
 バックエンド開発
Python チュートリアル
Python Web クローラーを使用して Bilibili のビデオ選択コンテンツを取得する方法を段階的に説明します (ソース コードが添付されています)。
バックエンド開発
Python チュートリアル
Python Web クローラーを使用して Bilibili のビデオ選択コンテンツを取得する方法を段階的に説明します (ソース コードが添付されています)。
Python Web クローラーを使用して Bilibili のビデオ選択コンテンツを取得する方法を段階的に説明します (ソース コードが添付されています)。
1. 背景の紹介
Bilibili に関して言えば、第一印象はビデオです。私と同じように、ウェブ クローラー テクノロジーを使用したいと考えている友人がたくさんいると思います。ステーション B からビデオを取得しますが、ステーション B からのビデオを取得するのは実際にはそれほど簡単ではありません。Guan はステーション B からビデオを取得する方法に関するもので、以前は次の場所で入手できました。 この導入は、you-get ライブラリを通じて実装されています。興味のある友人はこの記事を読むことができます: You-Get はとても強力です! 。
## 自宅の近くでは、Bilibili でよく勉強している友人が、特にこのようなビデオを数十、さらには数百本連載しているブロガーによく遭遇するかもしれません。プログラミング言語に関する継続的なチュートリアル、コース、ツールの使用方法などを選択すると、次の図に示すように一連の選択が表示されます。
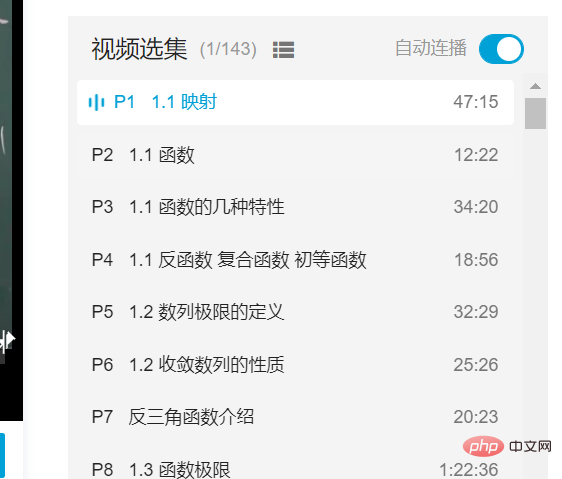
もちろんこれらの選択範囲は肉眼でも見ることができます。 Justプログラムで実装すると、想像ほど単純ではないかもしれません。したがって、この記事の目的は、Python Web クローラー テクノロジを通じて、Selenium ライブラリに基づいてビデオの選択を取得することです。
この記事で使用するライブラリは Selenium です。ユーザーのログインをシミュレートするためのライブラリは遅いように感じますが、Web クローラーの分野では今でもよく使用されており、ログインのシミュレートやデータの取得に繰り返し使用されています。以下は、ビデオ選択コレクションを実装するためのすべてのコードです。ご自身で実践してみてください。
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
class Item:
page_num = ""
part = ""
duration = ""
def __init__(self, page_num, part, duration):
self.page_num = page_num
self.part = part
self.duration = duration
def get_second(self):
str_list = self.duration.split(":")
sum = 0
for i, item in enumerate(str_list):
sum += pow(60, len(str_list) - i - 1) * int(item)
return sum
def get_bilili_page_items(url):
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 设置无界面
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2,
# "profile.managed_default_content_settings.flash": 0})
browser = webdriver.Chrome(options=options)
# browser = webdriver.PhantomJS()
print("正在打开网页...")
browser.get(url)
print("等待网页响应...")
# 需要等一下,直到页面加载完成
wait = WebDriverWait(browser, 10)
wait.until(EC.visibility_of_element_located((By.XPATH, '//*[@class="list-box"]/li/a')))
print("正在获取网页数据...")
list = browser.find_elements_by_xpath('//*[@class="list-box"]/li')
# print(list)
itemList = []
second_sum = 0
# 2.循环遍历出每一条搜索结果的标题
for t in list:
# print("t text:",t.text)
element = t.find_element_by_tag_name('a')
# print("a text:",element.text)
arr = element.text.split('\n')
print(" ".join(arr))
item = Item(arr[0], arr[1], arr[2])
second_sum += item.get_second()
itemList.append(item)
print("总数量:", len(itemList))
# browser.page_source
print("总时长/分钟:", round(second_sum / 60, 2))
print("总时长/小时:", round(second_sum / 3600.0, 2))
browser.close()
return itemList
get_bilili_page_items("https://www.bilibili.com/video/BV1Eb411u7Fw")ここで使用されるセレクターは xpath です。ビデオの例は、Station の「Advanced Mathematics」の同済版です。 B 完全な教育ビデオ (ソング ハオ先生) のビデオ選択 他のビデオ選択を取得したい場合は、上記のコードの最後の行にある URL リンクを変更するだけです。
在运行过程中小伙伴们应该会经常遇到这个问题,如下图所示。 这个是因为谷歌驱动版本问题导致的,只需要根据提示,去下载对应的驱动版本即可,驱动下载链接:三、常见问题
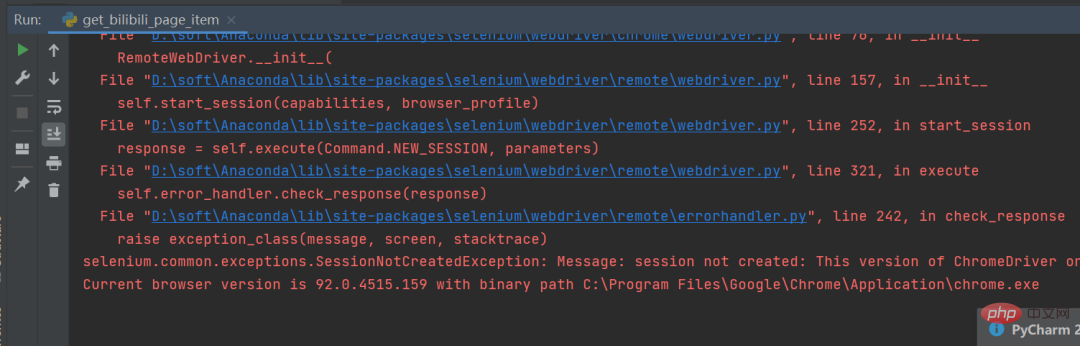
https://chromedriver.storage.googleapis.com/index.html
以上がPython Web クローラーを使用して Bilibili のビデオ選択コンテンツを取得する方法を段階的に説明します (ソース コードが添付されています)。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7500
7500
 15
1377
52
77
11
19
52
15
1377
52
77
11
19
52

 mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
MySQLには、無料のコミュニティバージョンと有料エンタープライズバージョンがあります。コミュニティバージョンは無料で使用および変更できますが、サポートは制限されており、安定性要件が低く、技術的な能力が強いアプリケーションに適しています。 Enterprise Editionは、安定した信頼性の高い高性能データベースを必要とするアプリケーションに対する包括的な商業サポートを提供し、サポートの支払いを喜んでいます。バージョンを選択する際に考慮される要因には、アプリケーションの重要性、予算編成、技術スキルが含まれます。完璧なオプションはなく、最も適切なオプションのみであり、特定の状況に応じて慎重に選択する必要があります。
 hadidb:pythonの軽量で水平方向にスケーラブルなデータベース
Apr 08, 2025 pm 06:12 PM
hadidb:pythonの軽量で水平方向にスケーラブルなデータベース
Apr 08, 2025 pm 06:12 PM
hadidb:軽量で高レベルのスケーラブルなPythonデータベースHadIDB(HadIDB)は、Pythonで記述された軽量データベースで、スケーラビリティが高くなっています。 PIPインストールを使用してHADIDBをインストールする:PIPINSTALLHADIDBユーザー管理CREATEユーザー:CREATEUSER()メソッド新しいユーザーを作成します。 Authentication()メソッドは、ユーザーのIDを認証します。 fromhadidb.operationimportuseruser_obj = user( "admin"、 "admin")user_obj。
 MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
Hash値として保存されているため、Navicatを介してMongoDBパスワードを直接表示することは不可能です。紛失したパスワードを取得する方法:1。パスワードのリセット。 2。構成ファイルを確認します(ハッシュ値が含まれる場合があります)。 3.コードを確認します(パスワードをハードコードできます)。
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 Python:主要なアプリケーションの調査
Apr 10, 2025 am 09:41 AM
Python:主要なアプリケーションの調査
Apr 10, 2025 am 09:41 AM
Pythonは、Web開発、データサイエンス、機械学習、自動化、スクリプトの分野で広く使用されています。 1)Web開発では、DjangoおよびFlask Frameworksが開発プロセスを簡素化します。 2)データサイエンスと機械学習の分野では、Numpy、Pandas、Scikit-Learn、Tensorflowライブラリが強力なサポートを提供します。 3)自動化とスクリプトの観点から、Pythonは自動テストやシステム管理などのタスクに適しています。
 Amazon AthenaでAWS接着クローラーの使用方法
Apr 09, 2025 pm 03:09 PM
Amazon AthenaでAWS接着クローラーの使用方法
Apr 09, 2025 pm 03:09 PM
データの専門家として、さまざまなソースから大量のデータを処理する必要があります。これは、データ管理と分析に課題をもたらす可能性があります。幸いなことに、AWS GlueとAmazon Athenaの2つのAWSサービスが役立ちます。
 2時間のPython計画:現実的なアプローチ
Apr 11, 2025 am 12:04 AM
2時間のPython計画:現実的なアプローチ
Apr 11, 2025 am 12:04 AM
2時間以内にPythonの基本的なプログラミングの概念とスキルを学ぶことができます。 1.変数とデータ型、2。マスターコントロールフロー(条件付きステートメントとループ)、3。機能の定義と使用を理解する4。
 MySQLはSQLサーバーに接続できますか
Apr 08, 2025 pm 05:54 PM
MySQLはSQLサーバーに接続できますか
Apr 08, 2025 pm 05:54 PM
いいえ、MySQLはSQL Serverに直接接続できません。ただし、次のメソッドを使用してデータ相互作用を実装できます。ミドルウェア:MySQLから中間形式にデータをエクスポートしてから、ミドルウェアを介してSQL Serverにインポートします。データベースリンカーの使用:ビジネスツールは、よりフレンドリーなインターフェイスと高度な機能を提供しますが、本質的にはミドルウェアを通じて実装されています。
