

超包括的なコレクション - Linux パフォーマンス分析ツールの概要コレクション
Linux オペレーティング システムへの興味と基礎知識への強い欲求から、この記事を構成しました。 。この記事は、基本的な知識をテストするための指標としても使用でき、さらにシステムのあらゆる側面をカバーしています。コンピュータ システム、ネットワーク、オペレーティング システムの完全な知識がなければ、本書に記載されているツールを完全に使いこなすことは不可能であり、また、システム パフォーマンスの分析と最適化は長期にわたるシリーズです。
このドキュメントは主に、Linux の専門家である Brendan Gregg 氏 (Netflix シニア パフォーマンス アーキテクト) の、Linux システム パフォーマンスを収集するための Linux パフォーマンス チューニング ツールの更新に関するブログ投稿に基づいています。最適化関連の記事をまとめた包括的な記事で、主にブログ投稿と組み合わせた原理とパフォーマンス テスト ツールについて説明します。
#背景知識: パフォーマンスの問題を分析するときに知っておく必要があるのは、背景知識です。たとえば、ハードウェア キャッシュ、別の例としてはオペレーティング システムのカーネルがあります。アプリケーションの動作の詳細は、多くの場合、これらの事柄と絡み合っています。これらの低レベルの事柄は、アプリケーションのパフォーマンスに予期せぬ形で影響を与える可能性があります。たとえば、一部のプログラムはキャッシュを完全に利用できず、パフォーマンスの低下を引き起こします。たとえば、不必要に呼び出されるシステムコールが多すぎて、カーネル/ユーザーの切り替えが頻繁に発生するなどです。これは、この記事の続きの内容に向けての準備です。チューニングについては、まだまだ分からないことがたくさんあります。皆さんも一緒に学び、進歩していただければ幸いです。
【パフォーマンス分析ツール】
最初に写真を見てみましょう:
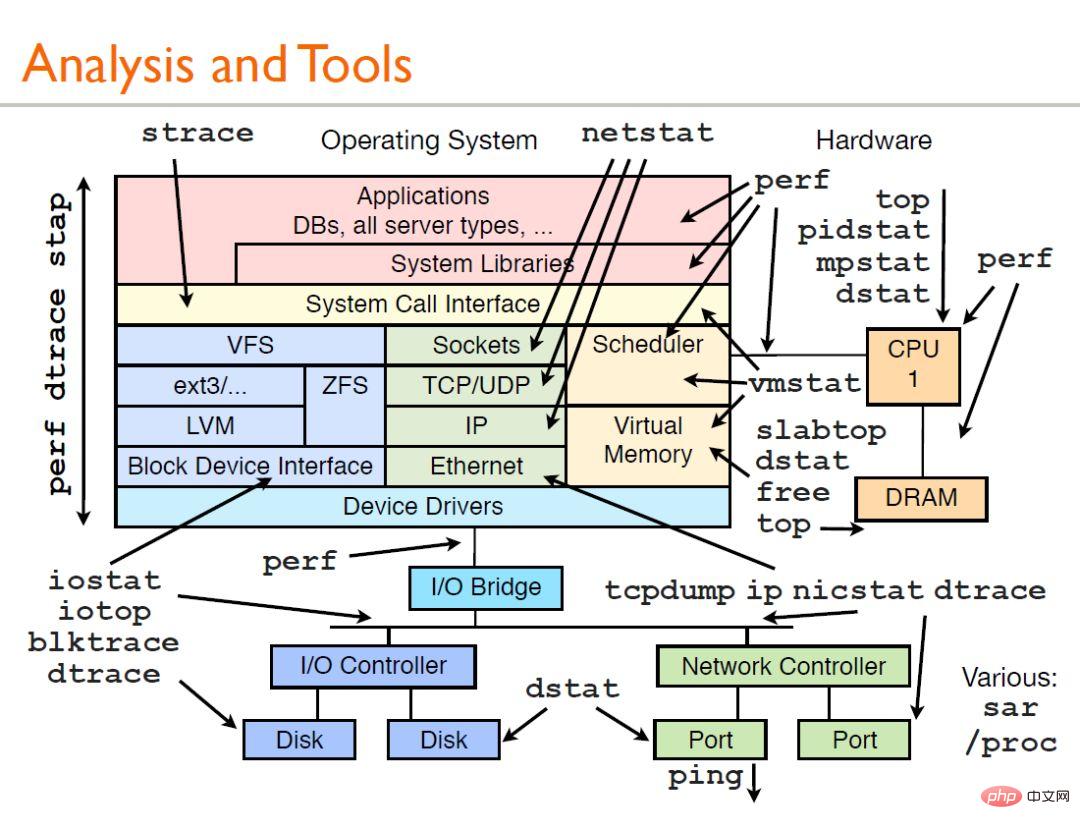
上の写真は、Brendan Gregg が共有したパフォーマンス分析です。 man からヘルプ ドキュメントを入手してください。一般的な使用法を簡単に説明します:
▲ vmstat--仮想メモリ統計
#vmstat (VirtualMeomoryStatistics、仮想メモリ統計) は、Linux でメモリを監視するための一般的なツールで、オペレーティング システムの仮想メモリ、プロセス、CPU などの全体的な状況を監視できます。
#vmstat の一般的な使用法: vmstat の間隔時間は、間隔秒ごとに 1 回、合計で 回サンプリングすることを意味します。時間を省略した場合は、 、その後、ユーザーが手動で停止するまでデータが収集されます。 #簡単な例:
 ##ctrl c を使用して、vmstat によるデータ収集を停止できます。
##ctrl c を使用して、vmstat によるデータ収集を停止できます。
最初の行はシステムが開始されてからの平均を示し、2 番目の行は現在何が起こっているかを示し始めます。次の行は 5 秒間隔ごとに何が起こっているかを示します。各列の意味は、先頭部分は次のようになります:
▪ procs: r 列は CPU を待機しているプロセスの数を示し、b 列は中断せずにスリープしている (IO を待機している) プロセスの数を示します。 。
▪ memory: swapd 列は、ディスクからスワップされたブロックの数 (ページ スワッピング) を示し、残りの列は空きブロックの数を示します。 (未使用)、使用中)、バッファとして使用されているブロックの数、およびオペレーティング システムのキャッシュとして使用されているブロックの数。
▪ swap: スワップ アクティビティを表示します。1 秒あたりに (ディスクから) スワップインおよび (ディスクに) スワップアウトされているブロック数を表示します。
io: ブロック デバイスから読み取られた (bi) および書き込まれた (bo) ブロックの数を示します。これは通常、ハードディスク I/O を反映します。
system: 1 秒あたりの割り込み (in) とコンテキスト スイッチ (cs) の数を表示します。
▪ cpu: ユーザー コードの実行 (カーネル以外)、システム コードの実行 (カーネル)、アイドル、IO の待機など、さまざまな操作に費やされたすべての CPU 時間の割合を表示します。 。
メモリ不足の症状: 空きメモリが急激に減少する、バッファとキャッシュをリサイクルしても役に立たない、スワップ パーティション (swpd) の広範な使用、頻繁なページ交換 (swap)、読み取り回数書き込みディスク (io) が増加し、ページ フォールト割り込み (in) が増加し、コンテキスト スイッチの数 (cs) が増加し、IO を待機しているプロセスの数 (b) が増加し、IO の待機に多くの CPU 時間が費やされます (わ)
▲iostat -- 中央処理装置の統計情報のレポートに使用されます。
iostat は、中央処理装置 (CPU) の統計情報と、システム全体、アダプター、TY デバイスのレポートに使用されます。 、ディスクおよび CD-ROM の入出力統計。デフォルトでは、vmstat と同じ CPU 使用率情報が表示されます。拡張デバイス統計を表示するには、次のコマンドを使用します:

最初の行はシステム起動以降の平均を示し、次に増分平均がデバイスごとに 1 行で表示されます。
一般的な Linux ディスク IO インジケーターの略語の習慣: rq はリクエスト、r は読み取り、w は書き込み、qu はキュー、sz はサイズ、a は平均、tm は時間、svc はサービス。
▪rrqm/s および wrqm/s: 1 秒あたりのマージされた読み取りおよび書き込みリクエスト。「マージ」とは、オペレーティング システムがキューから複数の論理リクエストを取り出し、それらを 1 つにマージすることを意味します。実際のディスクへのリクエスト。
▪r/s および w/s: デバイスに送信される 1 秒あたりの読み取りおよび書き込みリクエストの数。
▪rsec/s および wsec/s: 1 秒あたりの読み取りおよび書き込みセクター数。
▪avgrq –sz: 要求されたセクター数。
▪avgqu –sz: デバイス キューで待機しているリクエストの数。
▪await:每個IO請求花費的時間。
▪svctm:實際請求(服務)時間。
▪%util:至少有一個活躍請求所佔時間的百分比。
▲dstat--系統監控工具
dstat顯示了cpu使用情況,磁碟io情況,網路發包情況和換頁情況,輸出是彩色的,可讀性較強,相對於vmstat和iostat的輸入更加詳細且較為直觀。使用時,直接輸入指令即可,當然也可以使用特定參數。
如下:dstat –cdlmnpsy
▲iotop- -LINUX進程即時監控工具
iotop指令是專門顯示硬碟IO的指令,介面風格類似top指令,可以顯示IO負載具體是由哪個行程產生的。是用來監視磁碟I/O使用狀況的top類工具,具有與top相似的UI,其中包括PID、使用者、I/O、進程等相關資訊。
可以以非互動的方式使用:iotop –bod interval,檢視每個行程的I/O,可以使用pidstat,pidstat –d instat。
搜尋公眾號Linux中文社群後台回覆「私房菜”,取得驚喜禮包。
▲pidstat--監控系統資源狀況
pidstat主要用於監控全部或指定進程佔用系統資源的情況,如CPU,記憶體、設備IO、任務切換、執行緒等。
使用方法:pidstat –d interval;pidstat也可以用以統計CPU使用資訊:pidstat –u interval;統計記憶體資訊:Pidstat –r interval。
▲#top
top指令的匯總區域顯示了五個面向的系統效能資訊:
1.負載:時間,登陸用戶數,系統平均負載;
#2.進程:運行,睡眠,停止,殭屍;
#3.cpu:用戶狀態,核心態,NICE,空閒,等待IO,中斷等;
4.記憶體:總量,已用,空閒(系統角度),緩衝,快取;
5.交換分區:總量,已使用,空閒
任務區域預設顯示:進程ID,有效用戶,進程優先權,NICE值,進程使用的虛擬內存,物理內存和共享內存,進程狀態,CPU佔用率,內存佔用率,累計CPU時間,進程命令行資訊。
▲#htop
htop 是Linux系統中的一個互動的程序檢視器,一個文字模式的應用程式(在控制台或X終端機中),需要ncurses。 
Htop可讓使用者互動式操作,支援顏色主題,可橫向或縱向捲動進程列表,並支援滑鼠操作。
與top相比,htop有以下優點:
▪ 可以橫向或縱向捲動進程列表,以便看到所有的進程和完整的命令列。
▪ 在啟動上,比top快。
▪ 殺進程時不需要輸入進程號。
▪ htop支援滑鼠操作。
▲mpstat
#mpstat 是Multiprocessor Statistics的縮寫,是即時系統監控工具。其報告與CPU的一些統計信息,這些信息存放在/proc/stat文件中。在多CPUs系統裡,其不但能查看所有CPU的平均狀況信息,而且能夠查看特定CPU的信息。常見用法:mpstat –P ALL interval times。
▲netstat
Netstat用於顯示與IP、TCP、UDP和ICMP協定相關的統計數據,一般用於檢驗本機各連接埠的網路連線情況。
▲常見用法:
#netstat –npl 可以查看你要開啟的連接埠是否已經開啟。
netstat –rn 列印路由表資訊。
netstat –in 提供系統上的介面訊息,列印每個介面的MTU,輸入分組數,輸入錯誤,輸出分組數,輸出錯誤,衝突以及目前的輸出佇列的長度。
▲#ps--顯示目前行程的狀態
ps參數太多,因此使用方法可以參考man ps,常用的方法:ps aux #hsserver;ps –ef |grep #hundsun
# #▪ 殺掉某程式的方法:ps aux | grep mysqld | grep –v grep | awk '{print $2 }' xargs kill -9
#▪ 殺掉殭屍行程: ps –eal | awk '{if ($2 == “Z”){print $4}}' | xargs kill -9
▲strace
######追蹤程式執行過程中產生的系統呼叫及接收到的訊號,幫助分析程式或指令執行中遇到的異常情況。
範例:查看mysqld在linux上載入哪種設定文件,可以透過執行下面的指令:strace –e stat64 mysqld –print –defaults > /dev/null
▲uptime
能夠列印系統總共運作了多長時間和系統的平均負載,uptime指令最後輸出的三個數字的意義分別是1分鐘,5分鐘,15分鐘內系統的平均負荷。
▲lsof
lsof(list open files)是一個列出目前系統開啟檔案的工具。透過lsof工具能夠查看這個清單對系統偵測及排錯,常見的用法:
查看檔案系統阻塞 lsof /boot
##查看連接埠號碼被哪個進程佔用 lsof -i : 3306#
查看使用者開啟哪些檔案 lsof –u username
#檢視程式開啟哪些檔案 lsof –p 4838
#檢視遠端已開啟的網路連結 lsof –i @192.168.34.128
▲#perf
perf是Linux kernel自帶的系統效能最佳化工具。優點在於與Linux Kernel的緊密結合,它可以最先應用到加入Kernel的new feature,用於查看熱點函數,查看cashe miss的比率,從而幫助開發者來優化程式效能。
效能調校工具如perf,Oprofile 等的基本原理都是對被監控物件進行取樣,最簡單的情形是根據tick 中斷進行採樣,即在tick 中斷內觸發採樣點,在採樣點裡判斷程式當時的上下文。假如一個程式 90% 的時間都花費在函數 foo() 上,那麼 90% 的取樣點都應該落在函數 foo() 的上下文中。運氣不可捉摸,但我想只要取樣頻率夠高,取樣時間夠長,那麼以上推論就比較可靠。因此,透過 tick 觸發採樣,我們便可以了解程式中哪些地方最耗時間,從而重點分析。
想要更深的了解本工具可以參考:
http://blog.csdn .net/trochiluses/article/details/10261339
總結:結合以上常用的效能測試指令並聯絡文初的效能分析工具的圖,就可以初步了解到效能分析過程中哪個面向的效能使用哪方面的工具(命令)。
【常用的效能測試工具】
熟練且精通了第二部分的效能分析指令工具,引入幾個效能測試的工具,介紹之前先簡單了解幾個效能測試工具:
#▪ perf_events: 一款隨Linux核心程式碼一同發布和維護的效能診斷工具,由核心社群維護發展。 Perf 不僅可以用於應用程式的效能統計分析,還可以應用於核心程式碼的效能統計和分析。
更多參考:http://blog.sina.com.cn/s/blog_98822316010122ex.html。
▪ eBPF tools: 一款使用bcc進行的效能追蹤的工具,eBPF map可以使用客製化的eBPF程序被廣泛應用於核心調優方面,也可以讀取用戶級的非同步程式碼。重要的是這個外部的資料可以在使用者空間管理。這個k-v格式的map資料體是透過在使用者空間呼叫bpf系統呼叫來建立、新增、刪除等操作來管理的。 more: http://blog.csdn.net/ljy1988123/article/details/50444693。
▪ perf-tools: 一款基於 perf_events (perf) 和 ftrace 的Linux效能分析調優工具集。 Perf-Tools 依賴函式庫少,使用簡單。支援Linux 3.2 及以上核心版本。 more: https://github.com/brendangregg/perf-tools。
▪ bcc(BPF Compiler Collection): 一款使用eBPF的perf效能分析工具。一個用於創建高效的核心追蹤和操作程序的工具包,包括幾個有用的工具和範例。利用擴展的BPF(伯克利資料包過濾器),正式稱為eBPF,一個新的功能,首先被添加到Linux 3.15。多用途需要Linux 4.1以上BCC。
更多參考:https://github.com/iovisor/bcc#tools。
▪ ktap: 一種新型的linux腳本動態效能追蹤工具。允許用戶追蹤Linux核心動態。 ktap是設計給具有互通性,允許使用者調整操作的見解,排除故障和延長核心和應用程式。它類似於Linux和Solaris DTrace SystemTap。更多參考:https://github.com/ktap/ktap。
▪ Flame Graphs:是一款使用perf,system tap,ktap視覺化的圖形軟體,允許最頻繁的程式碼路徑快速且準確地識別,可以是使用github.com/brendangregg/flamegraph中的開發原始程式碼的程式產生。
更多參考:http://www.brendangregg.com/flamegraphs.html。
一、 Linux observability tools | Linux 效能觀測工具
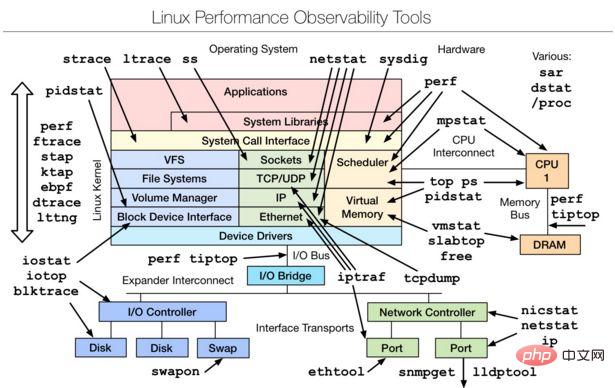
▪ 先學習的Basic Tool有如下:
uptime、top(htop)、mpstat、isstat、vmstat、free 、ping、nicstat、dstat。
▪ 高階的指令如下:
sar、netstat、pidstat、strace、 tcpdump、blktrace、iotop、slabtop、sysctl、/proc。
更多參考:http://www.open-open.com/lib/view/open1434589043973.html,詳細的指令使用方法可以參考man
二、Linux benchmarking tools | Linux 效能評估工具
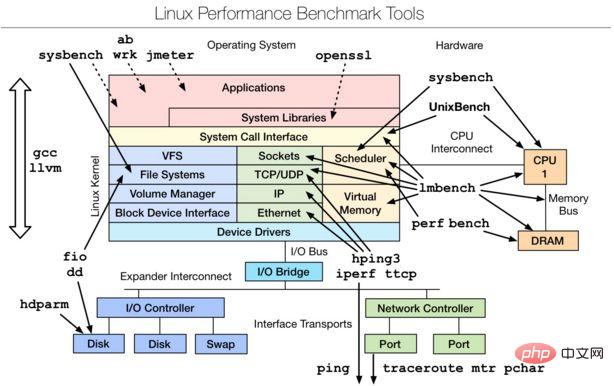
##是一款效能評估工具,對於不同模組的效能測試可以使用對應的工具,想要深入了解,可以參考最下文的附件文件。
三、Linux tuning tools | Linux 效能調優工具
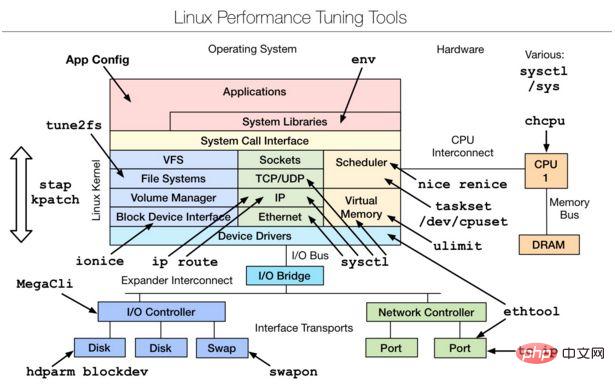
是一款效能調優工具,主要是從linux核心原始碼層進行的調優,想要深入了解,可以參考下文附件文件。
四、Linux observability sar | linux效能觀測工具
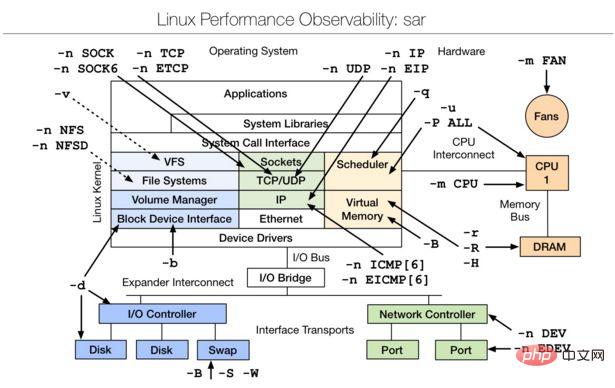
##sar(System Activity Reporter系統活動狀況報告)是目前LINUX上最為全面的系統效能分析工具之一,可以從多方面對系統的活動進行報告,包括:檔案的讀寫情況、系統呼叫的使用情況、磁碟I/O、 CPU效率、記憶體使用狀況、進程活動及IPC相關的活動等面向。
sar的常歸使用方式:sar [options] [-A] [-o file] t [n]
其中:
t為取樣間隔,n為取樣次數,預設值為1;
-o file表示將指令結果以二進位格式存放在檔案中,file 是檔案名稱。
options 為命令列選項
以上が超包括的なコレクション - Linux パフォーマンス分析ツールの概要コレクションの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7491
7491
 15
1377
52
77
11
19
41
15
1377
52
77
11
19
41

 rootとしてmysqlにログインできません
Apr 08, 2025 pm 04:54 PM
rootとしてmysqlにログインできません
Apr 08, 2025 pm 04:54 PM
ルートとしてMySQLにログインできない主な理由は、許可の問題、構成ファイルエラー、一貫性のないパスワード、ソケットファイルの問題、またはファイアウォール傍受です。解決策には、構成ファイルのBind-Addressパラメーターが正しく構成されているかどうかを確認します。ルートユーザー許可が変更されているか削除されてリセットされているかを確認します。ケースや特殊文字を含むパスワードが正確であることを確認します。ソケットファイルの許可設定とパスを確認します。ファイアウォールがMySQLサーバーへの接続をブロックすることを確認します。
 c言語条件付き編集:初心者向けの詳細なガイドへの実践的なアプリケーション
Apr 04, 2025 am 10:48 AM
c言語条件付き編集:初心者向けの詳細なガイドへの実践的なアプリケーション
Apr 04, 2025 am 10:48 AM
c言語条件付きコンパイルは、コンパイル時間条件に基づいてコードブロックを選択的にコンパイルするメカニズムです。導入方法には、#IFおよび#ELSEディレクティブを使用して、条件に基づいてコードブロックを選択します。一般的に使用される条件付き式には、STDC、_WIN32、Linuxが含まれます。実用的なケース:オペレーティングシステムに従って異なるメッセージを印刷します。システムの数字数に応じて異なるデータ型を使用します。コンパイラに応じて、異なるヘッダーファイルがサポートされています。条件付きコンパイルにより、コードの移植性と柔軟性が向上し、コンパイラ、オペレーティングシステム、CPUアーキテクチャの変更に適応できます。
 Linuxの5つの基本コンポーネントは何ですか?
Apr 06, 2025 am 12:05 AM
Linuxの5つの基本コンポーネントは何ですか?
Apr 06, 2025 am 12:05 AM
Linuxの5つの基本コンポーネントは次のとおりです。1。カーネル、ハードウェアリソースの管理。 2。機能とサービスを提供するシステムライブラリ。 3.シェル、ユーザーがシステムと対話するインターフェイス。 4.ファイルシステム、データの保存と整理。 5。アプリケーション、システムリソースを使用して機能を実装します。
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 MySQLはAndroidで実行できますか
Apr 08, 2025 pm 05:03 PM
MySQLはAndroidで実行できますか
Apr 08, 2025 pm 05:03 PM
MySQLはAndroidで直接実行できませんが、次の方法を使用して間接的に実装できます。Androidシステムに構築されたLightWeight Database SQLiteを使用して、別のサーバーを必要とせず、モバイルデバイスアプリケーションに非常に適したリソース使用量が少ない。 MySQLサーバーにリモートで接続し、データの読み取りと書き込みのためにネットワークを介してリモートサーバー上のMySQLデータベースに接続しますが、強力なネットワーク依存関係、セキュリティの問題、サーバーコストなどの短所があります。
 特定のシステムバージョンでMySQLが報告したエラーのソリューション
Apr 08, 2025 am 11:54 AM
特定のシステムバージョンでMySQLが報告したエラーのソリューション
Apr 08, 2025 am 11:54 AM
MySQLのインストールエラーのソリューションは次のとおりです。1。システム環境を慎重に確認して、MySQL依存関係ライブラリの要件が満たされていることを確認します。異なるオペレーティングシステムとバージョンの要件は異なります。 2.エラーメッセージを慎重に読み取り、依存関係のインストールやSUDOコマンドの使用など、プロンプト(ライブラリファイルの欠落やアクセス許可など)に従って対応する測定値を取得します。 3.必要に応じて、ソースコードをインストールし、コンパイルログを慎重に確認してみてください。これには、一定量のLinuxの知識と経験が必要です。最終的に問題を解決する鍵は、システム環境とエラー情報を慎重に確認し、公式の文書を参照することです。
 MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLのインストール障害の主な理由は次のとおりです。1。許可の問題、管理者として実行するか、SUDOコマンドを使用する必要があります。 2。依存関係が欠落しており、関連する開発パッケージをインストールする必要があります。 3.ポート競合では、ポート3306を占めるプログラムを閉じるか、構成ファイルを変更する必要があります。 4.インストールパッケージが破損しているため、整合性をダウンロードして検証する必要があります。 5.環境変数は誤って構成されており、環境変数はオペレーティングシステムに従って正しく構成する必要があります。これらの問題を解決し、各ステップを慎重に確認して、MySQLを正常にインストールします。
 ターミナルからMySQLにアクセスできません
Apr 08, 2025 pm 04:57 PM
ターミナルからMySQLにアクセスできません
Apr 08, 2025 pm 04:57 PM
端末からmysqlにアクセスできない場合は、次の理由があります。MySQLサービスが実行されていません。接続コマンドエラー;許可が不十分です。ファイアウォールは接続をブロックします。 mysql構成ファイルエラー。
