

インタビュアー: 高同時実行性についてどのくらい知っていますか?私:うーん...

高い同時実行性は、ほぼすべてのプログラマーが望んでいるエクスペリエンスです。 理由は非常に簡単です。トラフィックが増加すると、インターフェイスの応答タイムアウト、CPU 負荷の増加、頻繁な GC、デッドロック、大規模なデータ ストレージなど、さまざまな技術的な問題が発生します。Wait 、これらの質問は、技術的な深みを継続的に向上させる原動力になります。
過去の面接では、候補者が同時実行性の高いプロジェクトを行ったことがある場合、通常、候補者に同時性の高いプロジェクトについての理解を尋ねますが、体系的に答えることができます。 . この問題が得意な人は多くありませんが、大きく分けて
1、# に分類されます。 ##データベースのインジケーターはありません コンセプト: 同時実行性の高いシステムを測定するためにどのインジケーターを選択すればよいかわかりませんか?同時実行性と QPS の違いがわかりません。システムの総ユーザー数、アクティブ ユーザー数、平坦時とピーク時の QPS と TPS、その他の重要なデータさえもわかりません。
2. いくつかの計画は策定されましたが、詳細は完全に把握されていませんでした: Can'計画 では、技術的な点と起こり得る副作用に焦点を当てる必要があります。たとえば、読み取りパフォーマンスにボトルネックがある場合、キャッシュが導入されますが、キャッシュ ヒット率、ホット キー、データの一貫性などの問題は無視されます。
3. 高同時実行設計とパフォーマンスの最適化を同一視する一方的な理解: は同時プログラミング、マルチレベル キャッシュ、非同期化、水平拡張について説明していますが、高い同時実行性の設計を無視します。 利用可能な設計、サービス ガバナンス、運用および保守の保証。
4. 大きな計画をマスターしますが、最も基本的なことは無視します: 垂直方向について明確に説明できるようにする階層化、水平パーティショニングやキャッシュなどの大きなアイデアはあるが、データ構造が合理的かどうか、アルゴリズムが効率的かどうかを分析するつもりはなく、IOとコンピューティングの最も基本的な2つの側面から詳細を最適化することについて考えたことはありません。
この記事では、高同時実行プロジェクトでの私自身の経験を組み合わせて、高同時実行で習得する必要がある知識と実践的なアイデアを体系的にまとめたいと思います。お役に立てば幸いです。 コンテンツは次の 3 つの部分に分かれています:
高い同時実行性を理解するにはどうすればよいですか? #高同時実行性のシステム設計の目標は何ですか? -
高い同時実行性を実現する実際的なソリューションは何ですか?
高い同時実行性は大量のトラフィックを意味し、トラフィックの影響に抵抗するために技術的手段を使用する必要があります。これらの手段はトラフィックを運用するのと同様で、システムによるトラフィックのよりスムーズな処理を可能にします。ユーザーエクスペリエンスにより良い結果をもたらします。
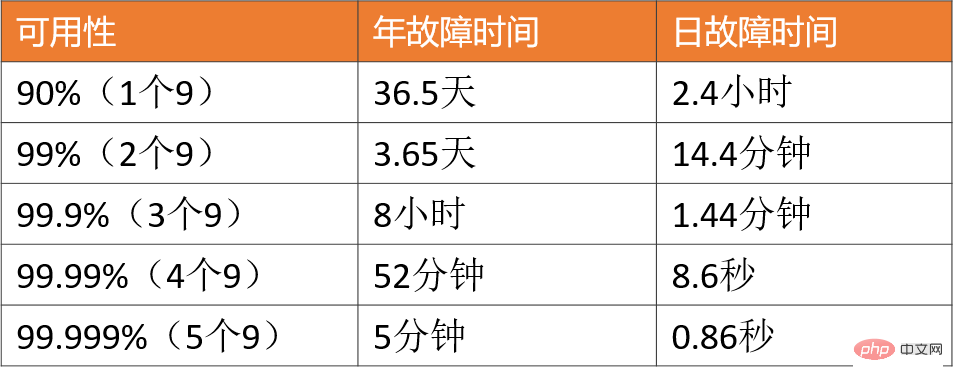
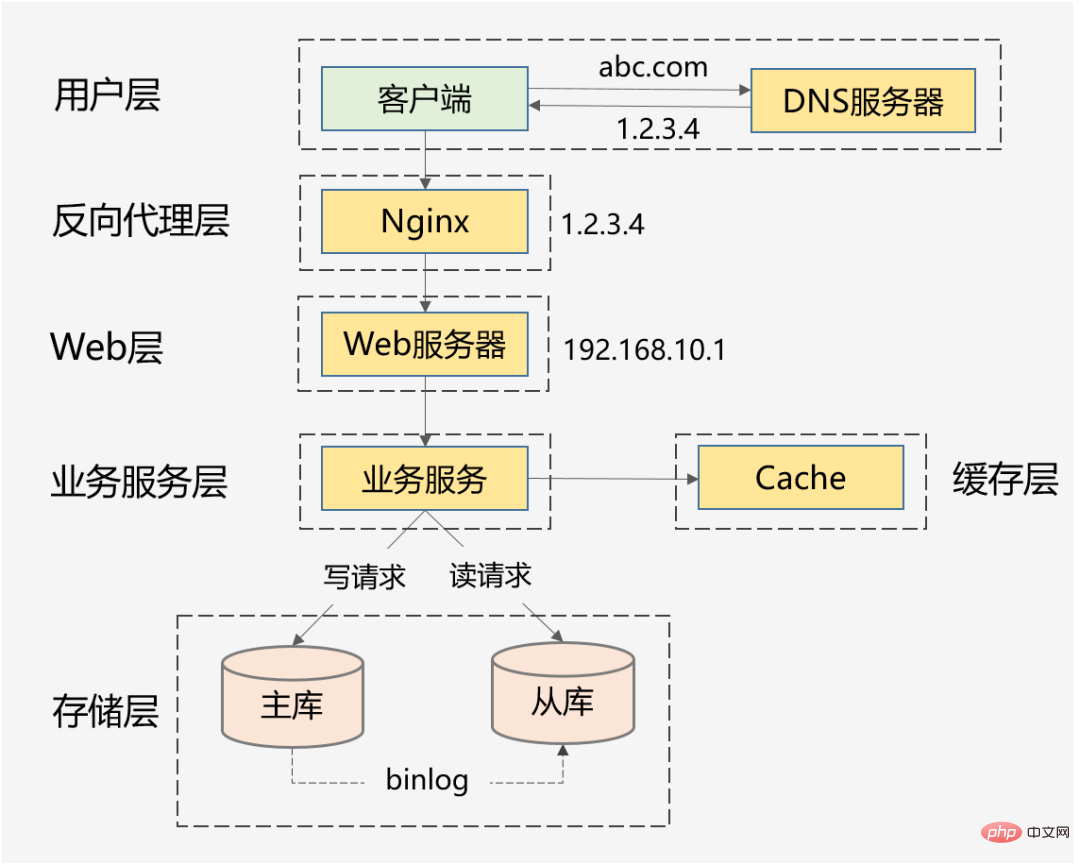
一般的な同時実行性の高いシナリオには、淘宝網のダブル 11、春節期間中のチケット入手、Weibo Vs からのホットなニュースなどが含まれます。これらの典型的なものに加えて、1 秒あたり数十万のリクエストを伴うフラッシュセール システム、1 日に数千万の注文を伴う注文システム、1 日に数億のデイリー アクティブを伴う情報フロー システムなどはすべて分類できます。高い同時実行性として。 明らかに、上記の高同時実行シナリオでは、同時実行の量は異なります。では、どの程度の同時実行が高同時実行とみなされるのでしょうか? ##1. 数字だけを見るのではなく、具体的なビジネス シナリオにも注目してください。 10W QPS のフラッシュセールは同時実行性が高いとは言えませんが、1W QPS の情報フローは同時実行性が高いとは言えません。情報フロー シナリオには複雑な推奨モデルとさまざまな手動戦略が含まれており、そのビジネス ロジックはフラッシュ セール シナリオよりも 10 倍以上複雑になる可能性があります。したがって、これらは同じ次元に存在せず、比較する意味はありません。 2. ビジネスは 0 から 1 から始まります。同時実行性や QPS はあくまで参考指標です。最も重要なのは、ビジネス量が徐々に 10 倍、100 倍に増加したときに、倍増のプロセスにおいて、システムを進化させるために高同時実行性の処理方法を使用し、アーキテクチャ設計、コーディング実装、さらには製品ソリューションの側面から高同時性によって引き起こされる問題を防止および解決しましたか?やみくもにハードウェアをアップグレードしたり、水平方向の拡張のためにマシンを追加したりするのではなく。 さらに、各高同時実行シナリオの ビジネス特性はまったく異なります。読み取りが多く書き込みが少ない情報フロー シナリオもあれば、書き込みが少ないトランザクション シナリオもあります。読み取りと書き込み、さまざまなシナリオでの同時実行性の問題を解決するための一般的な技術ソリューションはありますか?? 大きなアイデアや他の人の計画から学ぶことはできると思いますが、実際の実装プロセスでは、細部に無数の落とし穴があるでしょう。また、ソフトウェアとハードウェアの環境、技術スタック、製品ロジックは完全に一致することはできないため、同じビジネスシナリオにつながります。同じ技術ソリューションを使用したとしても、異なる問題に直面するため、これらの落とし穴を解決する必要があります。ひとつひとつ乗り越えていく。 したがって、この記事では、基礎的な知識、一般的な考え方、および私が実践した効果的な経験に焦点を当てて、あなたに高い同時実行性についてのより深い理解。 まず、高同時実行性のシステム設計の目標を明確にしてから、これに基づいて有意義かつ的を絞った設計計画と実際の経験について話し合います。 ##高い同時実行性は、単に高い同時実行性を追求することを意味するわけではありません パフォーマンス、これは多くの人の一方的な理解です。 マクロの観点から見ると、高同時実行性のシステム設計には、高い パフォーマンス、高可用性、および高いスケーラビリティという 3 つの目標があります。 パフォーマンスは、システムの並列処理能力を反映します。限られたハードウェア投資で、改善パフォーマンスとは、コストを節約することを意味します。同時にパフォーマンスはユーザーエクスペリエンスを反映しており、応答時間はそれぞれ100ミリ秒と1秒で、ユーザーに与える印象はまったく異なります。 2. 高可用性 : は、システムが正常に動作できる時間を示します。 1 つは年間を通じてダウンタイムや障害が発生しないもので、もう 1 つはオンライン事故やダウンタイムが時折発生するもので、ユーザーは間違いなく前者を選択します。また、システムが90%しか利用できないと業務に大きな支障をきたします。 3. 高拡張性 : システムの拡張能力、 を示します。トラフィックのピーク時の短時間 容量拡張を完了し、ダブル 11 イベント、有名人の離婚、その他の話題のイベントなどのピークトラフィックをよりスムーズに処理します。 これら 3 つの目標は相互に関連しており、相互に影響を与えるため、総合的に検討する必要があります。 # というような言い方より #:システムのスケーラビリティを考慮して、## サービスをステートレスになるように設計します。##,この種のクラスタは、高いスケーラビリティを確保するように設計されています。実際、はシステムを時々アップグレードします パフォーマンスと使いやすさ。 別の例: 可用性を確保するために、通常、多数のスレッドが遅いリクエストをブロックしてシステム雪崩を引き起こすことを防ぐために、サービス インターフェイスにタイムアウト設定が設定されます。通常、依存するサービスのパフォーマンスに基づいて設定を行います。 から見てみましょう。ミクロな視点 高性能、高可用性、高スケーラビリティを測定するための具体的な指標は何でしょうか?なぜこれらの指標が選ばれたのでしょうか? パフォーマンス指標は、現在のパフォーマンスの問題を解決し、パフォーマンス最適化の評価の基礎としても機能します。一般的に、一定期間内のインターフェースの応答時間が指標として使用されます。 1. 平均応答時間: 最も一般的に使用されますが、明らかな欠陥があり、遅いリクエストの影響を受けません。たとえば、リクエストが 10,000 件あり、そのうち 9,900 件が 1 ミリ秒、100 件が 100 ミリ秒である場合、平均応答時間は 1.99 ミリ秒です。平均消費時間は 0.99 ミリ秒しか増加していませんが、リクエストの 1% の応答時間は 100 ミリ秒増加しています。回。 2、TP90、TP99、およびその他の分位値: 応答時間を小さいものから大きいものに並べ替えます。TP90 は 90 番目のポイントにランクされることを意味します。ビット応答時間。分位値が大きいほど、遅いリクエストに対する感度が高くなります。 3. スループット: スループットは応答時間に反比例します。応答時間は 1ms、スループットは 1 秒あたり 1000 回です。 通常、パフォーマンス目標を設定するときは、次のようにスループットと応答時間の両方が考慮されます。 1 秒あたり 1 リクエストが 10,000 件未満では、AVG は 50 ミリ秒未満に制御され、TP99 は 100 ミリ秒未満に制御されます。同時実行性の高いシステムの場合、AVG と TP の分位値を同時に考慮する必要があります。 また、ユーザーエクスペリエンスの観点から、200ミリ秒が第一の区切り点であり、ユーザーが遅延を感じにくい、1秒が第二の区切り点であり、ユーザーが遅延を感じることができると考えています。遅れますが、許容範囲です。 したがって、健全な高同時実行システムの場合、TP99 は 200 ミリ秒以内に制御され、TP999 または TP9999 は 200 ミリ秒以内に制御される必要があります。 1秒以内。 高可用性とは、システム 高い無障害動作能力を持っている 可用性 = 通常の動作時間 / システムの総動作時間 システムの可用性を表すには、一般に数桁の 9 が使用されます。 高同時実行システムの場合、最も基本的な要件は、3 つの 9 または 4 つの 9 を保証することです。理由は簡単です。9 が 2 つしか達成できない場合、故障時間は 1% であることを意味します。たとえば、一部の大企業では、年間の GMV または収益が 1,000 億を超えることもよくあります。1% は、1 のビジネス インパクトです。億レベル。 突然のトラフィックに直面して、アーキテクチャを一時的に変更することは不可能です。最速の方法は、マシンを追加してシステムの処理能力を直線的に向上させることです。 業務クラスタや基本コンポーネントの場合、スケーラビリティ = 性能向上率 / マシン追加率 理想的なスケーラビリティは、リソースが数台増加することです。倍になり、パフォーマンスが数倍向上します。 一般的に、拡張能力は 70% 以上に維持する必要があります。 しかし、同時実行性の高いシステムの全体的なアーキテクチャの観点から見ると、 の目標はサービスを拡張することだけではありません トラフィックが 10 倍に増加すると、ビジネス サービスはすぐに 10 倍に拡張できますが、データベースが新たなボトルネックになる可能性があるため、ステートレスに設計してください。 MySQL のようなステートフル ストレージ サービスは、通常、拡張が技術的に困難です。アーキテクチャが事前に計画されていない場合 (垂直分割と水平分割)、移行が必要になります。大量のデータ。 したがって、サービス クラスター、データベースなどのミドルウェア、キャッシュやメッセージ キュー、負荷分散、帯域幅、依存するサードパーティなど、高いスケーラビリティを考慮する必要があります。同時実行性が一定に達すると、これらの各要素は、後でスケーリングする際のボトルネックになる可能性があります。 その目標は、単一マシンの処理能力を向上させることです。 , プランには次の内容も含まれます: 1. 階層化アーキテクチャを適切に実行します。これは水平方向の拡張の進歩です。なぜなら、高同時実行システムには複雑なビジネスが含まれることが多く、階層化された処理によって複雑な問題が単純化され、水平方向の拡張が容易になるからです。 上の図は、インターネットの最も一般的な階層型アーキテクチャですが、もちろん、実際の高同時実行性システム アーキテクチャは、これをベースにしてさらに改良されることになります。例えば、動的と静的な分離が行われ、CDNが導入され、リバースプロキシ層はLVS Nginx、Web層は統合されたAPIゲートウェイ、ビジネスサービス層は垂直ビジネスに応じてさらにマイクロサービス化され、ストレージ層はさまざまな異種データベースにすることができます。 #2. 各レイヤーの水平拡張: ステートレスな水平拡張、ステートフルなシャード ルーティング。通常、ビジネス クラスタはステートレスになるように設計できますが、データベースとキャッシュは多くの場合ステートフルです。したがって、パーティション キーはストレージ シャーディング用に設計する必要があります。もちろん、読み取りパフォーマンスは、マスターとスレーブの同期や読み取りと書き込みの分離によって改善することもできます。 1、クラスター展開、負荷による単一マシンへの負荷を軽減します。バランスをとること。 上記のソリューションは、コンピューティングと IO の 2 つの側面から考えられるすべての最適化ポイントを考慮したものにすぎません。現在のパフォーマンスをリアルタイムで理解するには、サポートする監視システムが必要です。パフォーマンスのボトルネック分析を実行し、28/20 原則に従って主な矛盾に焦点を当てて最適化します。 #1. ピア ノードのフェイルオーバー: Nginx とサービス ガバナンス フレームワークの両方が、ピア ノードの障害をサポートします。別のノードにアクセスします。 高可用性ソリューションは主に、冗長性、トレードオフ、システムの運用と保守の 3 つの方向から検討され、同時にサポート機能や障害対応機能も必要となります。オンラインで問題が発生した場合でも、時間内にフォローアップできます。 1. 合理的な階層化アーキテクチャ: たとえば、上記のインターネットで最も一般的なもの階層化アーキテクチャ。さらに、マイクロサービスは、 データ アクセス層とビジネス ロジック層に従って、よりきめ細かい方法でさらに階層化できます (ただし、パフォーマンスを評価する必要があり、ネットワーク内にもう 1 つのホップが存在する可能性があります)。 。 高い同時実行性は確かに複雑かつシステム的な問題です。スペースが限られているため、分散トレース、フルリンク ストレス テスト、柔軟なトランザクションなどが必要になります。すべては考慮すべき技術的な点です。また、ビジネスシナリオが異なれば、高同時実行性の実装ソリューションも異なりますが、全体的な設計思想や参考にできるソリューションは基本的に似ています。 同時実行性の高い設計では、 アーキテクチャ設計の 3 つの原則 (単純さ、適切さ、進化) も遵守する必要があります。 「時期尚早な最適化は諸悪の根源である」、 はビジネスの の実際の状況から切り離すことはできず、 過度に設計しないでください。 適切なソリューションが最も完璧です。 この記事によって、高同時実行性についてより包括的な理解が得られることを願っています。また、学ぶことができる経験や深い考え方をお持ちの場合は、コメントにメッセージを残してください。ディスカッションのためのエリア。 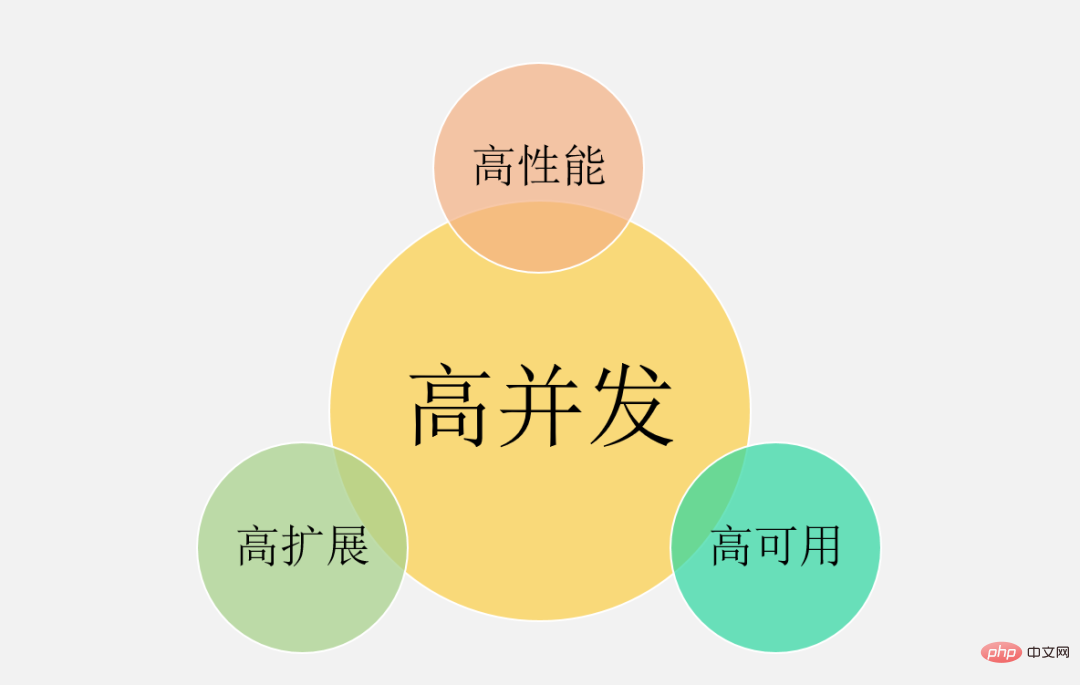
❇ パフォーマンス指標

❇ 可用性 インジケータ
❇ スケーラビリティ指標
❇ 垂直方向の拡張 (スケールアップ)
なぜなら、パフォーマンスには常に限界があるからです。単一マシンの場合、最終的には、次の 2 つの方向を含む、水平拡張の導入とクラスター展開による同時処理能力のさらなる向上が必要です:
❇ 高性能の実用的なソリューション
❇ 高可用性の実用的なソリューション
❇ 拡張性の高い実用的なソリューション
以上がインタビュアー: 高同時実行性についてどのくらい知っていますか?私:うーん...の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7490
7490
 15
1377
52
77
11
19
41
15
1377
52
77
11
19
41

 Go 言語の面接でよくある 5 つの質問と回答
Jun 01, 2023 pm 08:10 PM
Go 言語の面接でよくある 5 つの質問と回答
Jun 01, 2023 pm 08:10 PM
近年非常に人気が高まっているプログラミング言語として、Go言語は多くの企業や企業の面接で注目の的となっています。 Go 言語の初心者にとって、面接プロセス中に関連する質問にどのように答えるかは、検討する価値のある問題です。初心者向けに、Go 言語の面接でよくある 5 つの質問と回答を示します。 Go言語のガベージコレクションの仕組みを紹介してください。 Go 言語のガベージ コレクション メカニズムは、マーク スイープ アルゴリズムと 3 色マーキング アルゴリズムに基づいています。 Go プログラムのメモリ容量が足りない場合、Go ガベージ コレクターが
 2023 年のフロントエンド React 面接の質問の概要 (コレクション)
Aug 04, 2020 pm 05:33 PM
2023 年のフロントエンド React 面接の質問の概要 (コレクション)
Aug 04, 2020 pm 05:33 PM
有名なプログラミング学習 Web サイトとして、php 中国語 Web サイトは、フロントエンド開発者が React 面接の障害を準備してクリアできるように、React 面接の質問をいくつかまとめています。
 2023 年 Web フロントエンド面接厳選質疑応答完全集(コレクション)
Apr 08, 2021 am 10:11 AM
2023 年 Web フロントエンド面接厳選質疑応答完全集(コレクション)
Apr 08, 2021 am 10:11 AM
この記事では、Web フロントエンドの面接で収集する価値のある質問をいくつか抜粋してまとめています (回答付き)。一定の参考値があるので、困っている友達が参考になれば幸いです。
 マスターしなければならない 50 の Angular 面接の質問 (コレクション)
Jul 23, 2021 am 10:12 AM
マスターしなければならない 50 の Angular 面接の質問 (コレクション)
Jul 23, 2021 am 10:12 AM
この記事では、Angular の面接でマスターすべき 50 の質問を初級、中級、上級の 3 つのパートに分けて分析し、徹底的に理解するのに役立ちます。
 インタビュアー: 高同時実行性についてどのくらい知っていますか?私:うーん...
Jul 26, 2023 pm 04:07 PM
インタビュアー: 高同時実行性についてどのくらい知っていますか?私:うーん...
Jul 26, 2023 pm 04:07 PM
高い同時実行性は、ほぼすべてのプログラマーが望んでいるエクスペリエンスです。理由は簡単です。トラフィックが増加すると、インターフェイスの応答タイムアウト、CPU 負荷の増加、頻繁な GC、デッドロック、大規模なデータ ストレージなど、さまざまな技術的問題が発生するためです。これらの問題は、技術の深さの継続的な改善を促進することができます。
 2023 年の Vue の高頻度面接質問の共有 (回答分析付き)
Aug 01, 2022 pm 08:08 PM
2023 年の Vue の高頻度面接質問の共有 (回答分析付き)
Aug 01, 2022 pm 08:08 PM
この記事では、2023 年の vue の高頻度面接で収集する価値のある厳選された質問 (回答付き) をまとめています。一定の参考値があるので、困っている友達が参考になれば幸いです。
 高頻度の知識ポイントを習得するために、これらのフロントエンドの面接の質問を見てください (4)
Feb 20, 2023 pm 07:19 PM
高頻度の知識ポイントを習得するために、これらのフロントエンドの面接の質問を見てください (4)
Feb 20, 2023 pm 07:19 PM
毎日 10 問。100 日後には、フロントエンド面接の高頻度の知識ポイントをすべてマスターしていることになります。 ! ! , 記事を読みながら、答えを直接見るのではなく、まず知っているかどうか、知っている場合の答えは何かを考えてください。考えて、答えと比べてみてください。それが良いでしょうか? もちろん、私の答えよりも良い答えがある場合は、コメント欄にメッセージを残して、テクノロジーの美しさについて一緒に話し合ってください。
 知識を定着させるのに役立つ、フロントエンド面接でよくある質問 (回答付き) をまとめました。
Jul 29, 2022 am 09:49 AM
知識を定着させるのに役立つ、フロントエンド面接でよくある質問 (回答付き) をまとめました。
Jul 29, 2022 am 09:49 AM
記事を公開する主な目的は知識を定着させ、より熟練することです. すべては私自身の理解とネットで検索した情報に基づいています. 何か間違っている場合は、アドバイスをいただければ幸いです。以下は面接でよくある質問をまとめたもので、自分自身を監督するために今後も更新していきます。
