

入社してキャッシュとは何かを理解した
##まえがき
実際はこんな感じです。リーダーが引き継ぎました。perf ハードウェア パフォーマンス監視タスクがあります。perf を使用するプロセス中に、コマンド perf list を入力すると、次の情報が表示されました。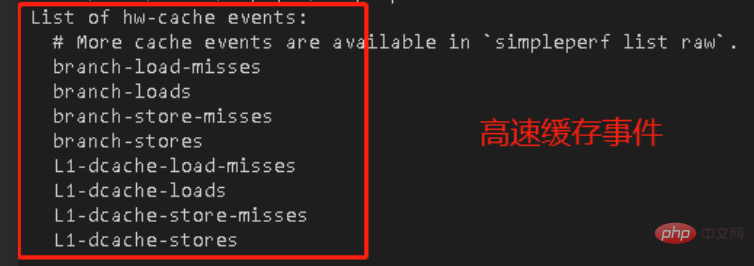
misses と loads が何を意味するのかわからないということです。
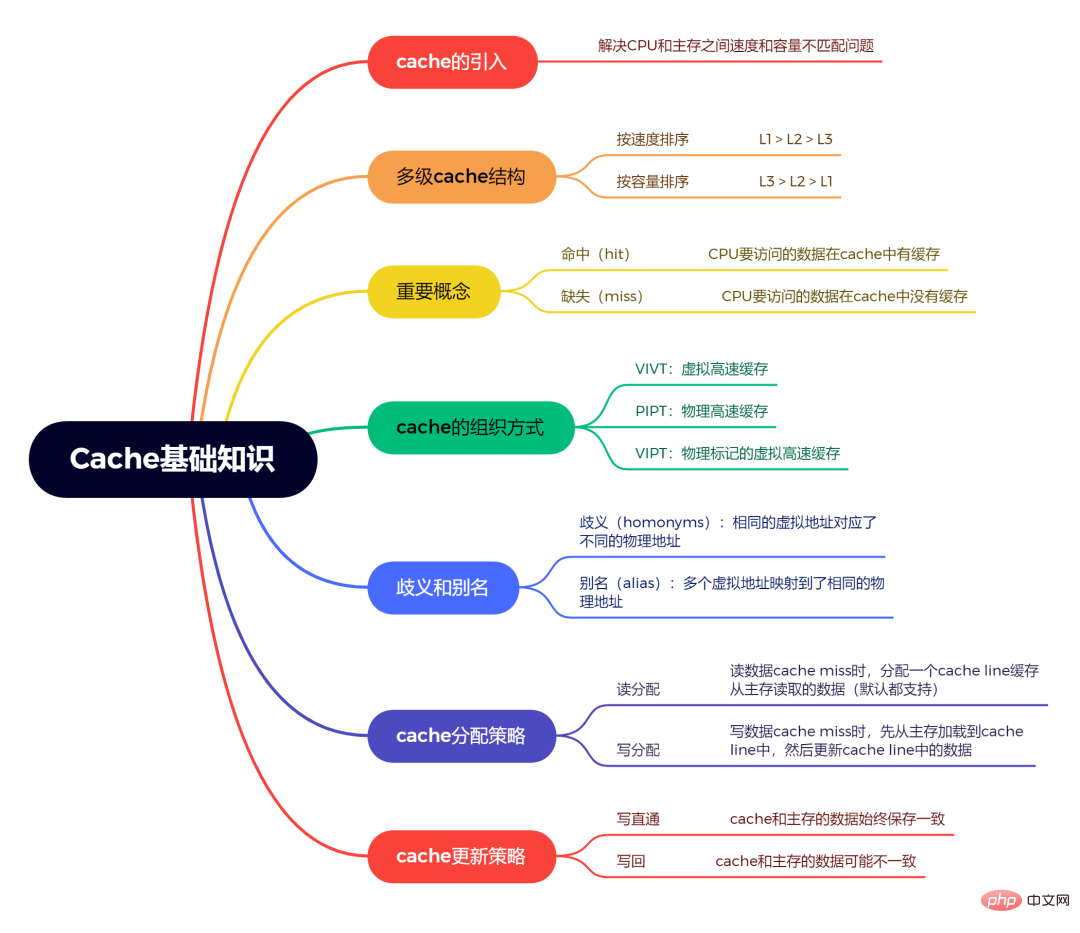
1. キャッシュとは何ですか?
まず、CPU はメモリに直接アクセスせず、最初にキャッシュを経由する必要があることを知っておく必要があります。 原因: CPU内のデータはレジスタに格納されており、レジスタへのアクセス速度は非常に速いですが、レジスタの容量は小さいです。メモリ容量は多いですが、速度は遅いです。CPU とメモリ間の速度と容量の問題を解決するために、キャッシュ Cache が導入されます。
キャッシュは CPU とメイン メモリの間にあります。CPU がメイン メモリにアクセスするとき、まずキャッシュにアクセスして、キャッシュにそのようなデータがあるかどうかを確認します。ある場合は、キャッシュからデータを CPU に返します; キャッシュにデータがない場合は、メイン メモリに再度アクセスします。
2. マルチレベル キャッシュのストレージ構造
一般的に言えば、キャッシュは複数ありますが、 、つまりマルチレベルキャッシュですが、なぜですか?
理由: CPU アクセス キャッシュも非常に高速です。しかし、速度と容量を完全に両立させることはできず、CPU がキャッシュにアクセスする速度と CPU がレジスタにアクセスする速度が同じであれば、キャッシュは非常に高速であるが、容量は非常に小さいことを意味します。小さなキャッシュ容量ではニーズを満たすことができないため、マルチレベル キャッシュが導入されました。
マルチレベル キャッシュは、キャッシュを複数のレベル L1、L2、L3 などに分割します。
#速度に応じて、L1 > L2 > L3 の順になります。
#ストレージ容量に応じて、L3 > L2 > L1 の順になります。
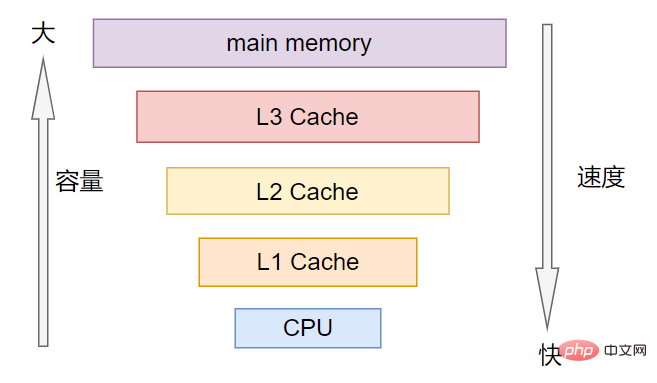
通常、L1 は命令キャッシュ (
ICache) とデータ キャッシュ (DCache) に分割され、L1 キャッシュは CPU 専用であり、それぞれCPU L1キャッシュあり。
#3. 「ヒット」と「ハズレ」とは何を意味しますか? Hit
: CPU がアクセスするデータがキャッシュにキャッシュされます。これを「ヒット」といいます。つまりcache hitMissing
キャッシュ ミスといいます。
4. キャッシュラインとは何ですか?
キャッシュ ライン: キャッシュ ライン。キャッシュは多くの等しいブロックに均等に分割され、各ブロックのサイズは キャッシュ ラインと呼ばれます。 ###。
キャッシュ ラインは、キャッシュとメイン メモリ間のデータ転送の最小単位でもあります。
CPU が 1 バイトのデータをロードしようとすると、キャッシュが見つからない場合、キャッシュ コントローラーはキャッシュ ライン サイズのデータをメイン メモリからキャッシュに一度にロードします。たとえば、キャッシュ ラインのサイズは 8 バイトです。 CPU が 1 バイトを読み取る場合でも、キャッシュが失われた後、キャッシュはメイン メモリから 8 バイトをロードして、キャッシュ ライン全体を埋めます。#CPU がキャッシュにアクセスするときのアドレス エンコーディングは、通常、タグ、インデックス、オフセットの 3 つの部分で構成されます。
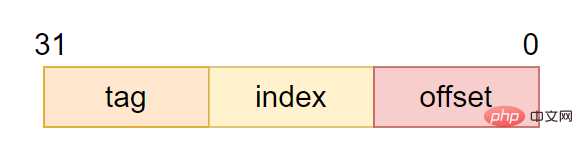
- ##tag
(タグフィールド): キャッシュラインにキャッシュされたデータのアドレスがプロセッサのアドレス指定アドレスと一致するかどうかを判断するために使用されます。 -
(インデックスフィールド): アドレスがキャッシュ内のどの行にあるかインデックスを付けて検索するために使用されます。
- (offset)
: キャッシュライン内のオフセット。キャッシュ ラインの内容は、ワードまたはバイトでアドレス指定できます。 キャッシュ ラインとタグ、インデックス、オフセットなどの関係は、図に示すとおりです。
#5. キャッシュは仮想アドレスにアクセスしますか?それとも物理アドレスにアクセスしますか?
CPU がメモリに直接アクセスするのではなく、CPU が仮想アドレスを発行し、それが MMU によって物理アドレスに変換され、その後データが送信されることがわかっています。物理アドレスに従ってメモリからフェッチされます。それでは、キャッシュは仮想アドレスにアクセスしているのでしょうか、それとも物理アドレスにアクセスしているのでしょうか?
回答: 必ずしもそうとは限りません。これは、仮想アドレス、物理アドレス、または仮想アドレスと物理アドレスの組み合わせのいずれかになります。
ハードウェア設計ではキャッシュを整理するさまざまな方法があるため:VIVT 仮想キャッシュ: インデックス仮想アドレスのタグと仮想アドレスのタグ。PIPT 物理キャッシュ: 物理アドレスのインデックス、物理アドレスのタグ。VIPT 物理的にタグ付けされた仮想キャッシュ: 仮想アドレスのインデックス、物理アドレスのタグ。
# 6. 曖昧さとエイリアシングの問題とは何ですか?
曖昧さ (同音異義語
): 同じ仮想アドレスが異なる物理アドレスに対応しますエイリアス (
alias): 複数の仮想アドレスが同じ物理アドレスにマッピングされます (複数の仮想アドレスはエイリアスと呼ばれます)。たとえば、上記の VIVT メソッドにはエイリアスの問題があります。VIVT、PIPT、VIPT のどれが優れていますか?
PIPTは、インデックスとタグの両方が物理アドレスを使用するため、実際には理想的です。 ソフトウェア レベルでは、あいまいさやエイリアスの問題を回避するためのメンテナンスは必要ありません。VIPTのタグは物理アドレスを使用しているため、あいまいさの問題はありませんが、インデックスは仮想アドレスであるため、 にはエイリアスの問題も発生する可能性があります。VIVTメソッドには、曖昧さとエイリアシングの問題が存在します。実際、現在ハードウェアで使用されているのは基本的に PIPT または VIPT です。 VIVT は問題が多すぎて、歴史になり、誰も使わなくなりました。さらに、PIVT 法は欠点だけで利点がなく、遅いだけでなく、曖昧性やエイリアシングの問題も存在するため存在しません。
キャッシュの構成、曖昧さおよびエイリアスの問題は、比較的大きなコンテンツです。ここで知っておく必要があるのは、キャッシュによってアクセスされるアドレスは、仮想アドレス、物理アドレス、または仮想アドレスと物理アドレスの組み合わせのいずれかである可能性があるということだけです。また、組織化方法が異なると、曖昧さやエイリアスの問題が発生します。
#7. キャッシュ割り当て戦略?
は、キャッシュミスが発生したときにキャッシュがどのように割り当てられるかを示します。
読み取り割り当て:
CPUがデータを読み取るとき、キャッシュがありません。この場合、キャッシュ ラインキャッシュが割り当てられます。 . メインメモリから読み取られたデータ。 デフォルトでは、cacheは読み取り割り当てをサポートします。書き込み割り当て: CPU 書き込みデータ
キャッシュが欠落している場合、書き込み割り当て戦略が考慮されます。書き込み割り当てをサポートしていない場合、書き込み命令はメイン メモリ データを更新するだけで終了します。書き込み割り当てがサポートされている場合、最初にメイン メモリからキャッシュ ラインにデータをロードし (最初に読み取り割り当てを実行するのと同じ)、次にキャッシュ ラインのデータを更新します。8. キャッシュ更新戦略?
は、キャッシュがヒットしたときに書き込み操作でデータを更新する方法を示します。
書き込みパススルー: CPU がストア命令を実行し、キャッシュがヒットすると、キャッシュ内のデータを更新し、メイン メモリ内のデータも更新します。 キャッシュとメインメモリ内のデータは常に一貫しています。
Writeback:
CPUがstore命令を実行し、cacheデータにヒットした場合にのみcache## を更新します。で #。そして、各キャッシュ ラインには、データが変更されたかどうかを記録するためのbitビットがあり、これはダーティ ビットと呼ばれます。ダーティビットを設定します。メイン メモリ内のデータは、キャッシュ ラインが置換されるか、明示的なclean操作が実行される場合にのみ更新されます。したがって、メイン メモリ内のデータは未変更のデータである可能性がありますが、変更されたデータは キャッシュ内にあります。 キャッシュとメインメモリ内のデータが不整合である可能性があります。最後に
キャッシュ、TLB、MESI、メモリ整合性モデルなどについて本当に習得するには、沈降と要約が必要なものです。 しかし、多くの人はこれを使用しないかもしれません。パフォーマンスの問題が発生し、キャッシュ ヒット率を改善する必要がある場合にのみ、この知識の重要性がわかります。 この記事で取り上げた知識について、キャッシュの基礎知識をマインドマップにまとめました。
以上が入社してキャッシュとは何かを理解したの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7480
7480
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 入社してキャッシュとは何かを理解した
Jul 31, 2023 pm 04:03 PM
入社してキャッシュとは何かを理解した
Jul 31, 2023 pm 04:03 PM
実際は次のようなものです。当時、私のリーダーは私に perf ハードウェア パフォーマンス監視タスクを与えました。perf を使用するプロセス中に、コマンド perf list を入力すると、次の情報が表示されました。私のタスクは、これらのキャッシュ イベントを有効にすることです。しかし重要なのは、これらのミスやロードが何を意味するのか全く分からないということです。
 キャッシュを使用するとコンピュータの速度が向上するのはなぜですか?
Dec 09, 2020 am 11:28 AM
キャッシュを使用するとコンピュータの速度が向上するのはなぜですか?
Dec 09, 2020 am 11:28 AM
キャッシュを使用すると、CPU の待ち時間が短縮されるため、コンピューターの速度が向上します。キャッシュは、CPU とメイン メモリ DRAM の間に位置する小さいながらも高速なメモリです。キャッシュの機能はCPUのデータ入出力速度を高めることであり、キャッシュは容量は小さいが速度が速く、メモリは速度は低いが容量が大きいため、スケジューリングアルゴリズムを最適化することでシステムのパフォーマンスを向上させることができます。大幅に改善されました。
 キャッシュとは何ですか?
Nov 25, 2022 am 11:48 AM
キャッシュとは何ですか?
Nov 25, 2022 am 11:48 AM
キャッシュはキャッシュメモリと呼ばれ、中央処理装置とメインメモリの間にある高速かつ小容量のメモリで、通常は高速SRAMで構成され、CPU向けのこの種のローカルメモリが導入されています。 CPU とメモリ間の速度差がシステム パフォーマンスに及ぼす影響を軽減または排除します。キャッシュ容量は小さいですが高速、メモリ速度は遅いですが容量は大きく、スケジューリングアルゴリズムを最適化することでシステムのパフォーマンスが大幅に向上します。
 SpringBootプロジェクトでキャッシュを使用する方法
May 16, 2023 pm 02:34 PM
SpringBootプロジェクトでキャッシュを使用する方法
May 16, 2023 pm 02:34 PM
Preface キャッシュは、頻繁にアクセスされるデータをメモリに保存し、データベースなどの基盤となるデータ ソースへの負担を軽減することで、システムのパフォーマンスと安定性を効果的に向上させることができます。誰もがプロジェクトで多かれ少なかれこれを使用したことがあると思いますが、私たちのプロジェクトも例外ではありませんでしたが、最近会社のコードをレビューしていたとき、非常に愚かでレベルの低い記述でした。 {Useruser=cache.getUser();if(user!=null){returnuser;}//データベースからユーザーを取得=loadFromDB(id);cahce.put(id,user);returnu
 nginx リバースプロキシキャッシュのチュートリアル。
Feb 18, 2024 pm 04:48 PM
nginx リバースプロキシキャッシュのチュートリアル。
Feb 18, 2024 pm 04:48 PM
nginx リバース プロキシ キャッシュのチュートリアルは次のとおりです。 nginx のインストール: sudoaptupdatesudoaptinstallnginx リバース プロキシの構成: nginx 構成ファイルを開きます: sdonano/etc/nginx/nginx.conf キャッシュを有効にするには、http ブロックに次の構成を追加します: http{...proxy_cache_path /var/cache/nginxlevels=1:2keys_zone=my_cache:10mmax_size=10ginactive=60muse_temp_path=off;proxy_cache
 Nginx キャッシュの構成計画と、関連するメモリ使用量の問題を解決する方法
May 23, 2023 pm 02:01 PM
Nginx キャッシュの構成計画と、関連するメモリ使用量の問題を解決する方法
May 23, 2023 pm 02:01 PM
nginx キャッシュの 5 つのオプション キャッシュ 1. 従来のキャッシュの 1 つ (404) この方法では、nginx の 404 エラーをバックエンドに送り、proxy_store を使用してバックエンドから返されたページを保存します。設定: location/{root/home/html/;#ホームディレクトリexpires1d;#Webページの有効期限error_page404=200/fetch$request_uri;#404 /fetchディレクトリに誘導される} Location/fetch/{#404ここに指定されています内部 ;#このディレクトリは外部から直接アクセスできないことを示します
 キャッシュ、rom、ramの特徴は何ですか?
Aug 26, 2022 pm 04:05 PM
キャッシュ、rom、ramの特徴は何ですか?
Aug 26, 2022 pm 04:05 PM
キャッシュの特徴:CPUとメインメモリの間に設けられた1層または2層の高速かつ小容量のメモリで、コンピュータの電源を切ると情報は自然に失われます。 ROM の特性: メモリからデータを読み取ることのみが可能ですが、情報を書き込むことはできず、コンピュータの電源を切ってもデータは残ります。 ram の特性: メモリからデータを読み取り、メモリに情報を書き込むことができます。プログラムの実行に必要なコマンド、プログラム、およびデータを保存するために使用されます。コンピュータの電源がオフになると、情報は自然に失われます。
 Spring Cache に基づいて Caffeine+Redis の 2 次キャッシュを実装する方法
Jun 01, 2023 am 10:13 AM
Spring Cache に基づいて Caffeine+Redis の 2 次キャッシュを実装する方法
Jun 01, 2023 am 10:13 AM
詳細は次のとおりです。 1. ハードコーディングされたキャッシュとは何ですか? SpringCache を学ぶ前は、ハードコーディングされた方法でキャッシュを使用することがよくありました。実際の例を見てみましょう。ユーザー情報のクエリ効率を向上させるために、ユーザー情報のキャッシュを使用します。サンプル コードは次のとおりです: @AutowireprivateUserMapperuserMapper; @AutowireprivateRedisCacheredisCache;//ユーザーをクエリ publicUsergetUserById(LonguserId){//キャッシュを定義しますkeyStringcacheKey= "userId_