

データの抽出方法です。要求された Web ページから を選択し、目的のデータを正しく見つけることが最初のステップです。
この記事では、誰もが学べるように、Python クローラーで Web ページ要素を見つけるために一般的に使用されるいくつかの方法 を比較します。 #Traditional
BeautifulSoup操作
BeautifulSoup に似ています)に基づく CSS セレクター (PyQuery- 正規表現
#XPath”- 参考 Web ページは
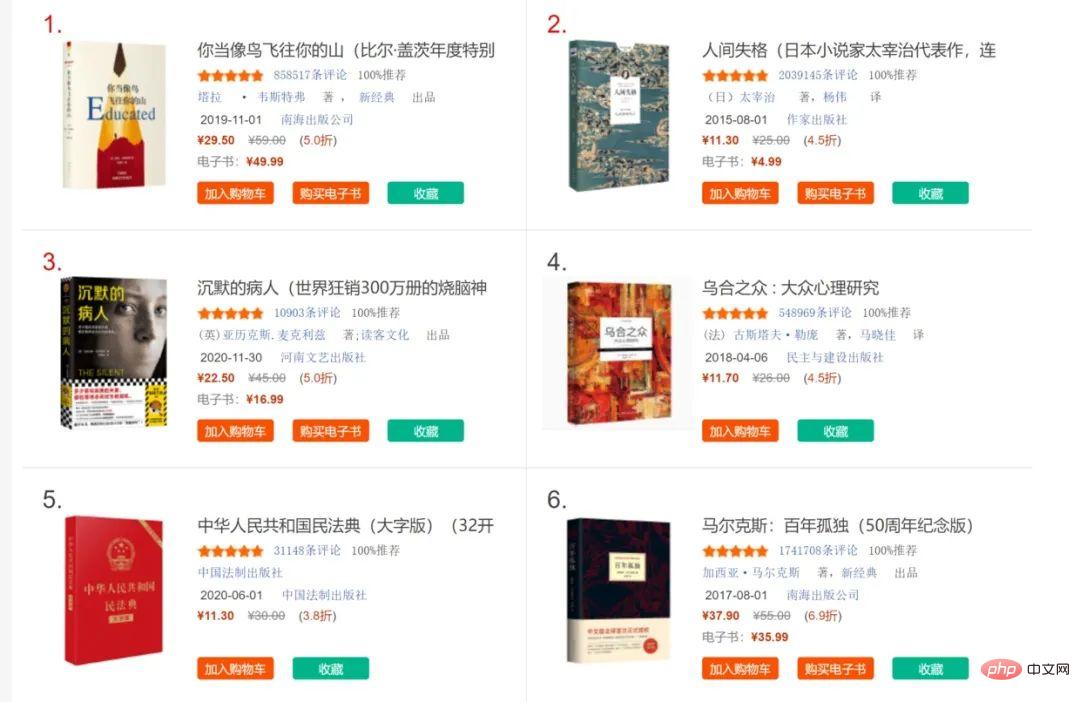
Dangdang.com ベストセラー書籍リスト :http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1ログイン後にコピー最初の 20 冊の本のタイトルを例として取り上げます。まず、Web サイトにクロール対策が設定されていないこと、および解析対象のコンテンツを直接返すことができるかどうかを確認します。
import requests url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text print(response)ログイン後にコピー慎重に検査した結果、返されたコンテンツには必要なデータがすべて含まれていることがわかり、不要であることがわかりました。 クロール対策に特別な配慮が払われています。
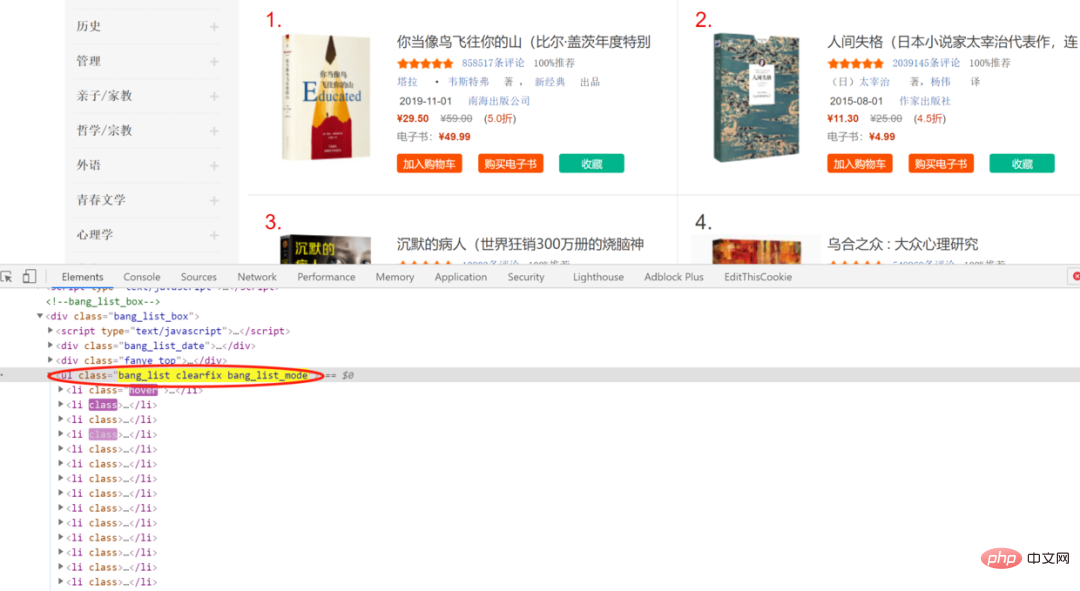
Web ページの要素を確認したところ、書誌情報が含まれていることがわかりました。
li内、これはclassに属し、bang_list clearfix bang_list_modeul内さらに検査すると、また、本のタイトルの対応する位置も明らかになり、さまざまな分析方法の重要な基礎となります
#1. 伝統的な BeautifulSoup 操作# #古典的な BeautifulSoup メソッドは、
from bs4 import BeautifulSoupを使用し、次に
soup = BeautifulSoup(html, " lxml")を使用します。テキストを特定の標準化された構造に変換し、を使用します。 find一連の解析メソッドです。コードは次のとおりです:<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>import requests from bs4 import BeautifulSoup url = &#39;http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1&#39; response = requests.get(url).text def bs_for_parse(response): soup = BeautifulSoup(response, "lxml") li_list = soup.find(&#39;ul&#39;, class_=&#39;bang_list clearfix bang_list_mode&#39;).find_all(&#39;li&#39;) # 锁定ul后获取20个li for li in li_list: title = li.find(&#39;div&#39;, class_=&#39;name&#39;).find(&#39;a&#39;)[&#39;title&#39;] # 逐个解析获取书名 print(title) if __name__ == &#39;__main__&#39;: bs_for_parse(response)</pre><div class="contentsignin">ログイン後にコピー</div></div>20 冊の本のタイトルを正常に取得しましたが、その中には文章で長く見えるものもあります。正規表現やその他の文字列メソッドについては、この記事では詳しく説明しません
2. 基于 BeautifulSoup 的 CSS 选择器
这种方法实际上就是 PyQuery 中 CSS 选择器在其他模块的迁移使用,用法是类似的。关于 CSS 选择器详细语法可以参考:
http://www.w3school.com.cn/cssref/css_selectors.asp由于是基于 BeautifulSoup 所以导入的模块以及文本结构转换都是一致的:import requests from bs4 import BeautifulSoup url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def css_for_parse(response): soup = BeautifulSoup(response, "lxml") print(soup) if __name__ == '__main__': css_for_parse(response)ログイン後にコピー然后就是通过
soup.select辅以特定的 CSS 语法获取特定内容,基础依旧是对元素的认真审查分析:import requests from bs4 import BeautifulSoup from lxml import html url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def css_for_parse(response): soup = BeautifulSoup(response, "lxml") li_list = soup.select('ul.bang_list.clearfix.bang_list_mode > li') for li in li_list: title = li.select('div.name > a')[0]['title'] print(title) if __name__ == '__main__': css_for_parse(response)ログイン後にコピー3. XPath
XPath 即为 XML 路径语言,它是一种用来确定 XML 文档中某部分位置的计算机语言,如果使用 Chrome 浏览器建议安装
XPath Helper插件,会大大提高写 XPath 的效率。之前的爬虫文章基本都是基于 XPath,大家相对比较熟悉因此代码直接给出:
import requests from lxml import html url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def xpath_for_parse(response): selector = html.fromstring(response) books = selector.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li") for book in books: title = book.xpath('div[@class="name"]/a/@title')[0] print(title) if __name__ == '__main__': xpath_for_parse(response)ログイン後にコピー4. 正则表达式
如果对 HTML 语言不熟悉,那么之前的几种解析方法都会比较吃力。这里也提供一种万能解析大法:正则表达式,只需要关注文本本身有什么特殊构造文法,即可用特定规则获取相应内容。依赖的模块是
re首先重新观察直接返回的内容中,需要的文字前后有什么特殊:
import requests import re url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text print(response)ログイン後にコピー
<div class="name"><a href="http://product.dangdang.com/xxxxxxxx.html" target="_blank" title="xxxxxxx">书名就藏在上面的字符串中,蕴含的网址链接中末尾的数字会随着书名而改变。分析到这里正则表达式就可以写出来了:
import requests import re url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def re_for_parse(response): reg = '<div class="name"><a href="http://product.dangdang.com/\d+.html" target="_blank" title="(.*?)">' for title in re.findall(reg, response): print(title) if __name__ == '__main__': re_for_parse(response)ログイン後にコピー可以发现正则写法是最简单的,但是需要对于正则规则非常熟练。所谓正则大法好!
当然,不论哪种方法都有它所适用的场景,在真实操作中我们也需要在分析网页结构来判断如何高效的定位元素,最后附上本文介绍的四种方法的完整代码,大家可以自行操作一下来加深体会
import requests from bs4 import BeautifulSoup from lxml import html import re url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def bs_for_parse(response): soup = BeautifulSoup(response, "lxml") li_list = soup.find('ul', class_='bang_list clearfix bang_list_mode').find_all('li') for li in li_list: title = li.find('div', class_='name').find('a')['title'] print(title) def css_for_parse(response): soup = BeautifulSoup(response, "lxml") li_list = soup.select('ul.bang_list.clearfix.bang_list_mode > li') for li in li_list: title = li.select('div.name > a')[0]['title'] print(title) def xpath_for_parse(response): selector = html.fromstring(response) books = selector.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li") for book in books: title = book.xpath('div[@class="name"]/a/@title')[0] print(title) def re_for_parse(response): reg = '<div class="name"><a href="http://product.dangdang.com/\d+.html" target="_blank" title="(.*?)">' for title in re.findall(reg, response): print(title) if __name__ == '__main__': # bs_for_parse(response) # css_for_parse(response) # xpath_for_parse(response) re_for_parse(response)ログイン後にコピー
以上がPython クローラーで要素を見つけるために一般的に使用される 4 つの方法を比較しました。どれが好みですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


 20 冊の本のタイトルを正常に取得しましたが、その中には文章で長く見えるものもあります。正規表現やその他の文字列メソッドについては、この記事では詳しく説明しません
20 冊の本のタイトルを正常に取得しましたが、その中には文章で長く見えるものもあります。正規表現やその他の文字列メソッドについては、この記事では詳しく説明しません
 观察几个数目相信就有答案了:
观察几个数目相信就有答案了:














![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



