
さっそく、次の図に直接進みましょう。
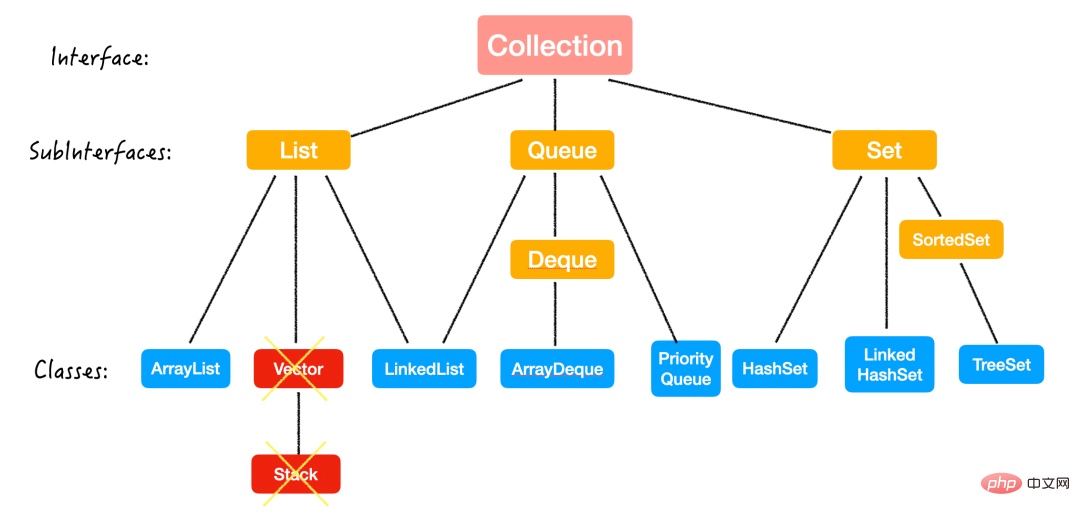
Java コレクション (コンテナーとも呼ばれます) , 主に 2 つの主要なインターフェイス (インターフェイス) から派生します: Collection と Map
名前が示すように、コンテナーはデータを保存するために使用されます。
これら 2 つのインターフェイスの違いは次のとおりです:
つまり、シングルはコレクションに配置され、カップルはマップに配置されます。 (それで、あなたはどこに属しますか?
これらのコレクション フレームワークを学習すると、次の 4 つの目標があると思います:
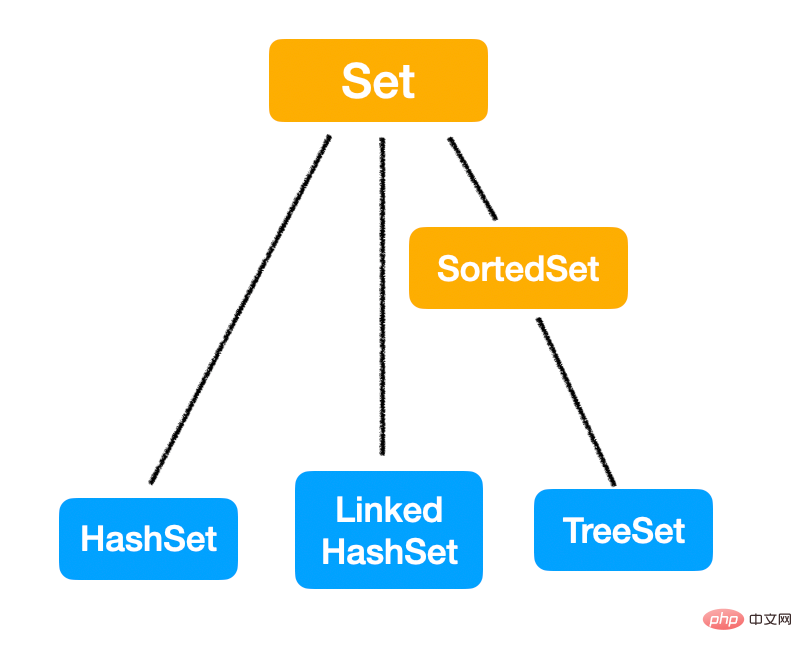
Map については、以前の HashMap の記事が非常に徹底的かつ詳細に説明されています。なので、この記事では詳しくは書きませんが、まだ記事を読んでいない方は、公式アカウントにアクセスして「HashMap」とリプライして記事を読んでみてください~
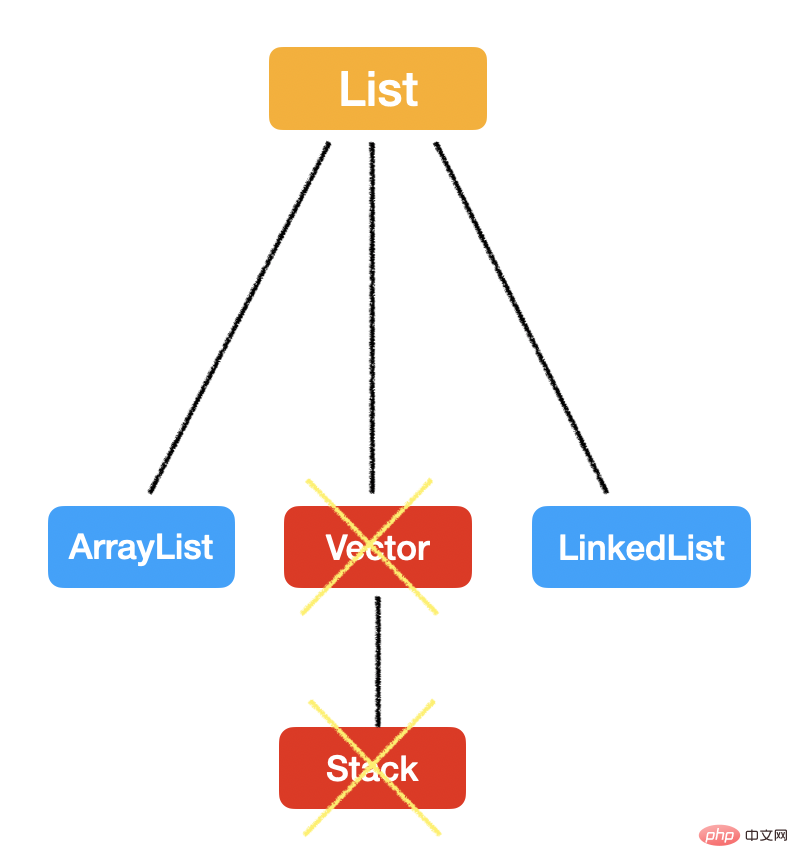
まずトップレベルのコレクションを見てみましょう。
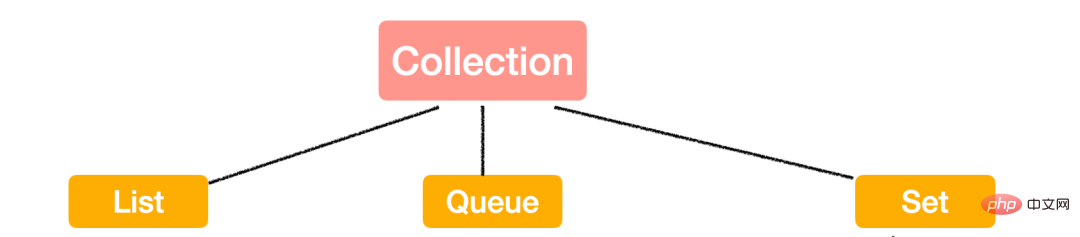
コレクションには多くのメソッドも定義されており、これらのメソッドは各サブインターフェイスや実装クラスにも継承されます。これらの API の使用は、日常業務や面接でもよく行われるテストです。まずはこれらのメソッドを見てください。
操作のコレクションは、「追加、削除、変更、確認」の 4 つのカテゴリにすぎず、CRUD:
Create、Read とも呼ばれます。
次に、これらの API を次の 4 つのカテゴリに分類します:
| 関数 | メソッド | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Add | add()/addAll() | |||||||||||||||||||||||
| 削除 | delete()/removeAll( ) | |||||||||||||||||||||||
| コレクション インターフェイスに | ||||||||||||||||||||||||
| contains()/ containsAll() | ||||||||||||||||||||||||
| isEmpty()/size()/toArray() |
| メソッド | ArrayList | LinkedList | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| add(E e) | O(1) | O(1) | ||||||||||||||||||||||
| add(int インデックス, E e) | O(n) | O(n) | ||||||||||||||||||||||
| 削除(int インデックス) | O(n) | O(n) | ||||||||||||||||||||||
| remove(E e) | O(n) | #O(n)#Change | ||||||||||||||||||||||
| O(1) | O(n) | Check | ||||||||||||||||||||||
| O(1) ######の上)############ いくつかの説明:
回答 :
「追加と削除」についてはどうでしょうか? この要素を見つける時間を考慮しない場合、 配列は物理的に連続しているため、要素を追加したり削除したりする場合は末尾でも大丈夫ですが、他の場所に移動すると後続の要素が削除されるため、効率が低下しますが、リンク リストでは次の要素との接続が簡単に切断されるため、新しい要素を直接挿入したり、古い要素を削除したりすることができます。 しかし、実際には、要素を見つけるまでの時間を考慮する必要があります。 。 。また、データ量が多い場合はArrayListを最後尾で動作させると高速になります。 ##つまり:
Vector も ArrayList と同様に java.util.AbstractListから継承し、最下層も配列を使用して実装されます。 よくある面接の質問: Vector と ArrayList の違いは何ですか? これに答えるだけでは、あまり包括的ではありません。 スタック オーバーフローに関する投票の多かった回答を見てみましょう:  1 つ目は、先ほど述べたスレッド セーフティの問題です。 ; 1 つ目は、先ほど述べたスレッド セーフティの問題です。 ;
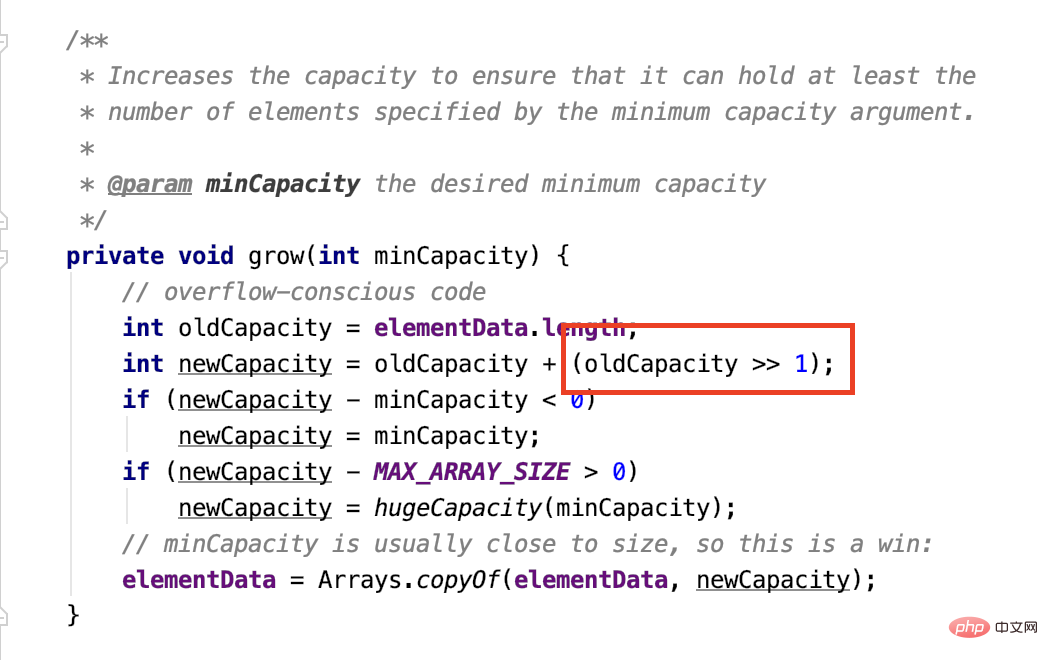 算術右シフト 算術右シフトが符号ビット を補いますが、容量には負の数がないため、やはり 0 を加算します。 1 ビットを右にシフトすると、 2 で除算され、定義される新しい容量は元の容量の 1.5 倍 になります。 Vector をもう一度見てみましょう: 通常、capacityIncrement を定義しないため、デフォルトでは 2 回拡張されます。 この2点に答えていただければ、間違いなく問題ありません。 Queue と DequeQueue は、一方の端が入力でもう一方の端が出力である線形データ構造であり、Deque両端ですので全て出入り可能です。 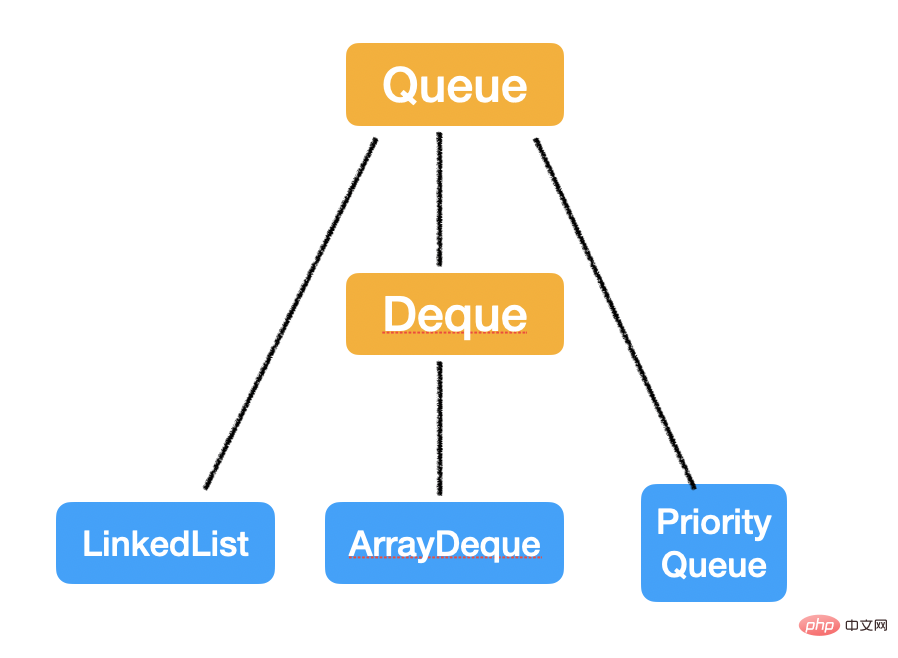 QueueJava の Queue インターフェイスは少しわかりにくいです。一般的に、セマンティクスは次のとおりです。キューの数 これらはすべて 先入れ先出し (FIFO) です。 しかし、ここには例外があります。つまり、PriorityQueue (ヒープとも呼ばれます) は、入力された時間順に出力されるのではなく、指定された優先順位に従って出力され、その操作は O ではありません。 (1)、時間 複雑さの計算は少し複雑なので、後ほど別の記事で説明します。 Queue メソッド公式ウェブサイト[1]すべてをまとめました。2 つの API セットがあり、基本的な機能は同じですが、次のとおりです。
|























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



