

フォント アンチクロール: 一般的なアンチクロール テクノロジ。Web ページとフロント ページを組み合わせたものです。現在、多くの主流の Web サイトやアプリも、フォント クロール防止テクノロジーを使用して、独自の Web サイトや Web サイトにクロール防止対策を追加しています。アプリ。
フォントのクロール防止原則 : ページ内の特定のデータをカスタム フォントに置き換える 正しいデコード方法を使用しないと、正しいデータ コンテンツを取得できません。
次に示すように、@font-face を通じて HTML でカスタム フォントを使用します。
構文形式は次のとおりです:
@font-face{
font-family:"名字";
src:url('字体文件链接');
url('字体文件链接')format('文件类型')
}フォント ファイルは一般的に ttf 形式、eot 形式、woff 形式であり、Woff 形式のファイルは広く使用されているため、誰もが通常それらに遭遇します。すべてwoffタイプのファイルです。
woff 形式のファイルを例に挙げると、その内容はどのようなもので、データとコードを 1 対 1 に対応させるにはどのようなエンコード方式を使用しているのでしょうか。
下図に示すように、求人 Web サイトのフォント ファイルを例として、Baidu フォント コンパイラを入力してフォント ファイルを開きます。

下の図に示すように、ランダムに 1 つのフォントを開きます。
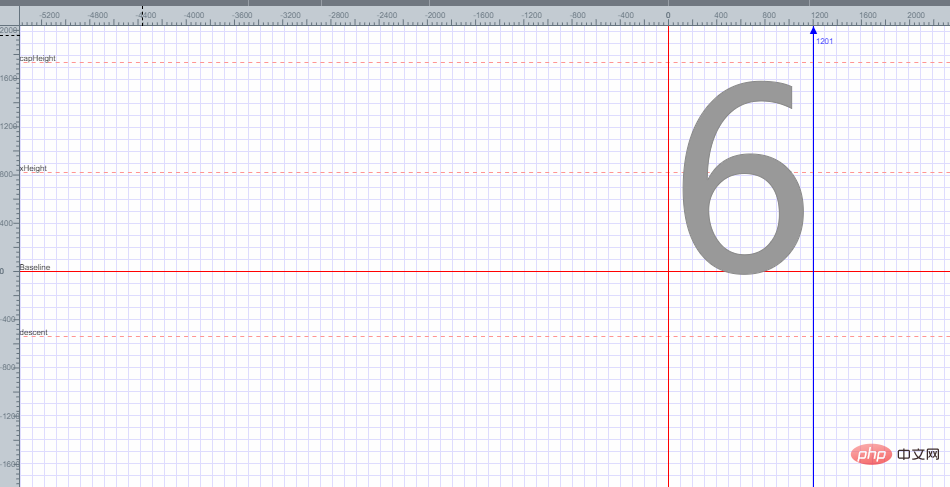
フォント 6 が平面座標に配置されており、フォント 6 のエンコーディングが以下であることがわかります。平面座標の各点に基づいて取得されるフォント6のエンコーディングを取得する方法を説明します。
フォントのアンチクライミングの問題を解決するにはどうすればよいですか?
まず、マッピング関係は辞書とみなすことができ、よく使われる方法は大きく分けて2つあります:
1つ目: コードの集合と文字の対応関係を手動で抽出する
replace_dict={
'0xf7ce':'1',
'0xf324':'2',
'0xf23e':'3',
.......
'0xfe43':'n',
}
for key in replace_dict:
数据=数据.replace(key,replace_dict[key])まずフォントに対応する辞書とそれに対応するコードを定義し、for ループでデータを 1 つずつ置き換えます。
注: この方法は主に、フォント マッピングがほとんどないデータに適しています。
2 番目のタイプ: まず Web サイトのフォント ファイルをダウンロードし、次にフォント ファイルを XML ファイルに変換し、その中にあるフォント マッピング関係のコードを見つけて、デコード関数を使用してデコードし、次に、デコードしたコードを辞書に取り込み、辞書の内容に応じてデータを一つ一つ置き換えていきます コードが長いのでここではサンプルコードを書きません この方法のコードは後ほど実戦演習で紹介します
さて、フォントのクロール対策について簡単に説明しましょう。次に、採用 Web サイトを正式にクロールします。
まず、採用 Web サイトに入り、図のように開発者モードを開きます。以下に表示:
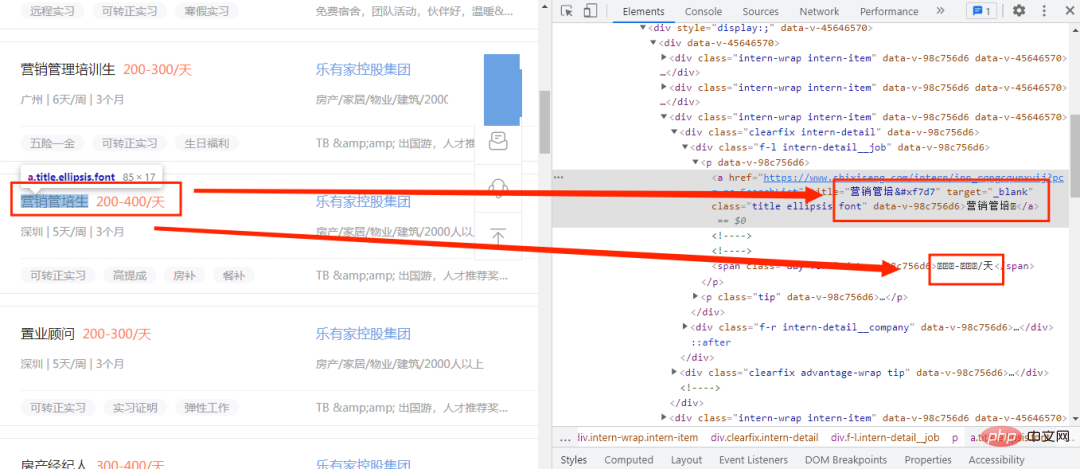
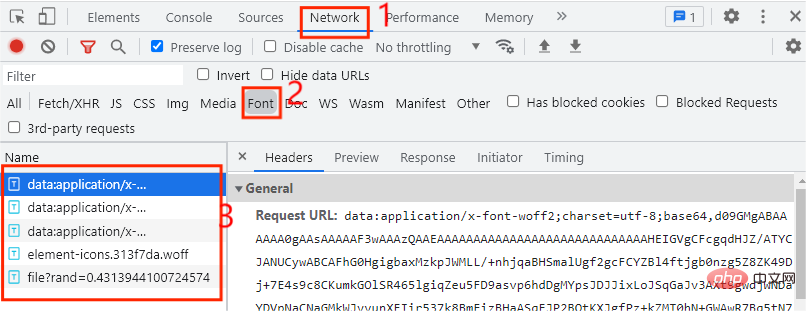
ここでは、コード内の新しい単語だけが正常に機能せず、コードに置き換えられていることがわかります。最初は、カスタム フォント ファイルが使用されていると判断されます。フォント ファイルを見つける必要がある場合、フォント ファイルはどこで見つかりますか? 次の図に示すように、まず開発者モードを開いて、[ネットワーク] オプションをクリックします。 , フォント ファイルは [フォント] タブに配置されます。ここには合計 5 つのエントリがあることがわかりました。カスタム フォント ファイルのエントリはどれですか? 次のページをクリックするたびに、カスタム フォント ファイルが表示されます。現時点では、次の図に示すように、Web ページの次のページをクリックするだけです。ファイルで始まるエントリです。この時点で、まず自作ファイルであると判断できます。フォントファイルを定義します。ダウンロードします。ダウンロード方法は非常に簡単です。エントリの URL をコピーするだけです。ファイルの先頭にあるファイルを Web ページで開きます。ダウンロード後、次の図に示すように、Baidu フォント コンパイラでファイルを開きます。 、開くことができないことがわかりました。間違ったフォント ファイルが見つかりましたか? Web サイトでは、このファイル タイプがサポートされていないというメッセージが表示されたため、ダウンロードしたファイルのサフィックスを .woff に変更しました。開いて試してください。下の図:
正常に開きます。
フォント ファイルのダウンロードと変換;

https://www.xxxxxx.com/interns/iconfonts/file?rand=0.2254193167485603 https://www.xxxxxx.com/interns/iconfonts/file?rand=0.4313944100724574 https://www.xxxxxx.com/interns/iconfonts/file?rand=0.3615862774301839
可以发现自定义字体文件的URL只有rand这个参数发生变化,而且是随机的十六位小于1的浮点数,那么我们只需要构造rand参数即可,主要代码如下所示:
def get_fontfile():
rand=round(random.uniform(0,1),17)
url=f'https://www.xxxxxx.com/interns/iconfonts/file?rand={rand}'
response=requests.get(url,headers=headers).content
with open('file.woff','wb')as f:
f.write(response)
font = TTFont('file.woff')
font.saveXML('file.xml')首先通过random.uniform()方法来控制随机数的大小,再通过round()方法控制随机数的位数,这样就可以得到rand的值,再通过.content把URL响应内容转换为二进制并写入file.woff文件中,在通过TTFont()方法获取文件内容,通过saveXML方法把内容保存为xml文件。xml文件内容如下图所示:
该字体.xml文件一共有4589行那么多,哪个部分才是字体映射关系的代码部分呢?
首先我们看回在百度字体编码器的内容,如下图所示:

汉字人对应的代码为f0e2,那么我们就在字体.xml文件中查询人的代码,如下图所示:
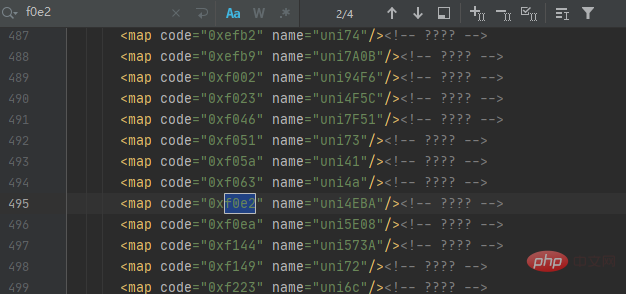
可以发现一共有4个结果,但仔细观察每个结果都相同,这时我们可以根据它们代码规律来获取映射关系,再通过解码来获取对应的数据值,最后以字典的形式展示,主要代码如下所示:
with open('file.xml') as f:
xml = f.read()
keys = re.findall('<map code="(0x.*?)" name="uni.*?"/>', xml)
values = re.findall('<map code="0x.*?" name="uni(.*?)"/>', xml)
for i in range(len(values)):
if len(values[i]) < 4:
values[i] = ('\\u00' + values[i]).encode('utf-8').decode('unicode_escape')
else:
values[i] = ('\\u' + values[i]).encode('utf-8').decode('unicode_escape')
word_dict = dict(zip(keys, values))首先读取file.xml文件内容,找出把代码中的code、name的值并分别设置为keys键,values值,再通过for循环把values的值解码为我们想要的数据,最后通过zip()方法合并为一个元组并通过dict()方法转换为字典数据,运行结果如图所示:

在上一步中,我们成功把字体映射关系转换为字典数据了,接下来开始发出网络请求来获取数据,主要代码如下所示:
def get_data(dict,url):
response=requests.get(url,headers=headers).text.replace('&#','0')
for key in dict:
response=response.replace(key,dict[key])
XPATH=parsel.Selector(response)
datas=XPATH.xpath('//*[@id="__layout"]/div/div[2]/div[2]/div[1]/div[1]/div[1]/div')
for i in datas:
data={
'workname':i.xpath('./div[1]/div[1]/p[1]/a/text()').extract_first(),
'link':i.xpath('./div[1]/div[1]/p[1]/a/@href').extract_first(),
'salary':i.xpath('./div[1]/div[1]/p[1]/span/text()').extract_first(),
'place':i.xpath('./div[1]/div[1]/p[2]/span[1]/text()').extract_first(),
'work_time':i.xpath('./div[1]/div[1]/p[2]/span[3]/text()').extract_first()+i.xpath('./div[1]/div[1]/p[2]/span[5]/text()').extract_first(),
'company_name':i.xpath('./div[1]/div[2]/p[1]/a/text()').extract_first(),
'Field_scale':i.xpath('./div[1]/div[2]/p[2]/span[1]/text()').extract_first()+i.xpath('./div[1]/div[2]/p[2]/span[3]/text()').extract_first(),
'advantage': ','.join(i.xpath('./div[2]/div[1]/span/text()').extract()),
'welfare':','.join(i.xpath('./div[2]/div[2]/span/text()').extract())
}
saving_data(list(data.values()))首先自定义方法get_data()并接收字体映射关系的字典数据,再通过for循环将字典内容与数据一一替换,最后通过xpath()来提取我们想要的数据,最后把数据传入我们自定义方法saving_data()中。
数据已经获取下来了,接下来将保存数据,主要代码如下所示:
def saving_data(data):
db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='recruit')
cursor = db.cursor()
sql = 'insert into recruit_data(work_name, link, salary, place, work_time,company_name,Field_scale,advantage,welfare) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)'
try:
cursor.execute(sql,data)
db.commit()
except:
db.rollback()
db.close()好了,程序已经写得差不多了,接下来将编写代码运行程序,主要代码如下所示:
if __name__ == '__main__':
create_db()
get_fontfile()
for i in range(1,3):
url=f'https://www.xxxxxx.com/interns?page={i}&type=intern&salary=-0&city=%E5%85%A8%E5%9B%BD'
get_data(get_dict(),url)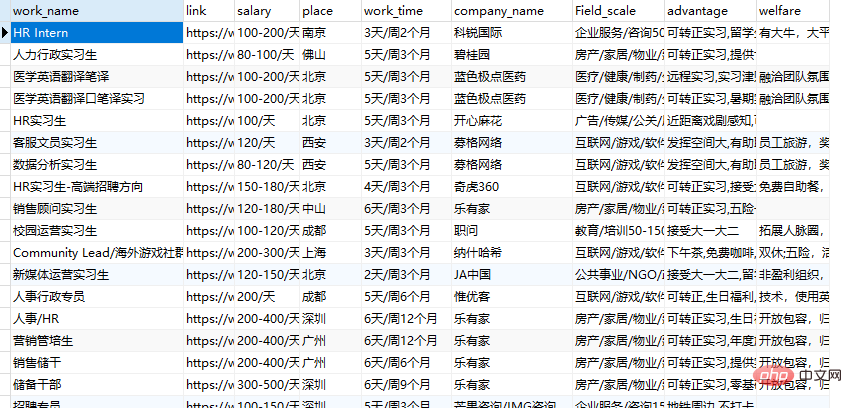
以上がJS をリバース エンジニアリングしてフォント クロールをリバースし、求人 Web サイトから情報を取得する方法を段階的に説明します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



