

Spring Boot は MySQL の読み取り/書き込み分離テクノロジを実装します
読み取りと書き込みの分離を実現する方法、Spring Boot プロジェクト、データベースは MySQL、永続層は MyBatis を使用します。
実際、これを実装するのは非常に簡単です。まず質問について考えてください:
高同時実行シナリオの場合、データベースに関するすべて どのような最適化方法がありますか?
次の実装方法が一般的に使用されます: 読み取り/書き込み分離、キャッシュ、マスター/スレーブ アーキテクチャ クラスター、サブデータベースとサブテーブルなど。
インターネット アプリケーションでは、ほとんどのシナリオで読み取りが多くなり、書き込みが少なくなり、メイン ライブラリと読み取りライブラリの 2 つのライブラリがセットアップされます。
メイン ライブラリは書き込みを担当し、スレーブ ライブラリは主に読み取りを担当します。読み取りライブラリ クラスターを確立すると、読み取りと書き込みを分離することで読み取りと書き込みの競合を減らし、データベースの負荷を軽減できます。データ ソース上の機能。データベースを保護する目的。実際の運用では、書き込み部分は直接メインライブラリに、読み込み部分は直接読み込みライブラリに切り替わる、典型的な読み書き分離技術です。
この記事では、読み取りと書き込みの分離に焦点を当て、それを達成する方法を検討します。
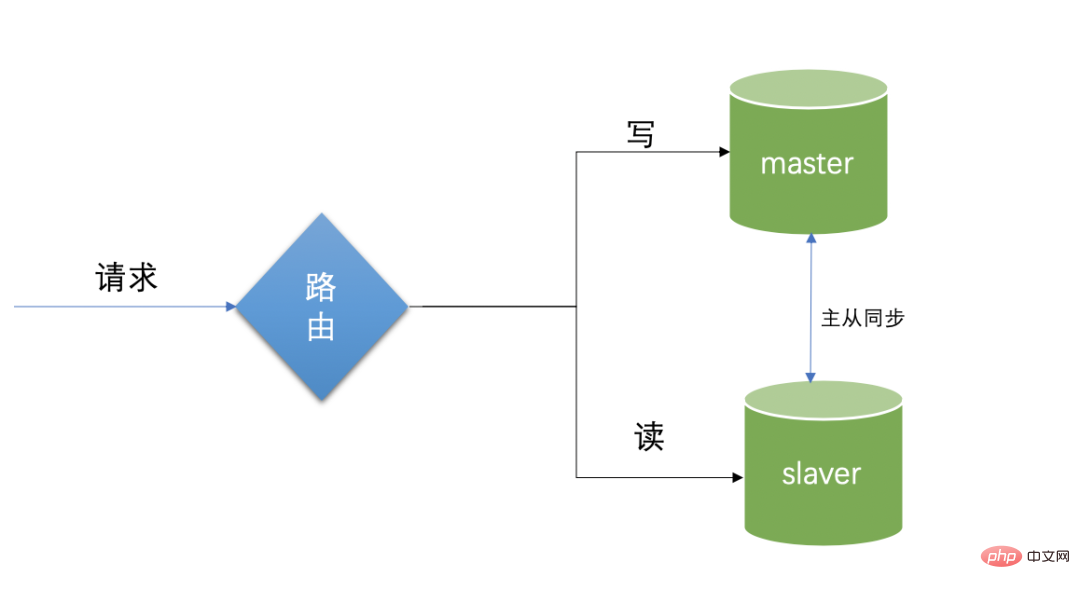
マスター/スレーブ同期の制限事項: マスター データベースとスレーブ データベースに分かれており、マスター データベースとスレーブ データベースは同じデータベース構造を維持します。マスター データベースは書き込みを担当し、データを書き込むと、データはスレーブ データベースに自動的に同期されます。スレーブ データベースは読み取りを担当し、読み取り要求が来ると、データは読み取りデータベースから直接読み取られ、マスター データベースは自動的にデータをスレーブ データベースにコピーします。ただし、このブログでは運用と保守の作業に重点を置いているため、この部分の構成知識は紹介しません。
ここには問題が含まれています:
マスター/スレーブ レプリケーションの遅延問題。メイン データベースに書き込むときに、突然読み取りリクエストが来ますが、データはまだそこにあります。完全な同期がないと、読み取り要求されたデータを読み取ることができない、または読み取られたデータが元の値より小さいという状況が発生します。最も単純な具体的な解決策は、読み取りリクエストを一時的にメイン ライブラリに向けることですが、同時にマスターとスレーブの分離の意味の一部も失われます。つまり、厳密な意味でのデータ整合性シナリオでは、読み取りと書き込みの分離は完全に適切ではないため、読み取りと書き込みの分離を使用する欠点として、更新の適時性に注意してください。
わかりました。この部分は理解のためのものです。次に、Java コードを通じて読み取りと書き込みの分離を実現する方法を見てみましょう:
注: このプロジェクトでは、Spring Boot、spring-aop、spring-jdbc、aspectjweaver などの依存関係を導入する必要があります。
プログラム期間: わずか 30 日、何をすればいいですか?準備しますか?
1: マスター/スレーブ データ ソースの構成
マスター/スレーブを構成する必要がありますデータベース、マスター/スレーブ データベース構成は通常、構成ファイルに記述されます。 @ConfigurationProperties アノテーションを使用すると、構成ファイル内のプロパティ (一般的な名前: application.Properties) を特定のクラス プロパティにマッピングできるため、書き込まれた値を読み取って特定のコードに挿入できます。カスタムは合意よりも優れているという原則に従って、私たちは全員、メイン ライブラリをマスターとしてマークし、スレーブ ライブラリをスレーブとしてマークします。
このプロジェクトは Alibaba の druid データベース接続プールを使用し、ビルド ビルダー モードを使用して DataSource オブジェクトを作成します。DataSource はコード レベルで抽象化されたデータ ソースです。次に、sessionFactory、sqlTemplate、トランザクション マネージャーなどを構成する必要があります。
/**
* 主从配置
*/
@Configuration
@MapperScan(basePackages = "com.wyq.mysqlreadwriteseparate.mapper", sqlSessionTemplateRef = "sqlTemplate")
public class DataSourceConfig {
/**
* 主库
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource master() {
return DruidDataSourceBuilder.create().build();
}
/**
* 从库
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaver() {
return DruidDataSourceBuilder.create().build();
}
/**
* 实例化数据源路由
*/
@Bean
public DataSourceRouter dynamicDB(@Qualifier("master") DataSource masterDataSource,
@Autowired(required = false) @Qualifier("slaver") DataSource slaveDataSource) {
DataSourceRouter dynamicDataSource = new DataSourceRouter();
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DataSourceEnum.MASTER.getDataSourceName(), masterDataSource);
if (slaveDataSource != null) {
targetDataSources.put(DataSourceEnum.SLAVE.getDataSourceName(), slaveDataSource);
}
dynamicDataSource.setTargetDataSources(targetDataSources);
dynamicDataSource.setDefaultTargetDataSource(masterDataSource);
return dynamicDataSource;
}
/**
* 配置sessionFactory
* @param dynamicDataSource
* @return
* @throws Exception
*/
@Bean
public SqlSessionFactory sessionFactory(@Qualifier("dynamicDB") DataSource dynamicDataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setMapperLocations(
new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/*Mapper.xml"));
bean.setDataSource(dynamicDataSource);
return bean.getObject();
}
/**
* 创建sqlTemplate
* @param sqlSessionFactory
* @return
*/
@Bean
public SqlSessionTemplate sqlTemplate(@Qualifier("sessionFactory") SqlSessionFactory sqlSessionFactory) {
return new SqlSessionTemplate(sqlSessionFactory);
}
/**
* 事务配置
*
* @param dynamicDataSource
* @return
*/
@Bean(name = "dataSourceTx")
public DataSourceTransactionManager dataSourceTransactionManager(@Qualifier("dynamicDB") DataSource dynamicDataSource) {
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();
dataSourceTransactionManager.setDataSource(dynamicDataSource);
return dataSourceTransactionManager;
}
}2: データ ソース ルーティングの構成
ルーティングはマスターとスレーブの分離において非常に重要です。読み取り/書き込みスイッチングの中核。 Spring は、ユーザー定義のルールに従って現在のデータ ソースを選択するための AbstractRoutingDataSource を提供します。その機能は、クエリを実行する前に使用されるデータ ソースを設定し、動的ルーティング データ ソースを実装し、各データベース クエリ操作の前にそれを実行することです。抽象メソッド determineCurrentLookupKey() は、使用するデータ ソースを決定します。
グローバル データ ソース マネージャーを使用するには、グローバル変数として理解され、いつでもアクセスできる DataSourceContextHolder データベース コンテキスト マネージャーを導入する必要があります (以下の詳細な紹介を参照)。関数は現在のデータ ソースを保存します。
public class DataSourceRouter extends AbstractRoutingDataSource {
/**
* 最终的determineCurrentLookupKey返回的是从DataSourceContextHolder中拿到的,因此在动态切换数据源的时候注解
* 应该给DataSourceContextHolder设值
*
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.get();
}
}三:数据源上下文环境
数据源上下文保存器,便于程序中可以随时取到当前的数据源,它主要利用 ThreadLocal 封装,因为 ThreadLocal 是线程隔离的,天然具有线程安全的优势。这里暴露了 set 和 get、clear 方法,set 方法用于赋值当前的数据源名,get 方法用于获取当前的数据源名称,clear 方法用于清除 ThreadLocal 中的内容,因为 ThreadLocal 的 key 是 weakReference 是有内存泄漏风险的,通过 remove 方法防止内存泄漏。
/**
* 利用ThreadLocal封装的保存数据源上线的上下文context
*/
public class DataSourceContextHolder {
private static final ThreadLocal<String> context = new ThreadLocal<>();
/**
* 赋值
*
* @param datasourceType
*/
public static void set(String datasourceType) {
context.set(datasourceType);
}
/**
* 获取值
* @return
*/
public static String get() {
return context.get();
}
public static void clear() {
context.remove();
}
}四:切换注解和 Aop 配置
首先我们来定义一个@DataSourceSwitcher 注解,拥有两个属性
① 当前的数据源② 是否清除当前的数据源,并且只能放在方法上,(不可以放在类上,也没必要放在类上,因为我们在进行数据源切换的时候肯定是方法操作),该注解的主要作用就是进行数据源的切换,在 dao 层进行操作数据库的时候,可以在方法上注明表示的是当前使用哪个数据源。
@DataSourceSwitcher 注解的定义:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Documented
public @interface DataSourceSwitcher {
/**
* 默认数据源
* @return
*/
DataSourceEnum value() default DataSourceEnum.MASTER;
/**
* 清除
* @return
*/
boolean clear() default true;
}DataSourceAop配置:
为了赋予@DataSourceSwitcher 注解能够切换数据源的能力,我们需要使用 AOP,然后使用@Aroud 注解找到方法上有@DataSourceSwitcher.class 的方法,然后取注解上配置的数据源的值,设置到 DataSourceContextHolder 中,就实现了将当前方法上配置的数据源注入到全局作用域当中。
@Slf4j
@Aspect
@Order(value = 1)
@Component
public class DataSourceContextAop {
@Around("@annotation(com.wyq.mysqlreadwriteseparate.annotation.DataSourceSwitcher)")
public Object setDynamicDataSource(ProceedingJoinPoint pjp) throws Throwable {
boolean clear = false;
try {
Method method = this.getMethod(pjp);
DataSourceSwitcher dataSourceSwitcher = method.getAnnotation(DataSourceSwitcher.class);
clear = dataSourceSwitcher.clear();
DataSourceContextHolder.set(dataSourceSwitcher.value().getDataSourceName());
log.info("数据源切换至:{}", dataSourceSwitcher.value().getDataSourceName());
return pjp.proceed();
} finally {
if (clear) {
DataSourceContextHolder.clear();
}
}
}
private Method getMethod(JoinPoint pjp) {
MethodSignature signature = (MethodSignature) pjp.getSignature();
return signature.getMethod();
}
}五:用法以及测试
在配置好了读写分离之后,就可以在代码中使用了,一般而言我们使用在 service 层或者 dao 层,在需要查询的方法上添加@DataSourceSwitcher(DataSourceEnum.SLAVE),它表示该方法下所有的操作都走的是读库。在需要 update 或者 insert 的时候使用@DataSourceSwitcher(DataSourceEnum.MASTER)表示接下来将会走写库。
其实还有一种更为自动的写法,可以根据方法的前缀来配置 AOP 自动切换数据源,比如 update、insert、fresh 等前缀的方法名一律自动设置为写库。select、get、query 等前缀的方法名一律配置为读库,这是一种更为自动的配置写法。缺点就是方法名需要按照 aop 配置的严格来定义,否则就会失效。
@Service
public class OrderService {
@Resource
private OrderMapper orderMapper;
/**
* 读操作
*
* @param orderId
* @return
*/
@DataSourceSwitcher(DataSourceEnum.SLAVE)
public List<Order> getOrder(String orderId) {
return orderMapper.listOrders(orderId);
}
/**
* 写操作
*
* @param orderId
* @return
*/
@DataSourceSwitcher(DataSourceEnum.MASTER)
public List<Order> insertOrder(Long orderId) {
Order order = new Order();
order.setOrderId(orderId);
return orderMapper.saveOrder(order);
}
}六:总结
还是画张图来简单总结一下:
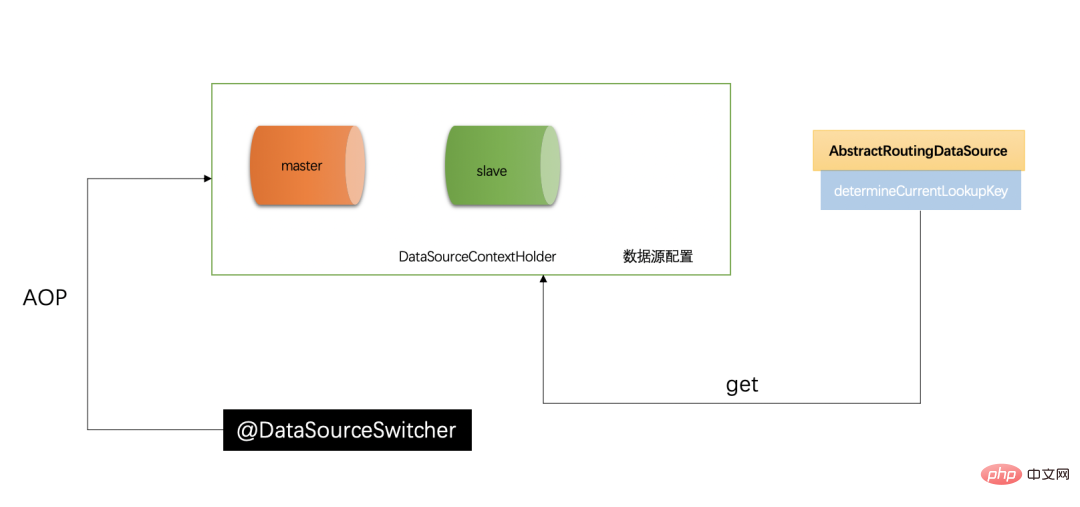
この記事では、データベースの読み取りと書き込みの分離を実現する方法を紹介します。読み取りと書き込みの分離の中核はデータ ルーティングであることに注意してください。AbstractRoutingDataSource とdetermineCurrentLookupKey.()メソッドを上書きします。同時に、グローバル コンテキスト マネージャー DataSourceContextHolder に注意する必要があります。これは、データ ソース コンテキストを保存するメイン クラスであり、ルーティング メソッドで見つかるデータ ソース値でもあります。これはデータ ソースの転送ステーションに相当し、データ ソースやトランザクションなどを作成および管理するための jdbc-Template の最下層と組み合わせることで、データベースの読み取りと書き込みの分離が完全に実現されます。
以上がSpring Boot は MySQL の読み取り/書き込み分離テクノロジを実装しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7504
7504
 15
1378
52
78
11
19
54
15
1378
52
78
11
19
54

 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
 NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する手順:データベースに接続します。 SQLエディターウィンドウを作成します。 SQLクエリまたはスクリプトを書きます。 [実行]ボタンをクリックして、クエリまたはスクリプトを実行します。結果を表示します(クエリが実行された場合)。
 Navicatは、データベースエラーコードとソリューションに接続します
Apr 08, 2025 pm 11:06 PM
Navicatは、データベースエラーコードとソリューションに接続します
Apr 08, 2025 pm 11:06 PM
データベースに接続するときの一般的なエラーとソリューション:ユーザー名またはパスワード(エラー1045)ファイアウォールブロック接続(エラー2003)接続タイムアウト(エラー10060)ソケット接続を使用できません(エラー1042)SSL接続エラー(エラー10055)接続の試みが多すぎると、ホストがブロックされます(エラー1129)データベースは存在しません(エラー1049)
