「URLを入力してページが表示されるまで」はネットで検索するとたくさんの情報が出てくるので、この記事を書き始めたときはかなり戸惑いました。また、この面接の質問は基本的に必須の質問であり、2月の面接では、途中経過はわかっていたものの、面接官が段階的に質問を続けると、詳細が不明な点が多くなりました。
#この記事の目的は、URL を入力した後に何が起こるかを通じて知識を要約し、広げることです。そのため記事が複雑になる可能性があります。
全体的なプロセスは次のとおりです:
ブラウザ URL を入力すると、ブラウザはすでに可能な URL をインテリジェントに照合しています。入力された文字列に対応する可能性のある URL を履歴レコードやブックマークなどから見つけて、インテリジェントなプロンプトを表示して、ユーザーが入力できるようにします。 URL: 完全な URL アドレス。 Google の Chrome ブラウザの場合は、Web ページをキャッシュから直接表示することもできます。つまり、Enter キーを押す前にページが表示されます。
2. ブラウザはドメイン名の IP アドレスを検索します1. リクエストが開始されると、ブラウザは最初にドメインを解決します。一般に、ブラウジングサーバーは、まずローカル ハード ディスク上の hosts ファイルをチェックして、このドメイン名に対応するルールがあるかどうかを確認し、存在する場合は、hosts ファイル内の IP アドレスを直接使用します。
2. 対応する IP アドレスがローカル ホスト ファイルで見つからない場合、ブラウザはローカル DNS サーバーに DNS リクエストを送信します。ローカル DNS サーバーは通常、チャイナ テレコムやチャイナ モバイルなどのネットワーク アクセス サーバー プロバイダーによって提供されます。
3. 入力した URL に対する DNS リクエストがローカル DNS サーバーに到達すると、ローカル DNS サーバーはまずキャッシュ レコードを照会します。キャッシュにこのレコードがある場合は、結果を直接返すことができます。このプロセスは再帰的クエリです。そうでない場合は、ローカル DNS サーバーも DNS ルート サーバーにクエリを実行します。
4. ルート DNS サーバーは、ドメイン名と IP アドレス間の特定の対応関係を記録せず、代わりに、ドメイン サーバーにアクセスしてクエリを続行できることをローカル DNS サーバーに伝えます。そしてドメインサーバーにアドレスを与えます。このプロセスは反復的なプロセスです。
5. ローカル DNS サーバーはドメイン サーバーへのリクエストを継続します。この例では、リクエスト オブジェクトは .com ドメイン サーバーです。 .com ドメイン サーバーは、リクエストを受信した後、ドメイン名と IP アドレスの対応関係を直接返すのではなく、ローカル DNS サーバーにドメイン名の解決サーバーのアドレスを伝えます。
###6. 最後に、ローカル DNS サーバーはドメイン名解決サーバーにリクエストを送信し、ドメイン名と IP アドレスの対応関係を受け取ります。ローカル DNS サーバーは IP アドレスをサーバーに返すだけでなく、この対応関係をユーザーのコンピュータに保存するだけでなく、次回別のユーザーがクエリを実行したときに結果を直接返すことができるため、ネットワーク アクセスが高速化されます。
#下の図は、このプロセスを完全に説明しています:

DNS (Domain Name System、ドメインネームシステム)、インターネット上のドメイン名と IP アドレスの分散マッピングこのデータベースを使用すると、ユーザーは、機械が直接読み取ることができる IP 文字列を覚えておく必要がなく、より便利にインターネットにアクセスできるようになります。ホスト名を介して最終的にホスト名に対応する IP アドレスを取得するプロセスをドメイン名解決 (またはホスト名解決) と呼びます。
一般的に、私たちは、167.23.10.2 などの IP アドレスを覚えるよりも、www.baidu.com などの Web サイトの名前を覚えることに慣れています。また、コンピューターは、www.baidu.com のようなリンクよりも、Web サイトの IP アドレスを記憶するのが得意です。 DNS は電話帳に相当するため、たとえば、www.baidu.com というドメイン名を探している場合、電話帳を見ると、ああ、その電話番号 (IP) は 167.23.10.2 であることがわかります。 。#2) DNS クエリの 2 つの方法: 再帰クエリと反復クエリ
# ローカル DNS サーバー自体がクライアントの DNS クエリに応答できない場合、他の DNS サーバーにクエリを実行する必要があります。このときの方法は2つあり、図に示した方法は再帰的方法です。ローカル DNS サーバーは他の DNS サーバーへのクエリを担当し、通常、最初にドメイン名のルート ドメイン サーバーにクエリを実行し、次にルート ドメイン ネーム サーバーが一度に 1 レベルずつ下位のクエリを実行します。最終的なクエリ結果はローカル DNS サーバーに返され、ローカル DNS サーバーはそれをクライアントに返します。
 2. 反復分析
2. 反復分析
ローカル DNS サーバー自体がクライアントの DNS クエリに応答できない場合は、図に示すようにクエリを反復することで解決することもできます。ローカル DNS サーバーは、自ら他の DNS サーバーにクエリを実行するのではなく、ドメイン名を解決できる他の DNS サーバーの IP アドレスをクライアント DNS プログラムに返します。クライアント DNS プログラムは、クエリの結果が得られるまで、これらの DNS サーバーにクエリを続けます。入手まで。つまり、反復分析は関連するサーバーを見つけるのに役立つだけで、サーバーを確認するのには役立ちません。例: baidu.com のサーバー IP アドレスは 192.168.4.5 です。ご自身で確認できます。私はとても忙しいので、ここでしかお手伝いできません。 私たちは前述したように、ルート DNS サーバーとドメイン DNS サーバーは、DNS ドメインの名前空間を構成する方法です。名前空間で DNS ドメイン名を記述するために使用される 5 つのカテゴリと、各名前タイプの例を以下の表に示します。 # Web サイトに十分なユーザーがいる場合、毎回要求されるリソースが同じマシン上にある場合、このマシンはいつでもポップオフになる可能性があります。解決策は、DNS 負荷分散テクノロジーを使用することです。その原理は、DNS サーバーで同じホスト名に対して複数の IP アドレスを構成することです。DNS クエリに応答するとき、DNS サーバーはホストによって記録された IP アドレスで各クエリに応答します。 DNS ファイル内で、異なる解析結果を順番に返し、クライアントのアクセスを異なるマシンに誘導し、異なるクライアントが異なるサーバーにアクセスするようにし、負荷分散を実現します。ユーザーは地理的距離などにすることができます。 3. ブラウザは Web サーバーに HTTP リクエストを送信します。 この接続要求は (LAN を除くさまざまなルーティング デバイスを介して) サーバーに到達した後、ネットワーク カードに入り、次にカーネルの TCP/IP プロトコル スタックに入ります (識別するために使用されます)。接続要求、カプセル化解除パケット、層ごとに剥がされます)、また、場合によっては Netfilter ファイアウォール (カーネルに属するモジュール) によってフィルタリングする必要があり、最終的に WEB プログラムに到達し、最終的に TCP/IP 接続を確立します。 (1) リクエストの 1 行目は「メソッド URL 提案/バージョン」: GET/sample.jsp HTTP/1.1 (2) リクエスト ヘッダー (Request Header)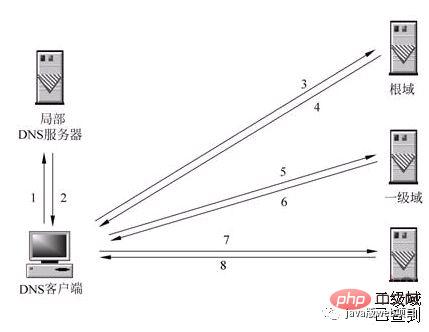
3) DNS ドメイン名前空間の構成方法

<span style="font-size: 16px;"><p style="margin: 10px auto;line-height: 25px;font-family: 微软雅黑;font-size: 14px;white-space: normal;background-color: rgb(255, 255, 255);"> <span style="font-size: 16px;"> TCP 接続を確立した後、http リクエストを開始します。一般的な http リクエスト ヘッダーには、通常、GET や POST などのリクエスト メソッドを含める必要があります。あまり一般的には使用されないものには、PUT および DELETE、HEAD、OPTION、TRACE メソッドなどがあります。一般的なブラウザは、GET または POST リクエストのみを開始できます。 </span></p>
<p style="margin: 10px auto;line-height: 25px;font-family: 微软雅黑;font-size: 14px;white-space: normal;background-color: rgb(255, 255, 255);"><span style="font-size: 16px;"> クライアントがサーバーに対して http リクエストを開始すると、いくつかのリクエスト情報が存在します。リクエスト情報には 3 つの部分が含まれます。リクエストメソッド URI プロトコル/バージョン</span></p>
<p style="margin: 10px auto;line-height: 25px;font-family: 微软雅黑;font-size: 14px;white-space: normal;background-color: rgb(255, 255, 255);"><span style="font-size: 16px;"> | リクエストヘッダー</span></p>
<p style="margin: 10px auto;line-height: 25px;font-family: 微软雅黑;font-size: 14px;white-space: normal;background-color: rgb(255, 255, 255);"><span style="font-size: 16px;"> | リクエストテキスト: </span></p>
<p style="margin: 10px auto;line-height: 25px;font-family: 微软雅黑;font-size: 14px;white-space: normal;background-color: rgb(255, 255, 255);"><span style="font-size: 16px;">The以下は完全な HTTP リクエストの例です: </span></p>
<p style="margin: 10px auto;line-height: 25px;font-family: 微软雅黑;font-size: 14px;white-space: normal;background-color: rgb(255, 255, 255);"></p>
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false;">GET/sample.jspHTTP/1.1Accept:image/gif.image/jpeg,*/*Accept-Language:zh-cn
Connection:Keep-Alive
Host:localhost
User-Agent:Mozila/4.0(compatible;MSIE5.01;Window NT5.0)
Accept-Encoding:gzip,deflate
username=jinqiao&password=1234</pre><div class="contentsignin">ログイン後にコピー</div></div>
<span style="font-size: 16px;"></span> </span>
リクエスト ヘッダーには、クライアント環境とリクエスト本文に関する多くの有用な情報が含まれています。たとえば、リクエスト ヘッダーでは、ブラウザで使用される言語、リクエスト本文の長さなどを宣言できます。 Accept:image/gif.image/jpeg.*/*
Accept-Language:zh-cn
Connection:Keep-Alive
Host:localhost
User-Agent:Mozila/4.0(compatible:MSIE5.01:Windows NT5.0)
Accept-Encoding:gzip,deflate.
(3) リクエスト ボディ
username=jinqiao&password=1234
4. サーバーの永続的なリダイレクト応答
なぜサーバーは、ユーザーが見たい Web ページのコンテンツを直接送信するのではなく、リダイレクトする必要があるのでしょうか?理由の 1 つは、検索エンジンのランキングに関係しています。 http://www.yy.com/ と http://yy.com/ のように、ページに 2 つのアドレスがある場合、検索エンジンはそれらを 2 つの Web サイトであると認識し、その結果、各検索リンクが減少し、検索結果が減少します。また、検索エンジンは 301 永久リダイレクトの意味を知っているため、www を含むアドレスと含まないアドレスを同じ Web サイトのランキングでランク付けします。また、異なるアドレスを使用するとキャッシュの扱いやすさが低下し、ページに複数の名前がある場合、キャッシュに何度も表示される可能性があります。
301 と 302 のステータス コードは両方ともリダイレクトを示し、サーバーから返されたステータス コードを取得した後、ブラウザが自動的に新しい URL アドレスにジャンプすることを意味します。応答の Location ヘッダー (ユーザーに表示される効果は、入力したアドレス A が別のアドレス B に即座に変更されることです) - これが共通点です。
# 違いは次のとおりです。 301 は、古いアドレス A のリソースが完全に削除されたことを示します (このリソースにはアクセスできなくなりました)。検索エンジンは、新しいコンテンツをクロールするときに、古い URL をリダイレクトされた URL と交換します;
302 は、古いアドレス A のリソースがまだそこにある (まだアクセスできる) ことを意味します。このリダイレクトは、古いアドレス A からアドレス B に一時的にジャンプするだけです。 検索エンジンはクロールします。新しいコンテンツを取得し、古い URL を保存します。 SEO302 は 301 より優れています
2) リダイレクトの理由:
(1) ウェブサイトの調整 (変更など) Web ページのディレクトリ構造); (2) Web ページが新しいアドレスに移動されます; (3) Web ページの拡張子が変更されます (アプリケーションで .php を変更する必要がある場合) .Html または .shtml) に変換します。 この場合、リダイレクトがない場合、ユーザーのお気に入りまたは検索エンジンのデータベースにある古いアドレスにより、訪問顧客に 404 ページ エラー メッセージが表示されるだけで、アクセス トラフィックは無駄に失われます。 ; さらに、一部の登録 複数のドメイン名を持つ Web サイトでは、これらのドメイン名にアクセスしたユーザーをメイン サイトに自動的にジャンプするようにリダイレクトする必要もあります。これで、ブラウザは「http://www.google.com/」がアクセスすべき正しいアドレスであることを認識したため、別の http リクエストを実行します。送信されます。ここで言うことは何もありません
6. サーバーのリクエスト処理前の手順の後、最終的に http リクエストをサーバーに送信しました。方向性がサーバーに到達しました。では、サーバーはリクエストをどのように処理するのでしょうか?
后端从在固定的端口接收到TCP报文开始,它会对TCP连接进行处理,对HTTP协议进行解析,并按照报文格式进一步封装成HTTP Request对象,供上层使用。
一些大一点的网站会将你的请求到反向代理服务器中,因为当网站访问量非常大,网站越来越慢,一台服务器已经不够用了。于是将同一个应用部署在多台服务器上,将大量用户的请求分配给多台机器处理。此时,客户端不是直接通过HTTP协议访问某网站应用服务器,而是先请求到Nginx,Nginx再请求应用服务器,然后将结果返回给客户端,这里Nginx的作用是反向代理服务器。同时也带来了一个好处,其中一台服务器万一挂了,只要还有其他服务器正常运行,就不会影响用户使用。
如图所示:
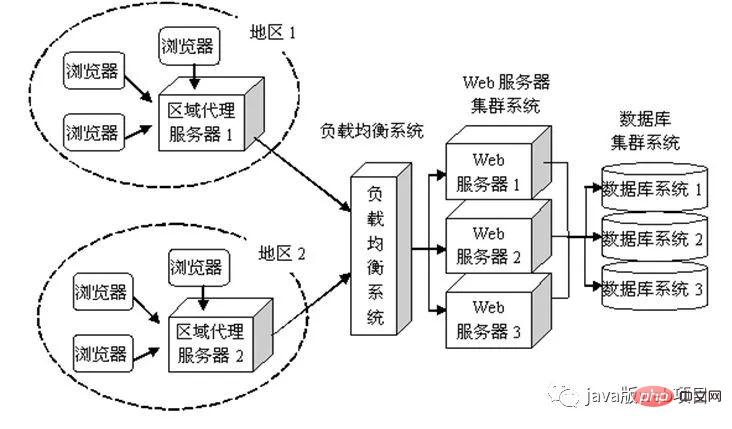
通过Nginx的反向代理,我们到达了web服务器,服务端脚本处理我们的请求,访问我们的数据库,获取需要获取的内容等等,当然,这个过程涉及很多后端脚本的复杂操作。由于对这一块不熟,所以这一块只能介绍这么多了。
经过前面的6个步骤,服务器收到了我们的请求,也处理我们的请求,到这一步,它会把它的处理结果返回,也就是返回一个HTPP响应。
HTTP响应与HTTP请求相似,HTTP响应也由3个部分构成,分别是:
l 状态行
l 响应头(Response Header)
l 响应正文
HTTP/1.1 200 OK Date: Sat, 31 Dec 2005 23:59:59 GMT Content-Type: text/html;charset=ISO-8859-1 Content-Length: 122<html> <head> <title>http</title> </head><body> <!-- body goes here --> </body> </html>
状态行:
状态行由协议版本、数字形式的状态代码、及相应的状态描述,各元素之间以空格分隔。
格式: HTTP-Version Status-Code Reason-Phrase CRLF
例如: HTTP/1.1 200 OK
-- プロトコル バージョン : http1.0 を使用するか、他のバージョンを使用するか
##-- ステータスの説明 : ステータスの説明ステータス コードをテキストで簡単に説明します。たとえば、ステータス コードが 200 の場合、説明は問題ありません。
##--ステータス コード: ステータス コードは 3 桁で構成され、最初の桁でステータスが定義されます。応答のカテゴリであり、5 つの可能な値があります。次のとおり
#1xx: サーバーがクライアント要求を受信し、クライアントが要求の送信を続行できることを示す情報ステータス コード。
100 続行101 プロトコルの切り替え
2xx:成功サーバーがリクエストを正常に受信して処理したことを示すステータス コード。
200 OK は、クライアント リクエストが成功したことを示します。204 No Content は成功しましたが、エンティティのメイン部分は返されません
206 部分コンテンツは範囲 (Range) リクエストを正常に実行しました
3xx: リダイレクト ステータス コード。サーバーがクライアントはリダイレクトする必要があります。
301 Moved Permanently 永続的なリダイレクト。応答メッセージの Location ヘッダーにはリソースの新しい URL が必要です。302 Found Temporary redirection Orientation 、応答メッセージの Location ヘッダーに指定された URL は、リソースを一時的に見つけるために使用されます。
303 See Other 要求されたリソースには別の URI があり、クライアントは GET メソッドを使用して、リソース
304 Not Modified サーバーのコンテンツは更新されておらず、ブラウザのキャッシュは直接読み取ることができます
307 一時的なリダイレクト一時的なリダイレクト。 302 Found と同じ意味です。 302 は POST から GET への変換を禁止していますが、実際の使用では必ずしもそうではありません。さらに多くのブラウザがこの標準に従う可能性がありますが、ブラウザの特定の実装にも依存します
# 4xx
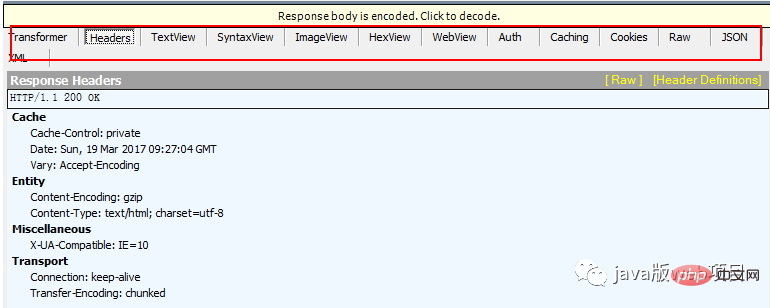
: クライアントのリクエストに不正なコンテンツが含まれていることを示すクライアント エラー ステータス コード。 400 Bad Request は、クライアント リクエストに構文エラーがあり、サーバーが理解できないことを示します。 401 Unauthonzed は、リクエストが承認されていないことを示します。このステータス コードは、 WWW-Authenticate と一致するようにする ヘッダー フィールドを一緒に使用する # 403 Forbidden は、サーバーがリクエストを受信したが、サービスの提供を拒否したことを意味します。サービスを提供しない理由は、通常、応答本文 404 Not Found 要求されたリソースが存在しません。たとえば、間違った URL が入力されました。 #5xx: サーバーが正常に機能しなかったことを示すサーバー エラー ステータス コード クライアントのリクエストの処理中に予期しないエラーが発生しました。 500 内部サーバー エラーは、サーバーで予期しないエラーが発生し、クライアントのリクエストを完了できなかったことを意味します。 503 サービスが利用できませんこれは、サーバーが現在クライアントのリクエストを処理できないことを意味します。一定時間が経過すると、サーバーは通常の状態に戻る可能性があります。 応答ヘッダー: 応答ヘッダー部分: キーワードと値のペアで構成され、1 行に 1 つのペアが含まれます。キーワードと値は英語のコロン「:」で区切られます。典型的な応答ヘッダーは次のとおりです: #応答テキスト # には、Cookie、HTML、画像、バックエンドから返されたリクエストデータなど。ここで注意すべき点は、レスポンスボディとレスポンスヘッダーの間にスペースが入っていることであり、レスポンスヘッダーの情報がスペースに到達していることを意味します。下の図は、fiddler によってキャプチャされたリクエストボディです。赤枠内: 応答本文: HTML を解析して dom ツリーを構築する -> レンダー ツリーを構築する -> レイアウト レンダー ツリー -> gt; レンダー ツリーを描画する ブラウザが HTML ファイルを解析するとき、「上から下に」ファイルを読み込み、読み込みプロセス中に解析とレンダリングを実行します。解析プロセス中に、画像、外部リンク CSS、アイコンフォントなどの外部リソースに対するリクエストがある場合、リクエスト プロセスは非同期であり、HTML ドキュメントの読み込みには影響しません。 解析プロセス中、ブラウザはまず HTML ファイルを解析して DOM ツリーを構築し、次に CSS ファイルを解析してレンダリング ツリーを構築します。レンダリング ツリーが構築された後、ブラウザはレンダリング ツリーのレイアウトを開始し、画面に描画されます。このプロセスは比較的複雑で、リフローと再ペイントという 2 つの概念が関係します。 DOM ノードの各要素はボックス モデルの形式で存在しており、ブラウザがその位置とサイズを計算する必要があります。このプロセスはリローと呼ばれます。位置、サイズ、および色やフォントなどのその他の属性が決定されると、ブラウザはコンテンツの描画を開始します。このプロセスは再描画と呼ばれます。 ページは、最初に読み込まれるときに必然的にリフローと再ペインが発生します。リフローと再描画のプロセスは、特にモバイル デバイスで非常にパフォーマンスを消費するため、ユーザー エクスペリエンスが破壊され、場合によってはページがフリーズすることがあります。したがって、リフローを減らし、再塗装をできるだけ少なくする必要があります。 ドキュメントの読み込み中に js ファイルが見つかると、HTML ドキュメントのレンダリングがハングします (読み込み、解析、レンダリング)。同期) スレッドは、ドキュメント内の js ファイルがロードされるのを待つだけでなく、HTML ドキュメントのレンダリング スレッドが再開される前に、解析の実行が完了するまで待つ必要があります。 JS は最も古典的な document.write である DOM を変更する可能性があるため、JS の実行が完了する前にすべてのリソースの後続のダウンロードが必要ない可能性があることを意味します。これが、js が後続のリソースのダウンロードをブロックする根本的な理由です。ということで、通常のコードではhtml文書の最後にjsが置かれていることが分かりました。 JS の解析は、Google の V8 などのブラウザの JS 解析エンジンによって完了します。 JS は単一のスレッドで実行されます。つまり、同時に実行できるのは 1 つのことだけです。すべてのタスクはキューに入れられる必要があります。前のタスクは、次のタスクが開始される前に終了します。ただし、IO の読み取りや書き込みなど、時間がかかるタスクもあるため、同期タスク (synchronous) と非同期タスク (asynchronous) という、後のタスクを先に実行する仕組みが必要です。 JS の実行メカニズムは、メインスレッドとタスクキューとみなすことができます。同期タスクはメインスレッドで実行されるタスクであり、非同期タスクはタスクキューに配置されるタスクです。すべての同期タスクはメイン スレッドで実行され、実行スタックを形成します。非同期タスクは、実行結果があるとタスク キューにイベントを配置します。スクリプトの実行中は、最初に実行スタックを順番に実行します。タスクキュー内のタスクでは、この処理が継続的に繰り返されるため、イベントループとも呼ばれます。具体的なプロセスについては、私の記事をご覧ください: ここをクリックしてください 実際、このステップは次のように並行して行うことができます。ステップ 8. ブラウザは HTML を表示すると、他のアドレスのコンテンツを取得する必要があるタグに気づきます。この時点で、ブラウザはファイルを取得するためのフェッチ リクエストを送信します。たとえば、次のリンクのような外部画像、CSS、JS ファイルなどを取得したいとします。 Picture: http://static.ak.fbcdn.net/ rsrc.php/z12E0 /hash/8q2anwu7.gif CSS スタイル シート: http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css JavaScript ファイル: http://static.ak.fbcdn.net/rsrc.php/zEMOA/hash/c8yzb6ub.js これらのアドレスは、HTML の読み取りと同様のプロセスを経験する必要があります。そのため、ブラウザーは DNS でこれらのドメイン名を検索し、リクエストを送信し、リダイレクトなどを行います... 動的ページとは異なり、静的ファイルではブラウザーがページをキャッシュできます。ファイルによっては、サーバーと通信する必要がない場合もありますが、キャッシュから直接読み取ることも、CDN に配置することもできます。この時点で、URL の入力からようやくページ表示が完了しました。もちろん、書き方には限界があり、間違いがあるかもしれませんが、この記事が多くの記事を参照していることをご指摘いただくのは歓迎ですが、多くの記事へのリンクを覚えていないため、以下の 3 つの参考リンクのみを記載します。 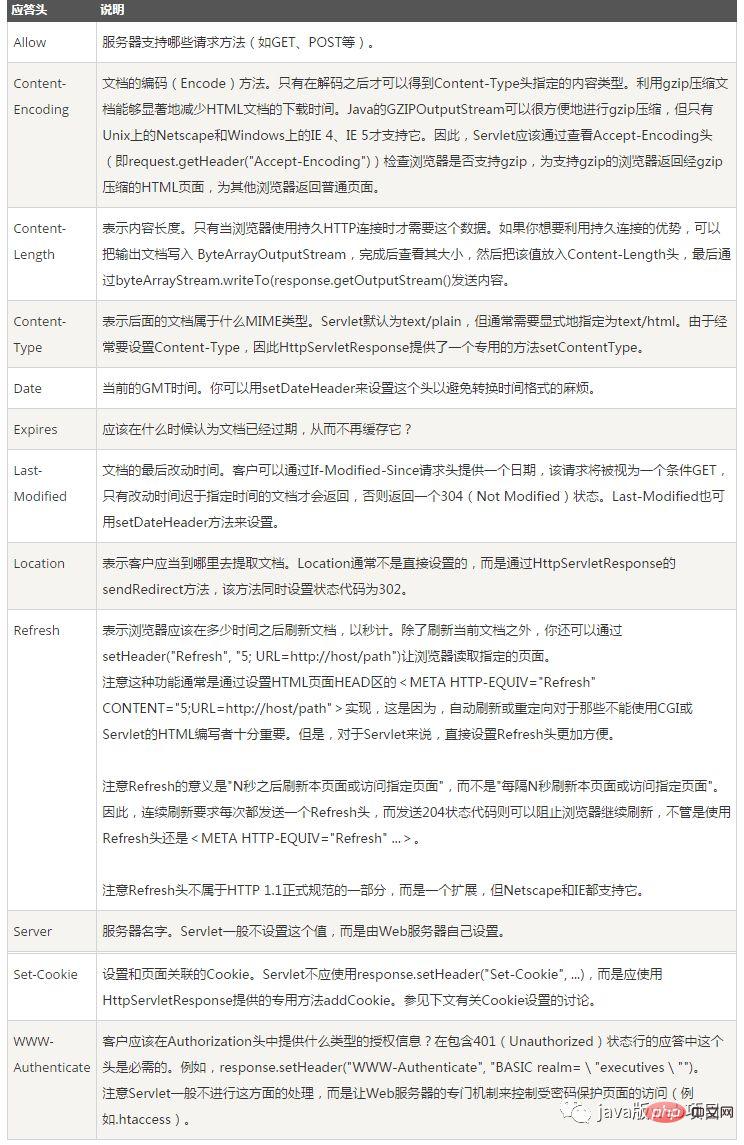
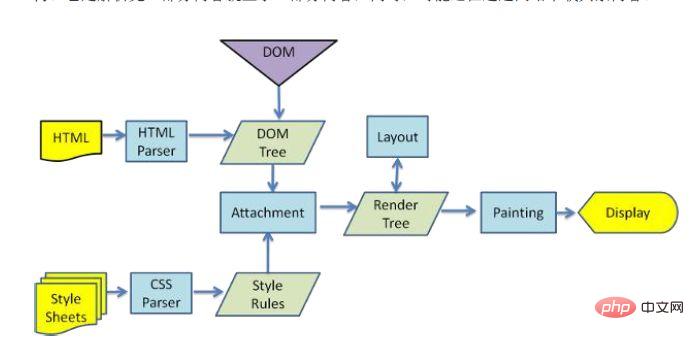
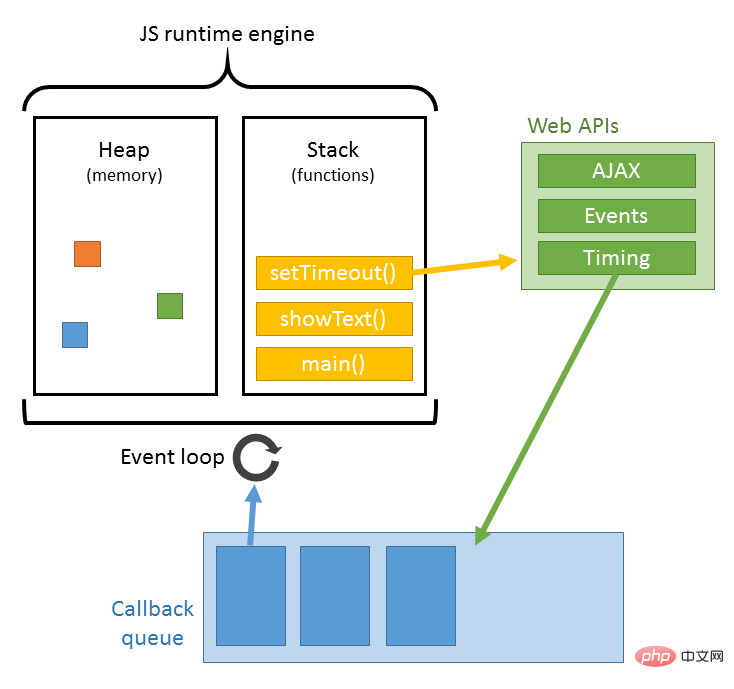
9. ブラウザは、HTML に埋め込まれたリソース (画像、音声、ビデオ、CSS、JS など) を取得するリクエストを送信します。
以上が面接で必ず聞かれる質問:URLを入力してページが表示されるまで、具体的にはどうなるのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



