


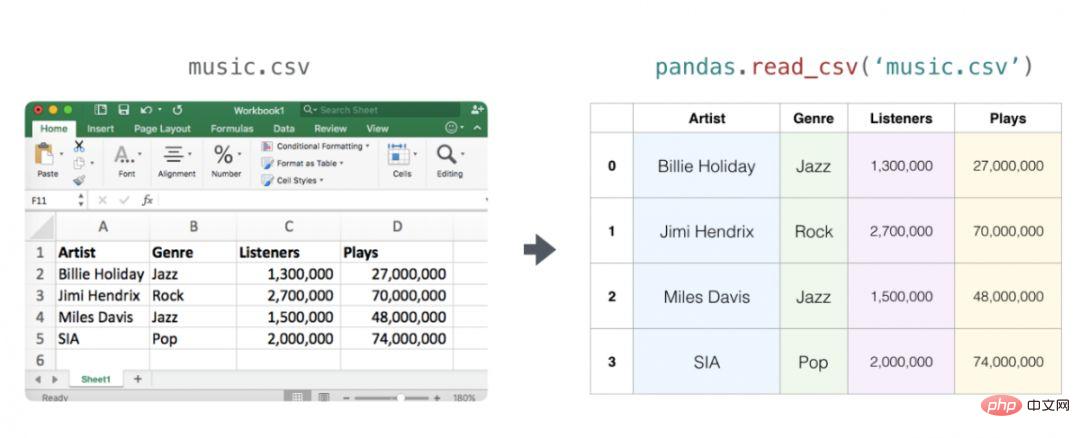
この記事では、NumPy の主な使い方を紹介します。 , そして、さまざまな種類のデータ (テーブル、画像、テキストなど) をどのように表示するか、Numpy によって処理されたこれらのデータは機械学習モデルの入力になります。
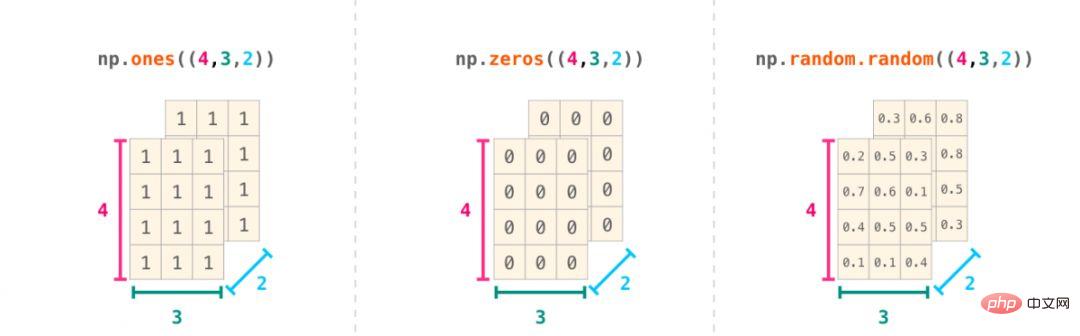
Python リストを np.array() に渡すことで、NumPy 配列 (つまり、強力な ndarray) を作成できます。次の例では、作成された配列が右側に表示されます。通常は、NumPy に配列の値を初期化してもらいます。この目的のために、NumPy は、ones()、zeros()、random.random( などの関数を提供します) ).メソッド。要素の数を渡すだけです:
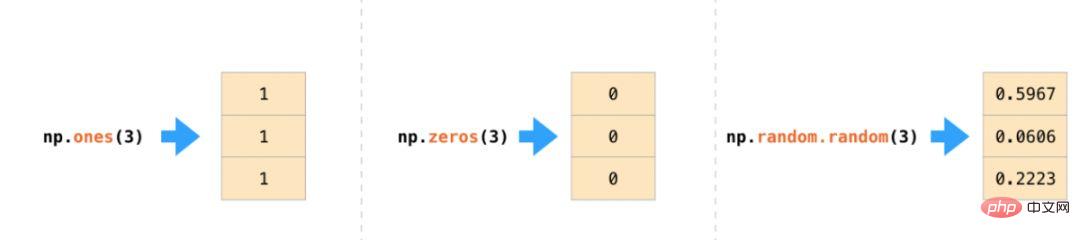 配列を作成したら、次のことができます。興味深いアプリケーションについては、以下で説明します。
配列を作成したら、次のことができます。興味深いアプリケーションについては、以下で説明します。
配列の算術演算
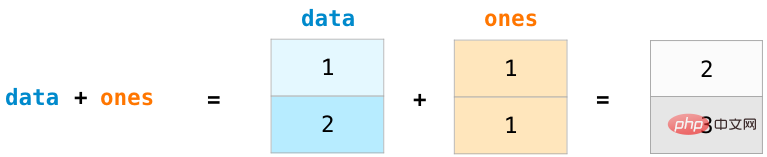
For data という名前の 2 つの NumPy 配列を作成しましょうと 1:

2 つの配列を計算するには 加算するには、次のように入力します。 data one は、対応する位置にデータを追加する (つまり、データの各行を追加する) 操作を実現でき、この操作は、配列をループして読み取るメソッド コードよりも簡潔です。
多くの場合、配列と単一の値に対して操作を実行したいと考えます (ベクトルとスカラーの間の演算とも呼ばれます)。例: 配列が距離をマイル単位で表す場合、目標はそれをキロメートルに変換することです。データを書き込むだけです * 1.6: ##NumPy は配列を渡しますブロードキャストでは、この演算には配列の各要素を乗算する必要があることが認識されています。 以下に示すように、Python のリスト操作のように NumPy 配列にインデックスを付けてスライスすることができます。 集計関数 ##NumPy がもたらす利便性は集計関数でもあり、集計関数は圧縮できます。データを取得し、配列内のいくつかの特徴値をカウントします:
np.array([[1,2],[3,4]])
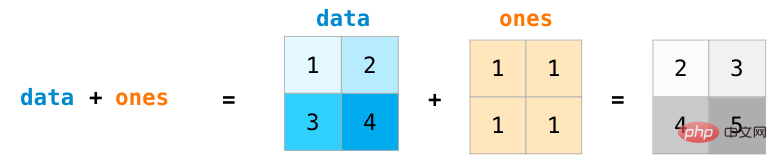
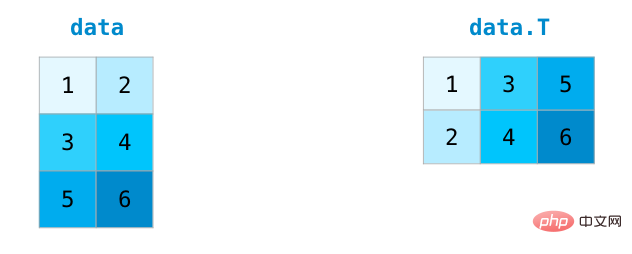
さらに、前述のones()、zeros()、random.random()を使用して行列を作成することもできます。行列の次元を記述するタプルを渡すだけです: ## 行列の算術演算 同じサイズの 2 つの行列の場合、算術演算子 (-*/) を使用して加算または乗算できます。 。 NumPy は、このタイプの操作に位置に関する操作を使用します。 サイズが異なる行列の場合、これらの算術演算は、2 つの行列の次元が 1 と同じ場合にのみ実行できます (たとえば、行列に 1 列または 1 行しかない場合)。 NumPy は、操作処理にブロードキャスト ルール (broadcast) を使用します。 は算術演算と大きな関係があります。違いは、内積を使用した行列の乗算です。 NumPy は、行列間のドット積演算を実行するために使用できる dot() メソッドを提供します。 行列の次元は、演算対象の 2 つの行列が列と行で等しくなければならないことを強調するために、上の図の下部に追加されています。この操作は次のように図式化できます: 行列のスライスと集計 行列を操作すると、インデックスとスライス関数が変更されます。より有用。データは、さまざまな次元でインデックス操作を使用してスライスできます。 #ベクトルを集計するのと同じように行列を集計できます。 #行列の転置と再構築 行列を処理する場合、多くの場合、行列の転置が必要になります。一般的な状況としては、2 つの行列のドット積を計算することが挙げられます。 NumPy 配列のプロパティ T を使用して、行列の転置を取得できます。
#上記の関数はすべて、多次元データとその中心データに適用できます。この構造は ndarray (N 次元配列) と呼ばれます。
平均二乗誤差は NumPy で簡単に実装できます:
これの利点は、numpy が予測とラベルに含まれる特定の値を考慮する必要がないことです。 DigestBacteria は、例を使用して上記のコード行の 4 つの操作をステップ実行します。 ##予測ベクトルとラベル ベクトルの両方に 3 つの値が含まれています。これは、n の値が 3 であることを意味します。減算を実行すると、次の値が得られます: これらの値を合計します:
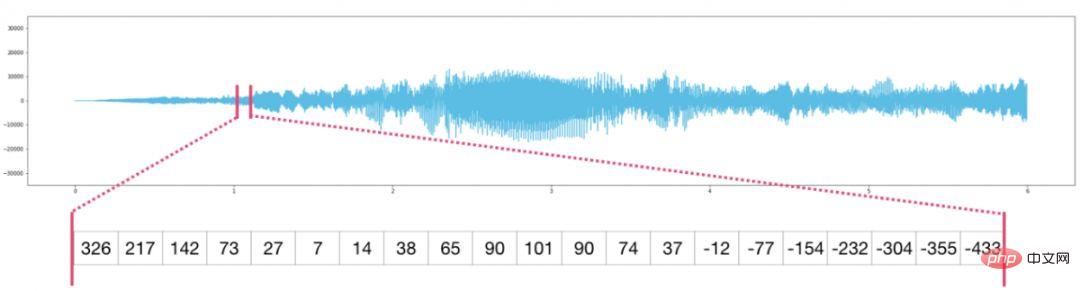
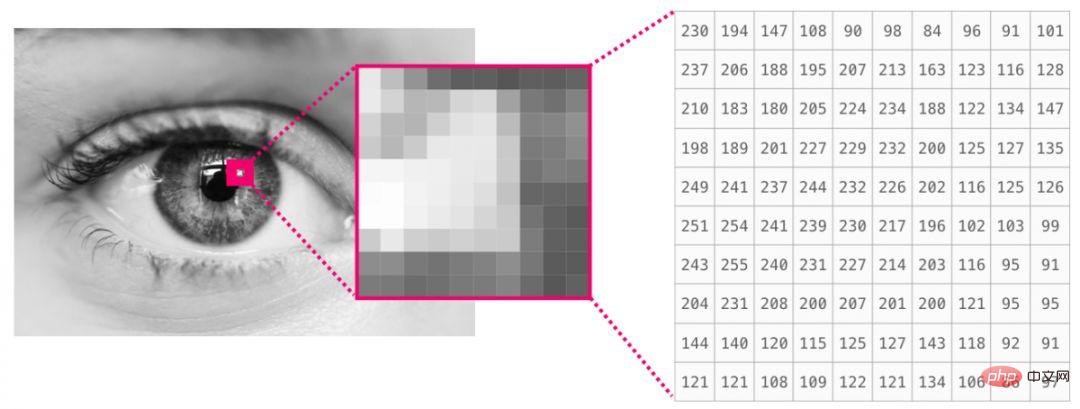
##スプレッドシートまたはデータ テーブルは 2 次元行列です。スプレッドシート内の各ワークシートを独自の変数にすることができます。 Python の同様の構造は pandas データフレームで、実際には NumPy を使用して構築されます。 ##オーディオと時系列 オーディオ ファイルはサンプルの 1 次元配列です。各サンプルは、オーディオ信号の小さなセグメントを表す数値です。 CD 品質のオーディオには 1 秒あたり 44,100 個のサンプルがあり、各サンプルは -65535 ~ 65536 の整数になります。これは、10 秒の CD 品質の WAVE ファイルがある場合、それを長さ 10 * 44,100 = 441,000 サンプルの NumPy 配列にロードできることを意味します。音声の最初の 2 秒を抽出したいですか?ファイルを audio と呼ぶ NumPy 配列にロードし、audio[:44100] をインターセプトするだけです。 次は音声ファイルです: 時系列データ (たとえば、一定期間にわたる一連の株価) にも同じことが当てはまります。 #画像
#################################言語################ ##テキストを扱う場合は状況が異なります。テキストを数値で表現するには、語彙 (モデルが知っているすべての一意の単語のリスト) を構築し、埋め込むという 2 つのステップが必要です。この(翻訳された)古代の名言を数値で表現する手順を見てみましょう。「私に先立った吟遊詩人たちは、歌われていないテーマを残していませんか?」
## ################################## その後、文を一連の「単語」トークン (共通ルールに基づいた単語または単語の部分) に分割できます。 次に、各単語を語彙の ID に置き換えます。 これらの ID は、まだモデルに貴重な情報を提供しません。したがって、一連の単語をモデルに入力する前に、トークン/単語を埋め込み (この場合は 50 次元の word2vec 埋め込みを使用) に置き換える必要があります。 # この NumPy 配列の次元は [embedding_dimension x sequence_length] であることがわかります。 実際には、これらの値は必ずしもこのように見えるわけではありませんが、視覚的な一貫性を保つためにこのように示しています。パフォーマンス上の理由から、深層学習モデルはバッチ サイズの最初の次元を保持する傾向があります (複数のサンプルを並行してトレーニングすると、モデルをより速くトレーニングできるため)。明らかに、これは reshape() を使用するのに適した場所です。たとえば、BERT のようなモデルは、入力行列の形状が [batch_size, sequence_length, embedding_size] であることを期待します。 #これは、モデルが処理してさまざまな便利な操作を実行できる数値のコレクションです。モデルのトレーニング (または予測) のために追加の例を入力できるように、多くの行を空白のままにしました。 





##


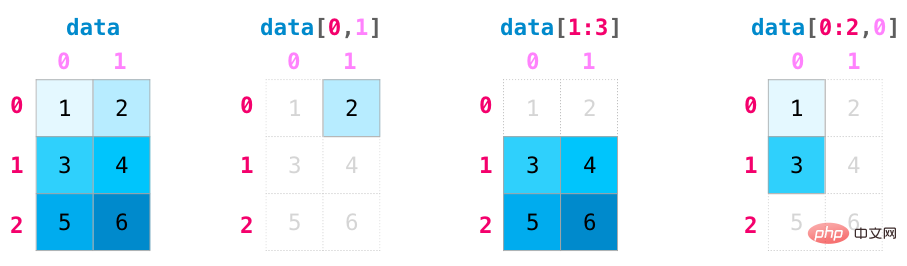


#より複雑な使用例では、変更が必要になる場合があります。マトリックスの次元。これは機械学習アプリケーションでは一般的です。たとえば、モデルの入力行列の形状がデータセットと異なる場合は、NumPy の reshape() メソッドを使用できます。マトリックスに必要な新しい次元を渡すだけです。 -1 を渡すこともでき、NumPy は行列に基づいて正しい次元を推測できます: 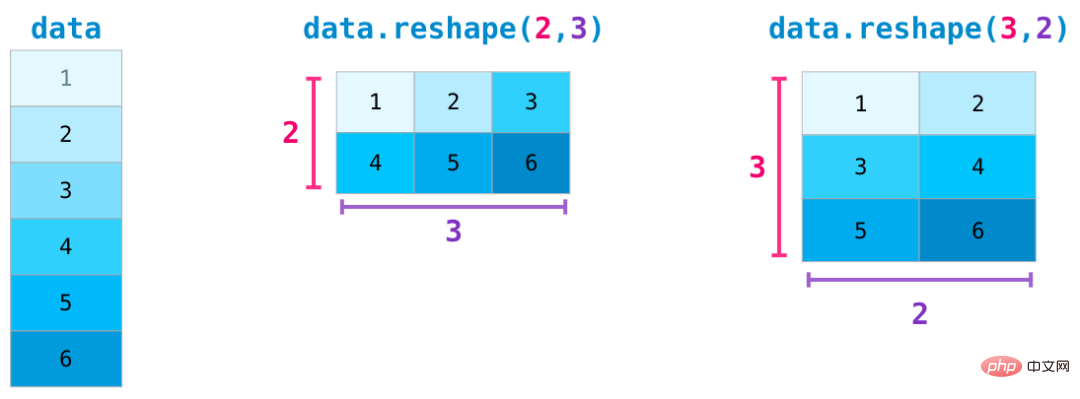

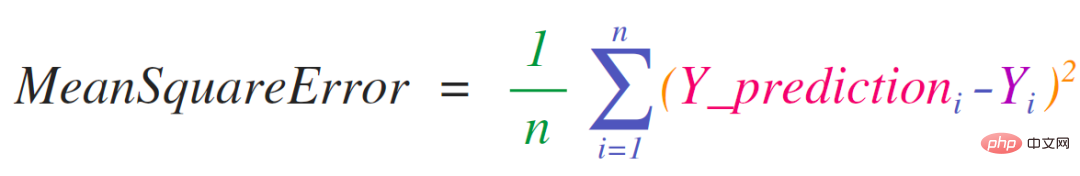






# #Theモデルは、戦場の詩人の詩を数値的に表現できるようになる前に、大量のテキストでトレーニングする必要があります。モデルに小さなデータセットを処理させ、このデータセットを使用して語彙 (71,290 語) を構築できます。 

以上がヒント | これはおそらく私が今まで見た中で最高の NumPy グラフィカル チュートリアルです。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



