

Redis 研究ノート - 文字列の原則
String は Redis の最も基本的なデータ型です。すべてのキーが文字列型であるだけでなく、他のいくつかのデータ型で構成される要素も文字列型です。文字列。文字列の長さは 512M を超えることができないことに注意してください。
まず、512Mを超えてはいけないと誰が定めたのでしょうか?あるいは、なぜ 512M を超えないのでしょうか?
// 源码定义(检查字符串长度)
static int checkStringLength(redisClient *c, long long size) {
if (size > 512*1024*1024) {
addReplyError(c,"string exceeds maximum allowed size (512MB)");
return REDIS_ERR;
}
return REDIS_OK;
}ソース コード チェックによって修正され、512 M を超えることはできません。
redis 文字列構造を見てみましょう:
struct sdshdr{
// 记录 buf 数组中已使用字节的数量
// 等于 SDS 所保存字符串的长度
int len;
// 记录 buf 数组中未使用字节的数量
int free;
// 字节数组,用于保存字符串
char buf[];
}int が 32 ビットであることが直接わかります。つまり、最大 4G文字列もサポートできますが、そうではありません。
なぜ 512 M を超えることができないのかを調べるために、公式の答えを見つけました。
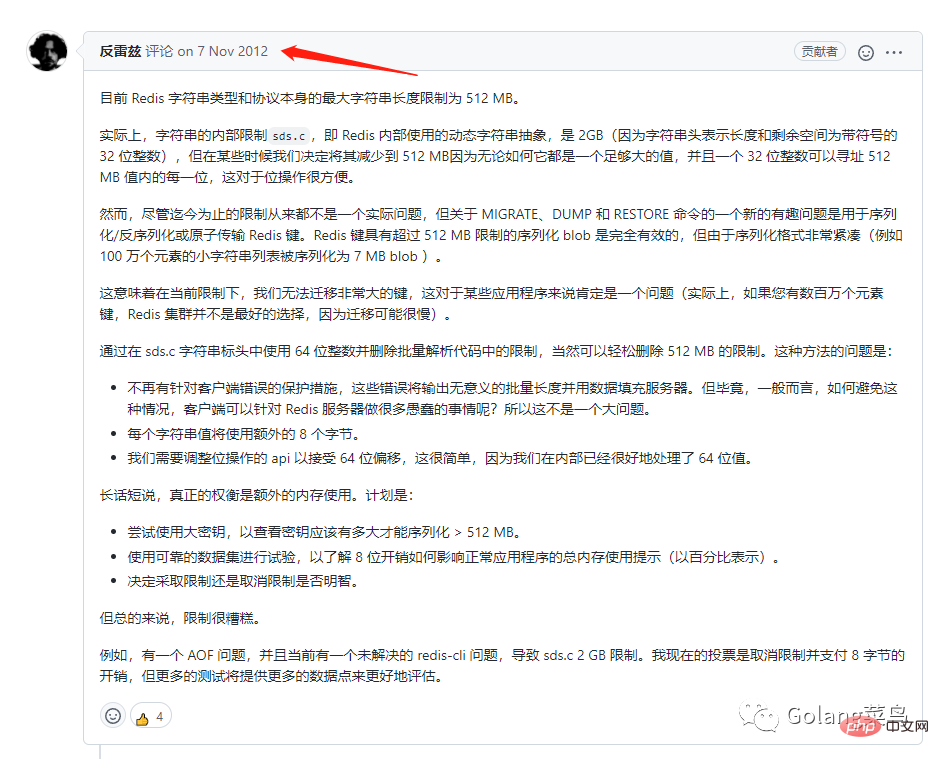
# #そして、私が読んだ Redis 情報が古いことに気づきました。
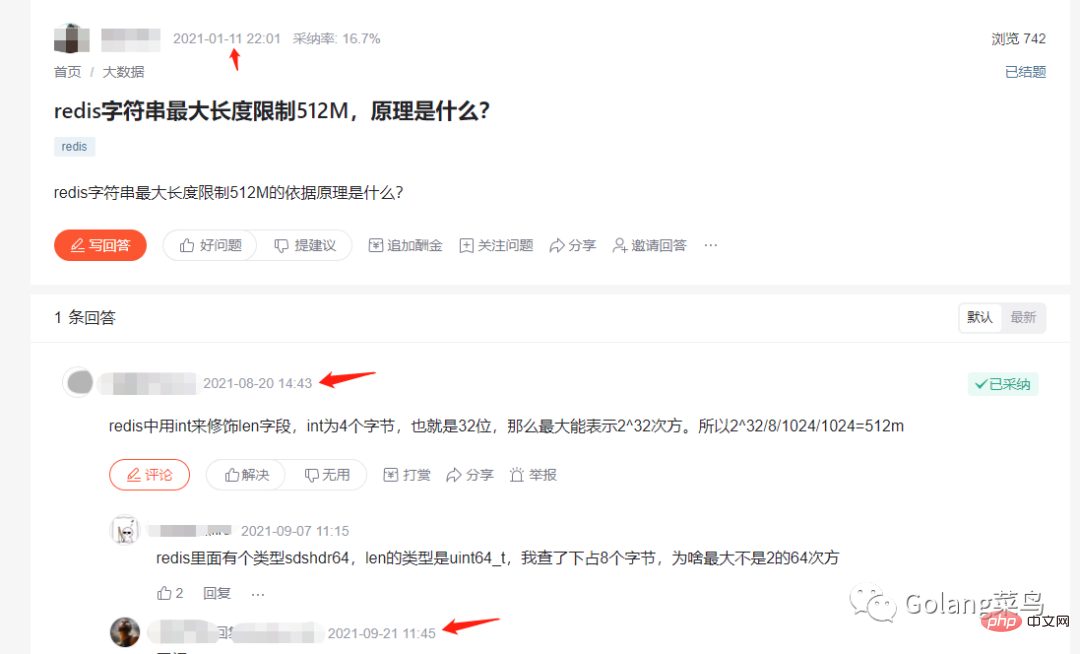
话不多说,继续学习 redis5.0 版本的资料。不过之前学习了的也没事,我们可以一起来看下 redis 的字符串是怎么优化的。
用如下结构来存储长度小于32的短字符串:
struct __attribute__((__packed__)) sdshdr5 {
unsigned char flags; /* 低3位存储类型,高5位存储长度*/
char buf[]; /* 柔性数组,存放实际内容*/
}sdshdr5 结构中,flags占1个字节,其低3位(bit)表示type,高5位(bit)表示长度,能表示的长度区间为0~31(25-1), flags后面就是字符串的内容。
而对于长度大于31的字符串,这个结构就不够用了,所以对于不同长度的字符串,有不同的处理方式:
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};可以看到,这4种结构的成员变量类似,唯一的区别是len和alloc的类型不同。
结构体中4个字段的具体含义分别如下:
1)len:表示buf中已占用字节数。
2)alloc:表示buf中已分配字节数,不同于free,记录的是为buf分配的总长度。
3)flags:标识当前结构体的类型,低3位用作标识位,高5位预留。
4) buf: 柔軟な配列、実際に文字列を格納するデータ空間。
文字列作成プロセス:
Redis は sdsnewlen 関数を通じて SDS を作成します。関数では、文字列の長さに基づいて適切な型が選択されます。対応する統計値を初期化した後、文字列の内容へのポインタが返され、文字列の長さに基づいてさまざまな型が選択されます。 。
sdshdr5 型の場合、空の文字列を作成すると、sdshdr8 にキャストされます。理由は、空文字列を作成した後、その内容が頻繁に更新されて拡張する可能性があるため、作成時に直接 sdshdr8 として作成されるためと考えられます。
文字列の結合:
sdscatsds は上位層に公開されるメソッドであり、最終的に sdscatlen を呼び出します。 SDS の展開が関係する可能性があるため、sdscatlen で sdsMakeRoomFor を呼び出して、結合された文字列 s の容量を確認します。展開が必要ない場合は s を直接返し、展開が必要な場合は展開された新しい文字列 s を返します。関数内の len やcurlen などの長さの値にはターミネータが含まれていません。スプライシングの際には、memcpy を使用して 2 つの文字列を結合し、関連する長さが指定されるため、このプロセスによりバイナリ セキュリティが確保されます。最後にターミネータを追加する必要があります。
文字列展開
sds で利用可能な残りの空き長さが新しいコンテンツ アドレンの長さより大きい場合、直接追加 柔軟な配列 buf の末尾に追加するだけで、展開は必要ありません。
SD で利用可能な残りの空き長さが、新しく追加されたコンテンツ アドレンの長さ以下である場合は、ケースバイケースで議論してください。追加後の長さが len addlen1MB の場合、新しい長さに 1MB を加えた値に従って容量が拡張されます。
#最後に、新しい長さに基づいてストレージ タイプを再選択し、スペースを割り当てます。ここで型を変更する必要がない場合は、realloc を通じてフレキシブル配列を拡張するだけです。そうでない場合は、メモリを再度開き、元の文字列の buf コンテンツを新しい場所に移動する必要があります。
#文字列には、おおよそ次の内容が含まれます。
バージョン 5.0 では、512M の文字列制限はありません。文字列の処理方法はタイプに応じて異なり、より多くのメモリを節約できます。
以上がRedis 研究ノート - 文字列の原則の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7480
7480
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
Redisはハッシュテーブルを使用してデータを保存し、文字列、リスト、ハッシュテーブル、コレクション、注文コレクションなどのデータ構造をサポートします。 Redisは、スナップショット(RDB)を介してデータを維持し、書き込み専用(AOF)メカニズムを追加します。 Redisは、マスタースレーブレプリケーションを使用して、データの可用性を向上させます。 Redisは、シングルスレッドイベントループを使用して接続とコマンドを処理して、データの原子性と一貫性を確保します。 Redisは、キーの有効期限を設定し、怠zyな削除メカニズムを使用して有効期限キーを削除します。
 Redis-Serverが見つからない場合はどうすればよいですか
Apr 10, 2025 pm 06:54 PM
Redis-Serverが見つからない場合はどうすればよいですか
Apr 10, 2025 pm 06:54 PM
Redis-Serverが見つからない問題を解決するための手順:インストールを確認して、Redisが正しくインストールされていることを確認します。環境変数Redis_hostとredis_portを設定します。 Redis Server Redis-Serverを起動します。サーバーがRedis-Cli pingを実行しているかどうかを確認します。
 Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示するには、3つの方法があります。キーコマンドを使用して、指定されたパターンに一致するすべてのキーを返します。スキャンコマンドを使用してキーを繰り返し、キーのセットを返します。情報コマンドを使用して、キーの総数を取得します。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisのバージョン番号を表示する方法
Apr 10, 2025 pm 05:57 PM
Redisのバージョン番号を表示する方法
Apr 10, 2025 pm 05:57 PM
Redisバージョン番号を表示するには、次の3つの方法を使用できます。(1)情報コマンドを入力し、(2) - versionオプションでサーバーを起動し、(3)構成ファイルを表示します。
 Redisの有効期限ポリシーを設定する方法
Apr 10, 2025 pm 10:03 PM
Redisの有効期限ポリシーを設定する方法
Apr 10, 2025 pm 10:03 PM
Redisデータの有効期間戦略には2つのタイプがあります。周期削除:期限切れのキーを削除する定期的なスキャン。これは、期限切れの時間帯-remove-countおよび期限切れの時間帯-remove-delayパラメーターを介して設定できます。怠zyな削除:キーが読み取られたり書かれたりした場合にのみ、削除の有効期限が切れたキーを確認してください。それらは、レイジーフリーレイジーエビクション、レイジーフリーレイジーエクスピア、レイジーフリーラジーユーザーのパラメーターを介して設定できます。
