

インタビューの観点から Kafka を完成させた
Kafka は優れた分散メッセージ ミドルウェアであり、メッセージ通信用の多くのシステムで使用されています。分散メッセージング システムを理解して使用することは、バックエンド開発者にとってほぼ必須のスキルとなっています。今日の 马哥byte は、Kafka の面接でよくある質問から始めて、Kafka についてお話します。
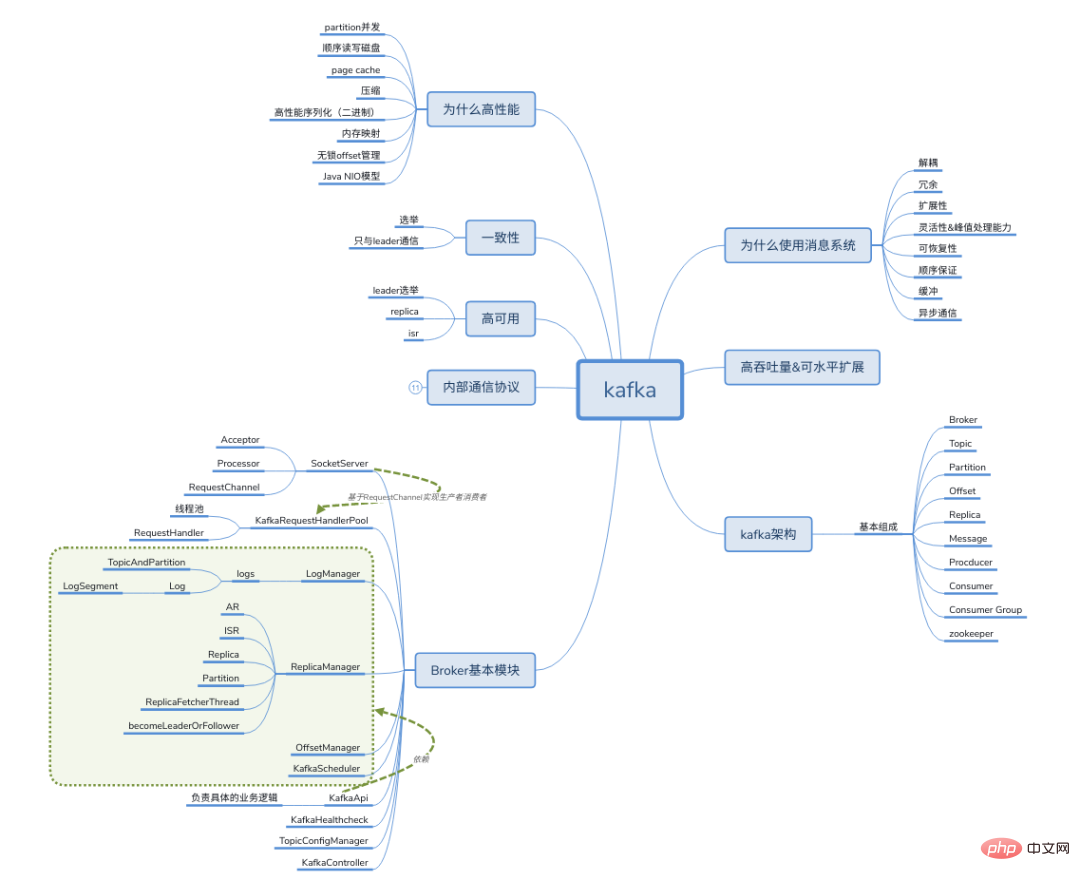 #マインド マップ
#マインド マップ- #分散メッセージング ミドルウェアとは何ですか?
- メッセージミドルウェアの役割は何ですか?
- メッセージミドルウェアの使用シナリオは何ですか? #メッセージミドルウェアの選択?

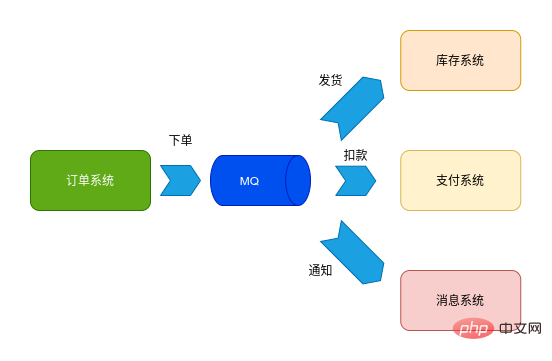
#デカップリング Kafka トピック パーティションのレイアウト Kafka コンシューマ オフセット プロデューサー、コンシューマー、コンシューマー グループ、トピック、パーティション 消費者グループ
以下は、いくつかの一般的な分散メッセージング システムの比較です:
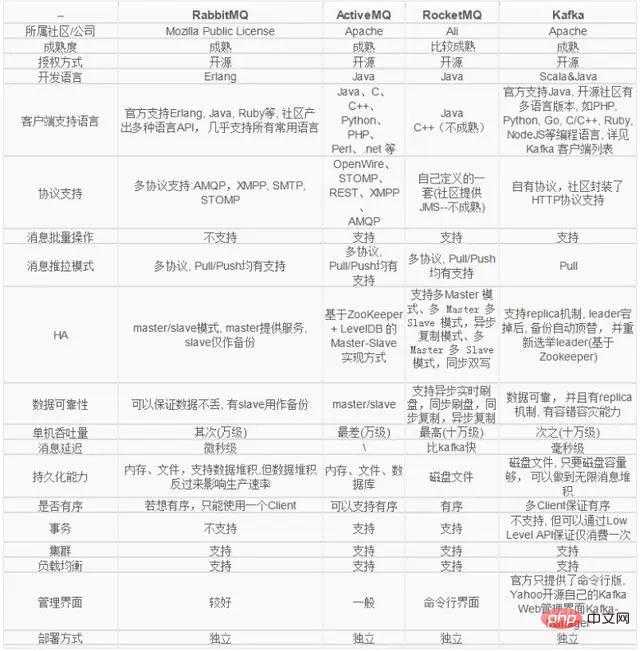
キーワードを答える
#Kafka の基本概念とアーキテクチャ
#質問
Kafka のアーキテクチャについて簡単に説明してください。
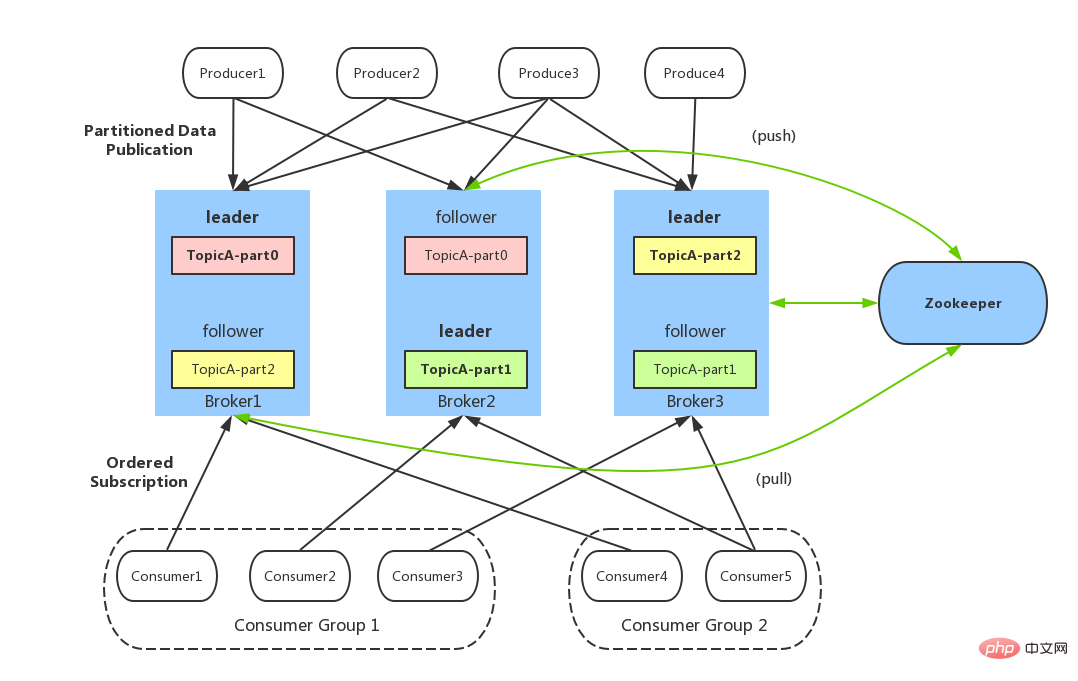
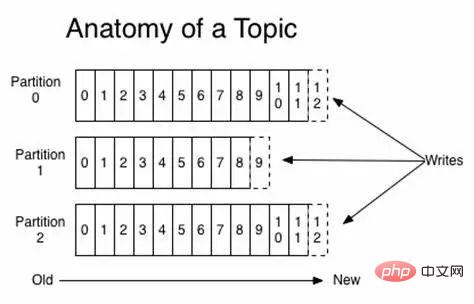 ##Topic
##Topic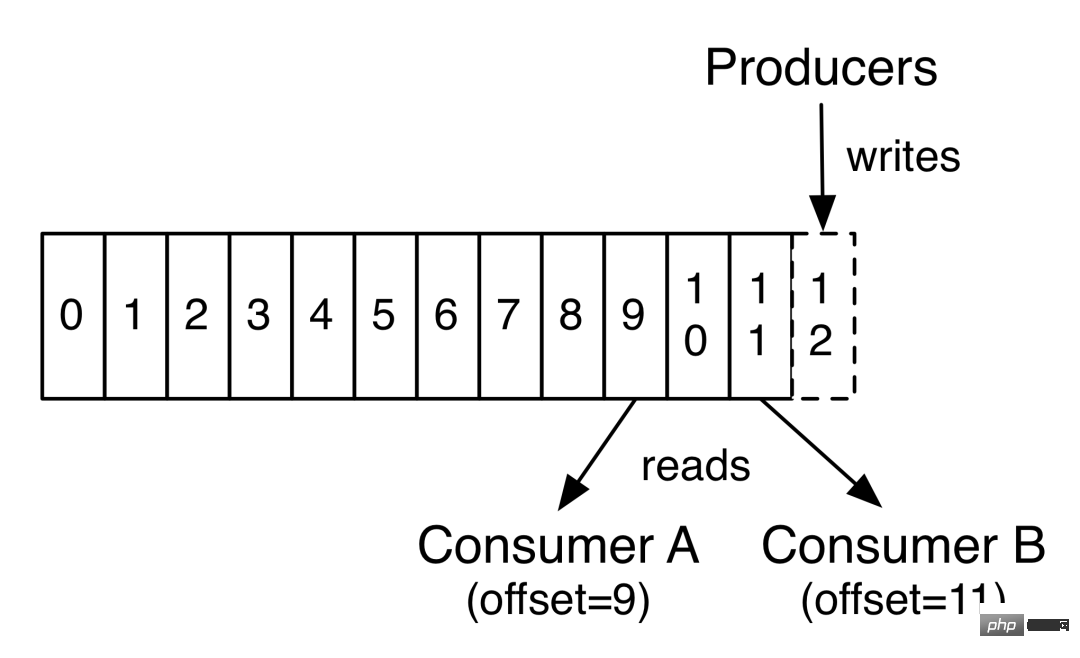 #消費者オフセット
#消費者オフセット#動物園の飼育員
#動物園の飼育員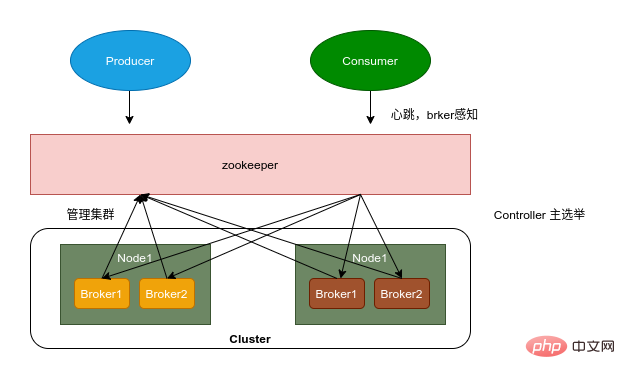
キーワードへの回答
Kafka のアーキテクチャを簡単に説明してください。
#Kafka はどのようにメッセージをブロードキャストしますか?
トピック レベルは順序付けされておらず、パーティションは順序付けされています
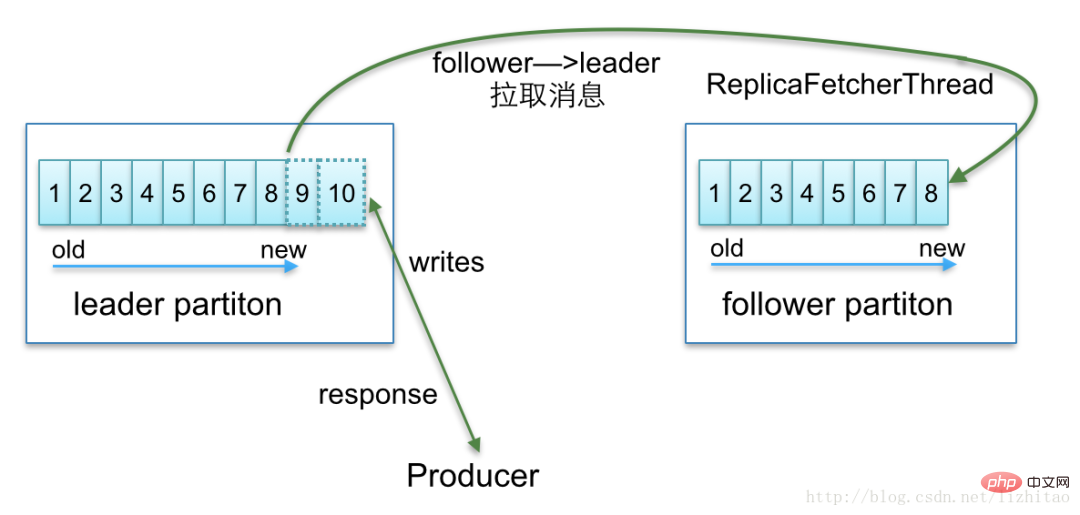
サポートされていません。外部の読み取りおよび書き込みサービスを提供するのは Leader のみです。
コピー、確認、HW
#いいえ、データは失われます
Kafka を使用した
問題
Kafka にはどのようなコマンド ライン ツールがありますか?どちらを使用したことがありますか? Kafka プロデューサーの実行プロセス? Kafka プロデューサーの一般的な構成は何ですか? Kafka メッセージを整理するにはどうすればよいでしょうか? プロデューサー データ送信が失われないようにするにはどうすればよいですか? プロデューサーのパフォーマンスを向上させるにはどうすればよいですか? 同じグループ内のコンシューマーの数がパーツの数よりも多い場合、Kafka はそれをどのように処理しますか? Kafka Consumer はスレッドセーフですか? Kafka Consumer を使用してメッセージを消費するときのスレッド モデルについて教えてください。なぜこのように設計されているのでしょうか? Kafka Consumer の一般的な構成? コンシューマーはいつクラスターから追い出されますか? Consumer が参加または終了したとき、Kafka はどのように反応しますか? リバランスとは何ですか?リバランスはいつ行われますか?
コマンド ライン ツール
Kafka のコマンド ライン ツールは、Kafka パッケージの /bin にあります。このディレクトリには主に、サービスおよびクラスターの管理スクリプト、構成スクリプト、情報表示スクリプト、トピック スクリプト、クライアント スクリプトなどが含まれます。
kafka-configs.sh: 構成管理スクリプト kafka-console-consumer.sh:kafka コンシューマー コンソール #kafka-console-Producer.sh:kafka プロデューサー コンソール- kafka-consumer-groups.sh:kafka コンシューマー グループ関連情報
- #kafka-log-dirs.sh: Kafka メッセージ ログ ディレクトリ情報
- kafka-mirror-maker.sh: 異なるデータセンターの Kafka クラスター レプリケーション ツール
- kafka-preferred-replica-election.sh: 優先レプリカの選択をトリガー
- kafka-Producer-perf-test.sh: Kafka プロデューサーのパフォーマンス テスト スクリプト
- kafka-reassign-partitions.sh: パーティションの再割り当てスクリプト
- kafka-replica-verification.sh: レプリケーション進行状況検証スクリプト
- kafka-server-start.sh: Kafka サービスの開始
-
- kafka-topics.sh: トピック管理スクリプト
-
- kafka-verifiable-Producer.sh: 検証可能な kafka プロデューサー
- zookeeper-server-start.sh : zk サービスを開始します
- #zookeeper-server-stop.sh: zk サービスを停止します
- zookeeper-shell.sh: zk client
- 通常、 kafka-console-consumer.sh
kafka-console-Producer.sh スクリプトを使用して、Kafka の生成と使用をテストできます。 kafka-consumer-groups.sh はクラスター内のトピックを表示および管理できます。通常、kafka-topics.sh は Kafka のコンシューマー グループの状況を表示するために使用されます。
Kafka プロデューサー
Kafka プロデューサーの通常のプロダクション ロジックには、次の手順が含まれます。
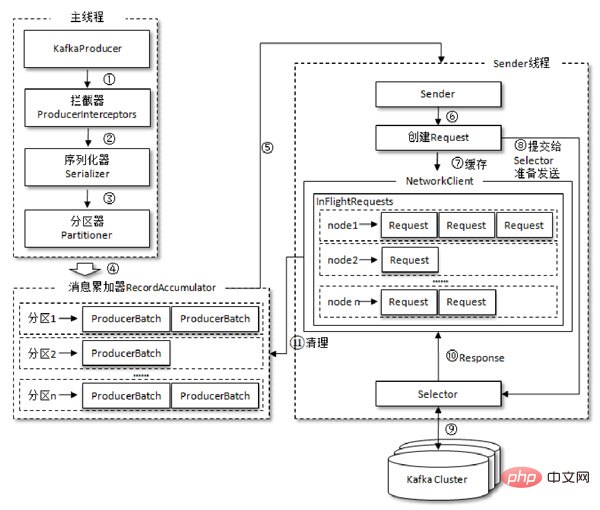
プロデューサーを構成するクライアントパラメータの共通プロデューサーインスタンス。 - #送信するメッセージを作成します。 ############メッセージを送ります。 #プロデューサー インスタンスを閉じます。
- Producer メッセージ送信のプロセスは次の図に示されており、
- interceptor
、 serializer 、
、最終的には、アキュムレータによってバッチでブローカーに送信されます。 プロデューサー
- key.serializer:キーシリアライザー
- value.serializer:値シリアライザー
- 共通パラメータ:
- デフォルト値: 200 (非同期キックインの場合のみ、毎回のバッチ メッセージの数)。
request.required.acks
デフォルト値: 0、0 は、プロデューサーがリーダーからの確認を待つ必要がないことを意味します。1 は、リーダーがローカル ログへの書き込みを確認してすぐに確認する必要があることを意味します。-1 は、プロデューサーは、すべてのバックアップが完了した後に確認する必要があります。非同期モードでのみ機能します。このパラメータの調整は、データ損失と伝送効率の間のトレードオフです。データ損失には敏感ではないが、効率を重視する場合は、0 に設定することを検討できます。これにより、伝送効率が大幅に向上します。データ送信時のプロデューサー。
#request.timeout.ms デフォルト値: 10000、確認タイムアウト。
partitioner.class デフォルト値: kafka.Producer.DefaultPartitioner、kafka.Producer.Partitioner を実装する必要があります, キーに基づいてパーティション分割戦略を提供します。
同じ種類のメッセージを順番に処理する必要がある場合があるため、同じ種類のデータを同じパーティションに割り当てるように分散戦略をカスタマイズする必要があります。
Producer.type デフォルト値: sync、メッセージが同期的に送信されるか非同期的に送信されるかを指定します。 。非同期非同期バッチ送信には kafka.Producer.AyncProducer を使用し、同期同期には kafka.Producer.SyncProducer を使用します。同期送信と非同期送信は、メッセージ生成の効率にも影響します。
- #compression.topic
デフォルト値: なし、メッセージ圧縮、デフォルトでは圧縮なし。他の圧縮方法には、「gzip」、「snappy」、「lz4」などがあります。メッセージを圧縮すると、ネットワーク送信量とネットワーク IO が大幅に削減され、全体的なパフォーマンスが向上します。 compressed.topics デフォルト値: null。圧縮が設定されている場合、特定のトピックの圧縮を指定できます。指定しない場合は、すべての圧縮が実行されます。
#message.send.max.retries デフォルト値: 3 (メッセージの送信試行の最大数)メッセージ。
- #retry.backoff.ms
デフォルト値: 300、試行ごとに追加の間隔が追加されます。 topic.metadata.refresh.interval.ms -
デフォルト値: 600000、定期的にメタデータを取得します。パーティションが失われ、リーダーが使用できない場合、プロデューサーも積極的にメタデータを取得します。0 の場合、メッセージが送信されるたびにメタデータが取得されるため、推奨されません。負の場合、メタデータは失敗した場合にのみフェッチされます。
デフォルト値: 5000 (プロデューサー キュー内の最大キャッシュ データ)時間、非同期のみ。 queue.buffering.max.message
- デフォルト値: 10000、プロデューサーによってキャッシュされるメッセージの最大数、非同期専用。
queue.enqueue.timeout.ms
デフォルト値: -1、キューがいっぱいの場合、0 は破棄されます。負の値はキューがいっぱいのときのブロック、正の値はキューがいっぱいのときのブロックの対応する時間です。非同期の場合。
Kafka にはコンシューマ グループの概念があり、各コンシューマのみが消費できます割り当てられたパーティションからのメッセージ。各パーティションはコンシューマ グループ内の 1 つのコンシューマによってのみ消費されます。そのため、同じコンシューマ グループ内のコンシューマの数がパーティションの数を超えると、一部のコンシューマが表示されます。消費できないパーティションは割り当てられます。 。コンシューマ グループとコンシューマの関係を次の図に示します。
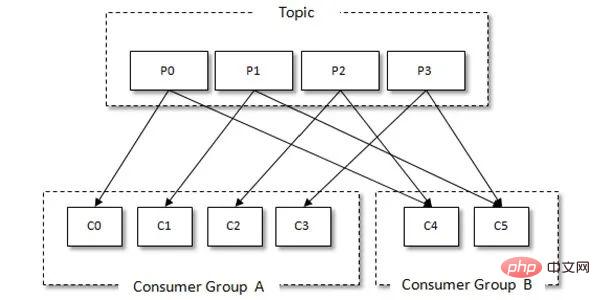 コンシューマ グループ
コンシューマ グループ- クライアントを構成してコンシューマを作成する
- トピックを購読する
- メッセージをプルして消費するそれ
- 消費変位の送信
- コンシューマ インスタンスを閉じる
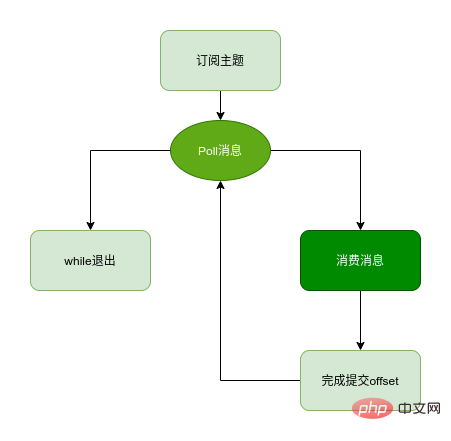 プロセス
プロセス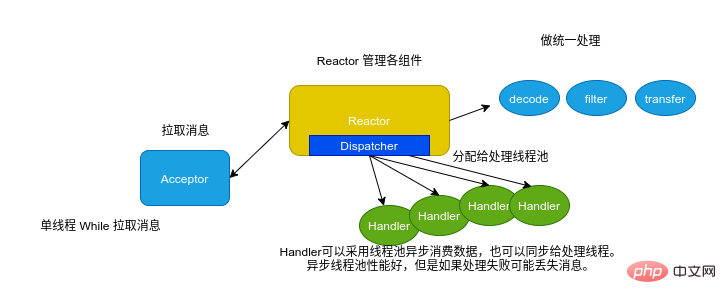
Kafka コンシューマ パラメータ
bootstrap.servers : 接続ブローカーのアドレス、 host: port形式。group.id: コンシューマが属するコンシューマ グループ。 key.deserializer: プロデューサの key.serializer、キーの逆シリアル化メソッドに対応します。value.deserializer: プロデューサの value.serializer、value の逆シリアル化メソッドに対応します。session.timeout.ms: コーディネーターの検出が失敗した時刻。デフォルトは 10 秒です。このパラメータは、ハートビートの有効期限と同様に、コンシューマ グループ (グループのメンバーである comSummer) がクラッシュをアクティブに検出する時間間隔です。 auto.offset.reset: この属性は、コンシューマがオフセットなしでオフセットを読み取った場合、そのオフセットが無効であることを指定します (コンシューマは長期間有効期限が切れており、現在のオフセットは無効です)パーティションが古くなって削除された場合はどうすればよいですか? デフォルト値は最新で、最新のレコード (コンシューマーの開始後に生成されたレコード) からデータを読み取ることを意味します。もう 1 つの値は最も早いもので、これは次のことを意味します。部分シフト量が無効な場合、コンシューマは開始位置からデータの読み取りを開始します。 enable.auto.commit: 変位を自動的に送信する場合はいいえ。 falseの場合は、プログラム内で変位を手動で送信する必要があります。 1 回限りのセマンティクスの場合は、オフセットを手動で送信するのが最善です。fetch.max.bytes: データの 1 回のプルの最大バイト数 max.poll.records: 1 回のポーリング呼び出しで返されるメッセージの最大数。処理ロジックが非常に軽量な場合は、この値を適切に増やすことができます。ただし、 max.poll.records個のデータは session.timeout.ms 以内に処理する必要があります。デフォルト値は 500request.timeout.ms: リクエスト応答の最大待機時間です。タイムアウト期間内に応答が受信されない場合、Kafka はメッセージを再送信するか、再試行回数を超えると直接失敗します。
Kafka Rebalance
Rebalance は本質的に、コンシューマ グループに属するすべてのコンシューマがそれぞれのコンシューマをどのように割り当てるかを規定するプロトコルです。パーティションがトピックにサブスクライブされました。たとえば、特定のグループの下に 20 人のコンシューマがあり、100 のパーティションを持つトピックをサブスクライブするとします。通常の状況では、Kafka は各コンシューマーに平均 5 つのパーティションを割り当てます。この割り当てプロセスはリバランスと呼ばれます。
リバランスはいつ行うべきですか?
これもよく言われる質問です。リバランスには 3 つのトリガー条件があります:
グループ メンバーの変更 (新しいコンシューマがグループに参加する、既存のコンシューマが自発的にグループを離れる、または既存のコンシューマがクラッシュする) - 2 つの違い後で説明します) to) サブスクライブされたトピックの数が変更されました トピックにサブスクライブされたパーティションの数が変更されました
グループ内にパーティションを割り当てるにはどうすればよいですか?
Kafka は、デフォルトで、範囲とラウンドロビンという 2 つの割り当て戦略を提供します。もちろん、Kafka はプラグ可能な割り当て戦略を採用しており、独自のアロケーターを作成してさまざまな割り当て戦略を実装できます。
キーワードへの回答
Kafka のコマンド ライン ツールとは何ですか?どちらを使用したことがありますか? /binディレクトリ、kafka クラスターの管理、トピックの管理、kafka の生成と消費Kafka プロデューサーの実行プロセス?インターセプター、シリアライザー、パーティショナー、アキュムレーター Kafka プロデューサーの一般的な構成は何ですか?ブローカー構成、ack 構成、ネットワークおよび送信パラメーター、圧縮パラメーター、ack パラメーター Kafka メッセージを順序どおりに保つにはどうすればよいですか? Kafka 自体はトピック レベルでは順序付けされておらず、パーティションでのみ順序付けされているため、処理順序を保証するために、パーティショナーをカスタマイズして、連続して処理する必要があるデータを同じパーティションに送信することができます プロデューサー データを損失なく確実に送信するにはどうすればよいですか? ack メカニズム、再試行メカニズム プロデューサーのパフォーマンスを向上させるにはどうすればよいですか?バッチ、非同期、圧縮 同じグループ内のコンシューマーの数がパーツの数よりも多い場合、Kafka はそれをどのように処理しますか?冗長パーツは役に立たない状態になり、データを消費しません - #Kafka Consumer はスレッドセーフですか?安全ではない、シングルスレッド消費、マルチスレッド処理
- Kafka Consumer を使用してメッセージを消費するときのスレッド モデルについて教えてください。なぜこのように設計されているのでしょうか?プルと処理の分離
- Kafka Consumer の一般的な構成?ブローカー、ネットワークおよびプル パラメーター、ハートビート パラメーター
- Consumer はいつクラスターから追い出されますか?クラッシュ、ネットワーク異常、処理時間が長すぎる、送信ディスプレイスメント タイムアウト
- Consumer が参加または終了したときに Kafka はどのように反応しますか?リバランスの実行
- リバランスとは何ですか?いつリバランスが行われますか?トピックの変更、消費者の変更
- Kafka はどのようにして高可用性を確保しますか?
- Kafka の配信セマンティクス?
- Replica は何をしますか?
- AR、ISR どうしたの?
- リーダーとフラワーとは何ですか?
- Kafka の HW、LEO、LSO、LW などは何を表しますか?
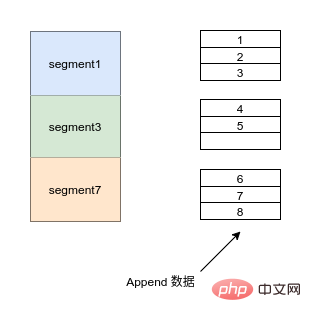
Kafka は優れたパフォーマンスを確保するために何をしましたか?
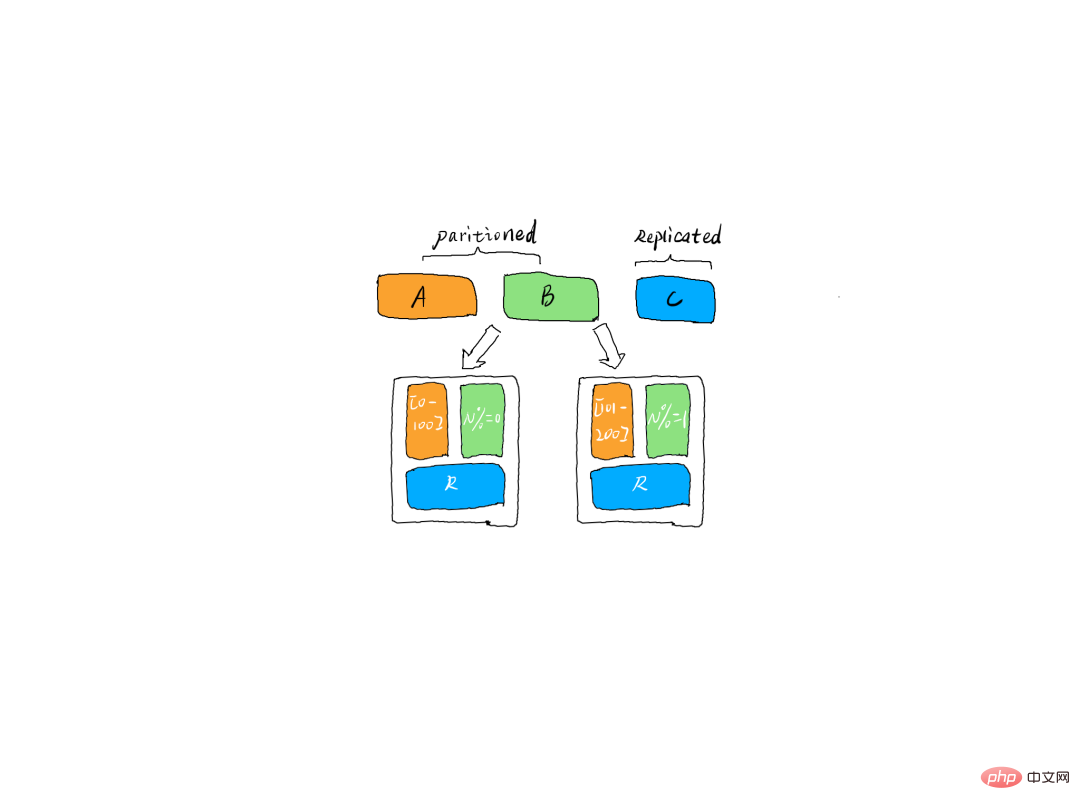 パーティション レプリカ
パーティション レプリカフォロワー コピーが読み取りサービスを提供しないのはなぜですか?
この問題は本質的に、パフォーマンスと一貫性の間のトレードオフです。想像してみてください。フォロワーのコピーが外部の世界にもサービスを提供したらどうなるでしょうか?まず、パフォーマンスは確実に向上します。しかし同時に、さまざまな問題も発生します。データベース トランザクションにおけるファントム リードとダーティ リードに似ています。たとえば、データを Kafka トピック a に書き込む場合、コンシューマ b はトピック a からのデータを消費しますが、コンシューマ b が読み取るパーティション コピーに最新のメッセージが書き込まれていないため、そのデータを消費できないことがわかります。このとき、別のコンシューマcはリーダーコピーを消費するため、最新のデータを消費することができる。 Kafka は、WH と Offset の管理を使用して、Consumer が消費できるデータと現在書き込まれているデータを決定します。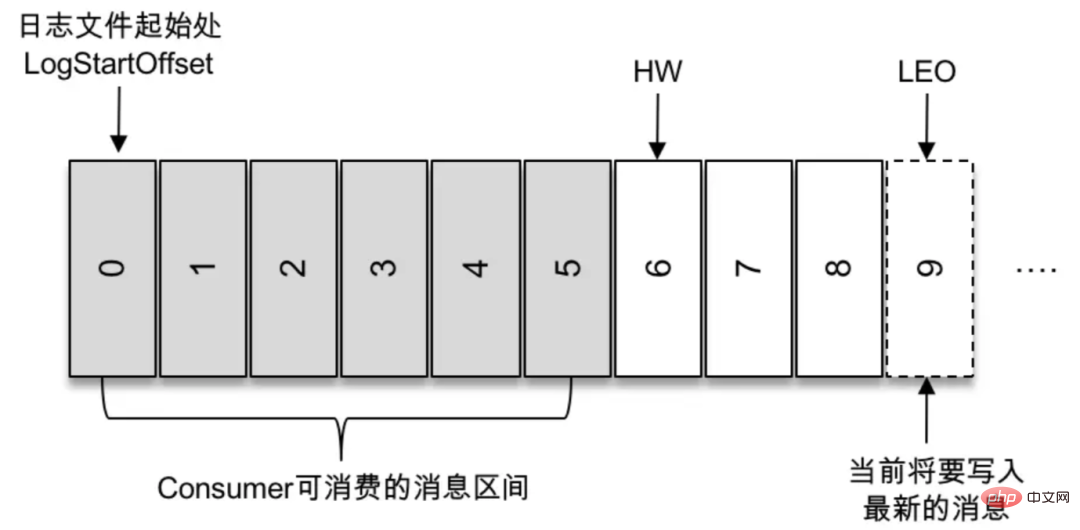 ウォーターマーク
ウォーターマークリーダーのみが外部読み取りサービスを提供できるため、リーダーの選出方法
kafkaリーダー レプリカによって同期が維持されるレプリカは、ISR レプリカ セットに配置されます。もちろん、ISR コピー セットには必ずリーダー コピーが存在しますが、特殊な場合には、ISR コピー内にリーダーのコピーが 1 つだけ存在することもあります。リーダーが失敗すると、kakfa は飼育員を通じてこの状況を感知し、ISR コピー内の新しいコピーをリーダーとして選択し、外部の世界にサービスを提供します。しかし、これには別の問題があり、前述したように、ISR レプリカ セットにはリーダーしか存在しない可能性があり、リーダー レプリカが死ぬと ISR セットは空になります。このとき、unclean.leader.election.enable パラメーターが true に設定されている場合、Kafka は非同期のリーダーとなるレプリカ、つまり ISR レプリカ セットに含まれていないレプリカを選択します。コピーが存在するとコピー同期の問題が発生します
Kafka は、割り当てられたすべてのレプリカ (AR) で使用可能なレプリカ リスト (ISR) を維持します。プロデューサーがブローカーにメッセージを送信すると、## に基づいてメッセージが同期されるまで待機する必要があるレプリカの数を決定します。 #ack 構成。成功した場合のみ、ブローカーは ReplicaManager サービスを内部的に使用して、フラワーとリーダー間のデータ同期を管理します。
パフォーマンスの最適化
- パーティションの同時実行性
- ディスクへの順次読み取りおよび書き込み
- ページ キャッシュ: ページごとの読み取りおよび書き込み
- 先をお読みください: Kafka は、メモリに消費されるメッセージを事前に読み取ります
- 高パフォーマンスのシリアル化 (バイナリ)
- メモリ マッピング
- Java NIO モデル
- バッチ: バッチ読み取り
- 圧縮: メッセージ圧縮、ストレージ圧縮、ネットワークと IO オーバーヘッドの削減
逐次読み取りおよび書き込み

データを追加
キーワードを答える
方法Kafka は高可用性を保証しますか?
レプリカ、プロデューサーの確認応答、再試行、リーダーの自動選出、コンシューマーのセルフバランシングを通じてデータの高可用性を確保します
# #Kafka の配信セマンティクス?
配信セマンティクスには通常、少なくとも 1 回 、最大 1 回 、および 正確に 1 回 が含まれます。 Kafka は、ack 構成を通じて最初の 2 つを実装します。
Replica は何をしますか?
データの高可用性の実現
AR と ISR とは何ですか?
AR: 割り当てられたレプリカ。 AR は、トピックの作成後にパーティションが作成されるときに割り当てられるレプリカのセットであり、レプリカの数はレプリカ係数によって決まります。 ISR: 同期レプリカ。 Kafka の特に重要な概念は、リーダーと同期される AR 内のレプリカのセットを指します。 AR 内のレプリカは ISR に含まれていない可能性がありますが、リーダー レプリカは当然 ISR に含まれます。 ISR に関しては、面接でよく聞かれるもう 1 つの質問は、コピーが ISR に属するかどうかを判断する方法です。現在の判断は、フォロワーのレプリカの LEO がリーダーの LEO より遅れている時間が、ブローカー側のパラメーターplica.lag.time.max.ms の値を超えるかどうかに基づいています。それを超えると、レプリカは ISR から削除されます。
#リーダーとフラワーとは何ですか? Kafka の HW は何を表しますか?
最高水準。これは、コンシューマが読み取ることができるメッセージの範囲を制御する重要なフィールドです。通常のコンシューマは、ログ開始オフセットとハードウェア (排他的) の間のリーダー レプリカ上のすべてのメッセージを「表示」することしかできません。水面より上のメッセージは消費者には見えません。
Kafka は優れたパフォーマンスを確保するために何をしましたか? #パーティションの同時実行性、ディスクへのシーケンシャル読み取りおよび書き込み、ページ キャッシュ圧縮、高パフォーマンスのシリアル化 (バイナリ)、メモリ マッピングのロックフリー オフセット管理、Java NIO モデル
方法Kafka は高可用性を保証しますか?
レプリカ、プロデューサーの確認応答、再試行、リーダーの自動選出、コンシューマーのセルフバランシングを通じてデータの高可用性を確保します
配信セマンティクスには通常、少なくとも 1 回
、最大 1 回、および正確に 1 回が含まれます。 Kafka は、ack 構成を通じて最初の 2 つを実装します。
データの高可用性の実現
AR: 割り当てられたレプリカ。 AR は、トピックの作成後にパーティションが作成されるときに割り当てられるレプリカのセットであり、レプリカの数はレプリカ係数によって決まります。 ISR: 同期レプリカ。 Kafka の特に重要な概念は、リーダーと同期される AR 内のレプリカのセットを指します。 AR 内のレプリカは ISR に含まれていない可能性がありますが、リーダー レプリカは当然 ISR に含まれます。 ISR に関しては、面接でよく聞かれるもう 1 つの質問は、コピーが ISR に属するかどうかを判断する方法です。現在の判断は、フォロワーのレプリカの LEO がリーダーの LEO より遅れている時間が、ブローカー側のパラメーターplica.lag.time.max.ms の値を超えるかどうかに基づいています。それを超えると、レプリカは ISR から削除されます。
最高水準。これは、コンシューマが読み取ることができるメッセージの範囲を制御する重要なフィールドです。通常のコンシューマは、ログ開始オフセットとハードウェア (排他的) の間のリーダー レプリカ上のすべてのメッセージを「表示」することしかできません。水面より上のメッセージは消費者には見えません。
以上がインタビューの観点から Kafka を完成させたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7564
7564
 15
1386
52
87
11
28
101
15
1386
52
87
11
28
101


 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Bootは、Java開発に革命をもたらす堅牢でスケーラブルな、生産対応のJavaアプリケーションの作成を簡素化します。 スプリングエコシステムに固有の「構成に関する慣習」アプローチは、手動のセットアップを最小化します。
