

Flask を使用して ES 検索エンジンを構築する方法を段階的に説明します (準備部分)
#/1 はじめに/
は、全文検索エンジン ライブラリに基づいて構築されたオープンソースの検索エンジンです。 Apache Lucene™ に基づいています。

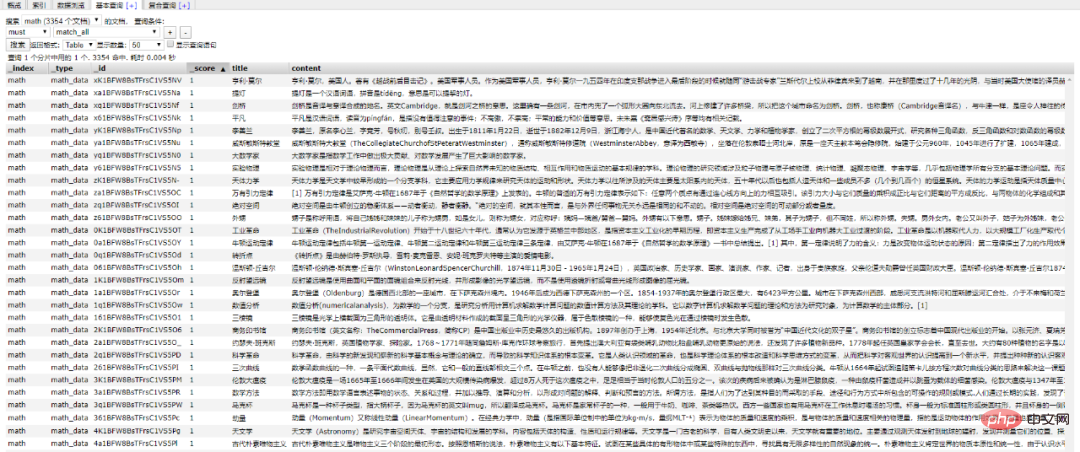
と Python の間の接続をどのように実現するかが私たちの関心事となっています。問題は (なぜすべてが Python に関連する必要があるのか?) です。 ##/2 Python インタラクション/ Python は に接続する方法も提供します。 Elasticsearch の依存ライブラリ。 接続を初期化する 操作オブジェクト。 Elasticsearch のローカル環境が設定されていることを確認してください。 #ID に基づいて文書データを取得 ## 插入文档数据 搜索文档数据 删除文档数据 好啊,封装 search 类也是为了方便调用,整体贴一下。 尝试一下把 Mongodb 中的数据插入到 ES 中。 到 ES 中查看一下,启动 elasticsearch-head 插件。 如果是 npm 安装的那么 cd 到根目录之后直接 npm run start 就跑起来了。 本地访问 http://localhost:9100/ 发现新加的 spider 数据文档确实已经进去了。 /3 爬虫入库/ 要想实现 ES 搜索,首先要有数据支持,而海量的数据往往来自爬虫。 为了节省时间,编写一个最简单的爬虫,抓取 百度百科。 简单粗暴一点,先 递归获取 很多很多的 url 链接 把全部 url 存到 url.txt 文件中之后,然后启动任务。 run.py 飞起来 黑窗口键入 哦豁 !! 你居然使用了 Celery 任务队列,gevent 模式,-c 就是10个线程刷刷刷就干起来了,速度杠杠的 !! 啥?分布式? 那就加多几台机器啦,直接把代码拷贝到目标服务器,通过 redis 共享队列协同多机抓取。 这里是先将数据存储到了 MongoDB 上(个人习惯),你也可以直接存到 ES 中,但是单条单条的插入速度堪忧(接下来会讲到优化,哈哈)。 使用前面的例子将 Mongo 中的数据批量导入到 ES 中,OK !!! 到这一个简单的数据抓取就已经完毕了。 好啦,现在 ES 中已经有了数据啦,接下来就应该是 Flask web 的操作啦,当然,Django,FastAPI 也很优秀。嘿嘿,你喜欢 !! 关于FastAPI 的文章可以看这个系列文章: 1、(入门篇)简析Python web框架FastAPI——一个比Flask和Tornada更高性能的API 框架 2、(进阶篇)Python web框架FastAPI——一个比Flask和Tornada更高性能的API 框架 3、(完结篇)Python web框架FastAPI——一个比Flask和Tornada更高性能的API 框架 /4 Flask 项目结构/ 这样一来前期工作就差不多了,接下来剩下的工作主要集中于 Flask 的实际开发中,蓄力中 !!
#pip install elasticsearch
def __init__(self, index_type: str, index_name: str, ip="127.0.0.1"):
# self.es = Elasticsearch([ip], http_auth=('username', 'password'), port=9200)
self.es = Elasticsearch("localhost:9200")
self.index_type = index_type
self.index_name = index_namedef get_doc(self, uid):
return self.es.get(index=self.index_name, id=uid)def insert_one(self, doc: dict):
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)
def insert_array(self, docs: list):
for doc in docs:
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)def search(self, query, count: int = 30):
dsl = {
"query": {
"multi_match": {
"query": query,
"fields": ["title", "content", "link"]
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
match_data = self.es.search(index=self.index_name, body=dsl, size=count)
return match_data
def __search(self, query: dict, count: int = 20): # count: 返回的数据大小
results = []
params = {
'size': count
}
match_data = self.es.search(index=self.index_name, body=query, params=params)
for hit in match_data['hits']['hits']:
results.append(hit['_source'])
return resultsdef delete_index(self):
try:
self.es.indices.delete(index=self.index_name)
except:
passfrom elasticsearch import Elasticsearch
class elasticSearch():
def __init__(self, index_type: str, index_name: str, ip="127.0.0.1"):
# self.es = Elasticsearch([ip], http_auth=('elastic', 'password'), port=9200)
self.es = Elasticsearch("localhost:9200")
self.index_type = index_type
self.index_name = index_name
def create_index(self):
if self.es.indices.exists(index=self.index_name) is True:
self.es.indices.delete(index=self.index_name)
self.es.indices.create(index=self.index_name, ignore=400)
def delete_index(self):
try:
self.es.indices.delete(index=self.index_name)
except:
pass
def get_doc(self, uid):
return self.es.get(index=self.index_name, id=uid)
def insert_one(self, doc: dict):
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)
def insert_array(self, docs: list):
for doc in docs:
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)
def search(self, query, count: int = 30):
dsl = {
"query": {
"multi_match": {
"query": query,
"fields": ["title", "content", "link"]
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
match_data = self.es.search(index=self.index_name, body=dsl, size=count)
return match_dataimport json
from datetime import datetime
import pymongo
from app.elasticsearchClass import elasticSearch
client = pymongo.MongoClient('127.0.0.1', 27017)
db = client['spider']
sheet = db.get_collection('Spider').find({}, {'_id': 0, })
es = elasticSearch(index_type="spider_data",index_name="spider")
es.create_index()
for i in sheet:
data = {
'title': i["title"],
'content':i["data"],
'link': i["link"],
'create_time':datetime.now()
}
es.insert_one(doc=data)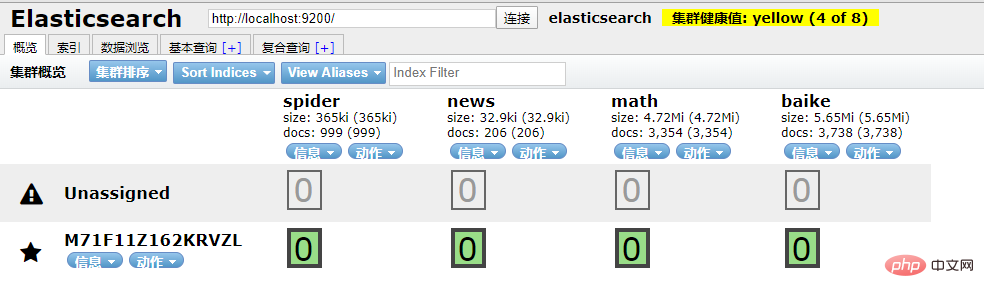
import requests
import re
import time
exist_urls = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36',
}
def get_link(url):
try:
response = requests.get(url=url, headers=headers)
response.encoding = 'UTF-8'
html = response.text
link_lists = re.findall('.*?<a target=_blank href="/item/([^:#=<>]*?)".*?</a>', html)
return link_lists
except Exception as e:
pass
finally:
exist_urls.append(url)
# 当爬取深度小于10层时,递归调用主函数,继续爬取第二层的所有链接
def main(start_url, depth=1):
link_lists = get_link(start_url)
if link_lists:
unique_lists = list(set(link_lists) - set(exist_urls))
for unique_url in unique_lists:
unique_url = 'https://baike.baidu.com/item/' + unique_url
with open('url.txt', 'a+') as f:
f.write(unique_url + '\n')
f.close()
if depth < 10:
main(unique_url, depth + 1)
if __name__ == '__main__':
start_url = 'https://baike.baidu.com/item/%E7%99%BE%E5%BA%A6%E7%99%BE%E7%A7%91'
main(start_url)# parse.py
from celery import Celery
import requests
from lxml import etree
import pymongo
app = Celery('tasks', broker='redis://localhost:6379/2')
client = pymongo.MongoClient('localhost',27017)
db = client['baike']
@app.task
def get_url(link):
item = {}
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36'}
res = requests.get(link,headers=headers)
res.encoding = 'UTF-8'
doc = etree.HTML(res.text)
content = doc.xpath("//div[@class='lemma-summary']/div[@class='para']//text()")
print(res.status_code)
print(link,'\t','++++++++++++++++++++')
item['link'] = link
data = ''.join(content).replace(' ', '').replace('\t', '').replace('\n', '').replace('\r', '')
item['data'] = data
if db['Baike'].insert(dict(item)):
print("is OK ...")
else:
print('Fail')from parse import get_url
def main(url):
result = get_url.delay(url)
return result
def run():
with open('./url.txt', 'r') as f:
for url in f.readlines():
main(url.strip('\n'))
if __name__ == '__main__':
run()celery -A parse worker -l info -P gevent -c 10

以上がFlask を使用して ES 検索エンジンを構築する方法を段階的に説明します (準備部分)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7561
7561
 15
1384
52
84
11
28
98
15
1384
52
84
11
28
98

 React と Flask を使用してシンプルで使いやすい Web アプリケーションを構築する方法
Sep 27, 2023 am 11:09 AM
React と Flask を使用してシンプルで使いやすい Web アプリケーションを構築する方法
Sep 27, 2023 am 11:09 AM
React と Flask を使用してシンプルで使いやすい Web アプリケーションを構築する方法 はじめに: インターネットの発展に伴い、Web アプリケーションのニーズはますます多様化および複雑化しています。使いやすさとパフォーマンスに対するユーザーの要件を満たすために、最新のテクノロジー スタックを使用してネットワーク アプリケーションを構築することがますます重要になっています。 React と Flask は、フロントエンドおよびバックエンド開発用の 2 つの非常に人気のあるフレームワークであり、うまく連携してシンプルで使いやすい Web アプリケーションを構築します。この記事では、React と Flask を活用する方法について詳しく説明します。
 Django vs. Flask: Python Web フレームワークの比較分析
Jan 19, 2024 am 08:36 AM
Django vs. Flask: Python Web フレームワークの比較分析
Jan 19, 2024 am 08:36 AM
Django と Flask はどちらも Python Web フレームワークのリーダーであり、それぞれに独自の利点と適用可能なシナリオがあります。この記事では、これら 2 つのフレームワークを比較分析し、具体的なコード例を示します。開発の概要 Django はフル機能の Web フレームワークであり、その主な目的は、複雑な Web アプリケーションを迅速に開発することです。 Django は、ORM (オブジェクト リレーショナル マッピング)、フォーム、認証、管理バックエンドなどの多くの組み込み機能を提供します。これらの機能により、Django は大規模なデータを処理できるようになります。
 ゼロから始めて、Flask をインストールし、個人ブログを迅速に確立する方法を段階的にガイドします。
Feb 19, 2024 pm 04:01 PM
ゼロから始めて、Flask をインストールし、個人ブログを迅速に確立する方法を段階的にガイドします。
Feb 19, 2024 pm 04:01 PM
ゼロから始めて、Flask をインストールし、個人ブログをすぐに構築する方法を段階的に説明します。書くことが好きな人にとって、個人ブログを持つことは非常に重要です。軽量の Python Web フレームワークである Flask は、シンプルで完全に機能する個人ブログを迅速に構築するのに役立ちます。この記事では、ゼロから始めて、Flask をインストールして個人ブログを迅速に構築する方法を段階的に説明します。ステップ 1: Python と pip をインストールする 開始する前に、まず Python と pi をインストールする必要があります
 Flask フレームワークのインストールガイド: Flask を正しくインストールするための詳細な手順
Feb 18, 2024 pm 10:51 PM
Flask フレームワークのインストールガイド: Flask を正しくインストールするための詳細な手順
Feb 18, 2024 pm 10:51 PM
Flask フレームワークのインストール チュートリアル: Flask フレームワークを正しくインストールする方法を段階的に説明します。特定のコード例が必要です。 はじめに: Flask は、シンプルで柔軟な Python Web 開発フレームワークです。学びやすく、使いやすく、強力な機能が満載です。この記事では、Flask フレームワークを正しくインストールする方法を段階的に説明し、参照用の詳細なコード例を提供します。ステップ 1: Python をインストールする Flask フレームワークをインストールする前に、まず Python がコンピュータにインストールされていることを確認する必要があります。 Pから始められます
 Flask と Intellij IDEA の統合: Python Web アプリケーション開発のヒント (パート 2)
Jun 17, 2023 pm 01:58 PM
Flask と Intellij IDEA の統合: Python Web アプリケーション開発のヒント (パート 2)
Jun 17, 2023 pm 01:58 PM
最初の部分では、基本的な Flask と Intellij IDEA の統合、プロジェクトと仮想環境の設定、依存関係のインストールなどを紹介します。次に、より効率的な作業環境を構築するための Python Web アプリケーション開発のヒントをさらに検討していきます。 FlaskBlueprints の使用FlaskBlueprints を使用すると、管理とメンテナンスを容易にするためにアプリケーション コードを整理できます。ブループリントは、パッケージ化された Python モジュールです。
 Flask vs FastAPI: 効率的な Web API 開発のための最良の選択
Sep 27, 2023 pm 09:01 PM
Flask vs FastAPI: 効率的な Web API 開発のための最良の選択
Sep 27, 2023 pm 09:01 PM
FlaskvsFastAPI: WebAPI の効率的な開発のための最良の選択 はじめに: 現代のソフトウェア開発において、WebAPI は不可欠な部分になっています。これらは、異なるアプリケーション間の通信と相互運用性を可能にするデータとサービスを提供します。 WebAPI を開発するためのフレームワークを選択する場合、Flask と FastAPI の 2 つの選択肢が大きな注目を集めています。どちらのフレームワークも非常に人気があり、それぞれに独自の利点があります。この記事ではフロリダ州について見ていきます。
 Flask アプリケーション展開における Gunicorn と uWSGI のパフォーマンスの比較
Jan 17, 2024 am 08:52 AM
Flask アプリケーション展開における Gunicorn と uWSGI のパフォーマンスの比較
Jan 17, 2024 am 08:52 AM
Flask アプリケーションのデプロイメント: Gunicorn と suWSGI の比較 はじめに: Flask は、軽量の Python Web フレームワークとして、多くの開発者に愛されています。 Flask アプリケーションを運用環境にデプロイする場合、適切なサーバー ゲートウェイ インターフェイス (SGI) を選択することが重要な決定となります。 Gunicorn と uWSGI は 2 つの一般的な SGI サーバーであり、この記事ではこれらについて詳しく説明します。
 Flask-RESTful と Swagger: Python Web アプリケーションで RESTful API を構築するためのベスト プラクティス (パート 2)
Jun 17, 2023 am 10:39 AM
Flask-RESTful と Swagger: Python Web アプリケーションで RESTful API を構築するためのベスト プラクティス (パート 2)
Jun 17, 2023 am 10:39 AM
Flask-RESTful と Swagger: Python Web アプリケーションで RESTful API を構築するためのベスト プラクティス (パート 2) 前回の記事では、Flask-RESTful と Swagger を使用して RESTful API を構築するためのベスト プラクティスについて説明しました。 Flask-RESTful フレームワークの基本を紹介し、Swagger を使用して RESTful API のドキュメントを構築する方法を示しました。本
