

4000 ワードの詳細な説明、20 の便利な Pandas 関数メソッドを推奨

あなたは知らないかもしれませんpandas 関数の多くを参照してください。しかし、これは非常に便利に使用できます。また、データ アナリストの作業効率を大幅に向上させるのにも役立ちます。また、これを読んだ後に皆さんが何かを得ることができれば幸いです
items()method##iterrows() methodinsert() メソッドassign() メソッドeval () メソッド- ##pop()
メソッド ##truncate() - メソッド
-
##add_prefix()add_suffix () - メソッド
クリップ() -
フィルター() #first() メソッドisin() メソッドdf.plot.area()- メソッド
- メソッド
##df.plot.pie()メソッド-
#items()
items()パンダのメソッドは、データを走査するために使用できます。セット内の列を取得する場合、列名と各列の内容を同時にタプルの形式で返します。例は次のとおりです。 df = pd.DataFrame({'species': ['bear', 'bear', 'marsupial'],
'population': [1864, 22000, 80000]},
index=['panda', 'polar', 'koala'])
dfログイン後にコピー species population
panda bear 1864
polar bear 22000
koala marsupial 80000
ログイン後にコピー
次に、使用します。 df = pd.DataFrame({'species': ['bear', 'bear', 'marsupial'],
'population': [1864, 22000, 80000]},
index=['panda', 'polar', 'koala'])
dfspecies population panda bear 1864 polar bear 22000 koala marsupial 80000
Methodfor label, content in df.items():
print(f'label: {label}')
print(f'content: {content}', sep='\n')
print("=" * 50)label: species content: panda bear polar bear koala marsupial Name: species, dtype: object ================================================== label: population content: panda 1864 polar 22000 koala 80000 Name: population, dtype: int64 ==================================================
iterrows()
メソッドiterrows() メソッドの機能は、トラバースすることです。データセット内の各行は、各行のインデックスと各行の内容を列名とともに返します。例は次のとおりです。for label, content in df.iterrows():
print(f'label: {label}')
print(f'content: {content}', sep='\n')
print("=" * 50)ログイン後にコピーlabel: panda
content: species bear
population 1864
Name: panda, dtype: object
==================================================
label: polar
content: species bear
population 22000
Name: polar, dtype: object
==================================================
label: koala
content: species marsupial
population 80000
Name: koala, dtype: object
==================================================
ログイン後にコピーinsert()方法
for label, content in df.iterrows():
print(f'label: {label}')
print(f'content: {content}', sep='\n')
print("=" * 50)label: panda content: species bear population 1864 Name: panda, dtype: object ================================================== label: polar content: species bear population 22000 Name: polar, dtype: object ================================================== label: koala content: species marsupial population 80000 Name: koala, dtype: object ==================================================
insert()方法insert()方法主要是用于在数据集当中的特定位置处插入数据,示例如下
df.insert(1, "size", [2000, 3000, 4000])
output
species size population panda bear 2000 1864 polar bear 3000 22000 koala marsupial 4000 80000
可见在DataFrame数据集当中,列的索引也是从0开始的
assign()方法
assign()方法可以用来在数据集当中添加新的列,示例如下
df.assign(size_1=lambda x: x.population * 9 / 5 + 32)
output
species population size_1 panda bear 1864 3387.2 polar bear 22000 39632.0 koala marsupial 80000 144032.0
lambda匿名函数,在数据集当中添加一个新的列,命名为‘size_1’,当然我们也可以通过assign()方法来创建不止一个列df.assign(size_1 = lambda x: x.population * 9 / 5 + 32,
size_2 = lambda x: x.population * 8 / 5 + 10)output
species population size_1 size_2 panda bear 1864 3387.2 2992.4 polar bear 22000 39632.0 35210.0 koala marsupial 80000 144032.0 128010.0
eval()方法
eval()方法主要是用来执行用字符串来表示的运算过程的,例如
df.eval("size_3 = size_1 + size_2")output
species population size_1 size_2 size_3 panda bear 1864 3387.2 2992.4 6379.6 polar bear 22000 39632.0 35210.0 74842.0 koala marsupial 80000 144032.0 128010.0 272042.0
当然我们也可以同时对执行多个运算过程
df = df.eval(''' size_3 = size_1 + size_2 size_4 = size_1 - size_2 ''')
output
species population size_1 size_2 size_3 size_4 panda bear 1864 3387.2 2992.4 6379.6 394.8 polar bear 22000 39632.0 35210.0 74842.0 4422.0 koala marsupial 80000 144032.0 128010.0 272042.0 16022.0
pop()方法
pop()方法主要是用来删除掉数据集中特定的某一列数据
df.pop("size_3")output
panda 6379.6 polar 74842.0 koala 272042.0 Name: size_3, dtype: float64
而原先的数据集当中就没有这个‘size_3’这一例的数据了
truncate()方法
truncate()方法主要是根据行索引来筛选指定行的数据的,示例如下
df = pd.DataFrame({'A': ['a', 'b', 'c', 'd', 'e'],
'B': ['f', 'g', 'h', 'i', 'j'],
'C': ['k', 'l', 'm', 'n', 'o']},
index=[1, 2, 3, 4, 5])output
A B C 1 a f k 2 b g l 3 c h m 4 d i n 5 e j o
我们使用truncate()方法来做一下尝试
df.truncate(before=2, after=4)
output
A B C 2 b g l 3 c h m 4 d i n
before和after存在于truncate()方法中,目的就是把行索引2之前和行索引4之后的数据排除在外,筛选出剩余的数据count()方法
count()方法主要是用来计算某一列当中非空值的个数,示例如下
df = pd.DataFrame({"Name": ["John", "Myla", "Lewis", "John", "John"],
"Age": [24., np.nan, 25, 33, 26],
"Single": [True, True, np.nan, True, False]})output
Name Age Single 0 John 24.0 True 1 Myla NaN True 2 Lewis 25.0 NaN 3 John 33.0 True 4 John 26.0 False
我们使用count()方法来计算一下数据集当中非空值的个数
df.count()
output
Name 5 Age 4 Single 4 dtype: int64
add_prefix()方法/add_suffix()方法
add_prefix()方法和add_suffix()方法分别会给列名以及行索引添加后缀和前缀,对于Series()数据集而言,前缀与后缀是添加在行索引处,而对于DataFrame()数据集而言,前缀与后缀是添加在列索引处,示例如下s = pd.Series([1, 2, 3, 4])
output
0 1 1 2 2 3 3 4 dtype: int64
我们使用add_prefix()方法与add_suffix()方法在Series()数据集上
s.add_prefix('row_')
output
row_0 1 row_1 2 row_2 3 row_3 4 dtype: int64
又例如
s.add_suffix('_row')
output
0_row 1 1_row 2 2_row 3 3_row 4 dtype: int64
DataFrame()形式数据集而言,add_prefix()方法以及add_suffix()方法是将前缀与后缀添加在列索引处的df = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [3, 4, 5, 6]})output
A B 0 1 3 1 2 4 2 3 5 3 4 6
示例如下
df.add_prefix("column_")output
column_A column_B 0 1 3 1 2 4 2 3 5 3 4 6
又例如
df.add_suffix("_column")output
A_column B_column 0 1 3 1 2 4 2 3 5 3 4 6
clip()方法
clip()方法主要是通过设置阈值来改变数据集当中的数值,当数值超过阈值的时候,就做出相应的调整data = {'col_0': [9, -3, 0, -1, 5], 'col_1': [-2, -7, 6, 8, -5]}
df = pd.DataFrame(data)output
df.clip(lower = -4, upper = 4)
output
col_0 col_1 0 4 -2 1 -3 -4 2 0 4 3 -1 4 4 4 -4
lower和upper分别代表阈值的上限与下限,数据集当中超过上限与下限的值会被替代。filter()方法
pandas当中的filter()方法是用来筛选出特定范围的数据的,示例如下
df = pd.DataFrame(np.array(([1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12])),
index=['A', 'B', 'C', 'D'],
columns=['one', 'two', 'three'])output
one two three A 1 2 3 B 4 5 6 C 7 8 9 D 10 11 12
我们使用filter()方法来筛选数据
df.filter(items=['one', 'three'])
output
one three A 1 3 B 4 6 C 7 9 D 10 12
我们还可以使用正则表达式来筛选数据
df.filter(regex='e$', axis=1)
output
one three A 1 3 B 4 6 C 7 9 D 10 12
当然通过参数axis来调整筛选行方向或者是列方向的数据
df.filter(like='B', axis=0)
output
one two three B 4 5 6
first()方法
当数据集当中的行索引是日期的时候,可以通过该方法来筛选前面几行的数据
index_1 = pd.date_range('2021-11-11', periods=5, freq='2D')
ts = pd.DataFrame({'A': [1, 2, 3, 4, 5]}, index=index_1)
tsoutput
A 2021-11-11 1 2021-11-13 2 2021-11-15 3 2021-11-17 4 2021-11-19 5
我们使用first()方法来进行一些操作,例如筛选出前面3天的数据
ts.first('3D')
output
A 2021-11-11 1 2021-11-13 2
isin()方法
isin()方法主要是用来确认数据集当中的数值是否被包含在给定的列表当中
df = pd.DataFrame(np.array(([1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12])),
index=['A', 'B', 'C', 'D'],
columns=['one', 'two', 'three'])
df.isin([3, 5, 12])output
one two three A False False True B False True False C False False False D False False True
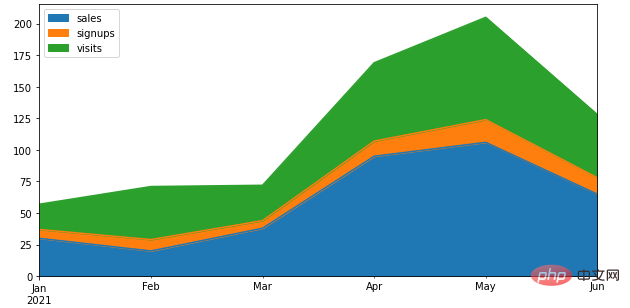
True,否则就返回Falsedf.plot.area()方法
Pandas当中通过一行代码来绘制图表,将所有的列都通过面积图的方式来绘制df = pd.DataFrame({
'sales': [30, 20, 38, 95, 106, 65],
'signups': [7, 9, 6, 12, 18, 13],
'visits': [20, 42, 28, 62, 81, 50],
}, index=pd.date_range(start='2021/01/01', end='2021/07/01', freq='M'))
ax = df.plot.area(figsize = (10, 5))output
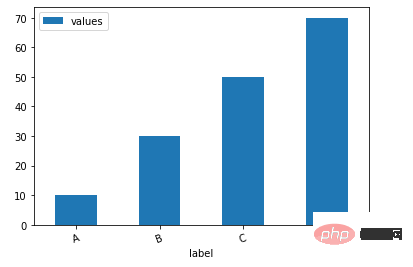
df.plot.bar()方法
下面我们看一下如何通过一行代码来绘制柱状图
df = pd.DataFrame({'label':['A', 'B', 'C', 'D'], 'values':[10, 30, 50, 70]})
ax = df.plot.bar(x='label', y='values', rot=20)output
当然我们也可以根据不同的类别来绘制柱状图
age = [0.1, 17.5, 40, 48, 52, 69, 88]
weight = [2, 8, 70, 1.5, 25, 12, 28]
index = ['A', 'B', 'C', 'D', 'E', 'F', 'G']
df = pd.DataFrame({'age': age, 'weight': weight}, index=index)
ax = df.plot.bar(rot=0)output
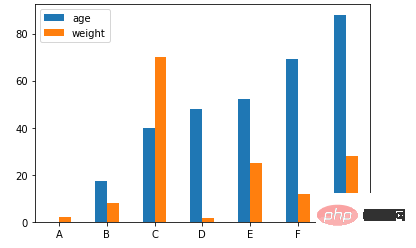
当然我们也可以横向来绘制图表
ax = df.plot.barh(rot=0)
output
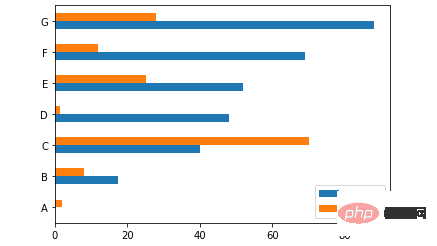
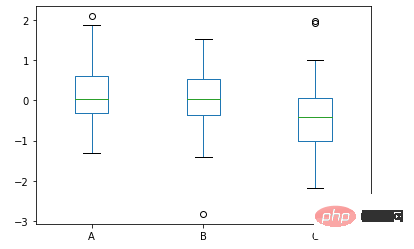
df.plot.box()方法
我们来看一下箱型图的具体的绘制,通过pandas一行代码来实现
data = np.random.randn(25, 3) df = pd.DataFrame(data, columns=list('ABC')) ax = df.plot.box()
output
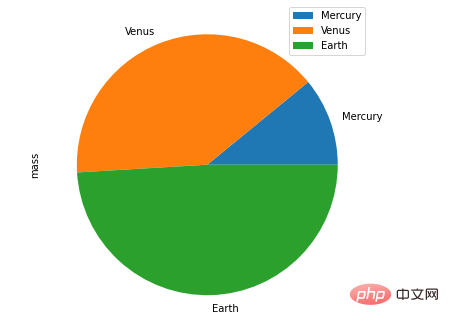
df.plot.pie()方法
接下来是饼图的绘制
df = pd.DataFrame({'mass': [1.33, 4.87 , 5.97],
'radius': [2439.7, 6051.8, 6378.1]},
index=['Mercury', 'Venus', 'Earth'])
plot = df.plot.pie(y='mass', figsize=(8, 8))output
除此之外,还有折线图、直方图、散点图等等,步骤与方式都与上述的技巧有异曲同工之妙,大家感兴趣的可以自己另外去尝试。
以上が4000 ワードの詳細な説明、20 の便利な Pandas 関数メソッドを推奨の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7404
7404
 15
1630
14
1358
52
1268
25
1218
29
15
1630
14
1358
52
1268
25
1218
29

 携帯電話でXMLをPDFに変換するとき、変換速度は高速ですか?
Apr 02, 2025 pm 10:09 PM
携帯電話でXMLをPDFに変換するとき、変換速度は高速ですか?
Apr 02, 2025 pm 10:09 PM
Mobile XMLからPDFへの速度は、次の要因に依存します。XML構造の複雑さです。モバイルハードウェア構成変換方法(ライブラリ、アルゴリズム)コードの品質最適化方法(効率的なライブラリ、アルゴリズムの最適化、キャッシュデータ、およびマルチスレッドの利用)。全体として、絶対的な答えはなく、特定の状況に従って最適化する必要があります。
 携帯電話のXMLファイルをPDFに変換する方法は?
Apr 02, 2025 pm 10:12 PM
携帯電話のXMLファイルをPDFに変換する方法は?
Apr 02, 2025 pm 10:12 PM
単一のアプリケーションで携帯電話でXMLからPDF変換を直接完了することは不可能です。クラウドサービスを使用する必要があります。クラウドサービスは、2つのステップで達成できます。1。XMLをクラウド内のPDFに変換し、2。携帯電話の変換されたPDFファイルにアクセスまたはダウンロードします。
 C言語合計の機能は何ですか?
Apr 03, 2025 pm 02:21 PM
C言語合計の機能は何ですか?
Apr 03, 2025 pm 02:21 PM
C言語に組み込みの合計機能はないため、自分で書く必要があります。合計は、配列を通過して要素を蓄積することで達成できます。ループバージョン:合計は、ループとアレイの長さを使用して計算されます。ポインターバージョン:ポインターを使用してアレイ要素を指し示し、効率的な合計が自己概要ポインターを通じて達成されます。アレイバージョンを動的に割り当てます:[アレイ]を動的に割り当ててメモリを自分で管理し、メモリの漏れを防ぐために割り当てられたメモリが解放されます。
 XMLをPDFに変換できるモバイルアプリはありますか?
Apr 02, 2025 pm 09:45 PM
XMLをPDFに変換できるモバイルアプリはありますか?
Apr 02, 2025 pm 09:45 PM
XML構造が柔軟で多様であるため、すべてのXMLファイルをPDFSに変換できるアプリはありません。 XMLのPDFへのコアは、データ構造をページレイアウトに変換することです。これには、XMLの解析とPDFの生成が必要です。一般的な方法には、ElementTreeなどのPythonライブラリを使用してXMLを解析し、ReportLabライブラリを使用してPDFを生成することが含まれます。複雑なXMLの場合、XSLT変換構造を使用する必要がある場合があります。パフォーマンスを最適化するときは、マルチスレッドまたはマルチプロセスの使用を検討し、適切なライブラリを選択します。
 XMLを写真に変換する方法
Apr 03, 2025 am 07:39 AM
XMLを写真に変換する方法
Apr 03, 2025 am 07:39 AM
XMLは、XSLTコンバーターまたは画像ライブラリを使用して画像に変換できます。 XSLTコンバーター:XSLTプロセッサとスタイルシートを使用して、XMLを画像に変換します。画像ライブラリ:PILやImageMagickなどのライブラリを使用して、形状やテキストの描画などのXMLデータから画像を作成します。
 推奨されるXMLフォーマットツール
Apr 02, 2025 pm 09:03 PM
推奨されるXMLフォーマットツール
Apr 02, 2025 pm 09:03 PM
XMLフォーマットツールは、読みやすさと理解を向上させるために、ルールに従ってコードを入力できます。ツールを選択するときは、カスタマイズ機能、特別な状況の処理、パフォーマンス、使いやすさに注意してください。一般的に使用されるツールタイプには、オンラインツール、IDEプラグイン、コマンドラインツールが含まれます。
 携帯電話でXMLを高品質でPDFに変換するにはどうすればよいですか?
Apr 02, 2025 pm 09:48 PM
携帯電話でXMLを高品質でPDFに変換するにはどうすればよいですか?
Apr 02, 2025 pm 09:48 PM
携帯電話の高品質でXMLをPDFに変換する必要があります。クラウドでXMLを解析し、サーバーレスコンピューティングプラットフォームを使用してPDFを生成します。効率的なXMLパーサーとPDF生成ライブラリを選択します。エラーを正しく処理します。携帯電話の重いタスクを避けるために、クラウドコンピューティングの能力を最大限に活用してください。複雑なXML構造の処理、マルチページPDFの生成、画像の追加など、要件に応じて複雑さを調整します。デバッグを支援するログ情報を印刷します。パフォーマンスを最適化し、効率的なパーサーとPDFライブラリを選択し、非同期プログラミングまたは前処理XMLデータを使用する場合があります。優れたコードの品質と保守性を確保します。
 Android電話でXMLをPDFに変換する方法は?
Apr 02, 2025 pm 09:51 PM
Android電話でXMLをPDFに変換する方法は?
Apr 02, 2025 pm 09:51 PM
Android電話でXMLをPDFに直接変換することは、組み込み機能を介して実現できません。次の手順を通じて国を保存する必要があります。XMLデータをPDFジェネレーター(テキストやHTMLなど)によって認識された形式に変換します。フライングソーサーなどのHTML生成ライブラリを使用して、HTMLをPDFに変換します。
