

Python の文字列の基本を再確認する
なぜ文字列が必要なのでしょうか?
ブラウザを呼び出して一部の Web サイトにログインする場合、パスワードを入力する必要があります。ブラウザがパスワードをサーバーに送信した後、サーバーはパスワードを検証します。検証プロセス以前の保存されたパスワードと今回渡されたパスワードを比較します。それらが等しい場合、パスワードは正しいと見なされ、そうでない場合、間違っていると見なされます。サーバーはこれらのパスワードを保存したいため、データベース (たとえば、 MySQL として)これを実現します。
もちろん、簡単にするために、まずパスワードを保存する変数を見つけますが、文字を含むパスワードを保存するにはどうすればよいでしょうか?ここで文字列が使用されます。
1. Python の文字列の形式
は次のように定義されます。変数aには数値型の値が格納されます。
a = 100
以下に定義されている変数 b には、文字列型の値が格納されます。
b = "hello itcast.cn"
或者
b = 'hello itcast.cn'簡単な概要:
二重引用符または一重引用符で囲む データは文字列
です
二、字符串输出
例:
name = 'ming'
position = '讲师'
address = '中山市平区建材城西路金燕龙办公楼1层'
print('--------------------------------------------------')
print("姓名:%s"%name)
print("职位:%s"%position)
print("公司地址:%s"%address)
print('--------------------------------------------------')结果:
--------------------------------------------------
姓名:ming
职位:讲师
公司地址:中山市昌平区建材城西路金燕龙办公楼1层
--------------------------------------------------三、字符串输入
input通过它能够完成从键盘获取数据,然后保存到指定的变量中;
注意:input获取的数据,都以字符串的方式进行保存,即使输入的是数字,那么也是以字符串方式保存。
例:
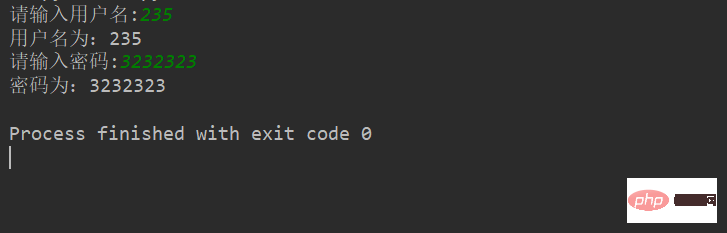
userName = input('请输入用户名:')
print("用户名为:%s"%userName)
password = input('请输入密码:')
print("密码为:%s"%password)结果:(根据输入的不同结果也不同)
4. 添え字とスライス
1. 添え字インデックス
いわゆる"添字" はスーパーの保管庫の番号と同じ番号です。この番号から該当する保管スペースを見つけることができます。
生活の中の「サブスク」
スーパーマーケットのロッカー

文字列での「添字」の使用
#リストとタプルは、理解しやすいように添字インデックスをサポートしています。文字列は実際には文字の配列です。したがって、添字インデックスもサポートされています。
文字列 name = 'abcdef' がある場合、メモリ内の実際のストレージは次のようになります。 :
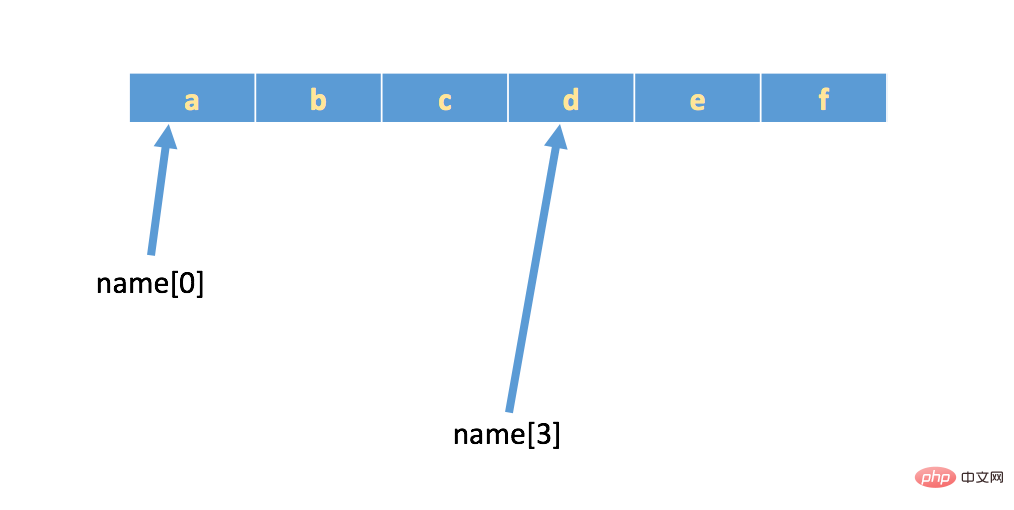
一部の文字を削除したい場合は、 を使用して を添え字にします。 メソッド (Python の添字は 0 から始まることに注意してください)
name = 'abcdef' print(name[0]) print(name[1]) print(name[2])
运行结果:

2. 切片的概念:
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
3. 切片的语法:[起始:结束:步长]
注意:选取的区间属于左闭右开型,即从"起始"位开始,到"结束"位的前一位结束(不包含结束位本身)。
我们以字符串为例讲解。
如果取出一部分,则可以在中括号[]中,使用 :
例:
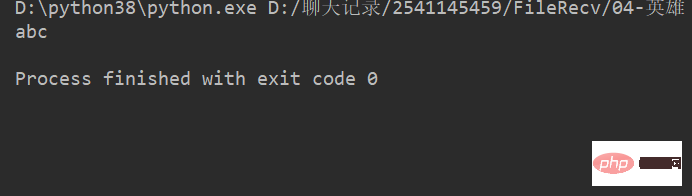
name = 'abcdef'
print(name[0:3]) # 取 下标0~2 的字符运行结果 :
例:
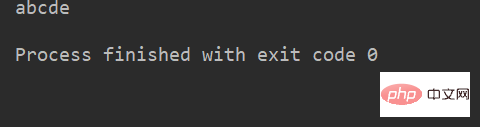
name = 'abcdef'
print(name[0:5]) # 取 下标为0~4 的字符运行结果:
例:
name = 'abcdef'
print(name[3:5]) # 取 下标为3、4 的字符运行结果:
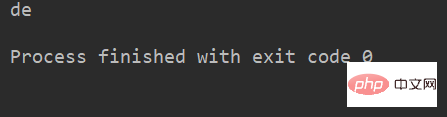
例:
name = 'abcdef'
print(name[2:]) # 取 下标为2开始到最后的字符运行结果:
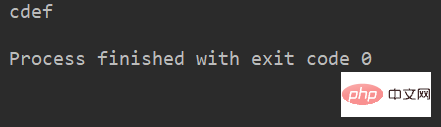
例:
name = 'abcdef'
print(name[1:-1]) # 取 下标为1开始 到 最后第2个 之间的字符运行结果:
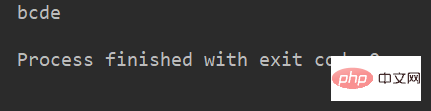
>>> a = "abcdef" >>> a[:3] #运行结果 'abc' >>> a[::2] #运行结果 'ace' >>> a[5:1:2] '' #运行结果 >>> a[1:5:2] 'bd' #运行结果 >>> a[::-2] 'fdb' #运行结果 >>> a[5:1:-2] 'fd' #运行结果
五、字符串常见16种操作
以字符串'lstr = 'welcome to Beijing Museumitcpps fdsfs',为例。
介绍字符常见的操作。
<1> find
检测 str 是否包含在 lstr中,如果是返回开始的索引值,否则返回-1。
语法:
lstr.find(str, start=0, end=len(lstr))
例:
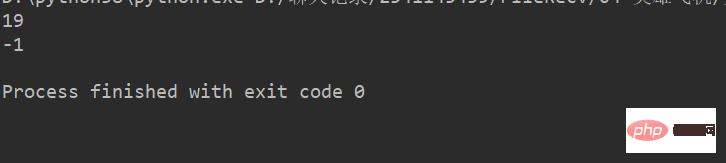
lstr = 'welcome to Beijing Museumitcpps fdsfs'
print(lstr.find("Museum"))
print(lstr.find("dada"))运行结果:
<2> index
跟find()方法一样,只不过如果str不在 lstr中会报一个异常。
语法:
lstr.index(str, start=0, end=len(lstr))
例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'
print(lstr.index("dada"))运行结果:

<3> count
返回 str在start和end之间 在 lstr里面出现的次数
语法:
lstr.count(str, start=0, end=len(lstr))
例:
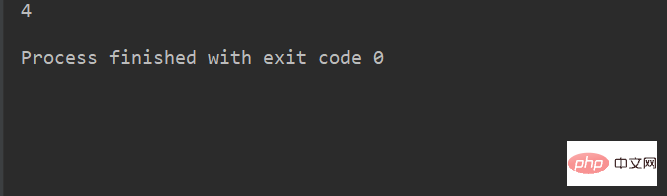
lstr = 'welcome to Beijing Museumitcpps fdsfs'
print(lstr.count("s"))运行结果:
<4> replace
把 lstr 中的 str1 替换成 str2,如果 count 指定,则替换不超过 count 次.
1str.replace(str1, str2, 1str.count(str1))
例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'
print(lstr.replace("s", "ttennd"))运行结果:

<5> split
以 str 为分隔符切片 lstr,如果 maxsplit有指定值,则仅分隔 maxsplit 个子字符串
1str.split(str=" ", 2)
例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'
print(lstr.split("to", 5))运行结果:

<6> capitalize
把字符串的第一个字符大写。
1str.capitalize()
例:
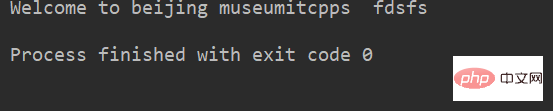
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.capitalize())
运行结果:
<7> title
把字符串的每个单词首字母大写。
>>> a = "hello itcast" >>> a.title() 'Hello Itcast' #运行结果
<8> startswith
检查字符串是否是以 obj 开头, 是则返回 True,否则返回 False
1str.startswith(obj)
例:
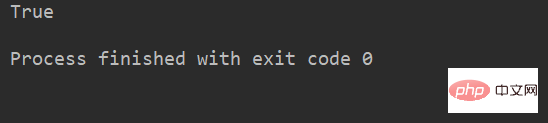
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.startswith('we'))
运行结果:
<9> endswith
检查字符串是否以obj结束,如果是返回True,否则返回 False.
1str.endswith(obj)
例:
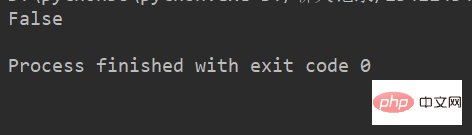
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.endswith('hfs'))
运行结果:
<10> lower
转换 lstr 中所有大写字符为小写
1str.lower()
例:
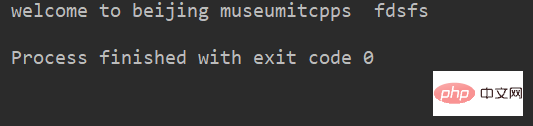
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.lower())
运行结果:
<11> upper
转换 lstr 中的小写字母为大写
1str.upper()
例:
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.upper())
运行结果:

<12> strip
删除lstr字符串两端的空白字符。
>>> a = "\n\t itcast \t\n" >>> a.strip() 'itcast' #运行结果
<13> rfind
类似于 find()函数,不过是从右边开始查找。
1str.rfind(str, start=0,end=len(1str) )
例:
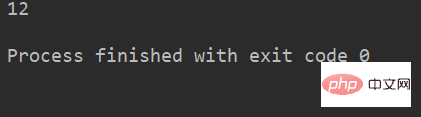
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.rfind('eijing'))
运行结果:
<14> rindex
类似于 index(),不过是从右边开始。
1str.rindex( str, start=0,end=len(1str))
例:
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.rindex('eijing'))
运行结果:
<15> partition
把lstr以str分割成三部分,str前,str和str后。
1str.partition(str)
例:
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.partition('eijing'))
运行结果:

<16> join
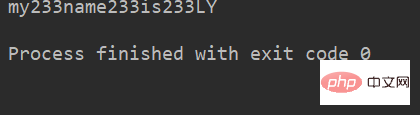
mystr 中每个字符后面插入str,构造出一个新的字符串。
lstr = 'welcome to Beijing Museumitcpps fdsfs' str='233' lstr.join(str) li=["my","name","is","LY"] print(str.join(li))
运行结果:
六、总结
本文详细的讲解了Python基础 ( 字符串 )。介绍了有关字符串,切片的操作。下标索引。以及在实际操作中会遇到的问题,提供了解决方案。希望可以帮助你更好的学习Python。
以上がPython の文字列の基本を再確認するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7515
7515
 15
1378
52
79
11
19
64
15
1378
52
79
11
19
64

 2時間のPython計画:現実的なアプローチ
Apr 11, 2025 am 12:04 AM
2時間のPython計画:現実的なアプローチ
Apr 11, 2025 am 12:04 AM
2時間以内にPythonの基本的なプログラミングの概念とスキルを学ぶことができます。 1.変数とデータ型、2。マスターコントロールフロー(条件付きステートメントとループ)、3。機能の定義と使用を理解する4。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 Redisのサーバーバージョンを表示する方法
Apr 10, 2025 pm 01:27 PM
Redisのサーバーバージョンを表示する方法
Apr 10, 2025 pm 01:27 PM
質問:Redisサーバーバージョンを表示する方法は?コマンドラインツールRedis-Cli-versionを使用して、接続されたサーバーのバージョンを表示します。 Info Serverコマンドを使用して、サーバーの内部バージョンを表示し、情報を解析および返信する必要があります。クラスター環境では、各ノードのバージョンの一貫性を確認し、スクリプトを使用して自動的にチェックできます。スクリプトを使用して、Pythonスクリプトとの接続やバージョン情報の印刷など、表示バージョンを自動化します。
 Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisサーバーを起動する手順には、以下が含まれます。オペレーティングシステムに従ってRedisをインストールします。 Redis-Server(Linux/Macos)またはRedis-Server.exe(Windows)を介してRedisサービスを開始します。 Redis-Cli ping(Linux/macos)またはRedis-Cli.exePing(Windows)コマンドを使用して、サービスステータスを確認します。 Redis-Cli、Python、node.jsなどのRedisクライアントを使用して、サーバーにアクセスします。
 ビジネスのニーズに応じてRedisメモリサイズを設定する方法は?
Apr 10, 2025 pm 02:18 PM
ビジネスのニーズに応じてRedisメモリサイズを設定する方法は?
Apr 10, 2025 pm 02:18 PM
Redisメモリサイズの設定は、次の要因を考慮する必要があります。データ量と成長傾向:保存されたデータのサイズと成長率を推定します。データ型:異なるタイプ(リスト、ハッシュなど)は異なるメモリを占めます。キャッシュポリシー:完全なキャッシュ、部分キャッシュ、フェージングポリシーは、メモリの使用に影響します。ビジネスピーク:トラフィックピークに対処するのに十分なメモリを残します。
 Redisメモリ構成パラメーターとは何ですか?
Apr 10, 2025 pm 02:03 PM
Redisメモリ構成パラメーターとは何ですか?
Apr 10, 2025 pm 02:03 PM
** Redisメモリ構成のコアパラメーターはMaxMemoryであり、Redisが使用できるメモリの量を制限します。この制限を超えると、Redisは、Maxmemory-Policyに従って除去戦略を実行します。これには、次のようになります。その他の関連パラメーターには、Maxmemory-Samples(LRUサンプル量)、RDB圧縮が含まれます
 メモリに対するRedisの持続性の影響は何ですか?
Apr 10, 2025 pm 02:15 PM
メモリに対するRedisの持続性の影響は何ですか?
Apr 10, 2025 pm 02:15 PM
Redis Persistenceは余分なメモリを取り、RDBはスナップショットを生成するときに一時的にメモリの使用量を増加させ、AOFはログを追加するときにメモリを取り上げ続けます。影響要因には、データのボリューム、永続性ポリシー、Redis構成が含まれます。影響を緩和するために、RDBスナップショットポリシーを合理的に構成し、AOF構成を最適化し、ハードウェアをアップグレードし、メモリの使用量を監視できます。さらに、パフォーマンスとデータセキュリティのバランスを見つけることが重要です。
 Python vs. C:比較されたアプリケーションとユースケース
Apr 12, 2025 am 12:01 AM
Python vs. C:比較されたアプリケーションとユースケース
Apr 12, 2025 am 12:01 AM
Pythonは、データサイエンス、Web開発、自動化タスクに適していますが、Cはシステムプログラミング、ゲーム開発、組み込みシステムに適しています。 Pythonは、そのシンプルさと強力なエコシステムで知られていますが、Cは高性能および基礎となる制御機能で知られています。
