

Linux のメモリ メカニズムとスワップ、バッファ、キャッシュの手動解放
#この記事では、Linux のメモリ機構、仮想メモリのスワップ、バッファ/キャッシュの解放などの原理と実際の操作を紹介します。 1. Linux のメモリの仕組みは何ですか? 2. Linux が仮想メモリ (スワップ) を使い始めたのはいつですか? 3. メモリを解放するにはどうすればよいですか? 4. スワップを解除するにはどうすればよいですか?
1. Linux のメモリの仕組みは何ですか?
物理メモリから直接データを読み書きする方が、ハードディスクからデータを読み書きするよりもはるかに高速であることがわかっています。それはメモリ内で完了し、メモリには限界があるため、物理メモリと仮想メモリの概念が生まれます。 物理メモリは、システム ハードウェアによって提供されるメモリ サイズです。それは実メモリです。物理メモリと比較して、Linux では仮想メモリの概念があります。仮想メモリは、物理メモリの不足を満たすために提案された戦略です。メモリ。ディスク領域を使用して仮想化された論理メモリです。仮想メモリとして使用されるディスク領域はスワップ領域と呼ばれます。 Linux では、物理メモリの拡張として、物理メモリが不足した場合に、スワップ パーティションの仮想メモリを使用します。具体的には、カーネルは、一時的に使用されていないメモリ ブロック情報をスワップ領域に書き込みます。これにより、物理メモリが解放され、このメモリを他の目的に使用できるようになり、元のコンテンツが必要になったときに、情報がスワップ領域から物理メモリに再度読み取られます。 Linux のメモリ管理は、ページング アクセス メカニズムを採用しています。物理メモリを最大限に活用できるようにするため、カーネルは、物理メモリ内の使用頻度の低いデータ ブロックを、適切なタイミングで自動的に仮想メモリにスワップします。使用された情報を物理メモリに保存します。Linux のメモリ操作メカニズムを深く理解するには、次の側面を理解する必要があります。
Linux システムは、可能な限り多くの空き物理メモリを維持するために、時々ページ スワップ操作を実行します。何かがメモリを必要とする場合でも、Linux は一時的に未使用のメモリ ページをスワップアウトします。これにより、交換までの待ち時間を回避できます。
Linux ページ スワッピングは条件付きです。使用されていないときにすべてのページが仮想メモリにスワップされるわけではありません。Linux カーネルは、「最近使用された」アルゴリズムに基づいて、使用頻度の低い一部のページ ファイルのみを仮想メモリにスワップします。メモリ、 Linux には依然として大量の物理メモリがありますが、大量のスワップ領域も使用されているという現象が時々見られます。実際、これは驚くことではありません。たとえば、大量のメモリを消費するプロセスの実行時に多くのメモリ リソースを消費する必要がある場合、一部の珍しいページ ファイルが仮想メモリにスワップされますが、後でこのプロセスが使用されることになります。大量のメモリ リソースが仮想メモリにスワップされます。プロセスが終了して大量のメモリが解放されても、スワップアウトされたばかりのページ ファイルは物理メモリに自動的にスワップされません。これが必要でない限り、システムの物理メモリはこの時点でメモリはかなり空き、スワップ領域も使用されているため、上記のような現象が発生します。何が起こっているかを知っている限り、現時点では心配する必要はありません。
スワップ領域内のページは、使用されるときに最初に物理メモリにスワップされます。この時点でこれらのページを収容するのに十分な物理メモリがない場合は、すぐにスワップアウトされます。このようにして、仮想メモリがない可能性があります。これらのスワップ ページを保存するのに十分なスペースがあれば、最終的に Linux の誤ったクラッシュやサービス異常などの問題が発生します。Linux は一定期間内に自動的に回復できますが、回復されたシステムは基本的に使用できなくなります。
したがって、Linux メモリの使用を適切に計画および設計することが非常に重要です。
Linux オペレーティング システムでは、アプリケーションがファイル内のデータを読み取る必要がある場合、最初にオペレーティング システムが実行されます。メモリを割り当て、ディスクからこれらのメモリにデータを読み取り、そのデータをアプリケーションに配布します。ファイルにデータを書き込む必要がある場合、オペレーティング システムはまずユーザー データを受信するためにメモリを割り当て、次にデータを書き込みます。メモリからディスクまで優れています。ただし、ディスクからメモリへの読み取り、またはメモリからディスクへの書き込みが必要なデータが大量にある場合、システムの読み取りおよび書き込みパフォーマンスは非常に低くなります。ディスクへの書き込みやディスクへのデータの書き込みは、非常に長いプロセスであり、時間とリソースを消費するプロセスです。この場合、Linux はバッファとキャッシュ メカニズムを導入しました。
バッファとキャッシュは両方ともメモリ操作であり、システムによって開かれたファイルとファイル属性情報を保存するために使用されます。このようにして、オペレーティング システムが特定のファイルを読み取る必要がある場合、まずバッファとキャッシュ内を検索します。メモリ領域が見つかった場合は、直接読み出してアプリケーションに送信します。必要なデータが見つからない場合は、ディスクから読み取られます。これがオペレーティング システムのキャッシュ メカニズムです。キャッシュを通じて、オペレーティング システムのパフォーマンスが向上します。システムが大幅に改善されました。ただし、バッファとキャッシュされたバッファの内容は異なります。
Buffers はブロック デバイスのバッファーに使用されます。これはファイル システムのメタデータと実行中のページの追跡のみを記録しますが、cached はファイルのバッファーに使用されます。より簡単に言うと、バッファは主にディレクトリの内容、ファイルの属性、アクセス許可などを保存するために使用されます。そして、キャッシュは、開いたファイルやプログラムを記憶するために直接使用されます。
私たちの結論が正しいかどうかを検証するには、vi を使用して非常に大きなファイルを開いてキャッシュ内の変更を確認し、そのファイルをもう一度 vi して、2 つの速度の類似点と相違点を確認します。初めてですか? 2 回目の開く速度は 1 回目よりも大幅に速くなりますか?次に、コマンド
find / -name .conf を実行してバッファーの値が変化するかどうかを確認し、find コマンドを繰り返し実行して 2 回の表示速度の違いを確認します。
2. Linux はいつから仮想メモリ (スワップ) を使い始めましたか?
[root@wenwen ~]# cat /proc/sys/vm/swappiness 60
上記の 60 は、物理メモリの 40% が使用されている場合にのみスワップが使用されることを意味します (ネットワーク情報を参照: 残りの物理メモリが使用されている場合) 40% (40 =100-60) 未満、スワップ領域の使用を開始) swappiness=0 の場合は、物理メモリを最大限に使用してからスワップ領域を使用することを意味し、swappiness=100 の場合は、スワップ領域を積極的に使用することを意味します。スワップパーティションを作成し、メモリ上のデータをタイムリーに転送し、スワップ領域に移動します。
値が大きいほど、スワップが使用される可能性が高くなります。 0 に設定できます。これはスワップの使用を禁止しませんが、スワップを使用する可能性を最小限に抑えるだけです。
通常情况下:swap分区设置建议是内存的两倍 (内存小于等于4G时),如果内存大于4G,swap只要比内存大就行。另外尽量的将swappiness调低,这样系统的性能会更好。
B.修改swappiness参数
临时性修改: [root@wenwen ~]# sysctl vm.swappiness=10 vm.swappiness = 10 [root@wenwen ~]# cat /proc/sys/vm/swappiness 10
永久性修改:
[root@wenwen ~]# vim /etc/sysctl.conf 加入参数: vm.swappiness = 35 然后在直接: [root@wenwen ~]# sysctl -p /etc/sysctl.conf 查看是否生效: cat /proc/sys/vm/swappiness 35
立即生效,重启也可以生效。
三、怎么释放内存?
一般系统是不会自动释放内存的关键的配置文件/proc/sys/vm/drop_caches。这个文件中记录了缓存释放的参数,默认值为0,也就是不释放缓存。他的值可以为0~3之间的任意数字,代表着不同的含义:
0 – 不释放1 – 释放页缓存2 – 释放dentries和inodes3 – 释放所有缓存
实操:

很明显多出来很多空闲的内存了吧
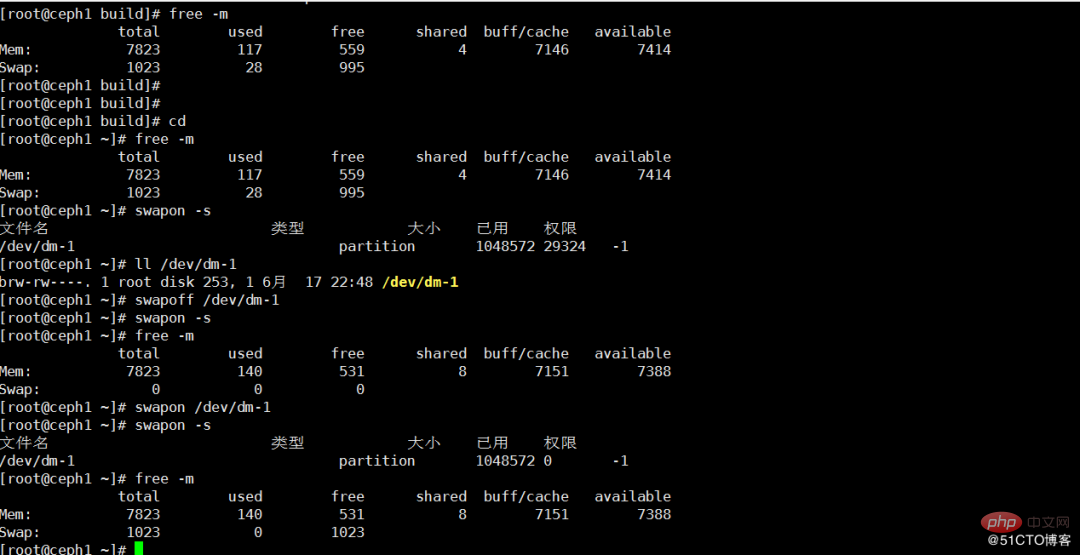
4. スワップを解放するにはどうすればよいですか?
前提: まず、残りのメモリがスワップ使用量以上であることを確認してください。そうでないとクラッシュします。メモリのメカニズムによれば、スワップ パーティションが解放されると、スワップ パーティションに格納されているすべてのファイルが物理メモリに転送されます。スワップの解放は通常、スワップ パーティションを再マウントすることによって行われます。
a. 現在のスワップ パーティションがどこにマウントされているか確認しますか? b. このパーティションをシャットダウンします c. ステータスを確認します: d. スワップ パーティションがシャットダウンされているかどうかを確認します。一番下の行にすべてが表示されます。 e. スワップを /dev/sda5 にマウントします f. マウントが成功したかどうかを確認します
以上がLinux のメモリ メカニズムとスワップ、バッファ、キャッシュの手動解放の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7526
7526
 15
1378
52
81
11
21
74
15
1378
52
81
11
21
74

 CentosとUbuntuの違い
Apr 14, 2025 pm 09:09 PM
CentosとUbuntuの違い
Apr 14, 2025 pm 09:09 PM
Centosとubuntuの重要な違いは次のとおりです。起源(CentosはRed Hat、for Enterprises、UbuntuはDebianに由来します。個人用のDebianに由来します)、パッケージ管理(CentosはYumを使用し、安定性に焦点を当てます。チュートリアルとドキュメント)、使用(Centosはサーバーに偏っています。Ubuntuはサーバーやデスクトップに適しています)、その他の違いにはインストールのシンプルさが含まれます(Centos is Thin)
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centosはメンテナンスを停止します2024
Apr 14, 2025 pm 08:39 PM
Centosはメンテナンスを停止します2024
Apr 14, 2025 pm 08:39 PM
Centosは、上流の分布であるRhel 8が閉鎖されたため、2024年に閉鎖されます。このシャットダウンはCentos 8システムに影響を与え、更新を継続し続けることができません。ユーザーは移行を計画する必要があり、提案されたオプションには、Centos Stream、Almalinux、およびRocky Linuxが含まれ、システムを安全で安定させます。
 Dockerデスクトップの使用方法
Apr 15, 2025 am 11:45 AM
Dockerデスクトップの使用方法
Apr 15, 2025 am 11:45 AM
Dockerデスクトップの使用方法は? Dockerデスクトップは、ローカルマシンでDockerコンテナを実行するためのツールです。使用する手順には次のものがあります。1。Dockerデスクトップをインストールします。 2。Dockerデスクトップを開始します。 3。Docker Imageを作成します(DockerFileを使用); 4. Docker画像をビルド(Docker Buildを使用); 5。Dockerコンテナを実行します(Docker Runを使用)。
 Centosをインストールする方法
Apr 14, 2025 pm 09:03 PM
Centosをインストールする方法
Apr 14, 2025 pm 09:03 PM
Centosのインストール手順:ISO画像をダウンロードし、起動可能なメディアを燃やします。起動してインストールソースを選択します。言語とキーボードのレイアウトを選択します。ネットワークを構成します。ハードディスクをパーティション化します。システムクロックを設定します。ルートユーザーを作成します。ソフトウェアパッケージを選択します。インストールを開始します。インストールが完了した後、ハードディスクから再起動して起動します。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 セントスにハードディスクをマウントする方法
Apr 14, 2025 pm 08:15 PM
セントスにハードディスクをマウントする方法
Apr 14, 2025 pm 08:15 PM
CentOSハードディスクマウントは、次の手順に分割されます。ハードディスクデバイス名(/dev/sdx)を決定します。マウントポイントを作成します( /mnt /newdiskを使用することをお勧めします);マウントコマンド(Mount /dev /sdx1 /mnt /newdisk)を実行します。 /etc /fstabファイルを編集して、永続的なマウント構成を追加します。 Umountコマンドを使用して、デバイスをアンインストールして、プロセスがデバイスを使用しないことを確認します。
 Centosがメンテナンスを停止した後の対処方法
Apr 14, 2025 pm 08:48 PM
Centosがメンテナンスを停止した後の対処方法
Apr 14, 2025 pm 08:48 PM
CentOSが停止した後、ユーザーは次の手段を採用して対処できます。Almalinux、Rocky Linux、Centosストリームなどの互換性のある分布を選択します。商業分布に移行する:Red Hat Enterprise Linux、Oracle Linuxなど。 Centos 9ストリームへのアップグレード:ローリングディストリビューション、最新のテクノロジーを提供します。 Ubuntu、Debianなど、他のLinuxディストリビューションを選択します。コンテナ、仮想マシン、クラウドプラットフォームなどの他のオプションを評価します。
