

Go でのメモリ割り当てについて説明した記事
#今日は、Go のメモリ管理に関する一般的な知識ポイントをいくつか共有します。
# 1. メモリ割り当ての 3 つの主要なコンポーネント
Go でのメモリ割り当てのプロセスは次のとおりです。主に 3 つで構成されます。大きなコンポーネントによって管理されるレベルは、上から下まで次のとおりです。mheap
プログラムが開始されると、Go はまず大きなメモリを申請します。オペレーティング システムからの情報を取得し、mheap 構造のグローバル管理に委ねられます。
mcentral
Go プログラムを開始すると、多くの mcentral が初期化されます。各 mcentral は、次のレベルのコンポーネントのみを担当します。特定の仕様の mspan を管理します。 mheap に基づいた mspan の洗練された管理を実装する mcentral と同等。 しかし、mcentral は Go プログラム内でグローバルに表示されるため、コルーチンがメモリを適用するために mcentral に来るたびに、ロックする必要があります。 各コルーチンがメモリを申請するために mcentral に来る場合、頻繁なロックと解放によるオーバーヘッドが非常に大きくなることが予想されます。 したがって、この圧力を緩衝するために mcentral のセカンダリ プロキシが必要ですmcache
Go プログラムでは、各スレッド M が単一の粒度でプロセッサ P にバインドされます。 goroutine はマルチ処理中に実行でき、各 P は mcache というローカル キャッシュにバインドされます。
メモリ割り当てが必要な場合、現在実行中の ゴルーチンは、利用可能な mspan を mcache から探します。ローカルの mcache からメモリを割り当てるときにロックする必要はありません。この割り当て戦略はより効率的です。
mspan サプライ チェーン
mcache の mspan の数は必ずしも十分ではありません。供給が需要を超えると、mcache は mcentral からより多くの mspan を再度申請します。 、mcentral の mspan の数が十分でない場合、mcentral は上位の mheap からの mspan も適用します。もっと極端に言えば、mheap の mspan がプログラムのメモリ要求を満たすことができない場合はどうすればよいでしょうか?
他に方法はありません。mheap は、恥知らずにもオペレーティング システムの兄貴分にのみ適用できます。
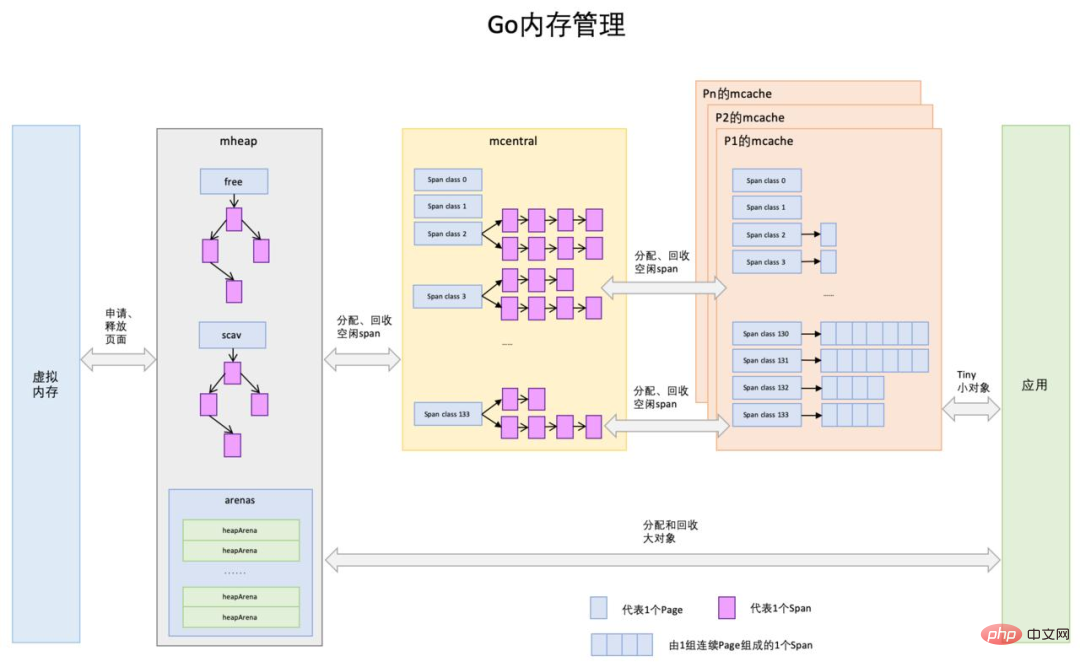
上記の供給プロセスは、メモリ ブロックが 64KB 未満のシナリオにのみ適用できます。その理由は、Go がワーカー スレッド mcache のローカル キャッシュとグローバル中央キャッシュ を使用できないためです。 mcentral は 64KB を超えるメモリ割り当てを管理するため、64KB を超えるメモリ アプリケーションの場合、対応する数のメモリ ページ (各ページ サイズは 8KB) がヒープ (mheap) から直接割り当てられます。プログラム。
# 2. ヒープ メモリとスタック メモリとは何ですか?
さまざまなメモリ管理 (割り当てとリサイクル) 方法に従って、メモリは ヒープ メモリ と スタック メモリ に分類できます。
それでは、それらの違いは何でしょうか?
ヒープ メモリ: メモリ アロケータとガベージ コレクタは、リサイクルを担当します。
スタック メモリ: コンパイラによって自動的に割り当ておよび解放されます
プログラムの実行中は複数のスタック メモリが存在する可能性がありますが、ヒープ メモリは確実に 1 つだけです。
各スタック メモリはスレッドまたはコルーチンによって独立して占有されるため、スタックからのメモリ割り当てにはロックが必要なく、関数終了後にスタック メモリは自動的にリサイクルされ、パフォーマンスはヒープメモリ。
では、ヒープ メモリについてはどうでしょうか?複数のスレッドまたはコルーチンが同時にヒープからメモリを申請する可能性があるため、ヒープ内のメモリを申請するには競合を避けるためにロックする必要があり、関数終了後にヒープ メモリには GC (ガベージ コレクション) の介入が必要です。 GC 操作の回数が多いと、プログラムのパフォーマンスが大幅に低下します。
# 3. エスケープ解析の必要性
プログラムのパフォーマンスを向上させるためには、メモリ内のメモリが必要であることがわかります。ヒープを最小化する必要があります。これにより、GC への負担が軽減されます。
変数にメモリがヒープ上に割り当てられるかスタック上に割り当てられるかを決定する際、先人がいくつかのルールをまとめましたが、コーディング時にこの問題に常に注意を払うのはプログラマの責任です。プログラマの要件は次のとおりです。かなり高い。
幸いなことに、Go コンパイラにはエスケープ解析機能も用意されており、エスケープ解析を使用すると、プログラマがヒープ上に割り当てたすべての変数を直接検出できます (この現象はエスケープと呼ばれます)。
方法は以下のコマンドを実行することです
go build -gcflags '-m -l' demo.go # 或者再加个 -m 查看更详细信息 go build -gcflags '-m -m -l' demo.go
#メモリ割り当て位置のルール
分析ツールをエスケープすると、実際にどの変数がヒープに割り当てられているかを手動で決定できます。
それでは、これらのルールとは何でしょうか?
#変数の使用範囲により、主に以下の 4 つの状況が考えられます。
- #変数の種類に基づいて決定
次に 1 つずつ分析して検証します
-
According変数の使用範囲へ
#コンパイル時にコンパイラはエスケープ解析を行い、変数が関数内でのみ使用されていることが判明した場合、その変数にメモリを割り当てることができます。スタック。
func foo() int {
v := 1024
return v
}
func main() {
m := foo()
fmt.Println(m)
}go build -gcflags '-m -l' Demon.go を通じてエスケープ分析の結果を表示できます。 -m
はエスケープ解析情報を出力し、-l
はインライン最適化を無効にします。 分析結果から、v 変数に関するエスケープ命令は見られませんでした。これは、変数がエスケープされず、スタックに割り当てられたことを示しています。$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:12:13: ... argument does not escape ./demo.go:12:13: m escapes to heap
変数を関数のスコープ外で使用する必要があり、変数がまだスタックに割り当てられている場合、関数が戻ると、変数が指すメモリ空間がリサイクルされます。プログラムは必然的にエラーを報告するため、そのような変数はヒープ上にのみ割り当てることができます。 たとえば、以下の例では、 はポインタを返します func foo() *int {
v := 1024
return &v
}
func main() {
m := foo()
fmt.Println(*m) // 1024
}moved to heap: v## であることがわかります。 # , v 変数はヒープから割り当てられたメモリーであり、上記のシナリオとは明らかに異なります。
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:6:2: moved to heap: v ./demo.go:12:13: ... argument does not escape ./demo.go:12:14: *m escapes to heap
除了返回指针之外,还有其他的几种情况也可归为一类:
第一种情况:返回任意引用型的变量:Slice 和 Map
func foo() []int {
a := []int{1,2,3}
return a
}
func main() {
b := foo()
fmt.Println(b)
}逃逸分析结果
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:6:12: []int literal escapes to heap ./demo.go:12:13: ... argument does not escape ./demo.go:12:13: b escapes to heap
第二种情况:在闭包函数中使用外部变量
func Increase() func() int {
n := 0
return func() int {
n++
return n
}
}
func main() {
in := Increase()
fmt.Println(in()) // 1
fmt.Println(in()) // 2
}逃逸分析结果
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:6:2: moved to heap: n ./demo.go:7:9: func literal escapes to heap ./demo.go:15:13: ... argument does not escape ./demo.go:15:16: in() escapes to heap
根据变量类型是否确定
在上边例子中,也许你发现了,所有编译输出的最后一行中都是 m escapes to heap 。
奇怪了,为什么 m 会逃逸到堆上?
其实就是因为我们调用了 fmt.Println() 函数,它的定义如下
func Println(a ...interface{}) (n int, err error) {
return Fprintln(os.Stdout, a...)
}可见其接收的参数类型是 interface{} ,对于这种编译期不能确定其参数的具体类型,编译器会将其分配于堆上。
根据变量的占用大小
最开始的时候,就介绍到,以 64KB 为分界线,我们将内存块分为 小内存块 和 大内存块。
小内存块走常规的 mspan 供应链申请,而大内存块则需要直接向 mheap,在堆区申请。
以下的例子来说明
func foo() {
nums1 := make([]int, 8191) // < 64KB
for i := 0; i < 8191; i++ {
nums1[i] = i
}
}
func bar() {
nums2 := make([]int, 8192) // = 64KB
for i := 0; i < 8192; i++ {
nums2[i] = i
}
}给 -gcflags 多加个 -m 可以看到更详细的逃逸分析的结果
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:5:15: make([]int, 8191) does not escape ./demo.go:12:15: make([]int, 8192) escapes to heap
那为什么是 64 KB 呢?
我只能说是试出来的 (8191刚好不逃逸,8192刚好逃逸),网上有很多文章千篇一律的说和 ulimit -a 中的 stack size 有关,但经过了解这个值表示的是系统栈的最大限制是 8192 KB,刚好是 8M。
$ ulimit -a -t: cpu time (seconds) unlimited -f: file size (blocks) unlimited -d: data seg size (kbytes) unlimited -s: stack size (kbytes) 8192
我个人实在无法理解这个 8192 (8M) 和 64 KB 是如何对应上的,如果有朋友知道,还请指教一下。
根据变量长度是否确定
由于逃逸分析是在编译期就运行的,而不是在运行时运行的。因此避免有一些不定长的变量可能会很大,而在栈上分配内存失败,Go 会选择把这些变量统一在堆上申请内存,这是一种可以理解的保险的做法。
func foo() {
length := 10
arr := make([]int, 0 ,length) // 由于容量是变量,因此不确定,因此在堆上申请
}
func bar() {
arr := make([]int, 0 ,10) // 由于容量是常量,因此是确定的,因此在栈上申请
}以上がGo でのメモリ割り当てについて説明した記事の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7508
7508
 15
1378
52
78
11
19
58
15
1378
52
78
11
19
58

 Golang 関数のライフサイクルと変数スコープの深い理解
Apr 19, 2024 am 11:42 AM
Golang 関数のライフサイクルと変数スコープの深い理解
Apr 19, 2024 am 11:42 AM
Go では、関数のライフ サイクルには定義、ロード、リンク、初期化、呼び出し、戻り値が含まれます。変数のスコープは関数レベルとブロック レベルに分割されますが、ブロック内の変数はブロック内でのみ表示されます。 。
 Go で正規表現を使用してタイムスタンプを照合するにはどうすればよいですか?
Jun 02, 2024 am 09:00 AM
Go で正規表現を使用してタイムスタンプを照合するにはどうすればよいですか?
Jun 02, 2024 am 09:00 AM
Go では、正規表現を使用してタイムスタンプを照合できます。ISO8601 タイムスタンプの照合に使用されるような正規表現文字列をコンパイルします。 ^\d{4}-\d{2}-\d{2}T \d{ 2}:\d{2}:\d{2}(\.\d+)?(Z|[+-][0-9]{2}:[0-9]{2})$ 。 regexp.MatchString 関数を使用して、文字列が正規表現と一致するかどうかを確認します。
 Go WebSocket メッセージを送信するにはどうすればよいですか?
Jun 03, 2024 pm 04:53 PM
Go WebSocket メッセージを送信するにはどうすればよいですか?
Jun 03, 2024 pm 04:53 PM
Go では、gorilla/websocket パッケージを使用して WebSocket メッセージを送信できます。具体的な手順: WebSocket 接続を確立します。テキスト メッセージを送信します。 WriteMessage(websocket.TextMessage,[]byte("message")) を呼び出します。バイナリ メッセージを送信します。WriteMessage(websocket.BinaryMessage,[]byte{1,2,3}) を呼び出します。
 GolangとGo言語の違い
May 31, 2024 pm 08:10 PM
GolangとGo言語の違い
May 31, 2024 pm 08:10 PM
Go と Go 言語は、異なる特性を持つ別個の存在です。 Go (Golang とも呼ばれます) は、同時実行性、高速なコンパイル速度、メモリ管理、およびクロスプラットフォームの利点で知られています。 Go 言語の欠点としては、他の言語に比べてエコシステムが充実していないこと、構文が厳格であること、動的型付けが欠如していることが挙げられます。
 Golang の技術的なパフォーマンスの最適化でメモリ リークを回避するにはどうすればよいですか?
Jun 04, 2024 pm 12:27 PM
Golang の技術的なパフォーマンスの最適化でメモリ リークを回避するにはどうすればよいですか?
Jun 04, 2024 pm 12:27 PM
メモリ リークは、ファイル、ネットワーク接続、データベース接続などの使用されなくなったリソースを閉じることによって、Go プログラムのメモリを継続的に増加させる可能性があります。弱参照を使用してメモリ リークを防ぎ、強参照されなくなったオブジェクトをガベージ コレクションの対象にします。 go coroutine を使用すると、メモリ リークを避けるために、終了時にコルーチンのスタック メモリが自動的に解放されます。
 IDE で Golang 関数のドキュメントを表示するにはどうすればよいですか?
Apr 18, 2024 pm 03:06 PM
IDE で Golang 関数のドキュメントを表示するにはどうすればよいですか?
Apr 18, 2024 pm 03:06 PM
IDE を使用して Go 関数のドキュメントを表示する: 関数名の上にカーソルを置きます。ホットキーを押します (GoLand: Ctrl+Q; VSCode: GoExtensionPack をインストールした後、F1 キーを押して「Go:ShowDocumentation」を選択します)。
 Golang のエラー ラッパーを使用するにはどうすればよいですか?
Jun 03, 2024 pm 04:08 PM
Golang のエラー ラッパーを使用するにはどうすればよいですか?
Jun 03, 2024 pm 04:08 PM
Golang では、エラー ラッパーを使用して、元のエラーにコンテキスト情報を追加することで新しいエラーを作成できます。これを使用すると、さまざまなライブラリまたはコンポーネントによってスローされるエラーの種類を統一し、デバッグとエラー処理を簡素化できます。手順は次のとおりです。errors.Wrap 関数を使用して、元のエラーを新しいエラーにラップします。新しいエラーには、元のエラーのコンテキスト情報が含まれています。 fmt.Printf を使用してラップされたエラーを出力し、より多くのコンテキストとアクション性を提供します。異なる種類のエラーを処理する場合は、errors.Wrap 関数を使用してエラーの種類を統一します。
 Go 同時関数の単体テストのガイド
May 03, 2024 am 10:54 AM
Go 同時関数の単体テストのガイド
May 03, 2024 am 10:54 AM
並行関数の単体テストは、同時環境での正しい動作を確認するのに役立つため、非常に重要です。同時実行機能をテストするときは、相互排他、同期、分離などの基本原則を考慮する必要があります。並行機能は、シミュレーション、競合状態のテスト、および結果の検証によって単体テストできます。
