

##Unsplash は無料の高品質写真ウェブサイトです #. これらはすべて本物の写真です. 写真の解像度も非常に大きいです. デザイナーの友人に非常に適しています. 素材はイラストのコピーライターの友人にも非常に便利で、壁紙としても機能します。対応する機能コードをexeツールにカプセル化してありますので、ご参考になれば幸いです コードツールの入手方法は記事の最後に載せております
##コード:
Nature を例に挙げると、無料ダウンロード をクリックしてダウンロード パスを選択します。画像サイズは 1.43M です。
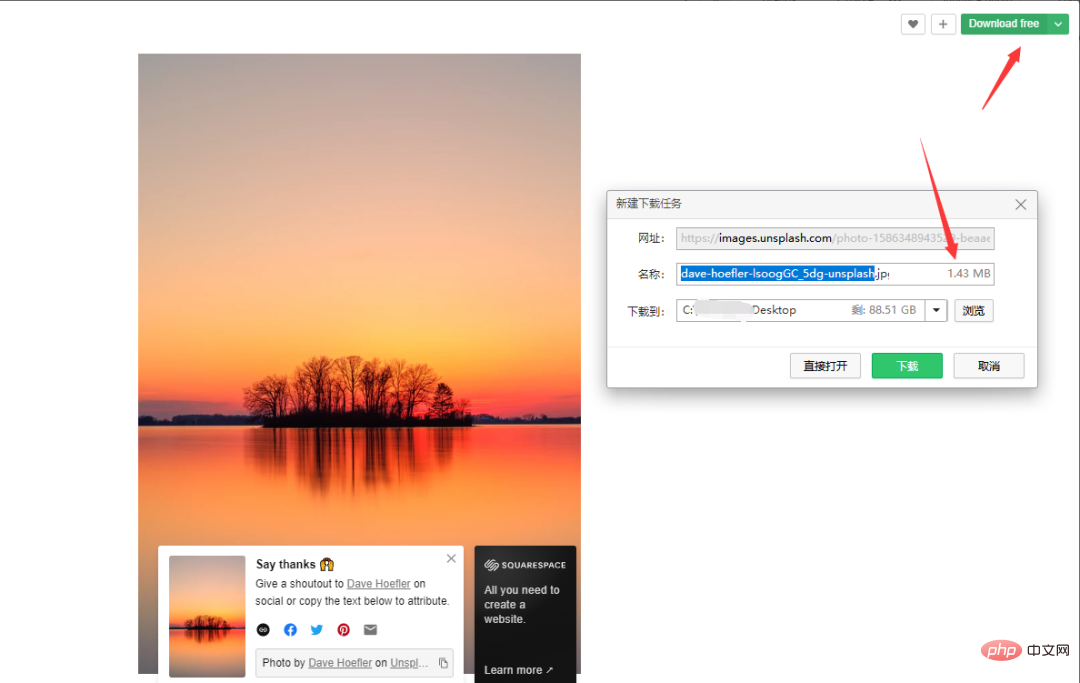 次に、
次に、いくつかの URL を見てみましょう:

上記のリンクは ページ パラメータのみです は異なります、順番に増えていくので比較的分かりやすく、リクエストする際は順番にたどっていくだけです。
#ページ番号の問題は解決しました。次に、各画像のリンクを分析します。:
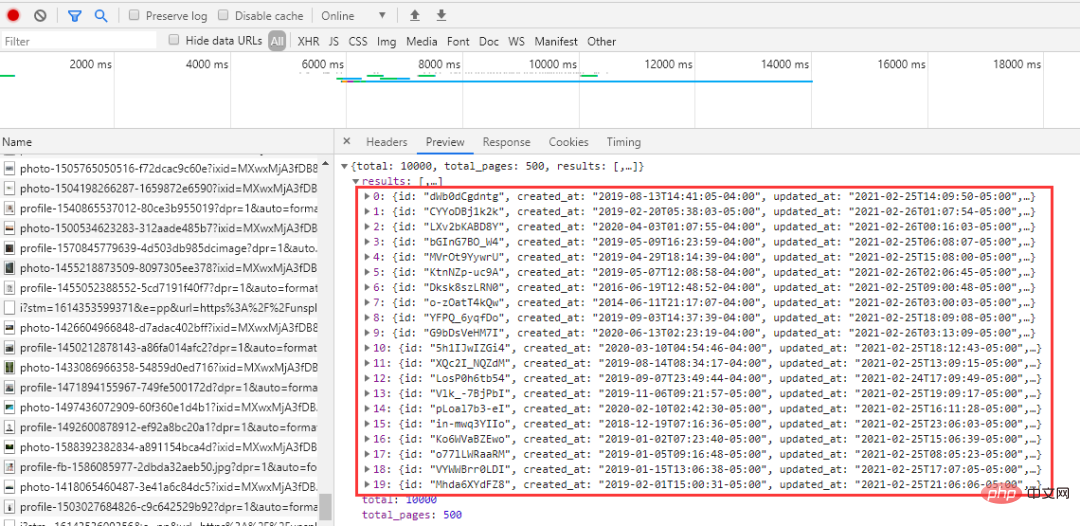
import time import random import json import requests from fake_useragent import UserAgent
fake_useragent:代理
ua = UserAgent(verify_ssl=False)
headers = {'User-Agent': ua.random}def getpicurls(i,headers):
picurls = []
url = 'https://unsplash.com/napi/search/photos?query=nature&per_page=20&page={}&xp=feedback-loop-v2%3Aexperiment'.format(i)
r = requests.get(url, headers=headers, timeout=5)
time.sleep(random.uniform(3.1, 4.5))
r.raise_for_status()
r.encoding = r.apparent_encoding
allinfo = json.loads(r.text)
results = allinfo['results']
for result in results:
href = result['urls']['full']
picurls.append(href)
return picurlsdef getpic(count,url):
r = requests.get(url, headers=headers, timeout=5)
with open('pictures/{}.jpg'.format(count), 'wb') as f:
f.write(r.content)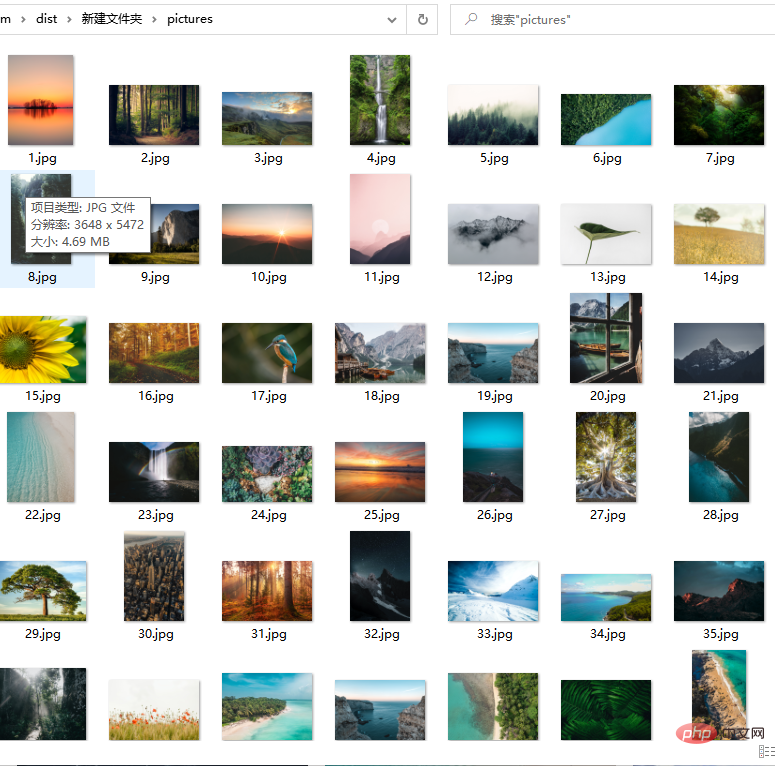
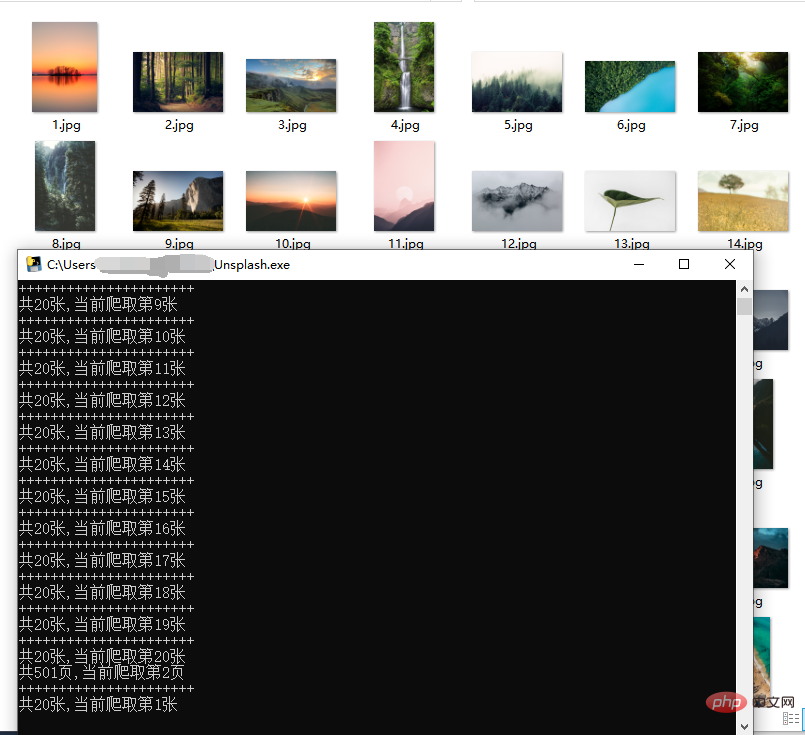
ネットワークの順序に影響を与えないように、頻繁にクロールしないようにしてください。
#画像は外部ネットワークからの高解像度画像です。クロール速度はネットワークによって異なりますが、一般的にはそれほど速くありません。
プロキシ プールを構築すると、クロールを高速化できます。
以上がクローラー | HD 壁紙のバッチダウンロード (ソースコード + ツールが含まれています)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



