

Tips | Python クローラーツール Selenium 入門から上級まで

selenium について話します。これらの内容全般について話します。
selenium導入とインストールページ要素の配置 ブラウザ コントロール - #マウス コントロール
- キーボード コントロール ##要素の待機を設定
- Get
- cookies
- JavaScript
- selenium## #高度な######
selenium の紹介とインストール
selenium は、最も広く使用されているオープン ソース Web です。 UI 自動テスト スイートの 1 つで、サポートされる言語には C 、Java、Perl、PHP、 が含まれます。 Python和Ruby は、データ キャプチャの強力なツールでもあり、ほとんどの Web ページのクロール防止対策を解決できます。もちろん、万能ではありません。より明白な点の 1 つは次のとおりです。比較的遅いですが、毎日収集されるデータの量がそれほど多くない場合は、このフレームワークを使用できます。 したがって、インストールに関しては、pip を使用して
pip install selenium
を直接インストールできます。同時に、ブラウザ ドライバもインストールする必要があります。さまざまなドライバーがありますが、ここでの編集者は主に次の 2 つを推奨します
Firefoxブラウザ ドライバ:geckodriver##Chrome ブラウザ ドライバ:chromedriver
chromedriver を使用するため、ここでは Chrome を使用します。 ブラウザはchromedriver のバージョンはブラウザのバージョンと一致している必要があるので、まずブラウザのバージョンを確認しましょう。下の図を見てください。
、もちろん、コンピューターのオペレーティング システムにも対応している必要があります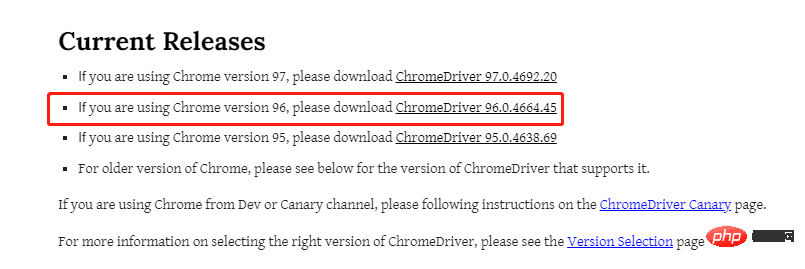
ページ要素の配置
ページ要素の配置について話すとき、編集者は、読者が次のような最も基本的なフロントエンドの知識を持っていることを前提としています。 HTML、CSS など
ID标签的定位
HTML当中,ID属性是唯一标识一个元素的属性,因此在selenium当中,通过ID来进行元素的定位也作为首选,我们以百度首页为例,搜索框的HTML代码如下,其ID为“kw”,而“百度一下”这个按钮的ID为“su”,我们用Python脚本通过ID的标签来进行元素的定位driver.find_element_by_id("kw")
driver.find_element_by_id("su")NAME标签的定位
HTML当中,Name属性和ID属性的功能基本相同,只是Name属性并不是唯一的,如果遇到没有ID标签的时候,我们可以考虑通过Name标签来进行定位,代码如下driver.find_element_by_name("wd")Xpath定位
Xpath方式来定位几乎涵盖了页面上的任意元素,那什么是Xpath呢?Xpath是一种在XML和HTML文档中查找信息的语言,当然通过Xpath路径来定位元素的时候也是分绝对路径和相对路径。/来表示,相对路径是以//来表示,而涉及到Xpath路径的编写,小编这里偷个懒,直接选择复制/粘贴的方式,例如针对下面的HTML代码<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Test</title>
</head>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
</form>
</body>
</html>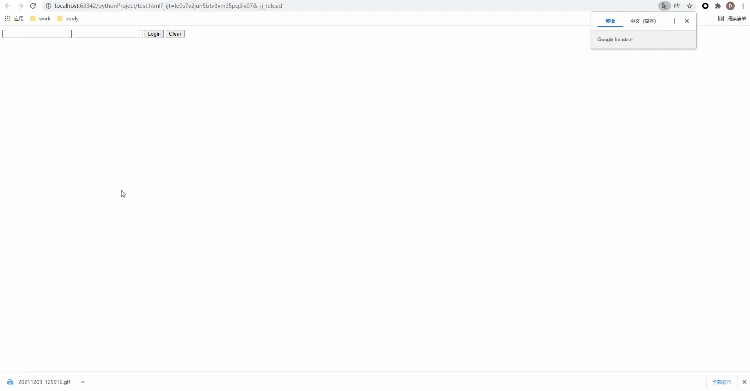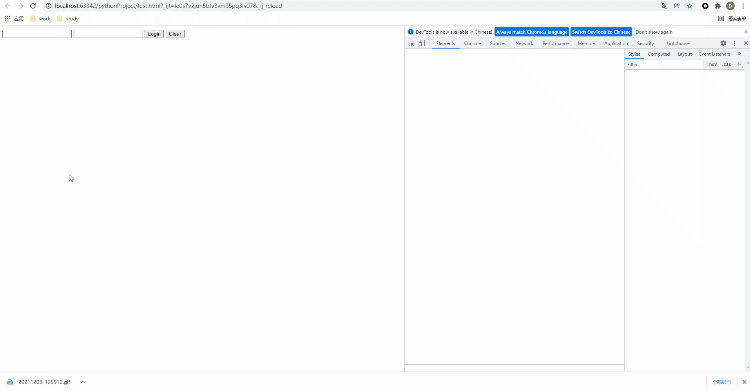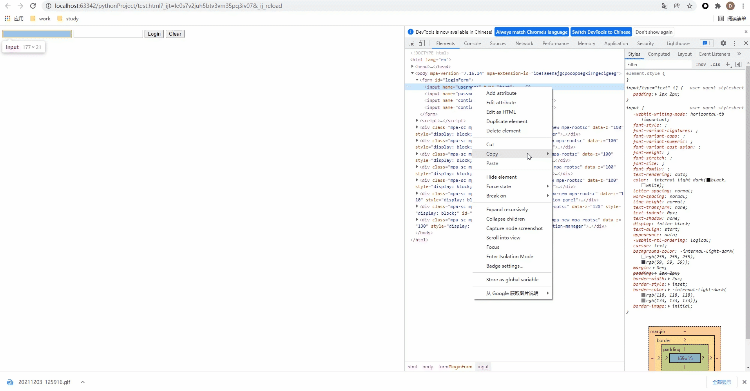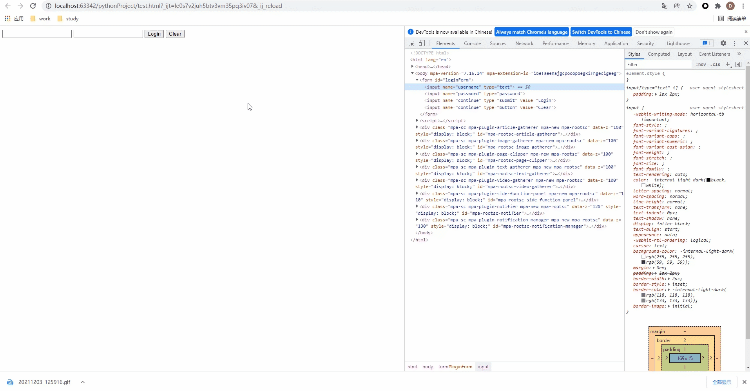
Xpath来进行页面元素的定位,代码如下driver.find_element_by_xpath('//*[@id="kw"]')
className标签定位
class属性来定位元素,尤其是当我们看到有多个并列的元素如list表单,class用的都是共用同一个,如:driver.find_element_by_class_name("classname")class属性来定位元素,该方法返回的是一个list列表,而当我们想要定位列表当中的第n个元素时,则可以这样来安排driver.find_elements_by_class_name("classname")[n]find_elements_by_class_name()方法而不是find_element_by_class_name()方法,这里我们还是通过百度首页的例子,通过className标签来定位搜索框这个元素driver.find_element_by_class_name('s_ipt')
CssSelector()方法定位
Selenium官网当中是更加推荐CssSelector()方法来进行页面元素的定位的,原因在于相比较于Xpath定位速度更快,Css定位分为四类:ID值、Class属性、TagName值等等,我们依次来看ID方式来定位
TagName的值,另外一种则是不加,代码如下driver.find_element_by_css_selector("#id_value") # 不添加前面的`TagName`值
driver.find_element_by_css_selector("tag_name.class_value") # 不添加前面的`TagName`值TagName的值非常的冗长,中间可能还有空格,那么这当中的空格就需要用点“.”来替换driver.find_element_by_css_selector("tag_name.class_value1.calss_value2.class_value3") # 不添加前面的`TagName`值我们仍然以百度首页的搜索框为例,它的HTML代码如下
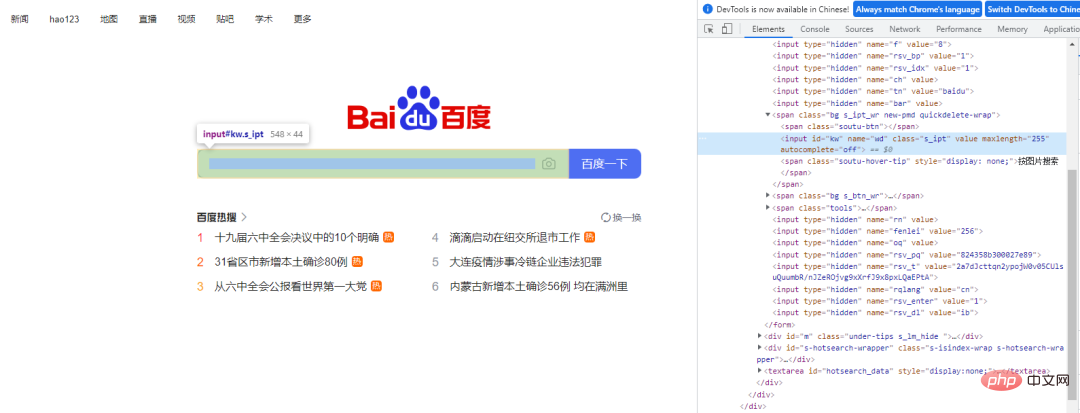
CssSelector的.class()方式来实现元素的定位的话,Python代码该这样来实现,和上面Xpath()的方法一样,可以稍微偷点懒,通过复制/粘贴的方式从开发者工具当中来获取元素的位置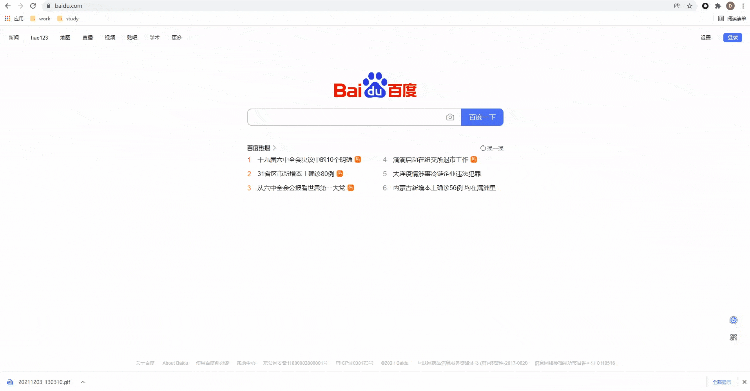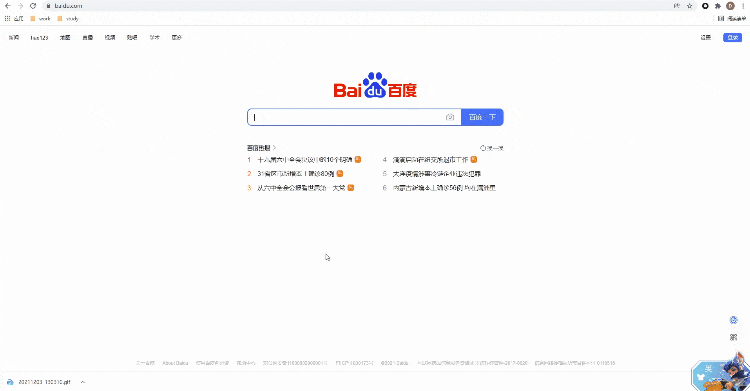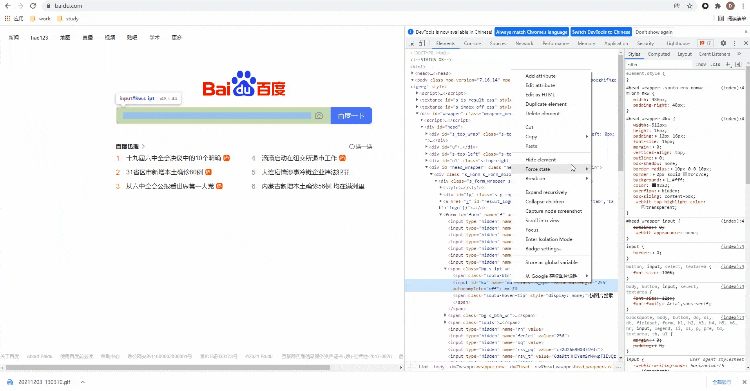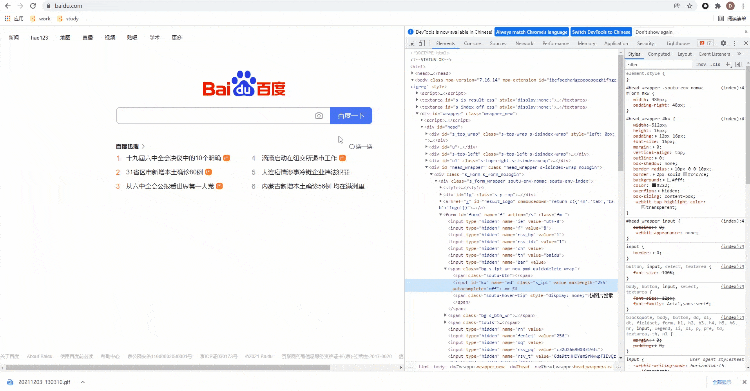
代码如下
driver.find_element_by_css_selector('#kw')
linkText()方式来定位
这个方法直接通过链接上面的文字来定位元素,案例如下
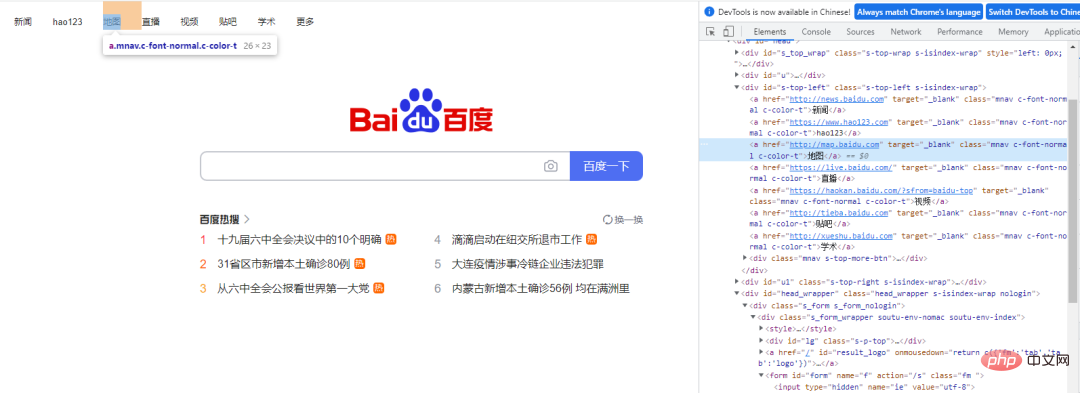
通过linkText()方法来定位“地图”这个元素,代码如下
driver.find_element_by_link_text("地图").click()浏览器的控制
修改浏览器窗口的大小
set_window_size()这个方法来修改浏览器窗口的大小,代码如下# 修改浏览器的大小 driver.set_window_size(500, 900)
同时还有maxmize_window()方法是用来实现浏览器全屏显示,代码如下
# 全屏显示 driver.maximize_window()
浏览器的前进与后退
前进与后退用到的方法分别是forward()和back(),代码如下
# 前进与后退 driver.forward() driver.back()
浏览器的刷新
刷新用到的方法是refresh(),代码如下
# 刷新页面 driver.refresh()
除了上面这些,webdriver的常见操作还有
关闭浏览器: get()清除文本: clear()单击元素: click()提交表单: submit()模拟输入内容: send_keys()
我们可以尝试着用上面提到的一些方法来写段程序
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome(executable_path="chromedriver.exe")
driver.get("https://www.baidu.com")
sleep(3)
driver.maximize_window()
sleep(1)
driver.find_element_by_xpath('//*[@id="s-top-loginbtn"]').click()
sleep(3)
driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_11__userName"]').send_keys('12121212')
sleep(1)
driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_11__password"]').send_keys('testtest')
sleep(2)
driver.refresh()
sleep(3)
driver.quit()output

鼠标的控制
鼠标的控制都是封装在ActionChains类当中,常见的有以下几种
引入action_chains类 from selenium.webdriver.common.action_chains import ActionChains # 右击 ActionChains(driver).context_click(element).perform() # 双击 ActionChains(driver).double_click(element).perform() # 拖放 ActionChains(driver).drag_and_drop(Start, End).perform() # 悬停 ActionChains(driver).move_to_element(Above).perform() # 按下 ActionChains(driver).click_and_hold(leftclick).perform() # 执行指定的操作
键盘的控制
webdriver中的Keys()类,提供了几乎所有按键的方法,常用的如下
# 删除键 driver.find_element_by_id('xxx').send_keys(Keys.BACK_SPACE) # 空格键 driver.find_element_by_id('xxx').send_keys(Keys.SPACE) # 回车键 driver.find_element_by_id('xxx').send_keys(Keys.ENTER) # Ctrl + A 全选内容 driver.find_element_by_id('xxx').send_keys(Keys.CONTROL, 'a') # Ctrl + C/V 复制/粘贴内容 driver.find_element_by_id('xxx').send_keys(Keys.CONTROL, 'c') driver.find_element_by_id('xxx').send_keys(Keys.CONTROL, 'v')
其他的一些键盘操作
向上箭头: Keys.ARROW_UP向下箭头: Keys.ARROW_DOWN向左/向右箭头: Keys.ARROW_LEFT/Keys.ARROW_RIGHTShift键: Keys.SHIFTF1键: Keys.F1
元素的等待
有显示等待和隐式等待两种
显示等待
TimeoutException),需要用到的是WebDriverWait()方法,同时配合until和not until方法WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
其中的参数:
timeout: 最长超时时间,默认以秒为单位 poll_frequency: 检测的时间间隔,默认是0.5s ignored_exceptions: 指定忽略的异常,默认忽略的有 NoSuchElementException这个异常
我们来看下面的案例
driver = webdriver.Chrome()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement")))
finally:
driver.quit()隐式等待
主要使用的是implicitly_wait()来实现
browser = webdriver.Chrome(path) # 隐式等待3秒 browser.implicitly_wait(3)
获取Cookie
Cookie是用来识别用户身份的关键,我们通常也是通过selenium先模拟登录网页获取Cookie,然后再通过requests携带Cookie来发送请求。webdriver提供了cookies的几种操作,我们挑选几个常用的来说明
get_cookies():以字典的形式返回当前会话中可见的cookie信息get_cookies(name): 返回cookie字典中指定的的cookie信息add_cookie(cookie_dict): 将cookie添加到当前会话中
下面看一个简单的示例代码
driver=webdriver.Chrome(executable_path="chromedriver.exe")
driver.get(url=url)
time.sleep(1)
cookie_list=driver.get_cookies()
cookies =";".join([item["name"] +"=" + item["value"] + "" for item in cookie_list])
session=requests.session()
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36',
'cookie': cookies
}
response=session.get(url=url,headers=headers)
soup=BeautifulSoup(response.text,'lxml')调用JavaScript
webdriver当中可以使用execut_script()方法来实现JavaScript的执行,下面我们来看一个简单的例子from selenium import webdriver
import time
bro=webdriver.Chrome(executable_path='./chromedriver')
bro.get("https://www.baidu.com")
# 执行js代码
bro.execute_script('alert(10)')
time.sleep(3)
bro.close()除此之外,我们还可以通过selenium执行JavaScript来实现屏幕上下滚动
from selenium import webdriver
bro=webdriver.Chrome(executable_path='./chromedriver')
bro.get("https://www.baidu.com")
# 执行js代码
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')selenium进阶
selenium启动的浏览器,会非常容易的被检测出来,通常可以通过window.navigator.webdriver的值来查看,如果是true则说明是使用了selenium模拟浏览器,如果是undefined则通常会被认为是正常的浏览器。window.navigator.webdriver最后返回的值driver.execute_script(
'Object.defineProperties(navigator,{webdriver:{get:()=>false}})'
)JavaScript程序已经通过读取window.navigator.webdriver知道你使用的是模拟浏览器了。所以我们有两种办法来解决这个缺陷。在Chrome当中添加实验性功能参数
代码如下
from selenium.webdriver import Chrome from selenium.webdriver import ChromeOptions option = ChromeOptions() option.add_experimental_option('excludeSwitches',['enable-automation']) driver=Chrome(options=option)
调用chrome当中的开发工具协议的命令
Chrome浏览器在打开页面,还没有运行网页自带的JavaScript代码时,先来执行我们给定的代码,通过execute_cdp_cmd()方法,driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})当然为了更好隐藏指纹特征,我们可以将上面两种方法想结合
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(options=options, executable_path='./chromedriver')
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
driver.get(url)stealth.min.js文件来实现隐藏selenium模拟浏览器的特征,这个文件之前是给puppeteer用的,使得其隐藏浏览器的指纹特征,而让Python使用时,需要先导入这份JS文件import time
from selenium.webdriver import Chrome
option = webdriver.ChromeOptions()
option.add_argument("--headless")
# 无头浏览器需要添加user-agent来隐藏特征
option.add_argument('user-agent=.....')
driver = Chrome(options=option)
driver.implicitly_wait(5)
with open('stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
driver.get(url)以上がTips | Python クローラーツール Selenium 入門から上級までの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7465
7465
 15
1376
52
77
11
18
19
15
1376
52
77
11
18
19

 PSフェザーリングは、遷移の柔らかさをどのように制御しますか?
Apr 06, 2025 pm 07:33 PM
PSフェザーリングは、遷移の柔らかさをどのように制御しますか?
Apr 06, 2025 pm 07:33 PM
羽毛の鍵は、その漸進的な性質を理解することです。 PS自体は、勾配曲線を直接制御するオプションを提供しませんが、複数の羽毛、マッチングマスク、および細かい選択により、半径と勾配の柔らかさを柔軟に調整して、自然な遷移効果を実現できます。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
MySQLには、無料のコミュニティバージョンと有料エンタープライズバージョンがあります。コミュニティバージョンは無料で使用および変更できますが、サポートは制限されており、安定性要件が低く、技術的な能力が強いアプリケーションに適しています。 Enterprise Editionは、安定した信頼性の高い高性能データベースを必要とするアプリケーションに対する包括的な商業サポートを提供し、サポートの支払いを喜んでいます。バージョンを選択する際に考慮される要因には、アプリケーションの重要性、予算編成、技術スキルが含まれます。完璧なオプションはなく、最も適切なオプションのみであり、特定の状況に応じて慎重に選択する必要があります。
 PSフェザーリングをセットアップする方法は?
Apr 06, 2025 pm 07:36 PM
PSフェザーリングをセットアップする方法は?
Apr 06, 2025 pm 07:36 PM
PSフェザーリングは、イメージエッジブラー効果であり、エッジエリアのピクセルの加重平均によって達成されます。羽の半径を設定すると、ぼやけの程度を制御でき、値が大きいほどぼやけます。半径の柔軟な調整は、画像とニーズに応じて効果を最適化できます。たとえば、キャラクターの写真を処理する際に詳細を維持するためにより小さな半径を使用し、より大きな半径を使用してアートを処理するときにかすんだ感覚を作成します。ただし、半径が大きすぎるとエッジの詳細を簡単に失う可能性があり、効果が小さすぎると明らかになりません。羽毛効果は画像解像度の影響を受け、画像の理解と効果の把握に従って調整する必要があります。
 PS Featheringは画質にどのような影響を与えますか?
Apr 06, 2025 pm 07:21 PM
PS Featheringは画質にどのような影響を与えますか?
Apr 06, 2025 pm 07:21 PM
PSフェザーリングは、画像の詳細の喪失、色の飽和の減少、およびノイズの増加につながる可能性があります。影響を減らすために、小さな羽の半径を使用し、レイヤーをコピーしてから羽毛をコピーし、羽毛の前後に画質を慎重に比較することをお勧めします。さらに、フェザーリングはすべてのケースに適しておらず、マスクなどのツールが画像エッジの処理に適している場合があります。
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 MySQLインストールエラーソリューション
Apr 08, 2025 am 10:48 AM
MySQLインストールエラーソリューション
Apr 08, 2025 am 10:48 AM
MySQLのインストールの一般的な理由とソリューションの失敗:1。誤ったユーザー名またはパスワード、またはMySQLサービスが開始されない場合、ユーザー名とパスワードを確認してサービスを開始する必要があります。 2。ポートの競合では、MySQLリスニングポートを変更するか、ポート3306を占めるプログラムを閉じる必要があります。 3.依存関係ライブラリがありません。システムパッケージマネージャーを使用して、必要な依存関係ライブラリをインストールする必要があります。 4.許可が不十分な場合、インストーラーを実行するには、sudoまたは管理者の権利を使用する必要があります。 5.誤った構成ファイルでは、構成が正しいことを確認するには、my.cnf構成ファイルを確認する必要があります。着実に慎重に作業することによってのみ、MySQLをスムーズにインストールできます。
