
 テクノロジー周辺機器
AI
チェン・ダンチー選手のACLアカデミックレポートはこちら!大型モデル「プラグイン」データベースの7つの大きな方向性と3つの大きな課題を詳しく解説、役立つ情報が満載の3時間
テクノロジー周辺機器
AI
チェン・ダンチー選手のACLアカデミックレポートはこちら!大型モデル「プラグイン」データベースの7つの大きな方向性と3つの大きな課題を詳しく解説、役立つ情報が満載の3時間
チェン・ダンチー選手のACLアカデミックレポートはこちら!大型モデル「プラグイン」データベースの7つの大きな方向性と3つの大きな課題を詳しく解説、役立つ情報が満載の3時間

清華ヤオクラス同窓生チェン・ダンチーがACL 2023で最新のスピーチを行いました!
このトピックは、最近でも非常に注目されている研究方向です -
(big)GPT-3 や PaLM などの言語モデル アプリケーションをより適切に実装するには、retrieval に依存してそれ自体の欠点を補う必要があります。
この講演では、彼女と他の 3 人の講演者が共同で、トレーニング方法、応用、課題など、このテーマに関するいくつかの主要な研究の方向性を紹介しました。
 写真
写真
スピーチ中の聴衆の反応も非常に熱心で、多くのネチズンが真剣に質問し、何人かの講演者が一生懸命答えようとしました。彼らの質問。
 写真
写真
このスピーチの具体的な効果については?一部のネチズンはコメント欄に直接「推薦」と言ってきた。
 写真
写真
それでは、この 3 時間のスピーチで彼らは一体何を話したのでしょうか?他に聞く価値のある場所は何ですか?
大規模なモデルに「プラグイン」データベースが必要なのはなぜですか?
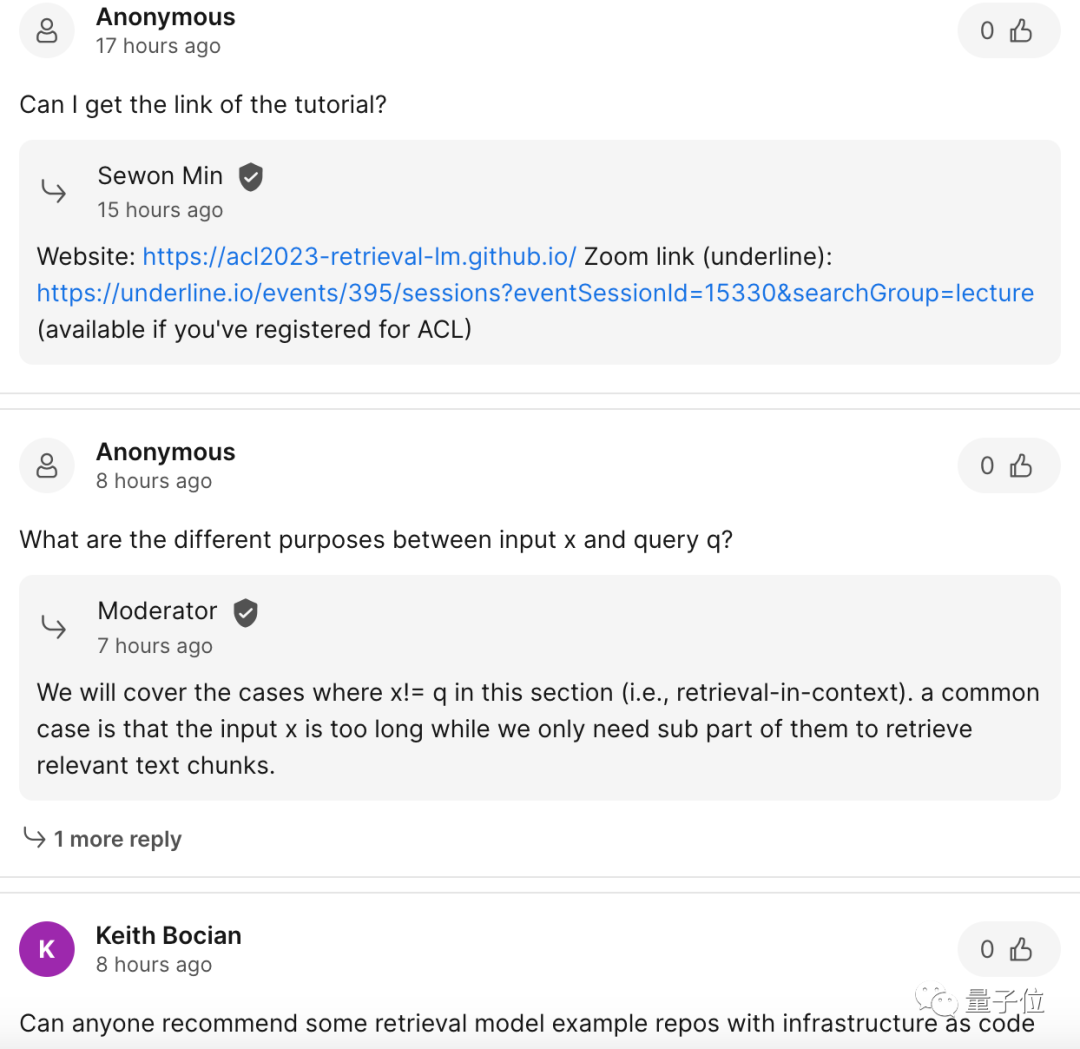
この講演の中核テーマは「検索ベースの言語モデル」で、これには 検索 と 言語モデル という 2 つの要素が含まれます。
定義から、データ検索データベースを言語モデルに「プラグイン」し、推論 (操作など) を実行するときにこのデータベースを使用することを指します 検索を実行し、検索結果に基づいて最終的に出力します。
このタイプのプラグイン データ リポジトリは、セミパラメトリック モデルまたはノンパラメトリック モデルとも呼ばれます。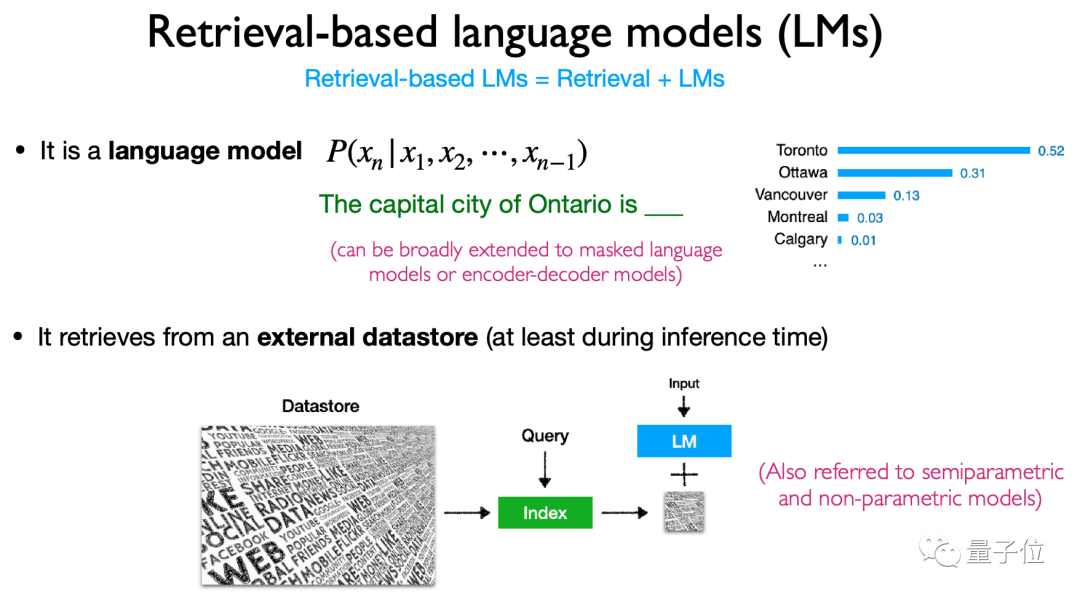 写真
写真
(大) 言語モデルのためです。と PaLM は良い結果を示しましたが、いくつかの厄介な「バグ」も発生しました。主な問題は 3 つです:
1. パラメータの数が多すぎます。新しいデータ、トレーニング、計算コストが高すぎる;
2、記憶力が乏しい (長いテキストに直面すると、下の方は覚えていて上は忘れる)、時間の経過とともに、幻覚を引き起こし、データ漏洩が起こりやすい;
3, 現在のパラメータの量では、すべての知識を記憶することは不可能です。
アーキテクチャ、トレーニング、マルチモダリティ、アプリケーション、課題 について説明します。
アーキテクチャでは、主に言語モデル検索に基づく内容、検索方法、検索「タイミング」について紹介します。 具体的には、このタイプのモデルは主にトークン、テキスト ブロック、エンティティの単語
(エンティティの言及)を取得します。取得の方法やタイミングも非常に多様であり、非常に柔軟です。タイプ、モデル アーキテクチャ。
写真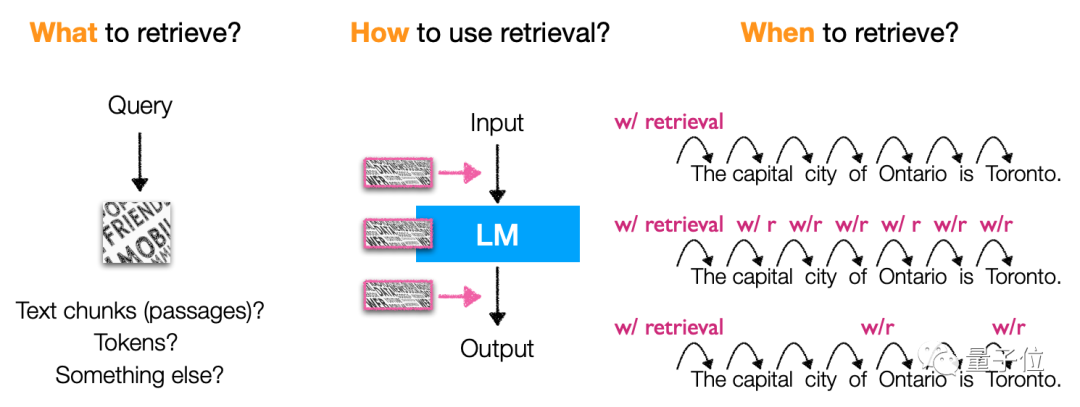
メソッドの観点からは、独立トレーニング(独立トレーニング、言語モデル、検索)に焦点を当てています。個別トレーニング)、継続学習 (逐次トレーニング)、マルチタスク学習 (共同トレーニング) などの手法をモデル化します。
図
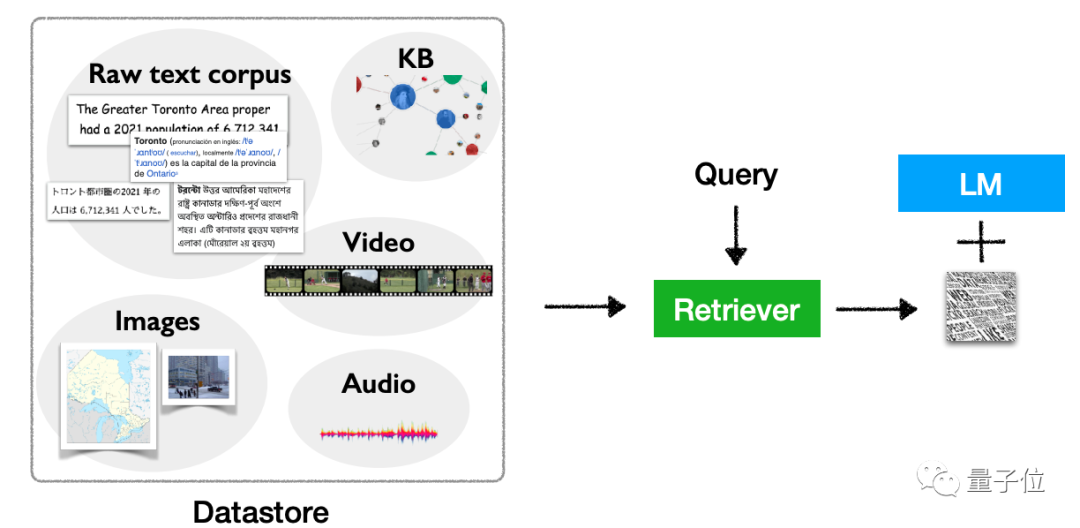
に関しては、このタイプのモデルにはさらに多くのことが含まれており、コード生成で使用できるだけでなく、分類や知識集約的な NLP などのタスクに使用でき、微調整、強化学習、検索ベースのプロンプト ワードなどの方法を通じて使用できます。 アプリケーション シナリオも非常に柔軟で、ロングテール シナリオ、知識の更新が必要なシナリオ、プライバシーとセキュリティに関係するシナリオなどが含まれます。このタイプのモデルは使用される場所があります。
もちろん、テキストだけではありません。このタイプのモデルには、テキスト以外のタスクに使用できる multimodal 拡張機能の可能性もあります。
 写真
写真
このタイプのモデルには多くの利点があるように思えますが、検索に基づいたいくつかの 課題もあります。ベースの言語モデル。
最後の「終わりの」スピーチで、Chen Danqi 氏は、この研究の方向性で解決する必要があるいくつかの主要な問題を強調しました。
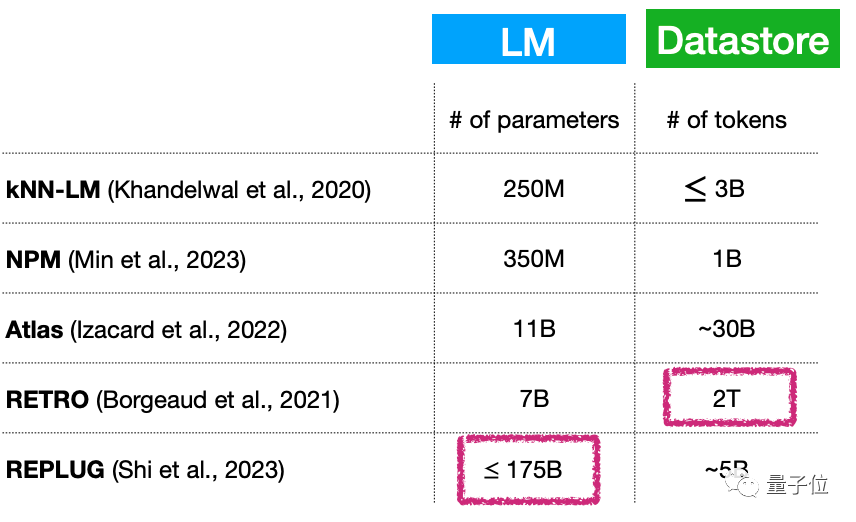
まず、小規模な言語モデル (継続的に拡張中) データベースが大きいということは、本質的に、言語モデルのパラメータの数が依然として非常に多いことを意味するのでしょうか?この問題を解決するにはどうすればよいでしょうか?
たとえば、このタイプのモデルのパラメータ量は非常に少なく、わずか 70 億パラメータですが、プラグイン データベースは 2T に達する可能性があります...
 #Picture
#Picture
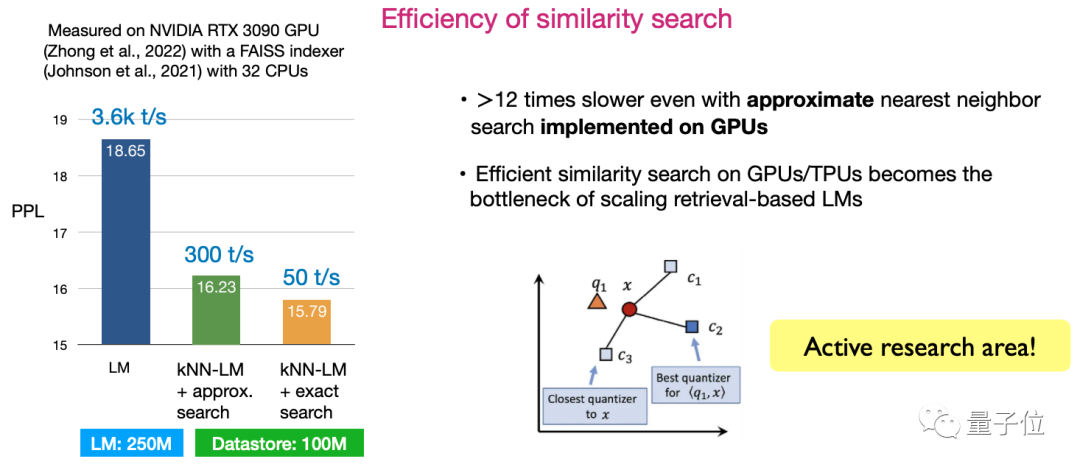
2 つ目は、類似性検索の効率です。検索効率を最大化するアルゴリズムを設計する方法は、現在非常に活発な研究方向です。
 図
図
3 番目の、複雑な言語タスクを完了します。オープンエンドのテキスト生成タスクや複雑なテキスト推論タスクを含め、検索ベースの言語モデルを使用してこれらのタスクを完了する方法も、継続的な探索が必要な方向性です。
 写真
写真
もちろん、Chen Danqi 氏は、これらのテーマは課題であるだけでなく、研究の機会でもあるとも述べました。まだ論文のテーマを探している友達は、研究リストに追加するかどうかを検討してください~
このスピーチは「何もないところから」出てきたテーマではないことを言及する価値があります。私が思慮深く投稿した 4 人の講演者公式ウェブサイト上のスピーチの参考文献へのリンク。
モデル アーキテクチャ、トレーニング方法、アプリケーション、マルチモダリティから課題まで、これらのトピックの一部に興味がある場合は、公式 Web サイトにアクセスして、対応する古典的な論文を見つけることができます。
 写真
写真
聴衆の混乱にその場で答える
非常に有益なスピーチであり、4 人の基調講演者には背景がないわけではありません。講演中は辛抱強く話し、聴衆からの質問にも答えました。
まず、Kangkang の講演者について話しましょう。
一人目は、この講演を主導したプリンストン大学コンピューターサイエンス助教授のChen Danqiです。
 写真
写真
CDQ 分割統治アルゴリズムは彼女にちなんで名付けられました。 2008年、彼女は中国チームを代表してIOI金メダルを獲得した。
そして、彼女の 156 ページの博士論文「Neural Reading Comprehension and Beyond」はかつて非常に人気になり、その年のスタンフォード最優秀博士論文賞を受賞しただけでなく、最近のスタンフォード大学の賞にもなりました。この10年間で最も人気のある卒業論文。 現在、Chen Danqi は、プリンストン大学のコンピューター サイエンスの助教授であることに加えて、同校の NLP チームの共同リーダーであり、AIML チームのメンバーでもあります。 彼女の研究関心は主に自然言語処理と機械学習に焦点を当てており、実際の問題において実現可能でスケーラブルで一般化可能な、シンプルで信頼性の高い方法に興味を持っています。 同じくプリンストン大学出身で、陳丹祁の弟子であるZhong Zexuan(Zexuan Zhong)もいます。
 写真
写真
彼の最新の研究は、非構造化テキストからの構造化情報の抽出、事前トレーニングされた言語モデルからの事実情報の抽出、高密度検索モデルの一般化能力の分析、および検索ベースのトレーニング手法に適した言語モデルの開発に焦点を当てています。
さらに、基調講演者には、ワシントン大学の浅井あかり氏とセウォン・ミン氏が参加します。
 写真
写真
Akari Asai は、ワシントン大学の博士課程 4 年生で、自然言語処理を専攻しています。東京大学を卒業。
彼女は主に、情報取得を向上させるための信頼性が高く適応性のある自然言語処理システムを開発することに興味を持っています。
最近、彼女の研究は一般知識検索システム、効率的な適応型 NLP モデル、その他の分野に焦点を当てています。
 写真
写真
Sewon Min は、ワシントン大学の自然言語処理グループの博士候補者です。 、彼はメタAIで働いていました 彼は研究者として4年間アルバイトとして働き、ソウル大学を学士号を取得して卒業しました。
最近、彼女は言語モデリング、検索、およびその 2 つの交差点に焦点を当てています。
スピーチ中、聴衆からは、なぜperplexity (perplexity)がスピーチの主な指標として使われるのかなど、多くの質問が熱心に出されていました。
 写真
写真
講演者は詳細な答えを出しました:
パラメータ化された言語モデルを比較するときの混乱の程度 (PPL ) がよく使われます。しかし、複雑さの改善を下流のアプリケーションに応用できるかどうかは研究課題として残っています。
研究によると、パープレキシティは下流のタスク (特に生成タスク) と良好な相関関係があり、パープレキシティは通常、大規模な評価データの評価に使用できる非常に安定した結果を提供します (下流タスクと比較して、評価データにはラベルが付けられていないため、下流タスクはキューの感度や大規模なラベル付きデータの欠如の影響を受ける可能性があり、結果が不安定になる可能性があります) 。
 写真
写真
一部のネチズンがこの質問を提起しました:
「言語モデルのトレーニングコストが高く、導入この問題は取得によって解決される可能性があります。」という質問は、時間計算量を空間計算量 (データ ストレージ) に置き換えただけですか?

講演者の答えは、江おばさんの答えです:
私たちの議論の焦点は、言語モデルをどのように縮小するかということです。小さいサイズ: 小さいため、必要な時間とスペースが削減されます。ただし、データ ストレージは実際には追加のオーバーヘッドも追加するため、慎重に比較検討する必要があり、これが現在の課題であると考えています。
100億を超えるパラメータを持つ言語モデルを訓練するのと比較して、現時点で最も重要なことは訓練コストを削減することだと思います。
 写真
写真
このスピーチの PPT または特定の再生を見つけたい場合は、公式 Web サイトにアクセスしてください。見てください~
公式ウェブサイト: https://acl2023-retrieval-lm.github.io/
以上がチェン・ダンチー選手のACLアカデミックレポートはこちら!大型モデル「プラグイン」データベースの7つの大きな方向性と3つの大きな課題を詳しく解説、役立つ情報が満載の3時間の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
19
20
15
1376
52
77
11
19
20

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
ソフトウェア テクノロジの最前線に立つ UIUC Zhang Lingming のグループは、BigCode 組織の研究者とともに、最近 StarCoder2-15B-Instruct 大規模コード モデルを発表しました。この革新的な成果により、コード生成タスクにおいて大きな進歩が達成され、CodeLlama-70B-Instruct を上回り、コード生成パフォーマンス リストのトップに到達しました。 StarCoder2-15B-Instruct のユニークな特徴は、その純粋な自己調整戦略であり、トレーニング プロセス全体がオープンで透過的で、完全に自律的で制御可能です。このモデルは、高価な手動アノテーションに頼ることなく、StarCoder-15B 基本モデルの微調整に応じて、StarCoder2-15B を介して数千の命令を生成します。
 総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
大規模言語モデル (LLM) を人間の価値観や意図に合わせるには、人間のフィードバックを学習して、それが有用で、正直で、無害であることを確認することが重要です。 LLM を調整するという点では、ヒューマン フィードバックに基づく強化学習 (RLHF) が効果的な方法です。 RLHF 法の結果は優れていますが、最適化にはいくつかの課題があります。これには、報酬モデルをトレーニングし、その報酬を最大化するためにポリシー モデルを最適化することが含まれます。最近、一部の研究者はより単純なオフライン アルゴリズムを研究しており、その 1 つが直接優先最適化 (DPO) です。 DPO は、RLHF の報酬関数をパラメータ化することで、選好データに基づいてポリシー モデルを直接学習するため、明示的な報酬モデルの必要性がなくなります。この方法は簡単で安定しています
 Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
Jun 07, 2024 pm 12:05 PM
Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
Jun 07, 2024 pm 12:05 PM
1. はじめに ここ数年、YOLO は、計算コストと検出パフォーマンスの効果的なバランスにより、リアルタイム物体検出の分野で主流のパラダイムとなっています。研究者たちは、YOLO のアーキテクチャ設計、最適化目標、データ拡張戦略などを調査し、大きな進歩を遂げました。同時に、後処理に非最大抑制 (NMS) に依存すると、YOLO のエンドツーエンドの展開が妨げられ、推論レイテンシに悪影響を及ぼします。 YOLO では、さまざまなコンポーネントの設計に包括的かつ徹底的な検査が欠けており、その結果、大幅な計算冗長性が生じ、モデルの機能が制限されます。効率は最適ではありませんが、パフォーマンス向上の可能性は比較的大きくなります。この作業の目標は、後処理とモデル アーキテクチャの両方から YOLO のパフォーマンス効率の境界をさらに改善することです。この目的を達成するために
 LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
上記と著者の個人的な理解: この論文は、自動運転アプリケーションにおける現在のマルチモーダル大規模言語モデル (MLLM) の主要な課題、つまり MLLM を 2D 理解から 3D 空間に拡張する問題の解決に特化しています。自動運転車 (AV) は 3D 環境について正確な決定を下す必要があるため、この拡張は特に重要です。 3D 空間の理解は、情報に基づいて意思決定を行い、将来の状態を予測し、環境と安全に対話する車両の能力に直接影響を与えるため、AV にとって重要です。現在のマルチモーダル大規模言語モデル (LLaVA-1.5 など) は、ビジュアル エンコーダーの解像度制限や LLM シーケンス長の制限により、低解像度の画像入力しか処理できないことがよくあります。ただし、自動運転アプリケーションには次の要件が必要です。
 清華大学が引き継ぎ、YOLOv10 が登場しました。パフォーマンスが大幅に向上し、GitHub のホット リストに掲載されました。
Jun 06, 2024 pm 12:20 PM
清華大学が引き継ぎ、YOLOv10 が登場しました。パフォーマンスが大幅に向上し、GitHub のホット リストに掲載されました。
Jun 06, 2024 pm 12:20 PM
ターゲット検出システムのベンチマークである YOLO シリーズが再び大幅にアップグレードされました。今年 2 月の YOLOv9 のリリース以来、YOLO (YouOnlyLookOnce) シリーズのバトンは清華大学の研究者の手に渡されました。先週末、YOLOv10 のリリースのニュースが AI コミュニティの注目を集めました。これは、コンピュータ ビジョンの分野における画期的なフレームワークと考えられており、リアルタイムのエンドツーエンドの物体検出機能で知られており、効率と精度を組み合わせた強力なソリューションを提供することで YOLO シリーズの伝統を継承しています。論文アドレス: https://arxiv.org/pdf/2405.14458 プロジェクトアドレス: https://github.com/THU-MIG/yo
 リー・フェイフェイが「空間インテリジェンス」の起業家的な方向性を明らかにする: 視覚化は洞察に変わり、見ることは理解に変わり、理解は行動につながる
Jun 01, 2024 pm 02:55 PM
リー・フェイフェイが「空間インテリジェンス」の起業家的な方向性を明らかにする: 視覚化は洞察に変わり、見ることは理解に変わり、理解は行動につながる
Jun 01, 2024 pm 02:55 PM
スタンフォード大学のリー・フェイフェイ氏は、起業後初めて「空間インテリジェンス」という新しい概念を発表した。これは彼女の起業家としての方向性であるだけでなく、彼女を導く「北極星」でもあり、彼女はそれが「人工知能の問題を解決するための重要なパズルのピース」であると考えています。視覚化は洞察につながり、理解は行動につながります。リー・フェイフェイの 15 分間の TED トークに基づいて、数億年前の生命進化の起源から、人間が自然から与えられたものに満足できず人工知能を開発し、どのように人工知能を構築するかまで完全に明らかにされています。次のステップでは空間インテリジェンスを学びます。 9 年前、Li Feifei は、同じステージで新しく生まれた ImageNet を世界に紹介しました。これは、ディープラーニングの爆発的な今回のラウンドの出発点の 1 つです。彼女自身もネチズンに「両方のビデオを見れば、過去 10 年間のコンピュータ ビジョンを理解できるでしょう」と激励しました。
