクバーにインターネット速度を表示する方法[簡単な手順]
Aug 01, 2023 pm 05:22 PM
タスクバーにインターネット速度を表示する方法[簡単な手順]
Aug 01, 2023 pm 05:22 PM
インターネット速度は、オンライン体験の結果を決定する重要なパラメータです。ファイルをダウンロードまたはアップロードする場合でも、単に Web を閲覧する場合でも、私たちは皆、適切なインターネット接続を必要とします。このため、ユーザーはタスクバーにインターネット速度を表示する方法を探しています。タスクバーにネットワーク速度を表示すると、ユーザーは、実行中のタスクに関係なく、状況をすばやく監視できます。タスクバーは、全画面モードでない限り常に表示されます。ただし、Windows には、タスクバーにインターネット速度を表示するネイティブ オプションがありません。そのため、サードパーティのツールが必要です。最適なオプションについてすべて学びましょう。 Windows コマンドラインから速度テストを実行するにはどうすればよいですか? + を押して「ファイル名を指定して実行」を開き、「power Shell」と入力して、++ を押します。窓
 修正: Windows 11 セーフ モードでインターネットにアクセスできないネットワーク接続の問題
Sep 23, 2023 pm 01:13 PM
修正: Windows 11 セーフ モードでインターネットにアクセスできないネットワーク接続の問題
Sep 23, 2023 pm 01:13 PM
セーフ モードとネットワークの Windows 11 コンピューターでインターネットに接続できないと、特にシステムの問題の診断とトラブルシューティングを行うときにイライラすることがあります。このガイドでは、問題の潜在的な原因について説明し、セーフ モードでインターネットにアクセスできるようにするための効果的な解決策をリストします。セーフ モードでネットワークを使用するとインターネットが利用できないのはなぜですか?ネットワーク アダプターに互換性がないか、正しく読み込まれていません。サードパーティ製のファイアウォール、セキュリティ ソフトウェア、またはウイルス対策ソフトウェアが、セーフ モードでのネットワーク接続を妨害する可能性があります。ネットワークサービスが実行されていません。マルウェア感染 Windows 11 でセーフ モードでインターネットが使用できない場合はどうすればよいですか?高度なトラブルシューティング手順を実行する前に、次のチェックを実行することを検討する必要があります。
 Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3 の論文がついに登場しました!このモデルは2週間前にリリースされ、Soraと同じDiT(DiffusionTransformer)アーキテクチャを採用しており、リリースされると大きな話題を呼びました。前バージョンと比較して、StableDiffusion3で生成される画像の品質が大幅に向上し、マルチテーマプロンプトに対応したほか、テキスト書き込み効果も向上し、文字化けが発生しなくなりました。 StabilityAI は、StableDiffusion3 はパラメータ サイズが 800M から 8B までの一連のモデルであると指摘しました。このパラメーター範囲は、モデルを多くのポータブル デバイス上で直接実行できることを意味し、AI の使用を大幅に削減します。
 ICCV'23論文賞「Fighting of Gods」! Meta Divide Everything と ControlNet が共同で選ばれました、審査員を驚かせた記事がもう 1 つありました
Oct 04, 2023 pm 08:37 PM
ICCV'23論文賞「Fighting of Gods」! Meta Divide Everything と ControlNet が共同で選ばれました、審査員を驚かせた記事がもう 1 つありました
Oct 04, 2023 pm 08:37 PM
フランスのパリで開催されたコンピュータービジョンのトップカンファレンス「ICCV2023」が閉幕しました。今年の論文賞はまさに「神と神の戦い」です。たとえば、最優秀論文賞を受賞した 2 つの論文には、ヴィンセント グラフ AI の分野を覆す研究である ControlNet が含まれていました。 ControlNet はオープンソース化されて以来、GitHub で 24,000 個のスターを獲得しています。拡散モデルであれ、コンピュータ ビジョンの全分野であれ、この論文の賞は当然のことです。最優秀論文賞の佳作は、同じく有名なもう 1 つの論文、Meta の「Separate Everything」「Model SAM」に授与されました。 「Segment Everything」は、発売以来、後発のものも含め、さまざまな画像セグメンテーション AI モデルの「ベンチマーク」となっています。
 NeRFと自動運転の過去と現在、10本近くの論文をまとめました!
Nov 14, 2023 pm 03:09 PM
NeRFと自動運転の過去と現在、10本近くの論文をまとめました!
Nov 14, 2023 pm 03:09 PM
Neural Radiance Fieldsは2020年に提案されて以来、関連論文の数が飛躍的に増加し、3次元再構成の重要な分野となっただけでなく、自動運転の重要なツールとして研究の最前線でも徐々に活発になってきています。 NeRF は、過去 2 年間で突然出現しました。その主な理由は、特徴点の抽出とマッチング、エピポーラ幾何学と三角形分割、PnP とバンドル調整、および従来の CV 再構成パイプラインのその他のステップをスキップし、メッシュ再構成、マッピング、ライト トレースさえもスキップするためです。 、2D から直接入力画像を使用して放射線野を学習し、実際の写真に近いレンダリング画像が放射線野から出力されます。言い換えれば、ニューラル ネットワークに基づく暗黙的な 3 次元モデルを指定されたパースペクティブに適合させます。
 紙のイラストも拡散モデルを使用して自動生成でき、ICLR にも受け入れられます。
Jun 27, 2023 pm 05:46 PM
紙のイラストも拡散モデルを使用して自動生成でき、ICLR にも受け入れられます。
Jun 27, 2023 pm 05:46 PM
生成 AI は人工知能コミュニティに旋風を巻き起こし、個人も企業も、Vincent 写真、Vincent ビデオ、Vincent 音楽など、関連するモーダル変換アプリケーションの作成に熱心になり始めています。最近、ServiceNow Research や LIVIA などの科学研究機関の数人の研究者が、テキストの説明に基づいて論文内のグラフを生成しようとしました。この目的のために、彼らは FigGen の新しい手法を提案し、関連する論文も TinyPaper として ICLR2023 に掲載されました。絵用紙のアドレス: https://arxiv.org/pdf/2306.00800.pdf 絵用紙のチャートを生成するのは何がそんなに難しいのかと疑問に思う人もいるかもしれません。これは科学研究にどのように役立ちますか?
 チャットのスクリーンショットから AI レビューの隠されたルールが明らかになります。 AAAI 3000元は強力に受け入れられますか?
Apr 12, 2023 am 08:34 AM
チャットのスクリーンショットから AI レビューの隠されたルールが明らかになります。 AAAI 3000元は強力に受け入れられますか?
Apr 12, 2023 am 08:34 AM
AAAI 2023 の論文提出期限が近づいていたとき、AI 投稿グループの匿名チャットのスクリーンショットが突然 Zhihu に表示されました。そのうちの1人は、「3,000元で強力なサービスを提供できる」と主張した。このニュースが発表されるとすぐに、ネットユーザーの間で国民の怒りを引き起こした。ただし、まだ急ぐ必要はありません。 Zhihuのボス「Fine Tuning」は、これはおそらく単に「言葉による喜び」である可能性が高いと述べた。 『ファイン・チューニング』によると、挨拶や集団犯罪はどの分野でも避けられない問題だという。 openreview の台頭により、cmt のさまざまな欠点がますます明らかになり、小さなサークルが活動できる余地は将来的には小さくなるでしょうが、余地は常にあります。これは個人の問題であり、投稿システムや仕組みの問題ではないからです。オープンRの紹介
 CVPR 2023 ランキング発表、採択率は 25.78%! 2,360 件の論文が受理され、投稿数は 9,155 件に急増しました。
Apr 13, 2023 am 09:37 AM
CVPR 2023 ランキング発表、採択率は 25.78%! 2,360 件の論文が受理され、投稿数は 9,155 件に急増しました。
Apr 13, 2023 am 09:37 AM
ちょうど今、CVPR 2023 が次のような記事を発表しました: 今年は記録的な 9,155 件の論文 (CVPR2022 より 12% 増) を受け取り、2,360 件の論文を受理し、受理率は 25.78% でした。統計によると、CVPRへの投稿数は2010年から2016年の7年間で1,724件から2,145件に増加しただけです。 2017年以降は急上昇して高度成長期に入り、2019年には初めて5,000件を超え、2022年には投稿数が8,161件に達した。ご覧のとおり、今年は合計 9,155 件の論文が投稿され、確かに記録を樹立しました。流行が緩和された後、今年のCVPRサミットはカナダで開催される予定だ。今年はシングルトラックカンファレンスとなり、従来の口頭選考は中止される。グーグルリサーチ
