データベース分散の中核となる内容は、データのセグメント化 (1000W または 100G は、業界の参考値 と言えます。詳細は、現在のシステムのハードウェア設備、テーブル構造の設計、その他の要因によって異なります。 。
シャーディング) と、セグメント化後のデータの位置付けと統合にほかなりません。データのセグメント化とは、データを複数のデータベースに分散して保存することで、単一のデータベースのデータ量を削減し、ホストの数を拡張することで単一のデータベースのパフォーマンスの問題を軽減し、データベースの運用を改善するという目的を達成することです。パフォーマンス。
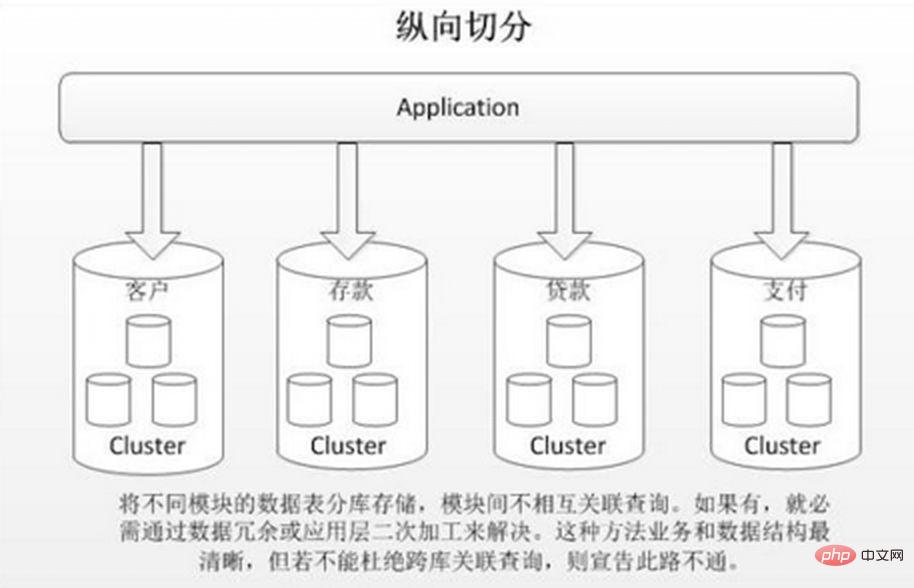
水平シャーディングの利点:
1. 単一データベース内の過剰なデータ量と高い同時実行性によって引き起こされるパフォーマンスのボトルネックがなくなり、システムの安定性と負荷容量が向上します。側面の変換が小さいため、ビジネス モジュールを分割する必要がありません
欠点:
1. シャード間のトランザクションの一貫性を保証するのが難しい 2. データベース間の結合クエリのパフォーマンスが低い 3. データの複数の拡張が難しく、メンテナンスの量が膨大になる.
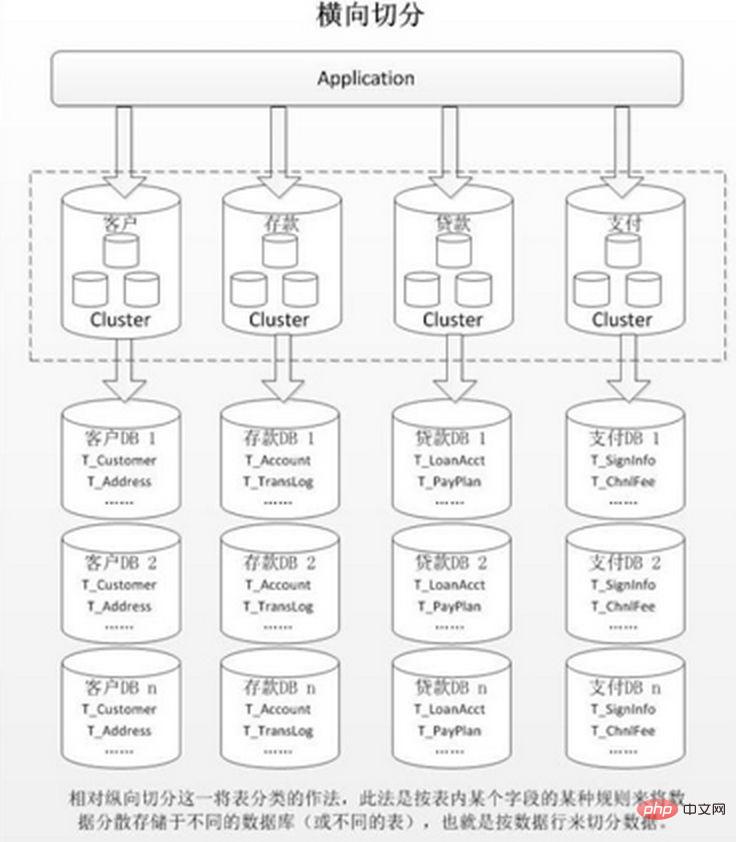
同じテーブル水平分割後 複数のデータベース/テーブルに出現し、それぞれのデータベース/テーブルの内容は異なります。典型的なデータ断片化ルールは次のとおりです:
に従って分割します。たとえば、異なる月または日のデータを日付ごとに異なるライブラリに分散し、userId が 1 ~ 9999 のレコードを最初のライブラリに割り当て、userId が 10000 ~ 20000 のレコードを 2 番目のライブラリに割り当てます。ある意味、一部のシステムで使用されている「ホット データとコールド データの分離」、あまり使用されていない履歴データの一部を他のライブラリに移行し、ビジネス機能でホット データ クエリのみを提供する方法も同様の手法です。
この利点は次のとおりです:
1. 単一テーブルのサイズを制御できる 2. 水平方向の拡張が当然簡単であるため、後でシャード クラスター全体を拡張したい場合は、必要なのはノードを追加することだけであり、他のシャードからデータを移行する必要はありません。 3. 範囲検索にシャード フィールドを使用する場合、連続シャーディングにより迅速なクエリのためにシャードをすばやく見つけることができ、シャード間のクエリの問題を効果的に回避できます。
欠点:
ホットスポット データがパフォーマンスのボトルネックになります。連続シャーディングには、時間フィールドによるシャーディングなどのデータ ホットスポットが存在する場合があります。一部のシャードには、最新の期間のデータが保存され、頻繁に読み書きされる可能性がありますが、一部のシャードには、めったにクエリされない履歴データが保存されます
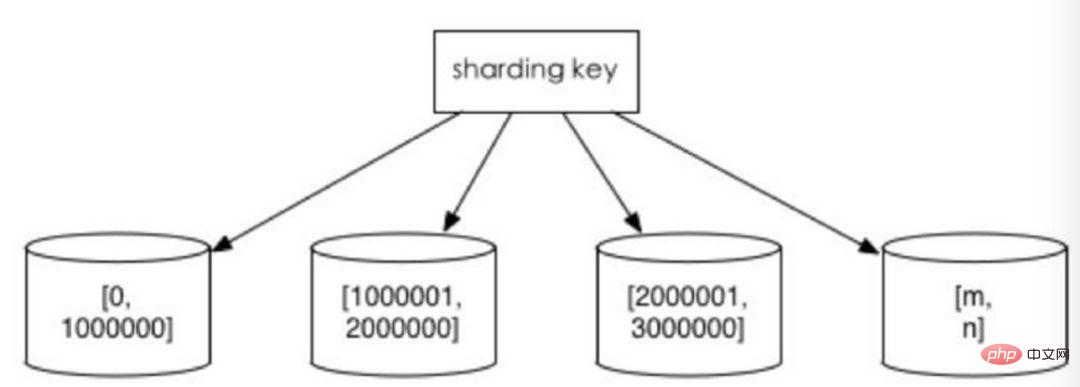
# 通常、Mod を取得するにはハッシュを使用します。分割方法。例: Customer テーブルを cusno フィールドに基づいて 4 つのライブラリに分割し、残りの 0 を最初のライブラリに、残りの 1 を 2 番目のライブラリに配置します。これにより、同じユーザーのデータが同じデータベースに分散されるため、クエリ条件に cusno フィールドが含まれている場合、対応するデータベースをクエリの対象として明確に配置できます。
#利点:
データの断片化は比較的均等であり、ホットスポットや同時アクセスのボトルネックが発生しにくいです。欠点: 1. 後でシャードクラスターを拡張する場合、古いデータを移行する必要があります (一貫したハッシュアルゴリズムを使用すると、この問題をより適切に回避できます) 2. クロスシャードクエリの複雑な問題に直面するのは簡単です。例えば、上記の例では、頻繁に使用するクエリ条件にcusnoが含まれていないとデータベースが見つからないため、4つのライブラリに同時にクエリを開始し、メモリ上のデータをマージする必要があります。 、最小セットを取得してアプリケーションに返すと、ライブラリがドラッグになってしまいます。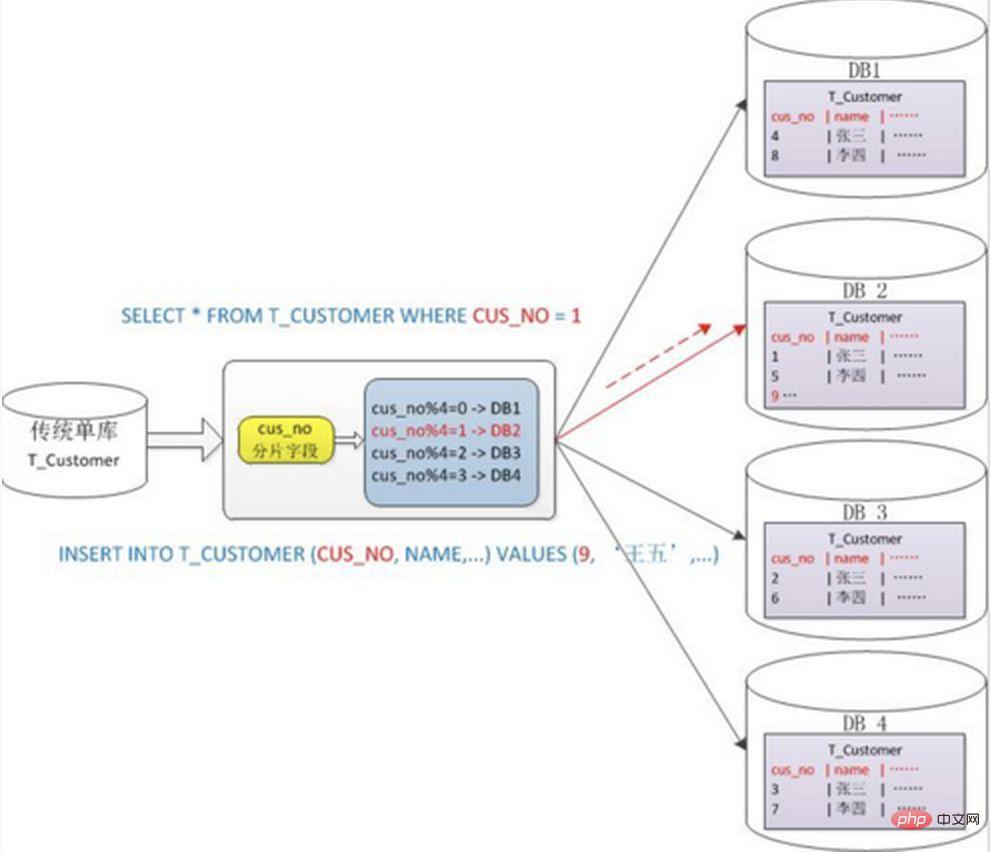
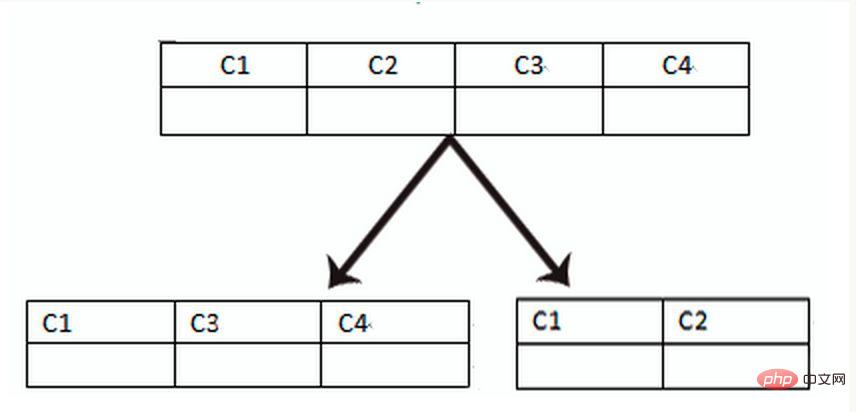
時間のためにスペースを使用し、パフォーマンスのために結合クエリを回避する典型的なアンチパラダイム設計。たとえば、注文テーブルが userId を保存すると、userName の冗長コピーも保存されるため、注文の詳細をクエリするときに「購入者ユーザー テーブル」をクエリする必要がなくなります。
ただし、この方法を適用できるシナリオも限られており、依存フィールドが比較的少ない状況に適しています。冗長フィールドのデータの一貫性を確保することも困難です。上記の注文テーブルの例と同様に、購入者が userName を変更した後、注文履歴で同期して更新する必要がありますか?これも実際のビジネス シナリオと併せて検討する必要があります。
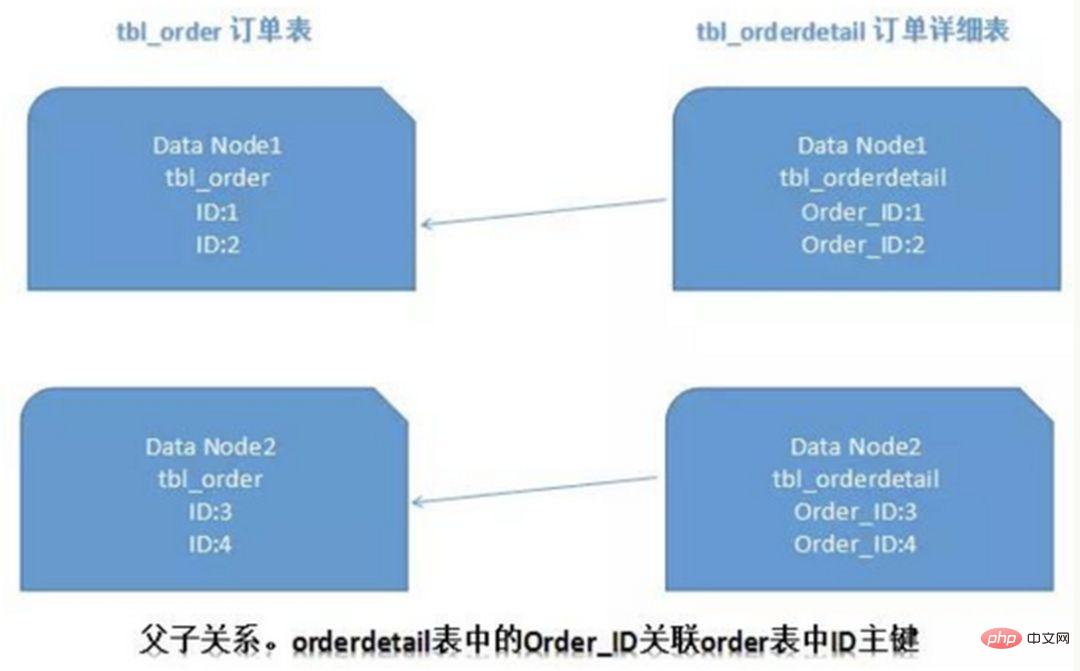
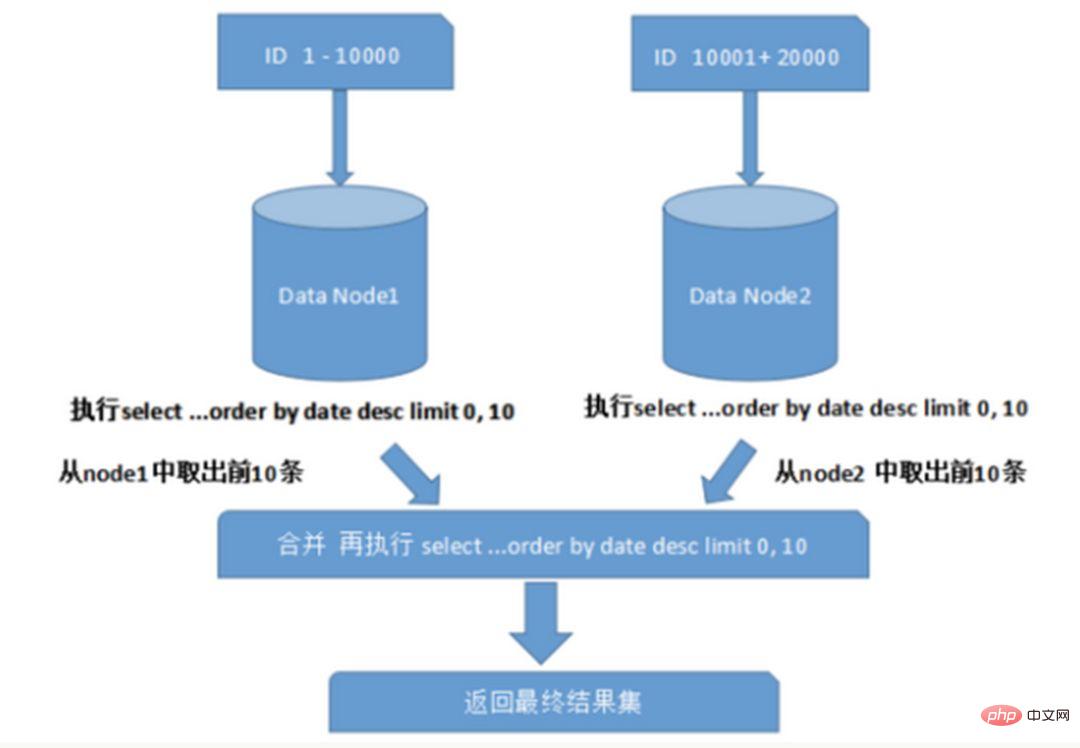
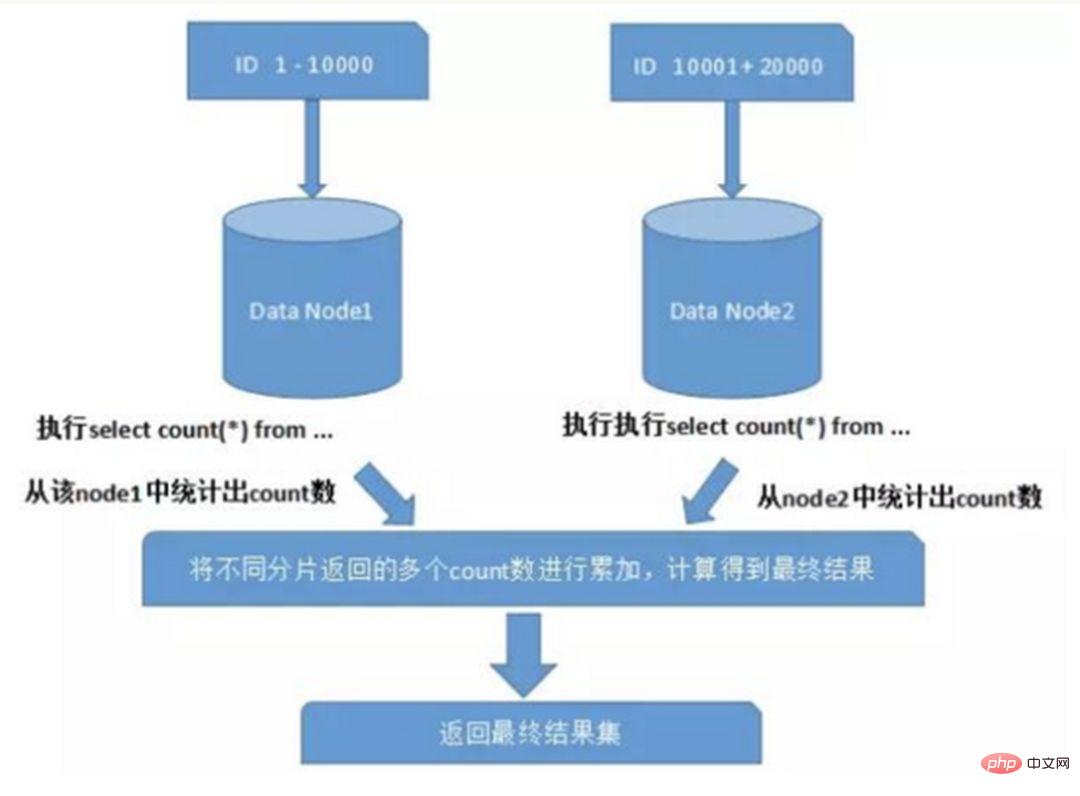
サブデータベース テーブル環境では、テーブル内のデータが異なるデータベースに同時に存在するため、主キー値の通常の自動インクリメントは役に立たず、パーティション データベースの自己生成 ID が保証されません。世界的にユニーク。したがって、データベース間で主キーが重複しないように、グローバル主キーを個別に設計する必要があります。一般的な主キー生成戦略がいくつかあります。
UUID 標準形式には、5 つのセグメントに分割された 32 個の 16 進数が含まれています。 8-4-4-4-12 の形式の 36 文字。例: 550e8400-e29b-41d4-a716-446655440000
UUID は主キーであり、ローカルで生成される最も単純なソリューションです。パフォーマンスが向上し、ネットワークに時間がかかりません。ただし、欠点も明らかです。UUID は非常に長いため、多くのストレージ スペースを占有します。さらに、主キーとしてインデックスを作成し、そのインデックスに基づいてクエリを実行すると、パフォーマンスの問題が発生します。 UUID が乱れると、データの場所が頻繁に変更され、ページングが発生します。
データベースにシーケンス テーブルを作成します:
CREATE TABLE `sequence` ( `id` bigint(20) unsigned NOT NULL auto_increment, `stub` char(1) NOT NULL default '', PRIMARY KEY (`id`), UNIQUE KEY `stub` (`stub`) ) ENGINE=MyISAM;
スタブ フィールドは一意のインデックスに設定され、同じスタブ値はシーケンス テーブル内に 1 つのレコードのみを持ち、複数のテーブルに対してグローバル ID を同時に生成できます。シーケンス テーブルの内容は次のとおりです。
+-------------------+------+ | id | stub | +-------------------+------+ | 72157623227190423 | a | +-------------------+------+
パフォーマンスを向上させるには、InnoDB の代わりに MyISAM ストレージ エンジンを使用します。 MyISAM はテーブル レベルのロックを使用し、テーブルへの読み取りと書き込みはシリアルであるため、同時実行中に同じ ID 値を 2 回読み取ることを心配する必要はありません。
グローバルに一意の 64 ビット ID が必要な場合は、次を実行します。
REPLACE INTO sequence (stub) VALUES ('a'); SELECT LAST_INSERT_ID();
これら 2 つのステートメントは接続レベルにあり、select lastinsertid() は replace into と同じデータベース接続に存在する必要があります。挿入された新しい ID を取得します。
insert into の代わりに replace into を使用する利点は、テーブルの行数が大きくなりすぎることを避け、定期的なクリーニングが必要ないことです。
この解決策は比較的単純ですが、欠点も明らかです: 単一点の問題があり、DB に強く依存しており、DB が異常になるとシステム全体が使用できなくなります。マスター/スレーブを構成すると可用性が向上しますが、マスター データベースに障害が発生してマスターとスレーブが切り替わった場合、特殊な状況下ではデータの一貫性を保証することが困難になります。さらに、パフォーマンスのボトルネックは、単一の MySQL の読み取りおよび書き込みパフォーマンスに限定されます。
flickr チームが使用する主キー生成戦略は、上記のシーケンス テーブル ソリューションに似ていますが、単一点とパフォーマンスのボトルネックの問題をより適切に解決します。
このソリューションの全体的なアイデアは、2 つ以上のグローバル ID 生成サーバーを確立し、各サーバーにデータベースを 1 つだけ展開し、各データベースには現在のグローバル ID を記録するシーケンス テーブルがあるということです。表内の ID 増加のステップ サイズはライブラリの数であり、ID の生成を各データベースにハッシュできるように、開始値が順番にずらしてあります。以下に示すように:
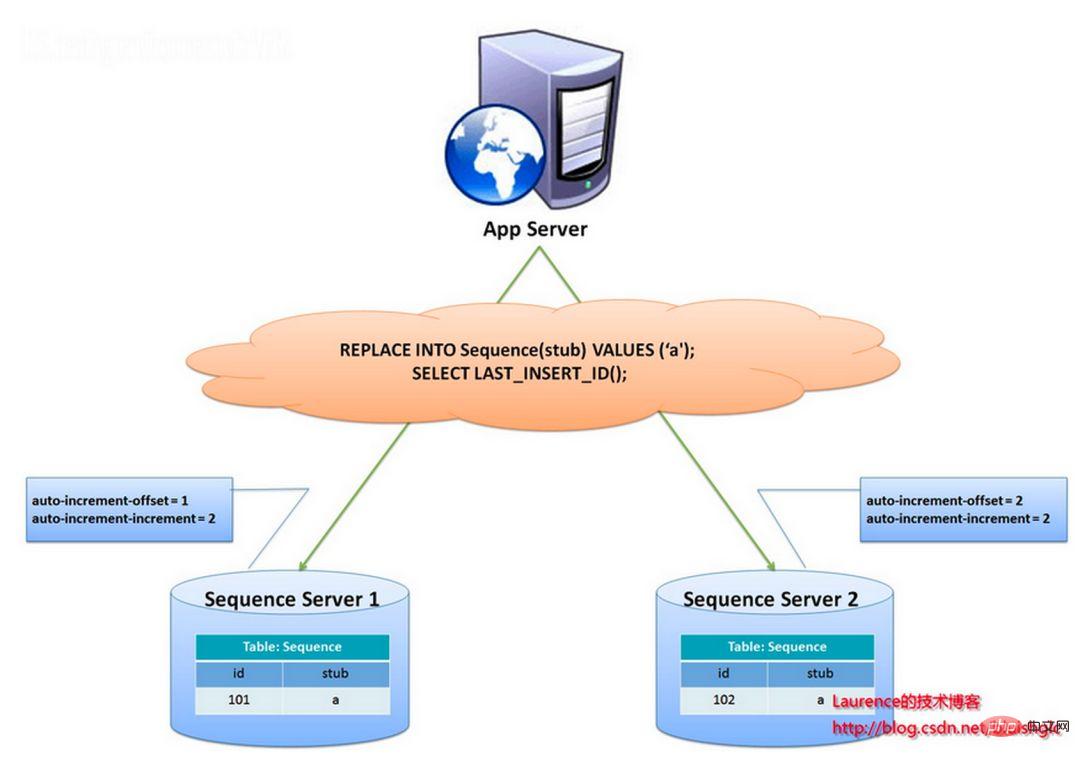
ID は 2 つのデータベース サーバーによって生成され、異なる auto_increment 値が設定されます。最初のシーケンスの開始値は 1 で、各ステップは 2 ずつ増加します。他のシーケンスの開始値は 2 で、各ステップは 2 ずつ増加します。その結果、1 番目のステーションで生成される ID はすべて奇数 (1、3、5、7...) となり、2 番目のステーションで生成される ID はすべて偶数 (2、4、6、8...) になります。 。)。
このソリューションは、ID 生成の圧力を 2 台のマシンに均等に分散します。また、システムの耐障害性も備えており、1 台目のマシンでエラーが発生した場合は、自動的に 2 台目のマシンに切り替えて ID を取得します。ただし、システムにマシンを追加する際の水平展開が煩雑になる、IDを取得するたびにDBを読み書きする必要がある、DBへの負荷が依然として非常に高い、パフォーマンスが低下するなどのデメリットがあります。ヒープマシンに依存することによってのみ改善できます。
flickr のソリューションに基づいて最適化を続けることができます。バッチ方式を使用してデータベースの書き込み圧力を軽減します。毎回 ID 番号セグメントの範囲を取得し、使用後にデータベースにアクセスしてそれらを取得します。これにより、データベースへの負担が大幅に軽減されます。次の図に示すように:
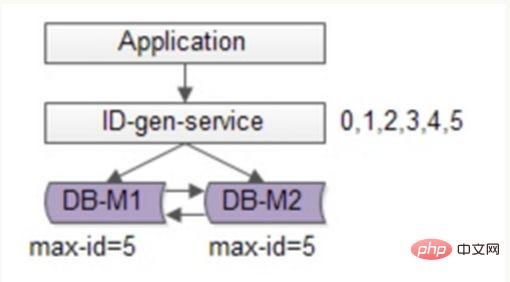
可用性を確保するために引き続き 2 つの DB を使用し、現在の最大 ID のみがデータベースに保存されます。 ID 生成サービスは毎回 6 つの ID をバッチで取得し、最初に maxid を 5 に変更します。アプリケーションが ID 生成サービスにアクセスするとき、データベースにアクセスする必要はなく、ID 0 ~ 5 が番号セグメントから順番にディスパッチされます。キャッシュ。これらのIDを発行した後、maxidを11に変更すると、次回からID6~11を配布できるようになります。その結果、データベースへの負担は元の 1/6 に軽減されます。
Twitter のスノーフレーク アルゴリズムは、分散システムがグローバル ID を生成する必要性を解決し、64 個のロング ID を生成します。タイプの桁数、構成要素:
#最初の桁は未使用です#次の 41 桁はミリ秒レベルの時間であり、41 桁の長さは 69 年間の時間を表すことができます
5 桁の datacenterId、5 桁の workerId。 10 ビットの長さは、最大 1024 ノードの展開をサポートします。
最後の 12 ビットはミリ秒以内のカウントであり、12 ビットのカウント シーケンス番号は、各ノードがミリ秒あたり 4096 個の ID シーケンスを生成することをサポートします
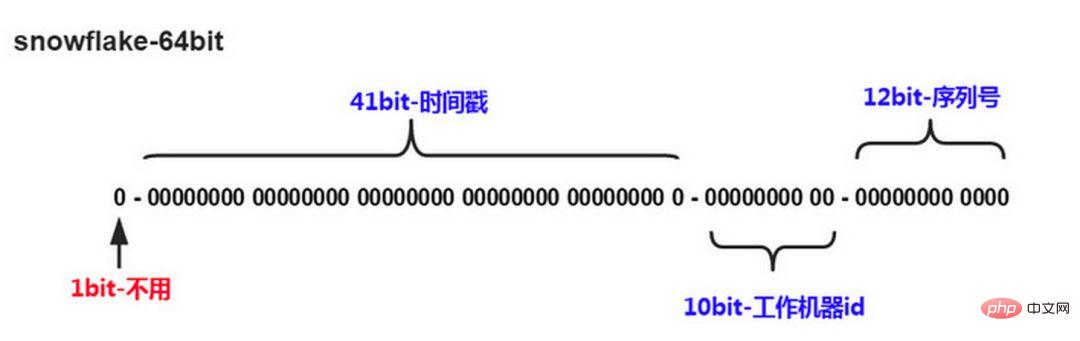
欠点は、マシンクロックに大きく依存することであり、クロックを遅らせるとIDが重複して生成される可能性があります。
データベースとスノーフレークの一意の ID ソリューションを組み合わせると、業界のより成熟したソリューションである Leaf - Meituan-Dianping 分散 ID を参照できます。生成システムを構築し、高可用性、災害復旧、分散クロッキングなどの問題を考慮しています。
ビジネスが急速に発展し、パフォーマンスとストレージのボトルネックに直面した場合、シャーディング設計が検討されます。今回は、履歴データの移行の問題を考慮することが避けられません。一般的なアプローチは、最初に履歴データを読み取り、次に指定されたシャーディング ルールに従って各シャード ノードにデータを書き込むことです。さらに、現在のデータ量と QPS、およびビジネス開発の速度に基づいてキャパシティ プランニングを実行し、必要なシャードのおおよその数を計算する必要があります (一般に、単一テーブルのデータ量を計算することをお勧めします)。単一シャードは 1000W を超えません)
数値範囲シャーディングを使用する場合は、ノードを追加して容量を拡張するだけで済み、シャード データを移行する必要はありません。数値モジュロ シャーディングを使用すると、後の拡張問題を考慮するのが比較的面倒になります。
データのセグメント化をいつ考慮するかを以下に説明します。
すべてのテーブルを分割する必要があるわけではありません。主にデータの増加に依存します。スピード。セグメント化によりビジネスはある程度複雑になりますが、データベースはデータの保存とクエリの実行に加えて、ビジネスのニーズをより適切に実現するのに役立つ重要なタスクの 1 つです。
「過剰設計」や「時期尚早の最適化」を避けるために絶対に必要な場合を除き、サブデータベースとサブテーブルという大きなトリックは使用しないでください。データベースやテーブルを分割する前に、分割のためだけに分割するのではなく、ハードウェアのアップグレード、ネットワークのアップグレード、読み取りと書き込みの分離、インデックスの最適化など、最初にできることから最善を尽くしてください。データ量が単一テーブルのボトルネックに達した場合は、データベースとテーブルのシャーディングを検討してください。
ここでいう運用保守とは、以下のことを指します。
1) データベースのバックアップの場合、1 つのテーブルが大きすぎると、バックアップ中に大量のディスク IO とネットワーク IO が必要になります。たとえば、1T のデータがネットワーク上で送信され、50MB を占有する場合、完了までに 20,000 秒かかり、プロセス全体のリスクが比較的高くなります。 , MySQL はテーブル全体をロックしますが、この時間は非常に長くなり、この期間中、ビジネスはこのテーブルにアクセスできなくなり、大きな影響が生じます。 pt-online-schema-changeを使用すると、使用中にトリガーやシャドウテーブルが作成されるため、これにも時間がかかります。この操作中はリスクタイムとしてカウントされます。データテーブルを分割して総量を減らすと、このリスクを軽減できます。
3)大表会经常访问与更新,就更有可能出现锁等待。将数据切分,用空间换时间,变相降低访问压力
举个例子,假如项目一开始设计的用户表如下:
id bigint #用户的IDname varchar #用户的名字last_login_time datetime #最近登录时间personal_info text #私人信息..... #其他信息字段
在项目初始阶段,这种设计是满足简单的业务需求的,也方便快速迭代开发。而当业务快速发展时,用户量从10w激增到10亿,用户非常的活跃,每次登录会更新 lastloginname 字段,使得 user 表被不断update,压力很大。而其他字段:id, name, personalinfo 是不变的或很少更新的,此时在业务角度,就要将 lastlogintime 拆分出去,新建一个 usertime 表。
personalinfo 属性是更新和查询频率较低的,并且text字段占据了太多的空间。这时候,就要对此垂直拆分出 userext 表了。
随着业务的快速发展,单表中的数据量会持续增长,当性能接近瓶颈时,就需要考虑水平切分,做分库分表了。此时一定要选择合适的切分规则,提前预估好数据容量
鸡蛋不要放在一个篮子里。在业务层面上垂直切分,将不相关的业务的数据库分隔,因为每个业务的数据量、访问量都不同,不能因为一个业务把数据库搞挂而牵连到其他业务。利用水平切分,当一个数据库出现问题时,不会影响到100%的用户,每个库只承担业务的一部分数据,这样整体的可用性就能提高。
用户中心是一个非常常见的业务,主要提供用户注册、登录、查询/修改等功能,其核心表为:
User(uid, login_name, passwd, sex, age, nickname) uid为用户ID, 主键login_name, passwd, sex, age, nickname, 用户属性
任何脱离业务的架构设计都是耍流氓,在进行分库分表前,需要对业务场景需求进行梳理:
用户侧:前台访问,访问量较大,需要保证高可用和高一致性。主要有两类需求:
1. ユーザー ログイン: ログイン名/電話番号/電子メールを介してユーザー情報をクエリします。リクエストの 1% がこのタイプに属します。 2. ユーザー情報のクエリ: ログイン後、uid を介してユーザー情報をクエリします。リクエストの 99% がこのタイプに属します。 運用側: バックエンドにアクセスし、運用ニーズをサポートし、年齢、性別、ログイン時間、登録時間などに基づいてページング クエリを実行します。これは、アクセス量が少なく、可用性と一貫性に関する要件が低い内部システムです。
#データ量がますます大きくなると、前述のようにデータベースを水平方向に分割する必要があります。上記 分割方法には、「数値範囲に基づく」と「数値剰余に基づく」があります。
"数値範囲に従って":主キーuidを分割基準として、uidの範囲に応じてデータを複数のデータベースに水平分割します。たとえば、user-db1 は 0 ~ 1000w の範囲の uid を持つデータを格納し、user-db2 は 1000w ~ 2000wuid の範囲の uid を持つデータを格納します。
利点は:拡張が簡単で、容量が足りない場合は新しいデータベースを追加するだけです。
欠点は : リクエスト量が均一ではないことです。一般に、新しく登録されたユーザーの方がアクティブになるため、新しい user-db2 の負荷が user-db1 よりも高くなり、その結果、 Balance
"数値に基づくモジュロ": 主キー uid も除算の基礎として使用され、データは、データに基づいて複数のデータベースに水平に分割されます。 uid のモジュロ値。たとえば、user-db1 は uid データを法 1 で保存し、user-db2 は uid データを法 0 で保存します。
メリットは:データ量とリクエスト量が均等に分散される
デメリットは:拡張が面倒。新しいデータベースを追加します。再ハッシュが必要です。データのスムーズな移行を考慮する必要があります。
水平セグメント化後、uid によるクエリの要求は十分に満たされ、直接ルートすることができます。特定のデータベースに。 login_name などの非 uid に基づくクエリの場合、どのライブラリにアクセスする必要があるかが不明であり、この場合、すべてのライブラリを走査する必要があり、パフォーマンスが大幅に低下します。
ユーザー側では「非uid属性からuidへのマッピング関係を確立する」、運用側では「フロントエンドとバックエンドを分離する」という解決策が採れます。採用することができます。
1) マッピング関係
例:ログイン名を直接指定することはできません。データベースを見つけて、マッピング関係 login_name→uid を確立し、インデックス テーブルまたはキャッシュを使用してそれを保存できます。 loginname にアクセスするときは、まずマッピング テーブルを介して login_name に対応する uid を照会し、次に uid を介して特定のライブラリを見つけます。
マッピング テーブルには列が 2 つしかなく、大量のデータを保持できます。データ量が多すぎる場合は、マッピング テーブルを水平に分割することもできます。このタイプの kv 形式のインデックス構造では、キャッシュを使用してクエリのパフォーマンスを最適化でき、マッピング関係が頻繁に変更されず、キャッシュ ヒット率が非常に高くなります。
2) 遺伝子メソッド
サブライブラリ遺伝子: ライブラリが uid によって 8 つのライブラリに分割されている場合、uid%8 を使用してルーティングされます。このとき、最後のものによって決定されます。 uid の 3 ビット。ユーザー データのこの行がどのライブラリに該当するかを決定すると、これらの 3 ビットはサブライブラリ遺伝子と見なすことができます。
上記のマッピング関係メソッドでは、マッピング テーブルの追加ストレージが必要です。非 uid フィールドでクエリを実行する場合は、追加のデータベースまたはキャッシュ アクセスが必要です。冗長なストレージとクエリを排除したい場合は、関数 f を使用して、loginname 遺伝子を uid のサブライブラリ遺伝子として取得できます。 uid を生成するときは、上記の分散固有 ID 生成スキームに最後の 3 ビット値 = f (ログイン名) を加えたものを参照してください。ログイン名をクエリする場合、f(ログイン名)%8 の値を計算するだけで、特定のライブラリを見つけることができます。ただし、これには、事前に容量計画を立て、今後数年間でデータ量をいくつのデータベースに分割する必要があるかを見積もり、データベース遺伝子の特定のビット数を予約する必要があります。
以上がデータベースはデータベースとテーブルに分かれています。分割方法は?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



