

クローラー + 視覚化 | Python Zhihu ホットリスト/Weibo ホット検索シーケンス チャート (パート 1)

この問題は<Zhihuホットリスト/Weiboホット検索シーケンスチャート>一連の記事前回の記事の内容 Python を使用してナレッジ Hu ホット リストを定期的にクロールする方法を紹介します/Weibo ホット検索データを取得し、その後の視覚化のために CSV ファイルに保存します。タイミング ダイアグラムの部分は #次の記事 #コンテンツで紹介されたそれがあなたに役立つことを願っています。 read_html — Web フォーム処理 ## 注意:电脑端端直接F12调试页即可看到热榜数据,手机端需要借助抓包工具查看,这里我们使用手机端接口(返回json格式数据,解析比较方便)。 ##コード: 定时间隔设置1S: 效果: 2.3 保存数据 ##3.1 Web ページ分析 ##Weibo ホット検索 URL: https://s.weibo.com/top/summary ##データは、Web ページの ##3.2 データの取得 # 代码: 定时间隔设置1S,效果: 3.3 保存数据 结果: 以上がクローラー + 視覚化 | Python Zhihu ホットリスト/Weibo ホット検索シーケンス チャート (パート 1)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。 リアルなヌード写真を作成する AI 搭載アプリ 写真から衣服を削除するオンライン AI ツール。 脱衣画像を無料で AI衣類リムーバー AIヘンタイを無料で生成します。 使いやすく無料のコードエディター 中国語版、とても使いやすい 強力な PHP 統合開発環境 ビジュアル Web 開発ツール 神レベルのコード編集ソフト(SublimeText3) Linux Systemsに付属するPythonインタープリターを削除する問題に関して、多くのLinuxディストリビューションは、インストール時にPythonインタープリターをプリインストールし、パッケージマネージャーを使用しません... Pythonプログラミングでカスタムデコレーターを使用する場合、Pylance Type検出問題解決策デコレーターは、行を追加するために使用できる強力なツールです... Python 3.6のピクルスファイルのロードレポートエラー:modulenotFounderror:nomodulenamed ... 「DebianStrings」は標準的な用語ではなく、その特定の意味はまだ不明です。この記事は、ブラウザの互換性について直接コメントすることはできません。ただし、「DebianStrings」がDebianシステムで実行されているWebアプリケーションを指す場合、そのブラウザの互換性はアプリケーション自体の技術アーキテクチャに依存します。ほとんどの最新のWebアプリケーションは、クロスブラウザーの互換性に取り組んでいます。これは、次のWeb標準と、適切に互換性のあるフロントエンドテクノロジー(HTML、CSS、JavaScriptなど)およびバックエンドテクノロジー(PHP、Python、Node.jsなど)を使用することに依存しています。アプリケーションが複数のブラウザと互換性があることを確認するには、開発者がクロスブラウザーテストを実施し、応答性を使用する必要があることがよくあります XMLコンテンツを変更するには、ターゲットノードの正確な検出が必要であるため、プログラミングが必要です。プログラミング言語には、XMLを処理するための対応するライブラリがあり、APIを提供して、データベースの運用などの安全で効率的で制御可能な操作を実行します。 Mobile XMLからPDFへの速度は、次の要因に依存します。XML構造の複雑さです。モバイルハードウェア構成変換方法(ライブラリ、アルゴリズム)コードの品質最適化方法(効率的なライブラリ、アルゴリズムの最適化、キャッシュデータ、およびマルチスレッドの利用)。全体として、絶対的な答えはなく、特定の状況に従って最適化する必要があります。 小さなXMLファイルの場合、注釈コンテンツをテキストエディターに直接置き換えることができます。大きなファイルの場合、XMLパーサーを使用してそれを変更して、効率と精度を確保することをお勧めします。 XMLコメントを削除するときは注意してください。コメントを維持すると、通常、コードの理解とメンテナンスが役立ちます。高度なヒントは、XMLパーサーを使用してコメントを変更するためのPythonサンプルコードを提供しますが、特定の実装を使用するXMLライブラリに従って調整する必要があります。 XMLファイルを変更する際のエンコード問題に注意してください。 UTF-8エンコードを使用して、エンコード形式を指定することをお勧めします。 XMLをPDFに直接変換するアプリケーションは、2つの根本的に異なる形式であるため、見つかりません。 XMLはデータの保存に使用され、PDFはドキュメントを表示するために使用されます。変換を完了するには、PythonやReportLabなどのプログラミング言語とライブラリを使用して、XMLデータを解析してPDFドキュメントを生成できます。import json
import time
import requests
import schedule
import pandas as pd
from fake_useragent import UserAgent
https://www.zhihu.com/hot
https://api.zhihu.com/topstory/hot-list?limit=10&reverse_order=0
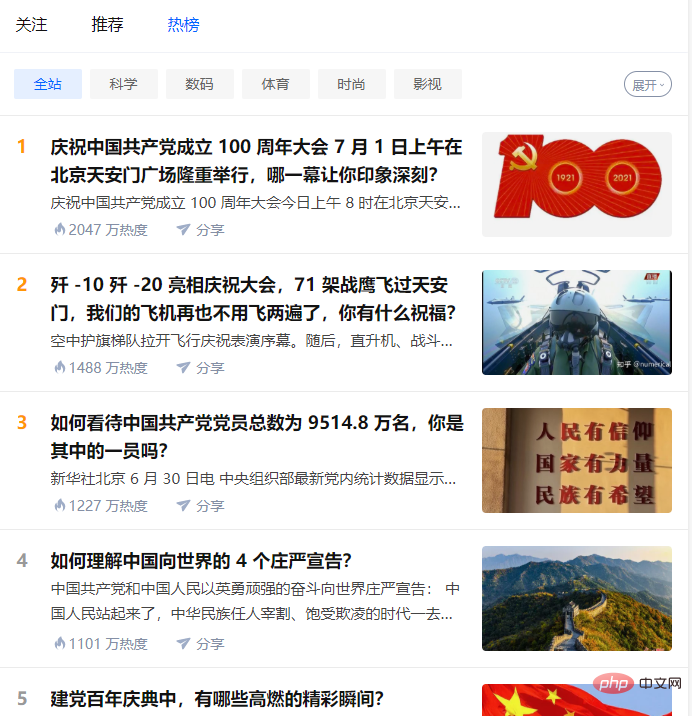
def getzhihudata(url, headers):
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
datas = json.loads(r.text)['data']
allinfo = []
time_mow = time.strftime("%Y-%m-%d %H:%M", time.localtime())
print(time_mow)
for indx,item in enumerate(datas):
title = item['target']['title']
heat = item['detail_text'].split(' ')[0]
answer_count = item['target']['answer_count']
follower_count = item['target']['follower_count']
href = item['target']['url']
info = [time_mow, indx+1, title, heat, answer_count, follower_count, href]
allinfo.append(info)
# 仅首次加表头
global csv_header
df = pd.DataFrame(allinfo,columns=['时间','排名','标题','热度(万)','回答数','关注数','链接'])
print(df.head())# 每1分钟执行一次爬取任务:
schedule.every(1).minutes.do(getzhihudata,zhihu_url,headers)
while True:
schedule.run_pending()
time.sleep(1)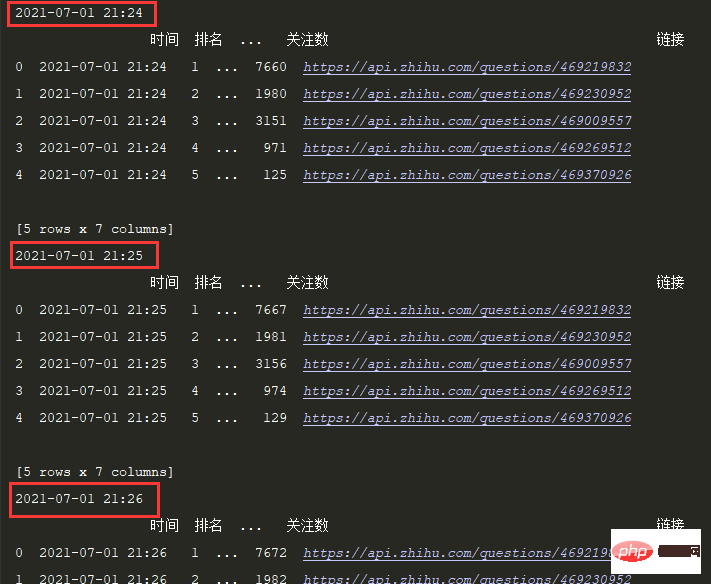
df.to_csv('zhuhu_hot_datas.csv', mode='a+', index=False, header=csv_header)
csv_header = False
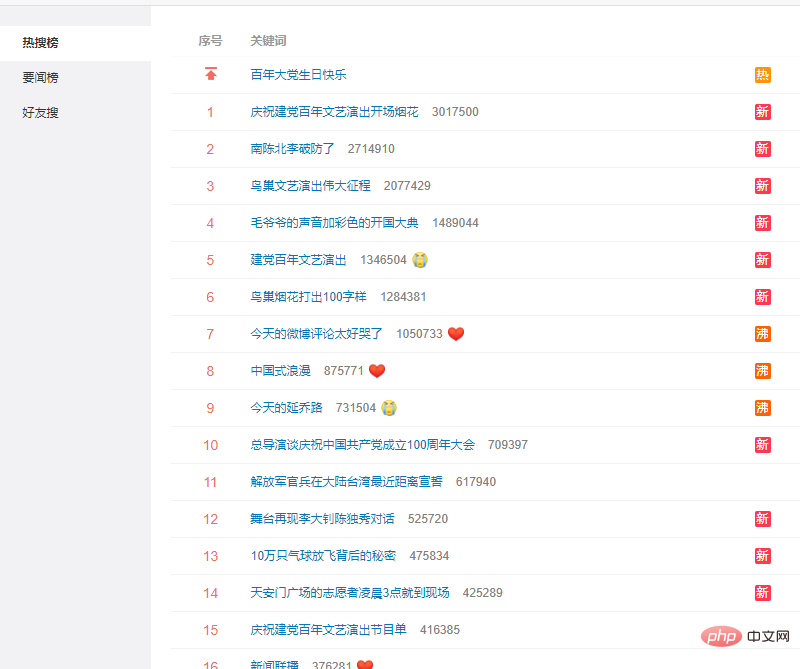
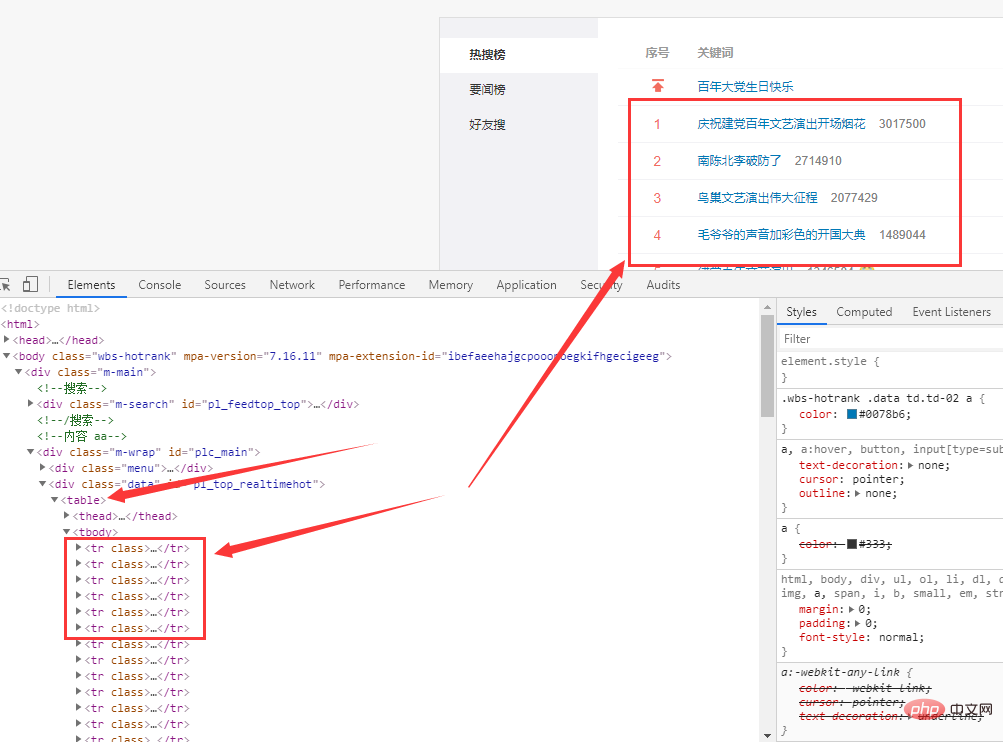
タグ にあります。
def getweibodata():
url = 'https://s.weibo.com/top/summary'
r = requests.get(url, timeout=10)
r.encoding = r.apparent_encoding
df = pd.read_html(r.text)[0]
df = df.loc[1:,['序号', '关键词']]
df = df[~df['序号'].isin(['•'])]
time_mow = time.strftime("%Y-%m-%d %H:%M", time.localtime())
print(time_mow)
df['时间'] = [time_mow] * df.shape[0]
df['排名'] = df['序号'].apply(int)
df['标题'] = df['关键词'].str.split(' ', expand=True)[0]
df['热度'] = df['关键词'].str.split(' ', expand=True)[1]
df = df[['时间','排名','标题','热度']]
print(df.head())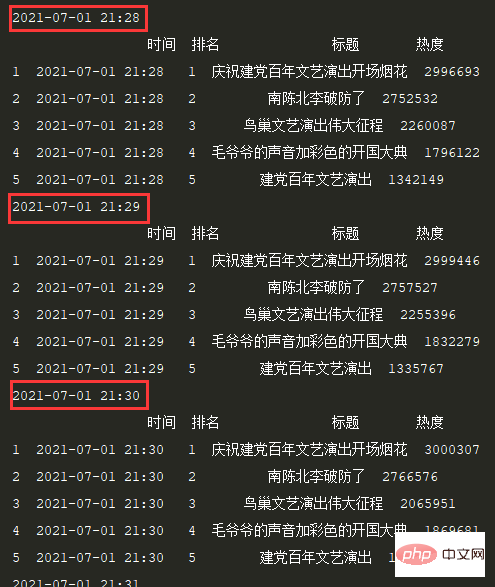
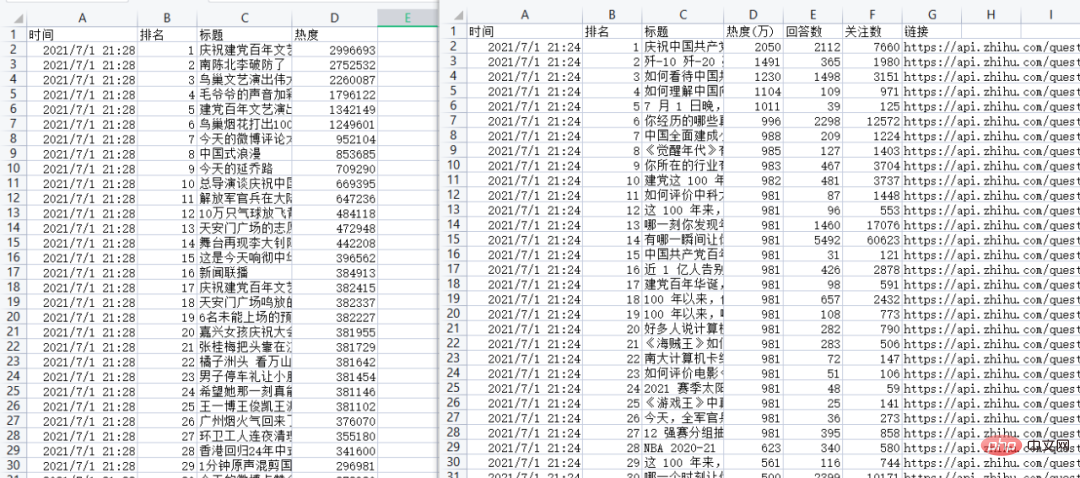
df.to_csv('weibo_hot_datas.csv', mode='a+', index=False, header=csv_header)

ホットAIツール

Undresser.AI Undress

AI Clothes Remover

Undress AI Tool

Clothoff.io

AI Hentai Generator

人気の記事
ホットツール

メモ帳++7.3.1

SublimeText3 中国語版

ゼンドスタジオ 13.0.1

ドリームウィーバー CS6

SublimeText3 Mac版
ホットトピック
 7338
7338
 9
1627
14
1352
46
1265
25
1210
29
9
1627
14
1352
46
1265
25
1210
29
 PythonインタープリターはLinuxシステムで削除できますか?
Apr 02, 2025 am 07:00 AM
PythonインタープリターはLinuxシステムで削除できますか?
Apr 02, 2025 am 07:00 AM
 Pythonでのカスタムデコレータのパイランスタイプ検出の問題を解決する方法は?
Apr 02, 2025 am 06:42 AM
Pythonでのカスタムデコレータのパイランスタイプ検出の問題を解決する方法は?
Apr 02, 2025 am 06:42 AM
 Python 3.6にピクルスファイルをロードするときに「__Builtin__」モジュールが見つからない場合はどうすればよいですか?
Apr 02, 2025 am 07:12 AM
Python 3.6にピクルスファイルをロードするときに「__Builtin__」モジュールが見つからない場合はどうすればよいですか?
Apr 02, 2025 am 07:12 AM
 Debian文字列は、複数のブラウザと互換性があります
Apr 02, 2025 am 08:30 AM
Debian文字列は、複数のブラウザと互換性があります
Apr 02, 2025 am 08:30 AM
 XMLの変更にはプログラミングが必要ですか?
Apr 02, 2025 pm 06:51 PM
XMLの変更にはプログラミングが必要ですか?
Apr 02, 2025 pm 06:51 PM
 携帯電話でXMLをPDFに変換するとき、変換速度は高速ですか?
Apr 02, 2025 pm 10:09 PM
携帯電話でXMLをPDFに変換するとき、変換速度は高速ですか?
Apr 02, 2025 pm 10:09 PM
 XMLのコメントコンテンツを変更する方法
Apr 02, 2025 pm 06:15 PM
XMLのコメントコンテンツを変更する方法
Apr 02, 2025 pm 06:15 PM
 XMLをPDFに変換できるモバイルアプリはありますか?
Apr 02, 2025 pm 08:54 PM
XMLをPDFに変換できるモバイルアプリはありますか?
Apr 02, 2025 pm 08:54 PM

