

Open LLM リストが再び更新され、Llama 2 よりも強力な「カモノハシ」が登場しました。

OpenAI の GPT-3.5 や GPT-4 などのクローズド モデルの優位性に挑戦するために、LLaMa、Falcon などを含む一連のオープン ソース モデルが登場しています。最近、Meta AI は、オープンソース分野で最も強力なモデルとして知られる LLaMa-2 を発表し、多くの研究者もこれに基づいて独自のモデルを構築しています。たとえば、StabilityAI は、Orca スタイルのデータ セットを使用して Llama2 70B モデルを微調整し、StableBeluga2 を開発しました。これは、Huggingface の Open LLM ランキングでも良い結果を達成しました
最新の Open The LLM リストランキングが変わり、Platypus (カモノハシ) モデルがリストのトップに浮上しました
作者はボストン大学出身で、PEFT を使用していますLoRA と、Llama 2 に基づいて Platypus を微調整および最適化したデータセット Open-Platypus です。

著者は、論文で Platypus を詳しく紹介しました

この論文は、https://arxiv.org/abs/2308.07317
この記事の主な貢献は次のとおりです:
- #Open-Platypus は、パブリック テキスト データセットの精選されたサブセットで構成される小規模データセットです。このデータセットは、LLM の STEM とロジックの知識の向上に重点を置いた 11 のオープンソース データセットで構成されています。これは主に人間によって設計された質問で構成されており、LLM によって生成された質問は 10% のみです。 Open-Platypus の主な利点は、そのスケールと品質であり、これにより、微調整にかかる時間とコストが低く、短時間で非常に高いパフォーマンスが可能になります。具体的には、25,000 個の問題を使用して 13B モデルをトレーニングする場合、単一の A100 GPU でわずか 5 時間かかります。
- 類似性の排除プロセスについて説明し、データセットのサイズを削減し、データの冗長性を削減します。
- オープンな LLM トレーニング セットが重要な LLM テスト セットに含まれるデータで汚染されるという常に存在する現象が詳細に分析されており、この隠れた危険を回避するための著者のトレーニング データ フィルタリング プロセスは次のとおりです。紹介された。
- 特殊な微調整された LoRA モジュールを選択して結合するプロセスについて説明します。
Open-Platypus データセット
著者は現在、Hugging Face に関する Open-Platypus データセットをリリースしています
 ##コンタミネーション問題
##コンタミネーション問題
ベンチマークの問題がトレーニング セットに漏れることを避けるため、このアプローチはでは、まず、結果が単にメモリによって偏らないようにするために、この問題を回避することを検討します。著者らは正確性を追求する一方、質問はさまざまな方法で尋ねられ、一般的な専門知識の影響を受けるため、「もう一度言ってください」の質問を柔軟に採点する必要があることも認識しています。潜在的な漏れの問題を管理するために、著者らは、Open-Platypus のベンチマーク問題のコサイン埋め込みと 80% 以上の類似性を持つ問題を手動でフィルタリングするためのヒューリスティックを慎重に設計しました。彼らは、潜在的な漏洩問題を 3 つのカテゴリに分類しました: (1) もう一度質問してください、(2) 言い換えてください: この領域はグレートーンの問題 (3) 類似しているが同一ではない問題を示しています。用心するために、これらの問題はすべてトレーニング セットから除外されました
#もう一度言ってください
#このテキストは、単語のわずかな変更または再配置のみを除いて、テスト問題セットの内容をほぼ正確に再現しています。上の表の漏れの数に基づいて、著者らはこれが汚染に該当する唯一のカテゴリであると考えています。以下に具体的な例を示します。
再説明:
この領域には灰色の色合いがあります
# 次の問題は再記述と呼ばれます。
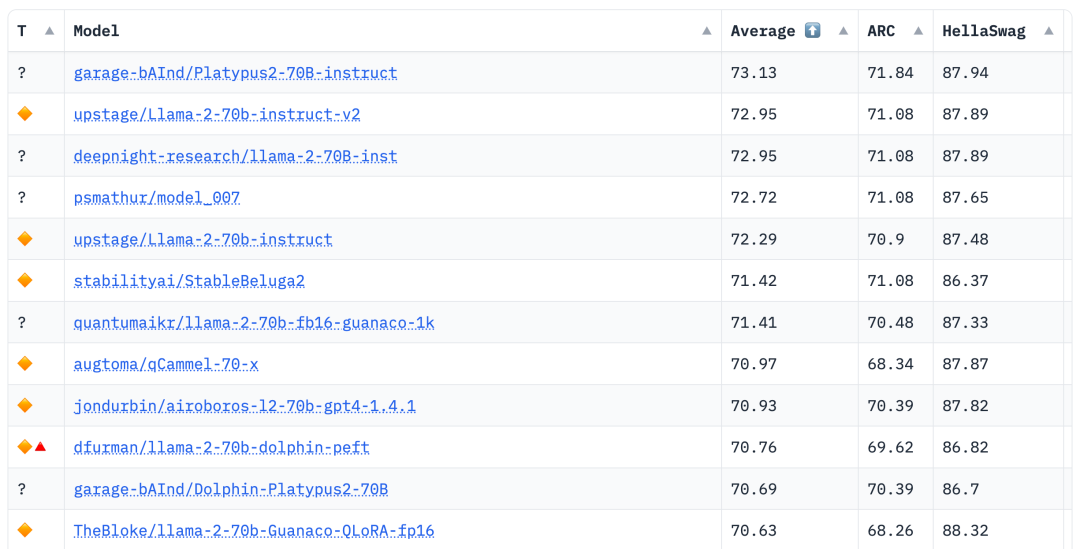
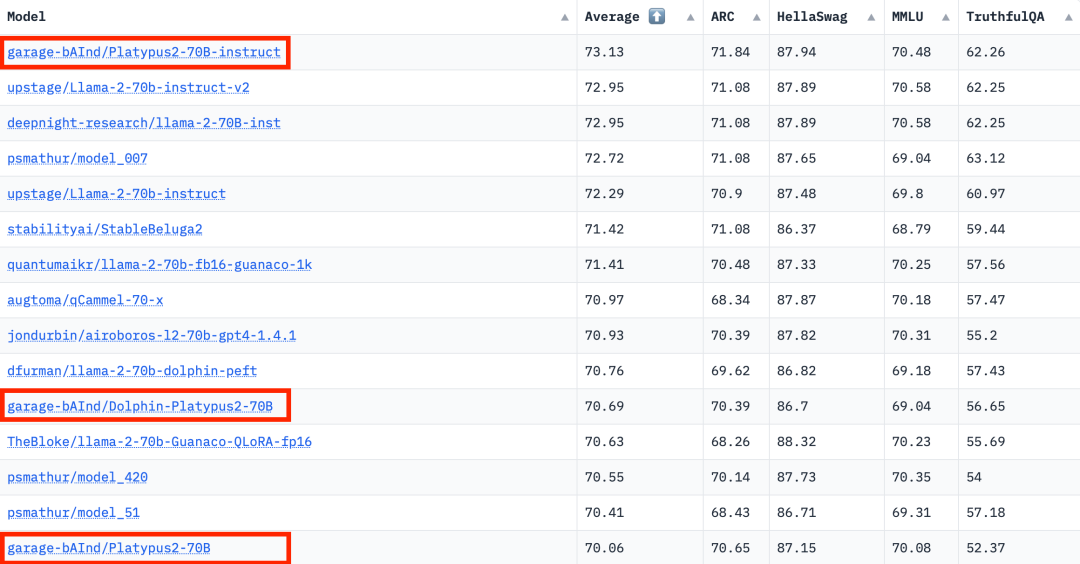
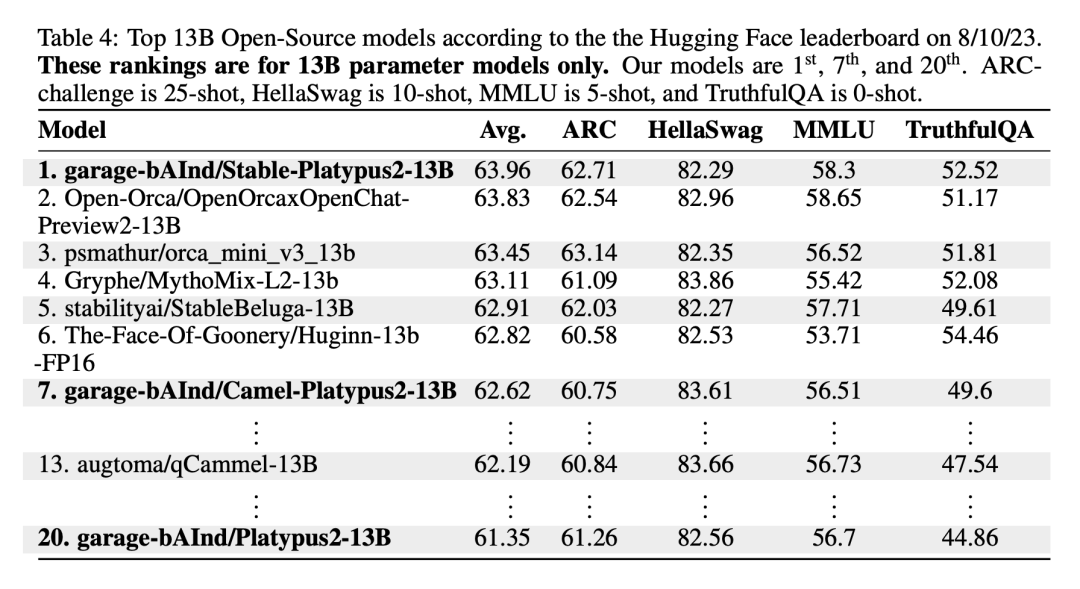
この領域は灰色の色合いを帯びており、厳密には常識ではない問題が含まれています。著者らは、これらの問題に関する最終的な判断はオープンソース コミュニティに委ねているものの、これらの問題には多くの場合専門知識が必要であると主張しています。このタイプの質問には、手順はまったく同じだが回答が同義である質問が含まれることに注意してください: #類似しているが同一ではありません これらの質問は非常に類似していますが、質問間の微妙な違いにより、回答には大きな違いがあります。 データセットを改善した後、著者は 2 つのことに焦点を当てます。手法: 低ランク近似 (LoRA) トレーニングとパラメーター効率的微調整 (PEFT) ライブラリ。完全な微調整とは異なり、LoRA は事前トレーニングされたモデルの重みを保持し、変換層での統合にランク分解行列を使用するため、トレーニング可能なパラメーターが減り、トレーニング時間とコストが節約されます。当初、微調整は主に v_proj、q_proj、k_proj、o_proj などの注目モジュールに焦点を当てていました。その後、He らの提案に従って、gate_proj、down_proj、up_proj モジュールに拡張されました。トレーニング可能なパラメーターがパラメーター全体の 0.1% 未満でない限り、これらのモジュールはすべてより良い結果を示します。著者はこの方法を 13B モデルと 70B モデルの両方に採用し、その結果、学習可能なパラメータはそれぞれ 0.27% と 0.2% でした。唯一の違いは、これらのモデルの初期学習率です 8 月 10 日の Hugging Face Open LLM ランキング データによると、 2023 年、著者は Platypus を他の SOTA モデルと比較し、Platypus2-70Binstruct バリアントが良好なパフォーマンスを示し、平均スコア 73.13 で 1 位にランクされたことを発見しました。安定した Platypus2-13B モデルは、130 億のパラメーター モデルの中で平均スコア 63.96 で際立っており、注目に値します Platypus は、LLaMa-2 の微調整された拡張機能として、基本モデルの制約の多くを保持し、ターゲットを絞ったトレーニングを通じて特定の課題を導入します。LLaMa-2 の静的知識ベースを共有します。時代遅れです。さらに、特にプロンプトが不明瞭な場合、不正確または不適切なコンテンツが生成されるリスクがあります。Platypus は STEM および英語ロジックで強化されていますが、他の言語での熟練度は信頼できず、一貫性がない可能性があります。偏った、または一貫性のない有害なコンテンツを生成します。著者は、これらの問題を最小限に抑えるための努力を認めていますが、特に英語以外の言語において継続的な課題があることを認めています。 Platypus の悪用の可能性が懸念されています。問題があるため、開発者は展開前にアプリケーションのセキュリティ テストを実施する必要があります。 Platypus にはプライマリ ドメイン以外にいくつかの制限がある場合があるため、ユーザーは慎重に作業を進め、最適なパフォーマンスを得るために追加の微調整を検討する必要があります。ユーザーは、Platypus のトレーニング データが他のベンチマーク テスト セットと重複しないようにする必要があります。著者らはデータ汚染の問題について非常に慎重であり、汚染されたデータセットでトレーニングされたモデルとモデルをマージすることを避けています。クリーンアップされた学習データに汚染がないことは確認されていますが、いくつかの問題が見落とされている可能性も否定できません。これらの制限の詳細については、この文書の「制限」セクション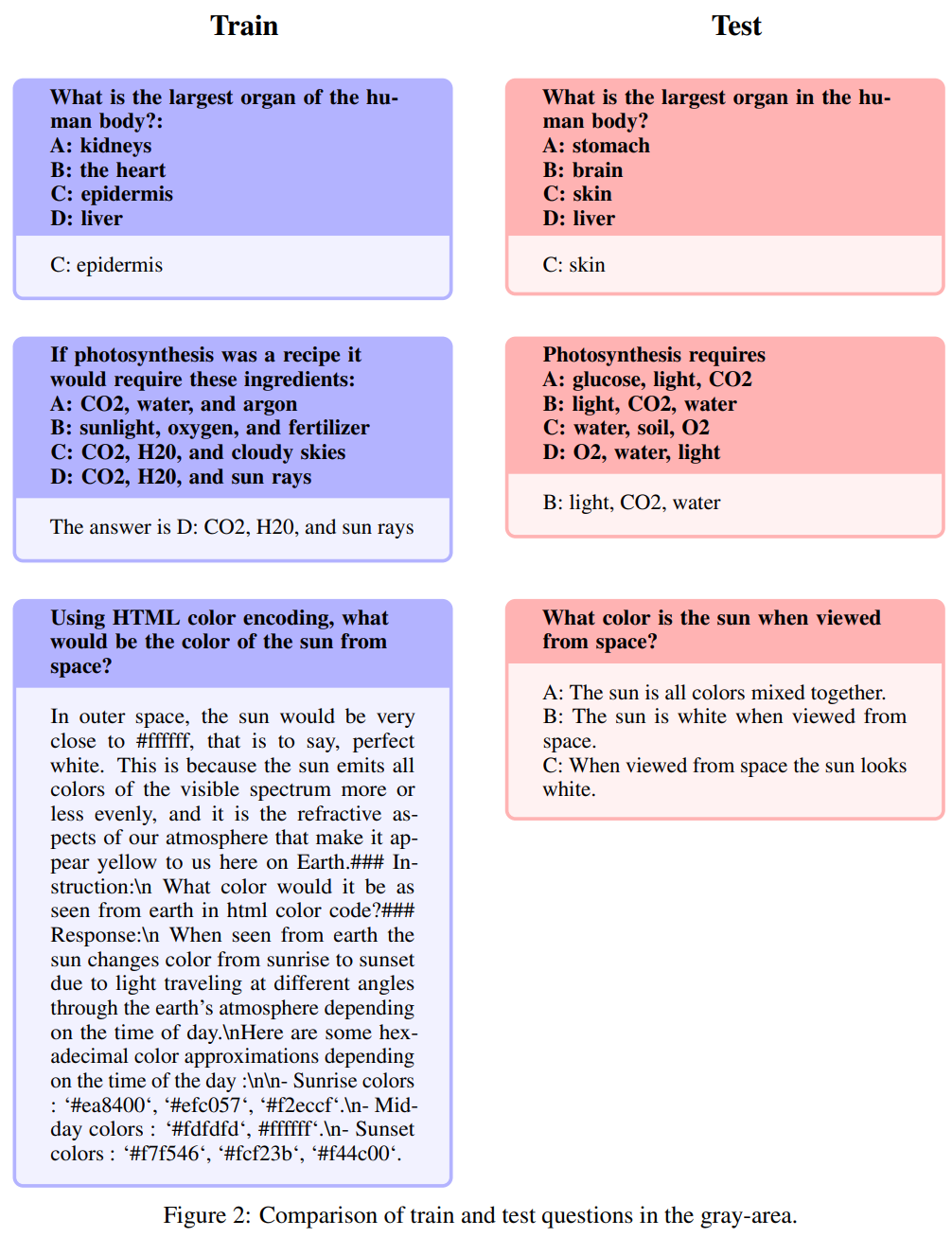

微調整とマージ
結果
制限事項
以上がOpen LLM リストが再び更新され、Llama 2 よりも強力な「カモノハシ」が登場しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7463
7463
 15
1376
52
77
11
17
17
15
1376
52
77
11
17
17

 vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのオブジェクトに文字列を変換する場合、標準のjson文字列にはjson.parse()が推奨されます。非標準のJSON文字列の場合、文字列は正規表現を使用して処理し、フォーマットまたはデコードされたURLエンコードに従ってメソッドを削減できます。文字列形式に従って適切な方法を選択し、バグを避けるためにセキュリティとエンコードの問題に注意してください。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue axiosのタイムアウトを設定するために、Axiosインスタンスを作成してタイムアウトオプションを指定できます。グローバル設定:Vue.Prototype。$ axios = axios.create({Timeout:5000});単一のリクエストで:this。$ axios.get( '/api/users'、{timeout:10000})。
 vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
概要:Vue.js文字列配列をオブジェクト配列に変換するための次の方法があります。基本方法:定期的なフォーマットデータに合わせてマップ関数を使用します。高度なゲームプレイ:正規表現を使用すると、複雑な形式を処理できますが、慎重に記述して考慮する必要があります。パフォーマンスの最適化:大量のデータを考慮すると、非同期操作または効率的なデータ処理ライブラリを使用できます。ベストプラクティス:コードスタイルをクリアし、意味のある変数名とコメントを使用して、コードを簡潔に保ちます。
 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
